






前言
正则表达式,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配符功能是用来处理文件名,而正则表达式是处理文本内容中字符。
主要用来匹配字符串(命令结果/文本内容)
正则表达式分为基本正则表达式和扩展正则表达式。
元字符
| 表达式 | 含义 |
|---|---|
| .(点) | 匹配任意单个字符,可以是一个汉字 |
| [ ] | 匹配指定范围内的任意单个字符,示例[0-9] |
| [^] | 匹配指定范围外的任意单个字符,示例[^geng] |
| [:alnum:] | 字母和数字 |
| [:alpha:] | 代表任何英文大小写字符,亦即 A-Z, a-z |
| [:lower:] | 小写字母,示例:[[:lower:]],相当于[a-z] |
| [:upper:] | 大写字母 |
| [:blank:] | 空白字符(空格和制表符) |
| [:space:] | 包括空格、制表符 (水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 |
| [:cntrl:] | 不可打印的控制字符(退格、删除…) |
| [:digit:] | 十进制数字 |
| [:xdigit:] | 十六进制数字 |
| [:graph:] | 可打印的非空白字符 |
| [:print:] | 可打印字符 |
| [:punct:] | 标点符号 |
\w #匹配单词构成部分,等价于[[:alnum:]]
\W #匹配非单词构成部分,等价于[^[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]
元字符(.)
这边的点代表字符
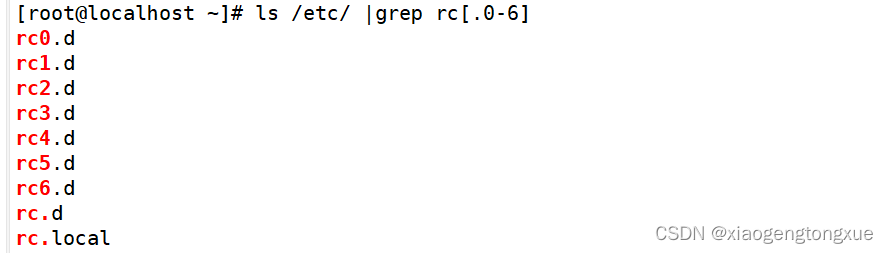
这边加转义和不加转义是两个意思,注意grep最好加引号将需要查找的字符框起来。
第一个点代表一个字符
第二就代表单纯的点
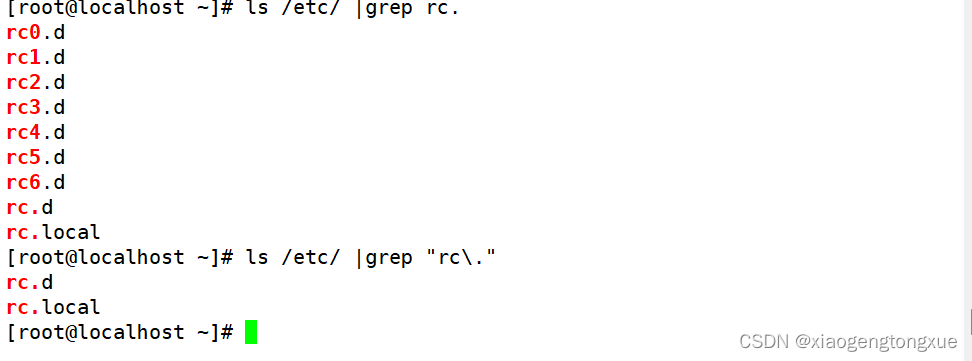
通配符的[a-d] 与正则表达式的[a-d]是不一样的。

通配符中[a-d]包含大写字母,请特别注意。
表示次数
| 字符 | 含义 |
|---|---|
| * | 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 |
| .* | 任意长度的任意字符 不包括0次 |
| \ ? | 匹配其前面的字符出现0次或1次,即:可有可无 |
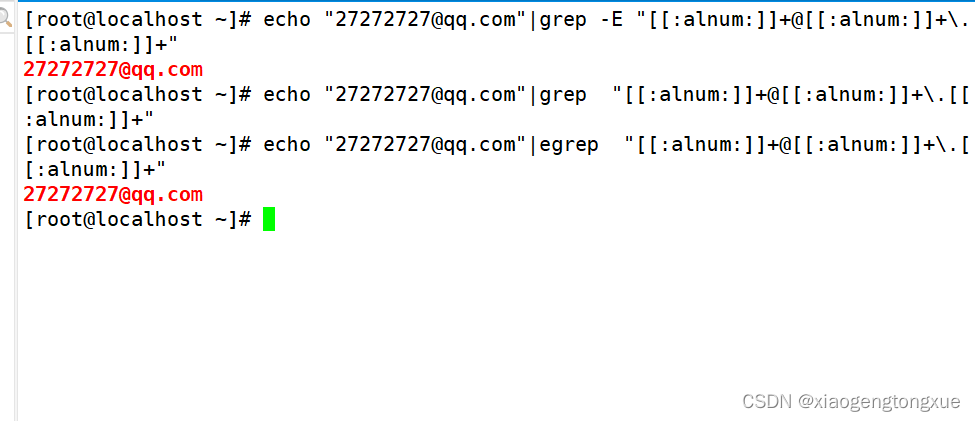
| \+ | 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次 |
| \{n\} | 匹配前面的字符n次 |
| \{m,n\} | 匹配前面的字符至少m次,至多n次 |
| \{,n\} | 匹配前面的字符至多n次,<=n |
| \{n,\} | 匹配前面的字符至少n次 |
注意:运用基本正则表达式时,需要运用转义符。
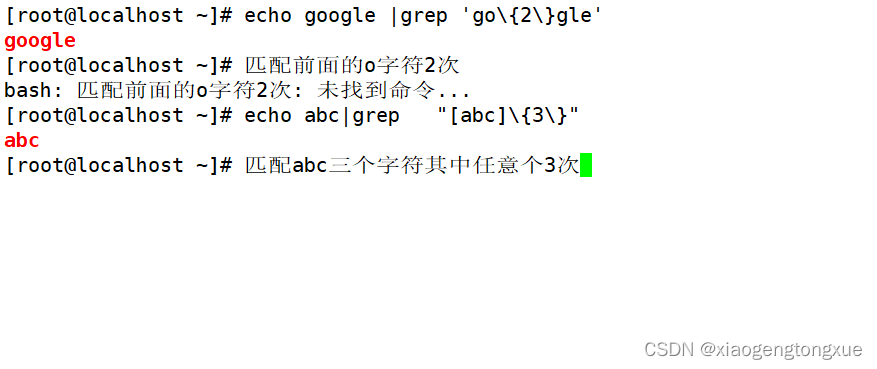
位置锚定
| 字符 | 含义 |
|---|---|
| ^ | 行首锚定, 用于模式的最左侧 |
| $ | 行尾锚定,用于模式的最右侧 |
| ^PATTERN$ | 用于模式匹配整行 |
| ^$ | 空行 |
| ^[[:space:]]*$ | 空白行 |
| < 或 \b | 词首锚定,用于单词模式的左侧 |
| > 或 \b | 词尾锚定,用于单词模式的右侧 |
| <PATTERN> | 匹配整个单词 |

分组或者其他
分组:用()将多个字符捆绑在一起,当作一个整体处理,如:(abc)
或者 :|
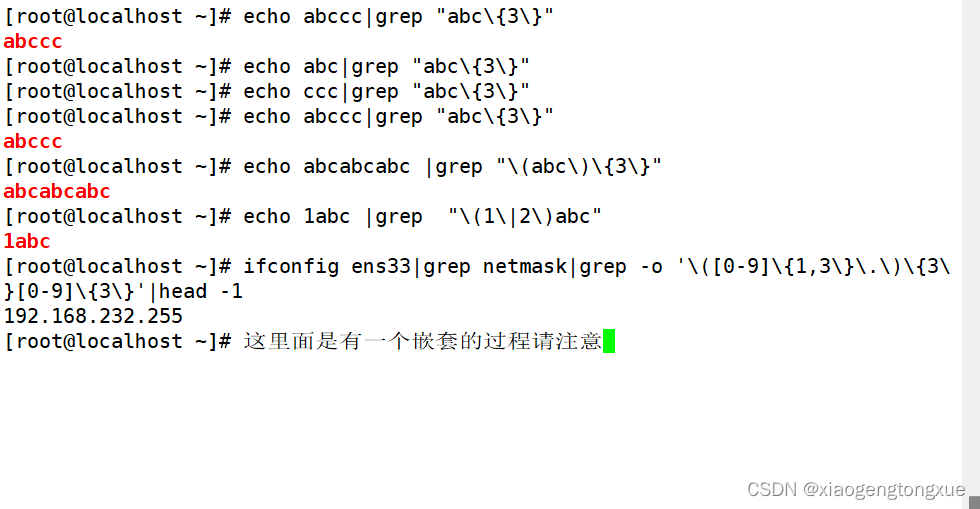
扩展正则表达式
grep -E
注意:与之前的正则表达式几乎没有差别,就是没有转义字符
| 字符 | 含义 |
|---|---|
| * | 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 |
| ? | 匹配其前面的字符出现0次或1次,即:可有可无 |
| + | 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次 |
| {n} | 匹配前面的字符n次 |
| {m,n} | 匹配前面的字符至少m次,至多n次 |
| {,n} | 匹配前面的字符至多n次,<=n |
| {n,} | 匹配前面的字符至少n次 |















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









