






**(具体操作会在下一篇讲,这一篇简单分析了解下SD3.5)
**
距离Stable Diffusion 3.5的发布也过去了一小段时间,其实我好像已经有一段时间没有专门提到Stable Diffusion系列了。
而上一个Stable Diffusion版本也就是3.0其实在今年6月份发布了,之所以没有提到过是因为SD3.0的风评好像不是很好:
SD3.0的实际生成效果远达不到宣传的那种预期,再加上授权许可问题,一些主流平台干脆ban掉了SD3.0
而正当大部分人都对stable diffusion乃至stabilityAI感到失望,转头跑向FLUX的怀抱时,Stable Diffusion 3.5发布了。
简单说一下这个模型的版本迭代,早在2022年SD开源至今已经发布了很多不同版本的基础模型(Base Model),而像是SD1、SD2、SDXL这样的大版本更新都代表着模型能力的显著提升,以及架构和使用方式的一些变化。
之前我们常用且经常提到的版本是22年发布的SD1.5和23年发布的SDXL,基于这两者去做的微调模型(LoRA、Checkpoint、ControlNet)是比较多的。
而现在的SD3.5同样是作为一个大版本的基础模型发布,并且提供了三种不同的基本型号来满足不同配置要求的用户,分别是Large(超大杯)、Large-Turbo(大杯)和Medium(中杯)。
https://huggingface.co/collections/stabilityai/stable-diffusion-35-671785cca799084f71fa2838
这三个都是开源的,并且large和large turbo都可以在线尝试,大家可以根据自己的配置要求进行下载
下载sd3.5_large.safetensors,太久没下载的小伙伴别下错了。
和大部分生成式模型一样,SD3.5带来了更优秀的图像质量、细节表现和文字呈现能力。

图片来源:https://civitai.com/images/36552442
在之前我写过几篇文章讲述Flux,在那个时候我将FLUX和之前的Stable Diffusion比作当今最强和史上最强。
其实这两者之间谁更加“厉害”的讨论也没停止过,目前FLUX(Dev)被认为是开源范围内最先进的模型。
人家Stability AI官网自己放出的数据报告提到,SD3.5 Large版本审美评分比Flux.1(dev)要稍微低一些(有些讨论区的小伙伴觉得SD3.5的审美更好些),但是提示词忠诚度(看得懂人话)要更优秀。
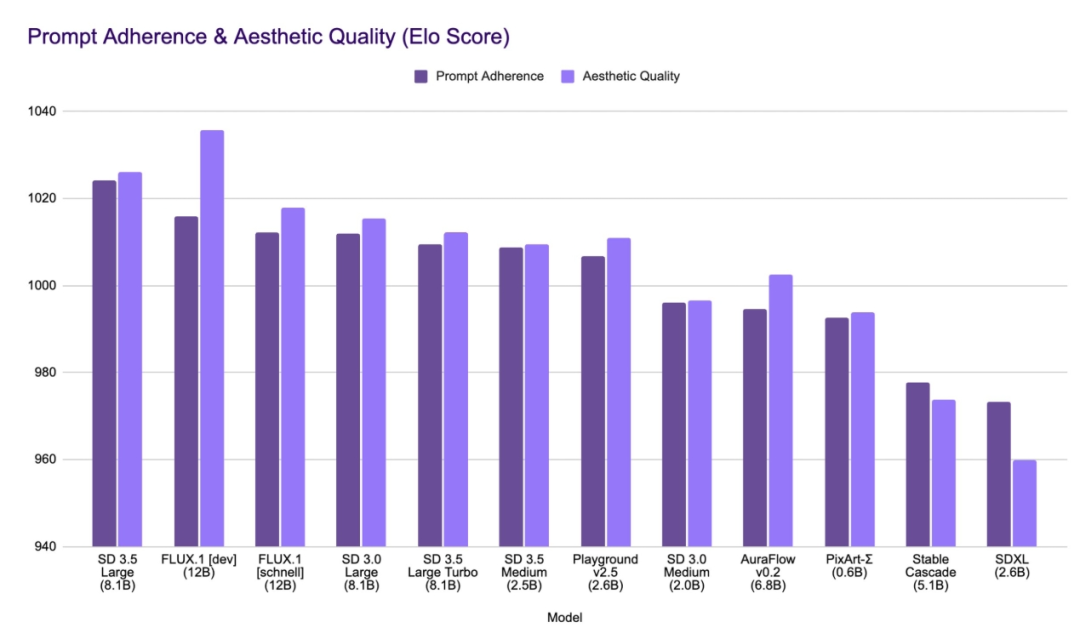
不过这些是官方给的数据信息,具体怎么样还是需要小伙伴们自己尝试一下看看。根据我所学习的原视频up提到,单论基础模型素质,Flux可能略微厉害点。
因为他认为在生成图像中让AI写字还蛮能考验一个模型的综合指标,用SD3.5 Large生成正确文字所需的生成次数大部分情况下要略多于Flux(dev)。
还有一点就是Flux是支持200万像素以下的,但是SD3.5的官方推荐生成尺寸在100万像素附近(Medium可以更大一些)。
当然SD3.5也是有优点的,首先是配置需求比起FLUX要低了不少。用Large生成图片约需要20G显存,而Medium则需要14-16G,量化后的SD3.5 Medium甚至只需要12G左右。
除此之外SD3.5或许要比FLUX更好“炼”一些,之前的笔记中有提到过FLUX dev像是一个“引导蒸馏”模型,而这样做是为了让AI的推理变得更加高效。
不过这样的模型也会有副作用,那就是许多训练者表示FLUX在一些使用大规模数据集进行微调时的效果并不是很好,因此基于FLUX.1 Dev微调出来的Checkpoint并不多。
其实也不少,只不过是对比SD来说比较少
而SD3.5会更适用于大规模的训练,对于我这样喜欢上网找大佬抄作业的用户来说,这也意味着模型会越来越丰富且更完善。
当然还有一点没有提及,那就是Flux Dev型号采用的是非商业的许可证,这意味着所有基于FLUX.1 Dev微调出来的模型都是带着“非商业”的属性,企业级用户就没法去微调使用了。
SD3.5则提供了一个更宽松的许可,非商业用途完全不受限制:

对于大部分用户来说,现在的SD3.5可以被看作是一个免费可商用的模型,这样围绕SD3.5去做的开发和应用也可能会更多。
这样看来,SD3.5的出现或将带来新的AI生态环境。
今天的内容就到这里啦,后续会用2-3篇笔记的量来介绍分享一下SD3.5的使用以及后续应用。
希望小伙伴们先根据自己的硬件条件事先下载好Stable Diffusion3.5模型,我就先去看看会不会遇到啥报错以及如何解决。
记得先下载好ComfyUI,因为目前SD3.5的首选还是ComfyUI。
大伙下篇笔记见啦,拜了个拜!

图片来源:https://civitai.com/images/38147317
生成模型:Stable Diffusion 3.5 Large
Prompt: Cinematic style, realism, cinematic quality, Pastel, a young women half portrait,She is looking in disbelieve as her face is disintegrating into fractals which are dominant on one half of her face so that no skin is visible anymore only colorful crystal like looking mathematical and colorful fractals. The fractals are also waving over the other half of her face, getting slightly weaker and less pronounced, fading out.
The background is misterious blue with shining stars.
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









