







一、前言
这篇文章之前是给新人培训时用的,大家觉的挺好理解的,所以就分享出来,与大家一起学习。如果你学过一些python,想用它做些什么又没有方向,不妨试试完成下面几个案例。
二、环境准备
安装requests lxml beautifulsoup4 三个库(下面代码均在python3.5环境下通过测试)
pip install requests lxml beautifulsoup4
三、几个爬虫小案例
- 获取本机公网IP地址
- 利用百度搜索接口,编写url采集器
- 自动下载搜狗壁纸
- 自动填写调查问卷
- 获取公网代理IP,并判断是否能用、延迟
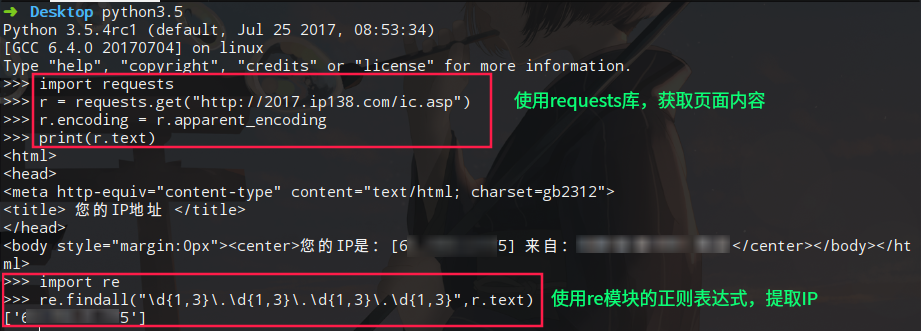
3.1 获取本机公网IP地址
利用公网上查询IP的借口,使用python的requests库,自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",r.text))
3.2 利用百度搜索接口,编写url采集器
这个案例中,我们要使用requests结合BeautifulSoup库来完成任务。我们要在程序中设置User-Agent头,绕过百度搜索引擎的反爬虫机制(你可以试试不加User-Agent头,看看能不能获取到数据)。注意观察百度搜索结构的URL链接规律,例如第一页的url链接参数pn=0,第二页的url链接参数pn=10…. 依次类推。这里,我们使用css选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









