






回顾
在系列(一)中,我们从全局鸟瞰了RPC,其有三大特点:
具有需要约定调用语法
需要约定内容编码方式
需要网络传输
所有RPC框架都是在围绕这几个点不断优化,以更优的方案,达到更低的成本,更快的速度。要想达到这个目的,内容编码方式就是一个非常重要的点,RPC调用的request和response内容在调用过程中有着不小的消耗:
内容的序列化、反序列化,如果效率更高,则对CPU消耗会更小
内容会在网络中传输,协议栈拷贝成本、带宽成本、GC等。体积越小,效率越高
本文将围绕这两点展开讨论。
目标是什么
一般的低流量场景,无须多考虑这些,因为远不会打满cpu或触及带宽上限。但是在高流量的环境下,这个点就会变得非常致命,一波10W的qps可能会将带宽瞬间打满,然后直接堵住,cpu的消耗也需要更多的机器,这些都会直接拉高接口耗时。
背后都是高成本及稳定性的损失。
更常见的例子是,很多业务会将结果缓存起来到Redis,避免查DB,而有时结果集会很大,我目前听说过的最大value有500M。缓存数据存放时都需要序列化,常规的方式是json,但json序列化后的体积很大,对于大key是万万不行的,一波并发读取,Redis分分种CPU、带宽就吃紧了,此时就需要有一个更高效的序列化策略,使得value尽量小。
在这方面,RPC框架都有以下几个目标:
尽可能快地序列化、反序列化
序列化后的体积越小越好
跨语言,和语言无关
简单、类型明确
易扩展,可以简单的迭代,向后兼容
解决方案
gRPC对此的解决方案是丢弃json、xml这种传统策略,使用 Protocol Buffers[1],是Google开发的一种跨语言、跨平台、可扩展的用于序列化数据协议。
// XXXX.proto
service Test {
rpc HowRpcDefine (Request) returns (Response) ; // 定义一个RPC方法
}
message Request {
//类型 | 字段名字| 标号
int64 user_id = 1;
string name = 2;
}
message Response {
repeated int64 ids = 1; // repeated 表示数组
Value info = 2; // 可嵌套对象
map<int, Value> values = 3; // 可输出map映射
}
message Value {
bool is_man = 1;
int age = 2;
}
以上是一个使用样例,包含方法定义、入参、出参。可以看出有几个明确的特点:
有明确的类型,支持的类型有多种
每个field会有名字
每个field有一个数字标号,一般按顺序排列(下文编解码会用到这个点)
能表达数组、map映射等类型
通过嵌套message可以表达复杂的对象
方法、参数的定义落到一个.proto 文件中,依赖双方需要同时持有这个文件,并依此进行编解码
这可以满足RPC调用的需求,具体的使用语法此处不做赘述,详情可参考文档[2]。
作为一个以跨语言为目标的序列化方案,protobuf能做到一份.proto文件走天下,不管什么语言,都能以同一份proto文件作为约定,不用A语言写一份,B语言写一份,各个依赖的服务将proto文件原样拷贝一份即可。
但.proto文件并不是代码,不能执行,要想直接跨语言是不行的,必须得有对应语言的中间代码才行,中间代码要有以下能力:
将message转成对象,例如golang里是struct,Ruby里是class,需要各自表达后,才能被理解
需要有进行编解码的代码,能解码内容为自己语言的对象、能将对象编码为对应的数据
由于message是自己定义的,而且有特定的类型等,一套通用的编解码代码是不行的(类似json),特定的proto需要对应的方法,对message编解码,不同的message编解码策略还不一样。
这些代码用手写是不行的,protobuf对此的解决方案是,提供一个统一的protoc工具,这个一个C++”翻译“工具,可以通过proto文件,生成某特定语言的中间代码,实现上面说的两个能力。也就是说,protobuf通过自动化编译器的方式统一提供了这种能力,避免人肉写。
// 依赖目录 生成golang中间代码 对应proto文件地址
protoc -I=
S
R
C
D
I
R
−
−
g
o
o
u
t
=
SRC_DIR --go_out=
SRCDIR−−goout=DST_DIR
S
R
C
D
I
R
/
X
X
X
.
p
r
o
t
o
p
r
o
t
o
c
−
I
=
SRC_DIR/XXX.proto protoc -I=
SRCDIR/XXX.protoprotoc−I=SRC_DIR --java_out=$DST_DIR $SRC_DIR/XXX.proto // 生成java中间代码
执行结果是对应语言的中间代码,以golang为例,会生成一个xx.pb.go文件,里面就是对应rpc、message的结构体,以及编解码的function。[3]
由于每个field有标号,当proto文件新增字段、message、rpc时也能自然向后兼容,这涉及编解码的策略,下文会详细讨论。
直观对比
为什么选择protobuf,而不是普及最广的json作为编码方案? 可以做一个直观对比,以上文proto中的Response为例,一次输出json的结果是:
"{\"ids\":[123,456],\"info\":{\"is_man\":true,\"age\":20},\"values\":{\"110\":{\"is_man\":false,\"age\":18}}}"
所有内容被打包成了一个字符串,里面包含字段名、value,当Reponse很大时,体积消耗很大,浪费主要在三个方面:
字段名,例如上面的“ids”、“info”等,如果json体大,则重复会更多
数字用字符串表达了,例如123数字变成了“123”,这在编码后体积由一个字节变成三字节
类型字符,如[ 、 ]、{ 、}
但如果是protobuf呢? 输出是一段人眼无法理解的二进制串,里面:
去掉了字段名,转而以字段标号替代,通过标号可以在proto中找到字段名
没有类型字符等
用二进制表达内容,不会将数字转成字符串
字段值按顺序依次排列
这使得protobuf的编码结果体积,通常是json编码后的十分之一以下。同时由于排列简单,其解析算法的时空复杂度远小于json,对cpu消耗也小很多。这使得protobuf在大数据量、高频率的数据交互场景下,远胜于json,被大规模分布式RPC场景广泛使用。
编解码详解
为什么它能有这个好的压缩效果? 我们先从编码的角度来思考,如何对一个对象进行编解码。以json编码为例,当遇到下一个字段用,隔开就行,遇到下一层级用{表示,这样可以将内容依次铺开成一个完整的字符串。解析时按照{ , }等字符也能原样还原字段和层次结构。
但protobuf为了减小体积不能使用这些分隔符,抛几个问题:
它该怎么分隔字段、表达层次结构呢?
字段value一般分为两种,一种是定长的,例如一个int,它最多4个字节;第二种是变长的,如字符串,你不知道它在哪儿结束。该如何表示?
对于定长的int,如果对应值是1,那用4个字节表达是不是有些浪费,该如何节省?
对于此,protobuf将数据类型做了分类(Wire Type),并提供不同的编解码方式:
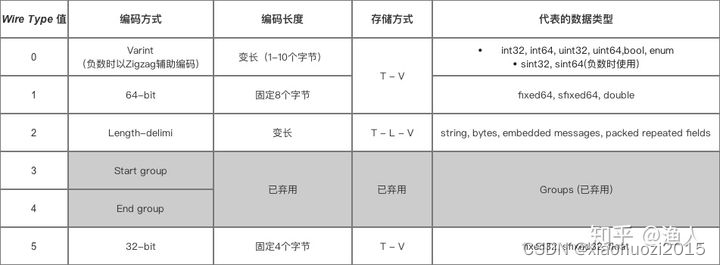
值得关注的有两种:
Varint,解决定长类型的空间浪费,例如值为1的int32只用1字节,避免用四字节,达到压缩的效果。 T - V
Length-delimi,用来表达长度不定的内容,如string、嵌套数据、数组。 T - L - V
T - V
T - V 的含义是:
T: tag,包含两部分数据: 对应字段的Wire Type(这可以知道是那种分类), 字段的数字标号(tagNum)(可以在proto中找到是哪个字段,这样就避开了传字段名)。其打包方式是: (tagNum<<3) | WireType
如果在proto中没有找到对应的tagNum则会跳过,这样提供了兼容能力
V: value, 对应字段的值,解析了T,就知道value表达的是哪个字段、什么类型、如何解析了
protobuf编码的结果就是一组组 T-V对依次紧凑排列,message有几个字段,就有几对。对于特定的RPC请求,proto中是有明确的请求、回复 message定义的,将T-V对去套对应的message,即可解析出对象。
紧接着上文预留的一个问题不可跳过,紧凑排列的T-V对,是如何进行分隔的?:
如何分隔 T 和 V,该从哪个解析V ?
如何分隔 T-V对,该从哪儿开始解析下一对?
T - V 对是一堆紧凑排列二进制串,里面没有分隔符,其解决方案是:
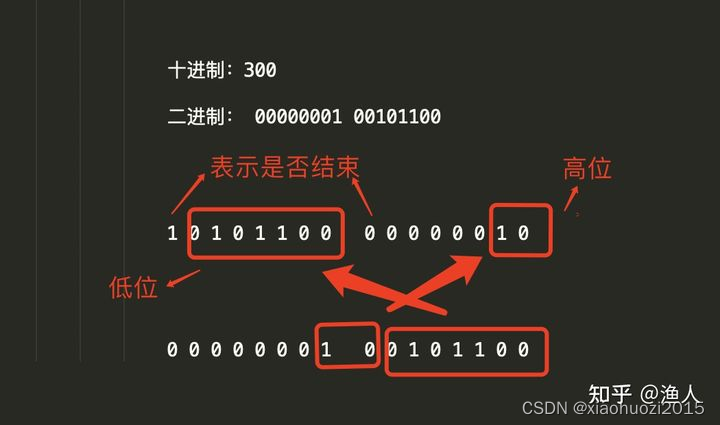
征用了每个字节的最高位,如果最高位是1,说明数据没解析完,下个字节还要继续解析,如果字节高位是0,说明当前T或V解析完了,下一个字节开始是其他的T或V
类小端排列,高位在➡️,低位左
小于 128 的数字 都可以用 1个字节 表示(用8个bit表达7个bit,一bit当作标志位)
大于 128 的数字,比如 300(00000001 00101100),会用两个字节来表示:10101100 00000010 (类小端)
T - V 编码举例:
message request {
int63 user_id = 1; // tagNum = 1, wireType = 0,
}
假设 value为 2, 则编码出的T-V为:
±----±–±----------------+
|00001|000|00000010|
±----±–±----------------+
tagNum type data
假设 value为 300, 则编码出的T-V为:
第一个字节 第二 第三
±----±–±----------------------+
|00001|000| 10101100 00000010| 下个T-V
±----±–±----------------------+
tagNum type data
Tag高位=0: 一个byte
data的第一个字节最高位为1,说明下一个字节还要继续读
T - L - V
T - L - V 就是在上面的基础上增加了length,用来表达变长的内容:

由于是变长,例如数组、嵌套对象,有多个value,此时就无法通过最高位是否是1,来表示该字段是否解析完毕,必须要在value前增加一个length,其他都和T-V一样。
接下来我们学习两个点:
数组如何表达
嵌套对象如何表达
数组的表达其实比较简单,就是同一个T不断的重复(tagNum和wireType不变),解析对应的V就行,然后组成一个数组:

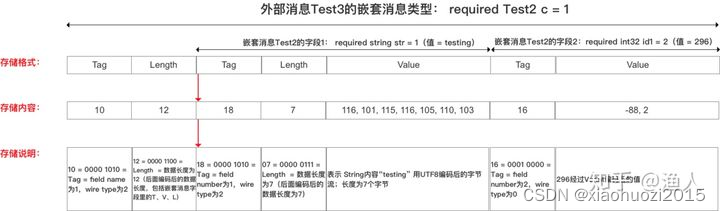
嵌套对象编码举例:
message request {
User user = 1; // tagNum = 1, wireType = 2,
}
message User {
int64 user_id = 1; // tagNum = 1
}
假设 request = { user_id: 2}, 则编码出的T-L-V为:
Tag length value
Tag value
±--------±-------±--------±--------
|00001010 |00000010|000010000|00000010|
1<<3 | 2 2 byte 1<<3 | 0 2
通过解request 知道第一个字段是User,再拿到第一个字段的value去解User,
知道User第一个字段是int64,解析出data为2。 一个嵌套对象即解析完毕
优缺点对比
全文到此,基本解释清楚了protobuf如何编解码,以及为什么压缩率会比json高,可以看出其优点有:
没有打包无用的数据,排列紧凑,体积小,利于传输
解析策略简单,序列化/反序列化 速度快
能较好的兼容字段(不能解析到的会跳过)
但缺点也非常明显:
肉眼看不出来value是什么,无法自描述, 难以debug
需要proto文件才能知道如何解析,否则是天书,这在灵活性上不如json
其实在本质上其差别在于:json的设计是给人看的,protobuf则是利于机器。
适用场景不同,各有利弊。作为工具,讨论其快、好、差没有意义,在合适的地方,用合适的工具即可。














 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









