







以驱动方式测试dma的工作原理,用户层程序不停调用ioctl触发驱动里面完成的dma操作,把内存的数据块从一个连续地址搬到另一个连续地址,然后用memcmp测试搬移后的数据和搬移前是不是完全一样。
简单的驱动代码:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/device.h>
#include <linux/fs.h>
#include <linux/mm.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <linux/interrupt.h>
#include <linux/irq.h>
#include <linux/gpio.h>
#include <linux/sched.h>
#include <linux/wait.h>
#include <linux/poll.h>
#include <linux/input.h>
#include <linux/dma-mapping.h>
#include <asm/uaccess.h>
#include <asm/irq.h>
#include <asm/io.h>
#include <mach/regs-gpio.h>
#define MEM_CPY_NO_DMA 0
#define MEM_CPY_USE_DMA 1
#define DMA_BUF_SIZE (512*1024)
#define GRH_MODULE_NAME "grh_dma"
#define DMA_REG_BASE_ADDR_0 0x4B000000
#define DMA_REG_BASE_ADDR_1 0x4B000040
#define DMA_REG_BASE_ADDR_2 0x4B000080
#define DMA_REG_BASE_ADDR_3 0x4B0000C0
static struct dma_regs{
volatile unsigned long *disrc;
volatile unsigned long *disrcc;
volatile unsigned long *didst;
volatile unsigned long *didstc;
volatile unsigned long *dcon;
volatile unsigned long *dstat;
volatile unsigned long *dcsrc;
volatile unsigned long *dcdst;
volatile unsigned long *dmasktrig;
};
static struct dma_regs dma_regs_ins;
static int major = 0;
static char *src;
static char *dst;
static unsigned int src_phys; //数据源的物理地址
static unsigned int dst_phys; //目标位置的物理地址
static struct class *dma_class;
static struct class_device *dma_class_device;
//dma中断处理的相关数据
static DECLARE_WAIT_QUEUE_HEAD(dma_waitq); //休眠的进程队列头
static volatile int sleep_for_dma; //这个变量为0的时候ioctl函数会休眠,中断里面将其置1,read函数末尾将其设置为0
static int dma_ioctl(struct inode *inode, struct file *file, unsigned int cmd, unsigned long arg){
int i;
memset(src, 0xaa, DMA_BUF_SIZE);
memset(dst, 0x55, DMA_BUF_SIZE);
switch(cmd){
case MEM_CPY_NO_DMA:{
for(i=0; i<DMA_BUF_SIZE; i++)
dst[i] = src[i];
if(0 == memcmp(src, dst, DMA_BUF_SIZE))
printk(KERN_EMERG"dma success!\n");
else
printk(KERN_EMERG"dma fail!\n");
break;
}
case MEM_CPY_USE_DMA:{
*(dma_regs_ins.disrc) = src_phys; //将数据源的物理地址存入disrc寄存器
*(dma_regs_ins.disrcc) = (0<<0) | (0<<1); //源数据和目的位置是位于主存上的,设置dma的地址递增
*(dma_regs_ins.didst) = dst_phys; 将目标物理地址存入didst寄存器
*(dma_regs_ins.didstc) = (0<<0) | (0<<1) | (0<<2); //不使用自动加载,地址递增,目的地址是位于主存中的
*(dma_regs_ins.dcon) = (1<<30) | (1<<29) | (0<<28) | (1<<27) | (0<<23) | (0<<20) | (DMA_BUF_SIZE<<0); //使能中断,不使用突发传输,dma为软件触发,传输的最小单位是1字节
//启动dma
*(dma_regs_ins.dmasktrig) = (1<<1) | (1<<0);
//休眠进程
wait_event_interruptible(dma_waitq, sleep_for_dma);
sleep_for_dma = 0;
if(0 == memcmp(src, dst, DMA_BUF_SIZE))
printk(KERN_EMERG"dma success!\n");
else
printk(KERN_EMERG"dma fail!\n");
break;
}
}
return 0;
}
static struct file_operations dma_fops = {
.owner = THIS_MODULE,
.ioctl = dma_ioctl,
};
//dma中断处理函数
static irqreturn_t grh_handle_dma_int(int irq, void *dev_id){
printk(KERN_EMERG"dma interrupt happened!\n");
sleep_for_dma = 1;
wake_up_interruptible(&dma_waitq);
return IRQ_HANDLED;
}
static int dma_init(void){
unsigned long *p_start;
unsigned long **pp;
int i;
//分配dma使用的缓存空间
src = dma_alloc_writecombine(NULL, DMA_BUF_SIZE, &src_phys, GFP_KERNEL);
dst = dma_alloc_writecombine(NULL, DMA_BUF_SIZE, &dst_phys, GFP_KERNEL);
if(NULL==src){
printk(KERN_EMERG"allocate buffer for dma error!\n");
return -ENOMEM;
}
if(NULL==dst){
dma_free_writecombine(NULL, DMA_BUF_SIZE, src, src_phys);
printk(KERN_EMERG"allocate buffer for dma error!\n");
return -ENOMEM;
}
//进行地址映射
p_start = (unsigned long*)ioremap(DMA_REG_BASE_ADDR_0, sizeof(struct dma_regs));
pp = &(dma_regs_ins.disrc);
for(i=0; i<9; i++){
*(pp++) = p_start++;
}
//申请dma的中断
if(request_irq(IRQ_DMA0, grh_handle_dma_int, 0, "dma0", 1)){
printk(KERN_EMERG"request irq for dma error!\n");
return -ENOMEM;
}
//默认会等待dma进行休眠
sleep_for_dma = 0;
major = register_chrdev(0, GRH_MODULE_NAME, &dma_fops);
//create my own device class
dma_class = class_create(THIS_MODULE, "grh_dma_class");
//create my device of my own class
dma_class_device = device_create(dma_class, NULL, MKDEV(major,0), NULL, "grh_dma_device");
return 0;
}
static void dma_exit(void){
unregister_chrdev(major, GRH_MODULE_NAME);
device_unregister(dma_class_device);
class_destroy(dma_class);
iounmap(dma_regs_ins.disrc);
dma_free_writecombine(NULL, DMA_BUF_SIZE, src, src_phys);
dma_free_writecombine(NULL, DMA_BUF_SIZE, dst, dst_phys);
free_irq(IRQ_DMA0, 1); //释放dma中断
}
module_init(dma_init);
module_exit(dma_exit);
MODULE_AUTHOR("GRH");
MODULE_VERSION("1.0");
MODULE_DESCRIPTION("DMA DRIVER");
MODULE_LICENSE("GPL");//用户层测试程序
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <string.h>
#define MEM_CPY_NO_DMA 0
#define MEM_CPY_USE_DMA 1
void print_usage(const char *command){
printf("usage: %s <nodma|dma>\n", command);
}
int main(int argc, char *argv[]){
int count;
int fd;
fd = open("/dev/grh_dma_device", O_RDWR);
if(fd < 0){
printf("open device error!\n");
return -1;
}
if(2 != argc){
printf("command format error!\n");
print_usage(argv[0]);
return -1;
}
if(0 == strcmp(argv[1],"nodma")){
while(1){
ioctl(fd, MEM_CPY_NO_DMA);
}
}
else if(0 == strcmp(argv[1],"dma")){
while(1){
ioctl(fd, MEM_CPY_USE_DMA);
}
}
else{
printf("parameter error!\n");
print_usage(argv[0]);
return -1;
}
close(fd);
return 0;
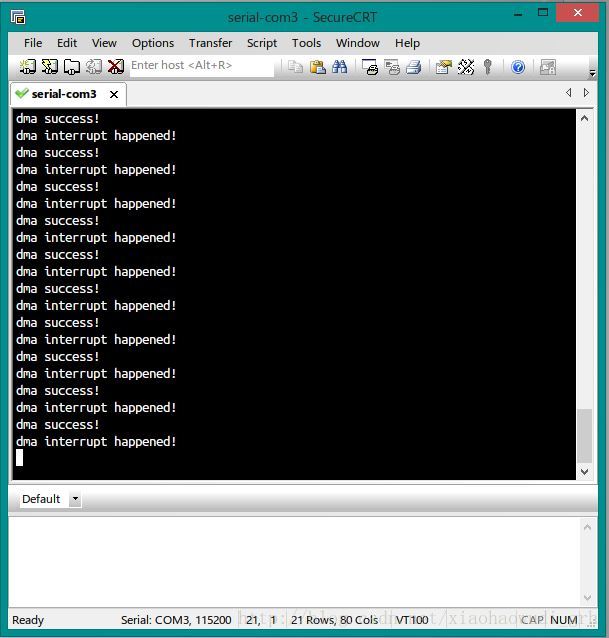
}运行结果:使用dma时和不使用dma时数据搬移的效率明显加快,cpu消耗量锐减,系统响应速度提升。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









