







Generative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
代码:https://github.com/ltp1995/GPVL
论文:https://arxiv.org/abs/2501.08861
GPVL(Generative Planning with 3D-vision Language Pre-training)是一种端到端自动驾驶模型,旨在解决现有视觉基础模型在视觉理解、决策推理和场景泛化方面的挑战。
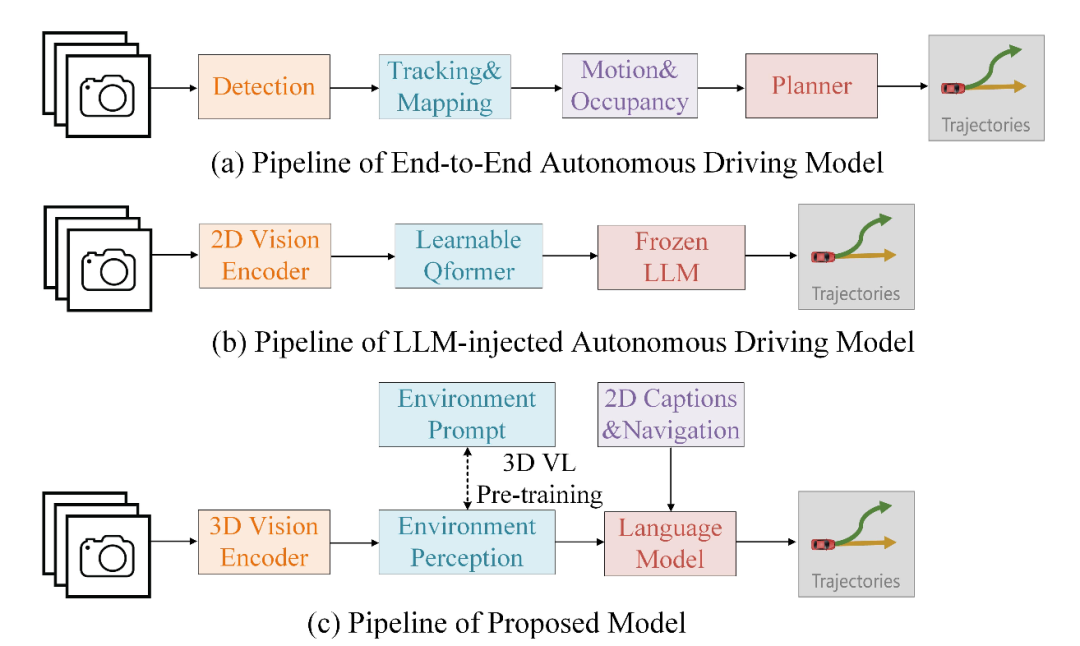
GPVL 模型通过3D视觉语言预训练模块,将视觉感知与语言理解相结合,实现了对驾驶环境的全面理解和推理。该模型还引入了跨模态语言模型,以自回归的方式生成整体驾驶决策和精细轨迹,从而提高了自动驾驶系统的安全性和效率。
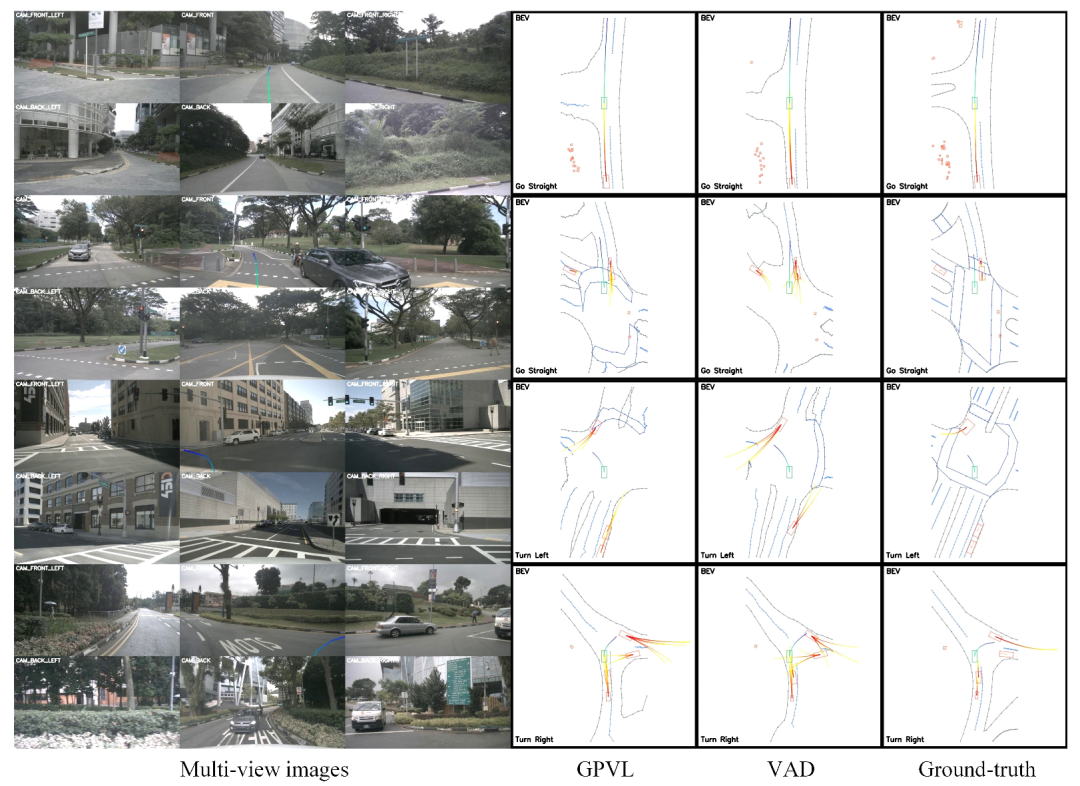
GPVL 在nuScenes数据集上的实验结果表明,其在轨迹预测的准确性和避免碰撞方面显著优于现有方法,并且具备强大的泛化能力和实时性能,显示出在实际应用中的潜力。
技术解读
本研究提出了一种名为GPVL的端到端自动驾驶模型,旨在通过3D视觉语言预训练和跨模态语言模型,提升自动驾驶系统在复杂环境下的感知、决策和轨迹规划能力。其设计思路是利用预训练的BEVformer提取多视图图像的鸟瞰图特征,结合向量化检测、运动和映射变换器学习关键感知信息,并通过3D视觉语言预训练模块对齐视觉特征与语言表示,实现全面的3D场景理解和文本推理。然后,利用跨模态语言模型基于对齐的特征和导航指令,以自回归方式生成整体驾驶决策和精细轨迹。
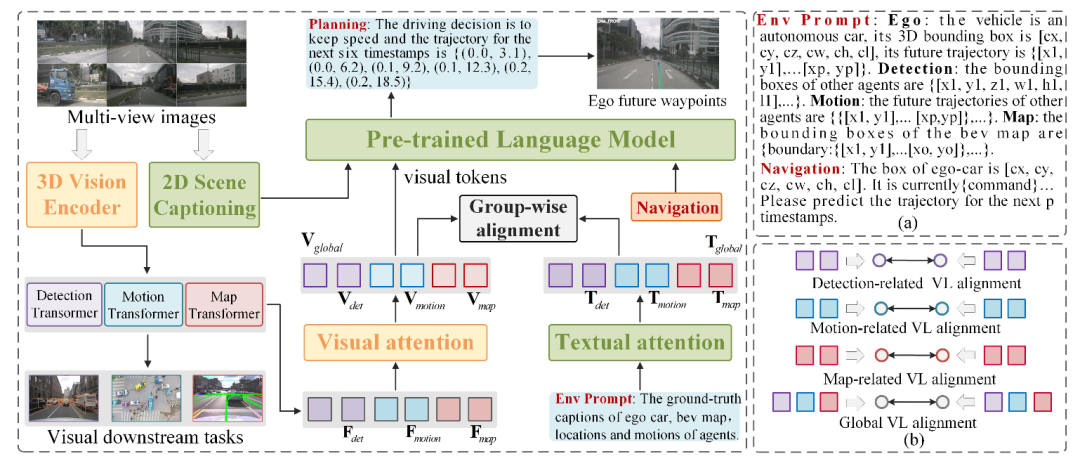
在处理过程中,GPVL首先使用BEVformer提取多视图图像的BEV特征图,涵盖驾驶场景中的关键语义元素。接着,通过向量化检测、运动和映射变换器学习关键感知信息,并利用3D视觉语言预训练模块对齐BEV特征与语言表示,建立多级关联。此外,基于预训练的BLIP设计的2D场景描述模型生成场景级描述,这些描述与对齐的3D感知特征和导航指令一起输入到跨模态语言模型中,以自回归方式生成驾驶决策和轨迹。
GPVL 的技术特点主要包括:1) 3D视觉语言预训练模块能够建立视觉与语言特征之间的组内关联,促进对驾驶环境的全面理解;2) 跨模态语言模型具备自回归生成能力,能够生成合理的驾驶决策和轨迹;3) 在nuScenes数据集上的实验表明,GPVL在轨迹预测的准确性和避免碰撞方面显著优于现有方法,同时具备强大的泛化能力和实时性能。
GPVL 能够显著提升自动驾驶系统的安全性和效率,通过创新的3D视觉语言预训练和跨模态语言模型,为端到端自动驾驶提供了一种新的解决方案。其在复杂驾驶场景下的出色表现和强大的泛化能力,使其在实际应用中具有广阔的前景,有望推动更安全、更可靠的自动驾驶技术的发展。
论文解读
这篇论文提出了一种名为GPVL(Generative Planning with 3D-vision Language Pre-training)的端到端自动驾驶模型,旨在解决现有视觉基础模型在视觉理解、决策推理和场景泛化方面的挑战。论文内容要点概括如下:
背景知识
-
自动驾驶需要车辆能够感知并理解周围环境以进行安全的轨迹规划。
-
现有的端到端模型虽然取得了一定成果,但仍面临视觉理解、决策推理和场景泛化的挑战。
研究方法
-
GPVL模型:包含两个主要部分,3D视觉语言预训练模块和跨模态语言模型。
-
3D视觉语言预训练模块:利用预训练的BEVformer提取多视图图像的BEV特征图,涵盖驾驶场景的关键语义元素。通过向量化检测、运动和映射变换器学习关键感知信息,并开发3D视觉语言预训练模块来对齐BEV特征与语言表示,实现全面的3D场景理解和文本推理。
-
跨模态语言模型:基于预训练的BLIP设计了一个2D场景描述模型,用于生成场景级描述。然后,将2D视觉描述、对齐的3D感知特征和导航指令输入到语言模型中,以自回归的方式生成整体驾驶决策和精细轨迹。
实验
-
数据集:在nuScenes数据集上进行实验,该数据集包含1000个交通场景,每个视频约20秒,提供超过140万个3D边界框,涵盖23个不同对象类别。
-
评估指标:使用位移误差(L2)和碰撞率(Collision)来评估规划结果,同时引入延迟和FPS指标来评估模型的实时性能。
关键结论
-
性能对比:GPVL在L2距离度量上获得最低分数,与VAD相比,在1秒、2秒、3秒和平均情况下分别减少了0.18米、0.28米、0.34米和0.27米的规划位移误差,显示出轨迹预测的优越准确性。在碰撞率方面,GPVL在大多数指标上表现最佳,突出了其在避免碰撞方面的卓越安全性和稳健性。
-
实时性能:GPVL的延迟为188.7毫秒,推理速度为5.3fps,显示出实际应用的潜力。
-
泛化能力:在nuScenes数据集中,87.7%的训练样本和88.2%的验证样本是简单的直行场景,导致UniAD和VAD更容易过拟合和学习捷径,而在更复杂的转弯场景中表现不佳。相比之下,GPVL在所有场景中都获得了良好的结果,显示出在多样化驾驶情况下的强大泛化能力。
-
定性结果:GPVL生成的规划结果与VAD和真实情况相比,显示出准确和合理的轨迹。例如,在直行指令下,GPVL生成的轨迹引导车辆安全通过城市道路,而VAD的轨迹存在与路边碰撞的风险。
消融研究
- 关键组件贡献:消融研究系统地调查了GPVL的关键组件对nuScenes数据集的贡献。没有感知模块,GPVL在检测前景对象、预测运动和构建地图方面表现不佳,导致L2和碰撞分数较高。禁用VLP(3D视觉语言预训练)和GA(组内对齐)组件显著降低了性能,突出了模型在连接视觉和语言理解方面的能力。缺少GA导致性能明显下降,表明其在细粒度特征关联方面的重要性。排除CLM(跨模态语言模型)增加了L2和碰撞分数,强调了其在生成合理规划决策方面的作用。所有模块的集成产生了最佳性能,展示了组合系统的协同效应。
零样本泛化
-
不同城市环境:为了验证模型的泛化能力,作者在两个不同城市环境(波士顿和新加坡)构建的数据集上训练和测试模型。实验结果表明,GPVL在两个组的评估分数明显优于UniAD和VAD。
-
鲁棒性测试:为了验证GPVL的鲁棒性,作者在测试图像中引入了四种噪声(雨、雾、雪和黑暗),这些噪声条件对UniAD和VAD产生了显著的负面影响,而对GPVL的影响较小。因此,GPVL在各种真实世界场景中的出色表现证明了其提高自动驾驶系统鲁棒性和安全性的能力。
结论
文章提出了一种新颖的端到端自动驾驶的生成规划模型GPVL,该模型通过3D视觉语言预训练模块整合文本信息,建立丰富的3D视觉语言关系,并利用组内对齐来利用不同表示之间的多级关联,促进对驾驶场景的更好理解和推理。跨模态语言模型作为生成引擎,利用对齐的特征和导航以自回归方式产生未来轨迹。这种生成风格使模型能够像自然语言建模一样做出正确的决策。GPVL构建了一个统一框架,不仅能够进行可靠的规划,而且在各种驾驶场景中展现出卓越的泛化能力。在nuScenes数据集上的广泛实验表明,GPVL显著优于现有方法。未来的工作期望GPVL能够推动更安全、更可靠的自动驾驶技术的发展。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









