









背景
客户侧要求支持中间件sqlproxy支持达梦数据库的主备切换,但这个主备切换功能在开发版本上并不支持,它是商业版才有的功能,为此只能详细研究文档说明,以珍惜成本高昂的试错机会。
主备切换配置文档
达梦官网关于主备切换的配置说明,

完整的说明文档参考:巧用服务名13.3节
相应的服务名配置说明:

完整的说明文档参考: 共享存储集群安装部署
与主备切换相关的关键参数说明:

初步测试
初步研读过以后,对dm_svc.conf文件按照如下想法做了配置:
- 节点列表中将主机193.108.99.55放在前面,99.25备机放在后面。
- 将EP_SELECTOR配置成1让优先选择最前面的节点,也就是主机。
- AUTO_RECONNECT配置成1用于连接异常后自动重连。
# 全局配置区
DMDW=(193.108.99.55:25236,193.168.99.25:25236)
TIME_ZONE=(+480) #表示+8:00时区
#DMDW 服务配置区
#当服务器故障后,以间隔2000毫秒的节奏尝试连接第一个节点3次,若连接成功则进行使用,若连接失败则连接下一个节点。
[DMDW]
SWITCH_TIMES=(3)
SWITCH_INTERVAL=(2000)
EP_SELECTOR=(1)
AUTO_RECONNECT=(1)
数据库连接串也相应的改为使用服务名进行配置。
dm://uc_uniform:uc_uniform@DMRW?svcConfPath=/etc/dm_svc.conf
结果刚重启sqlproxy,就报了如下错误试图在Standby模式下,修改用户库的错误,意思应该是连接到了备机,而备机权限受限,因此在执行一些SQL 写操作时报了此类错误。
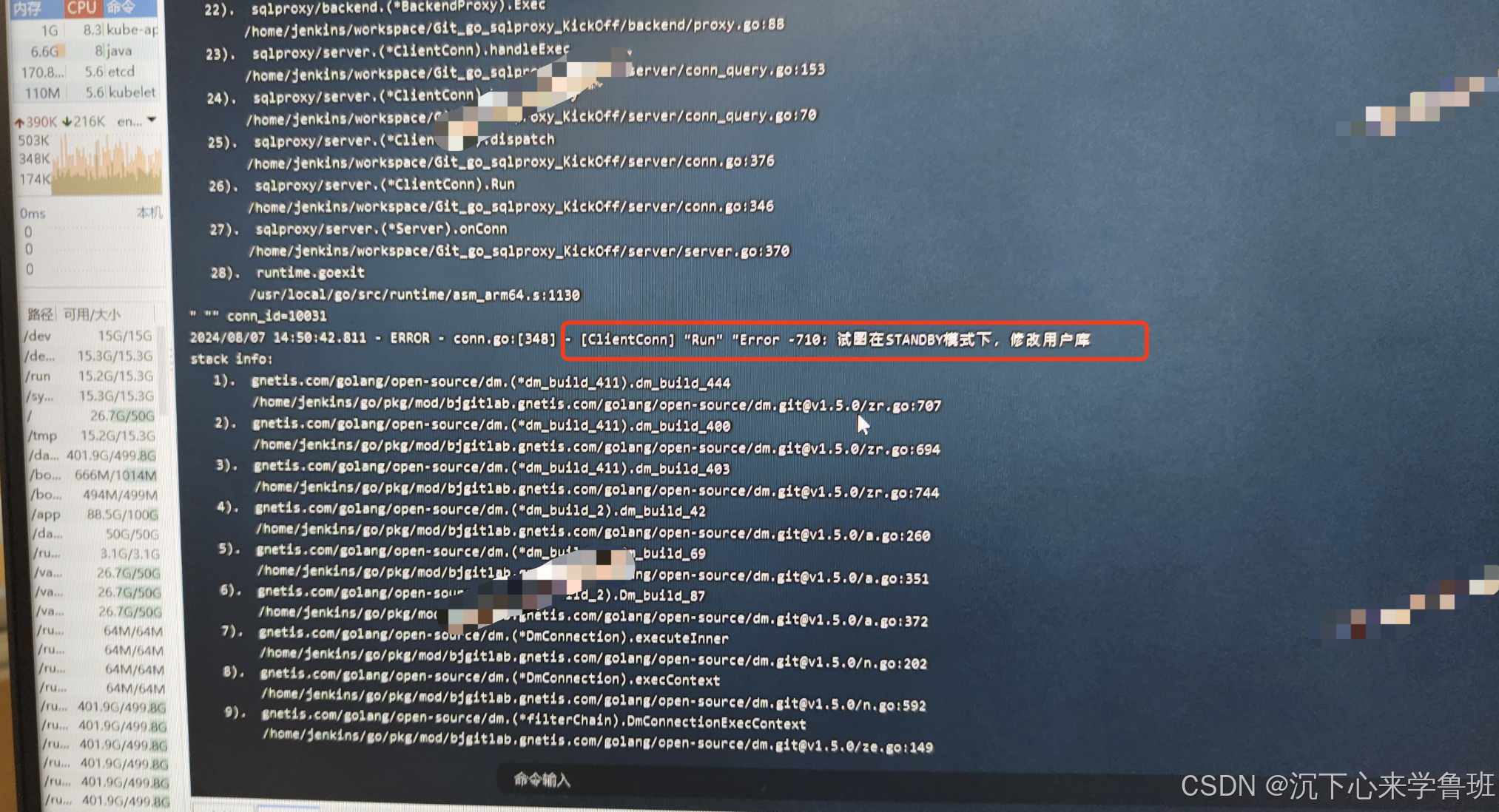
理论上按照参数说明,应该先连前面的主机,至于这里为什么会连到后面的备机,取决于达梦数据库驱动的实现是否与文档说明一致,这里未作深入探究。
既然不能连接到备机,那是不是可以强制连接主机?有一个login_mode配置项从文档上看起来是可以做到的。

加上login_mode后,相应的DRDW服务配置如下所示(前面的全局配置省略):
[DMDW]
SWITCH_TIMES=(3)
SWITCH_INTERVAL=(2000)
LOGIN_MODE=(1)
EP_SELECTOR=(1)
AUTO_RECONNECT=(1)
这次sqlproxy能够正常启动。
接下来进行了达梦数据库的主备切换,切换完后,数据库并不能正常连接,对外抛出的错误主要是Error 1105: driver: bad connection:

错误分析
主要分析sqlproxy日志:sys.log和sql.log。
从错误类型来看,有两类错误:
-
连接重置错误:应该是达梦驱动内部对异常连接进行自动重连后抛出,按照文档说明需要应用上层处理。
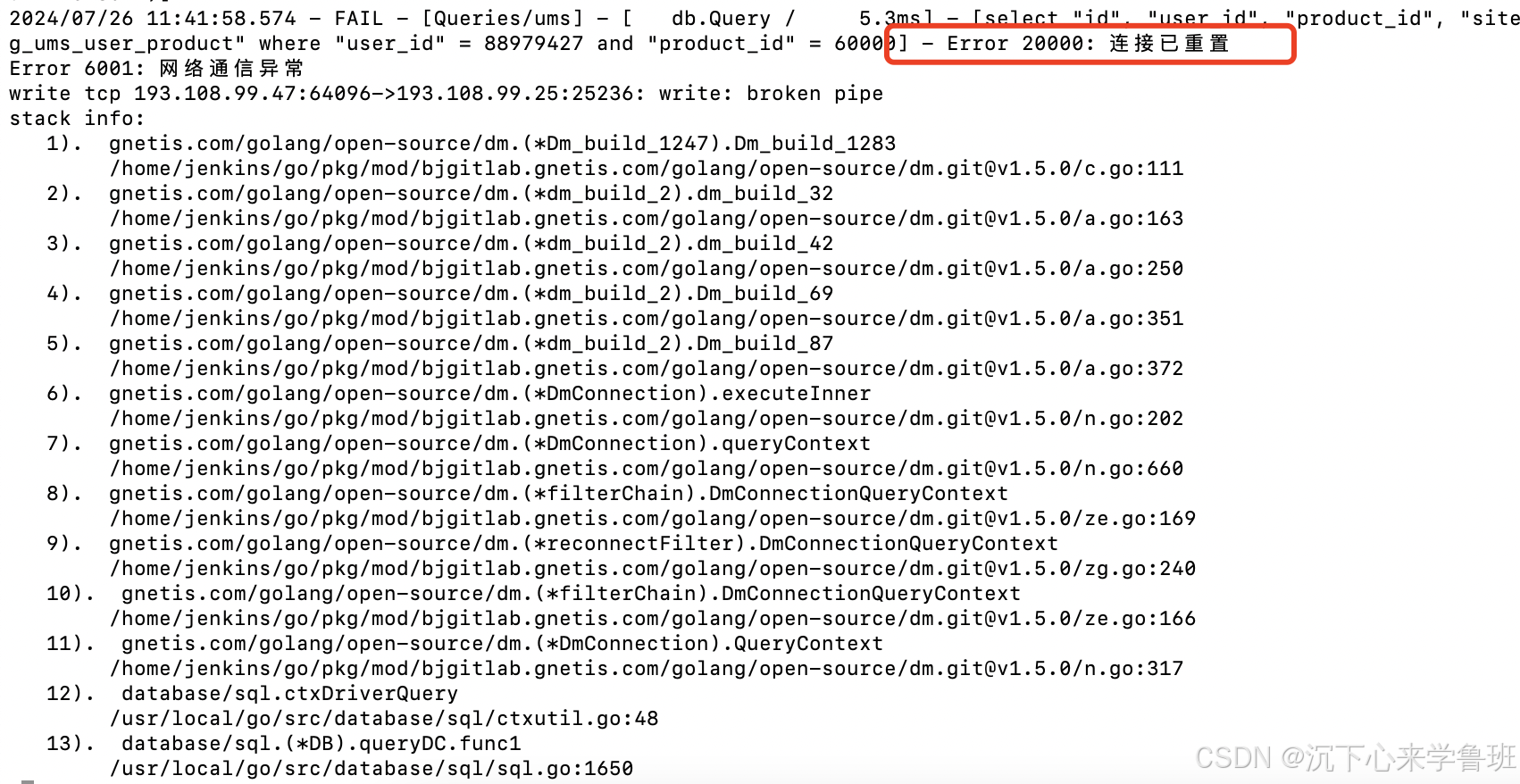
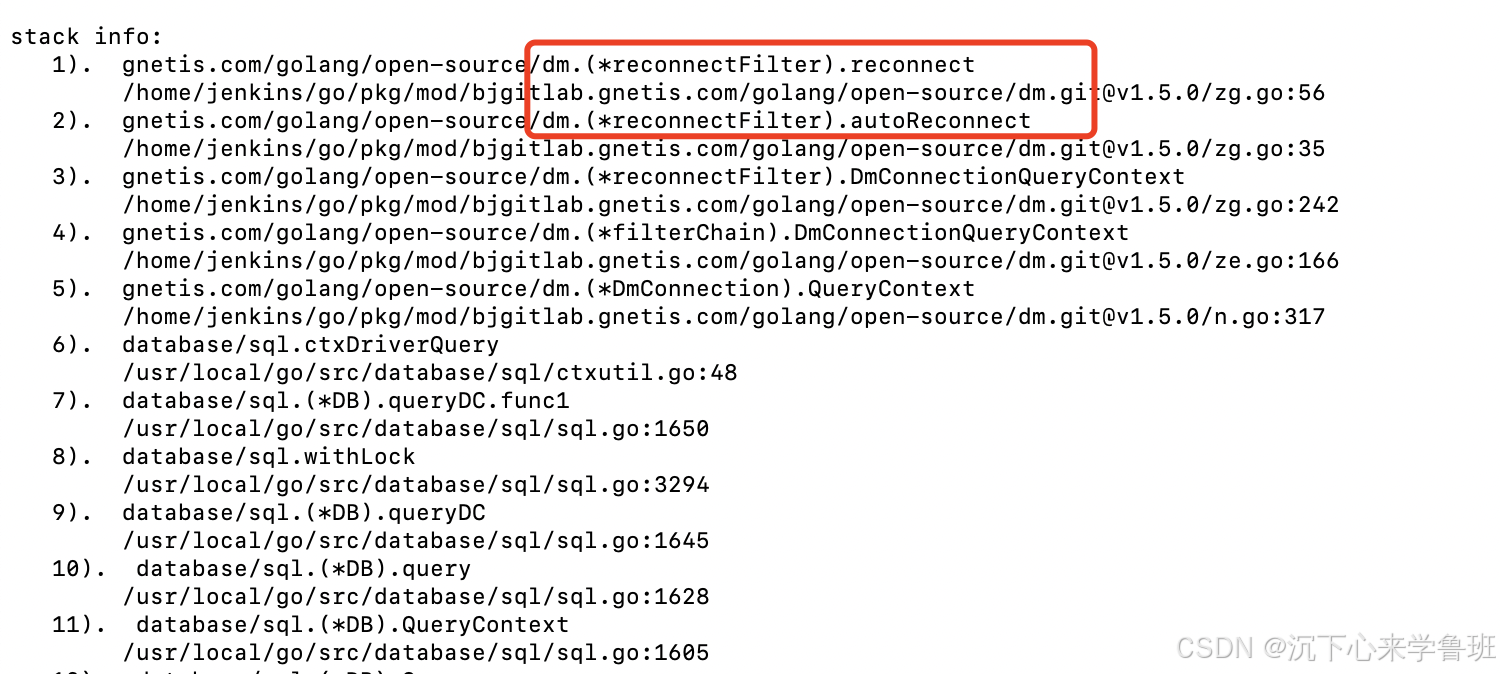
-
bad connection,就如同前面的截图所示,原因暂不清楚。
对于连接重置错误,理论上我们在连接池这一层忽略此错误,重连即可解决。
关键的问题是bad_connection这个错误,database/sql的连接池是支持对ErrBadConn进行自动重连的,go sdk官方代码逻辑如下截图所示。
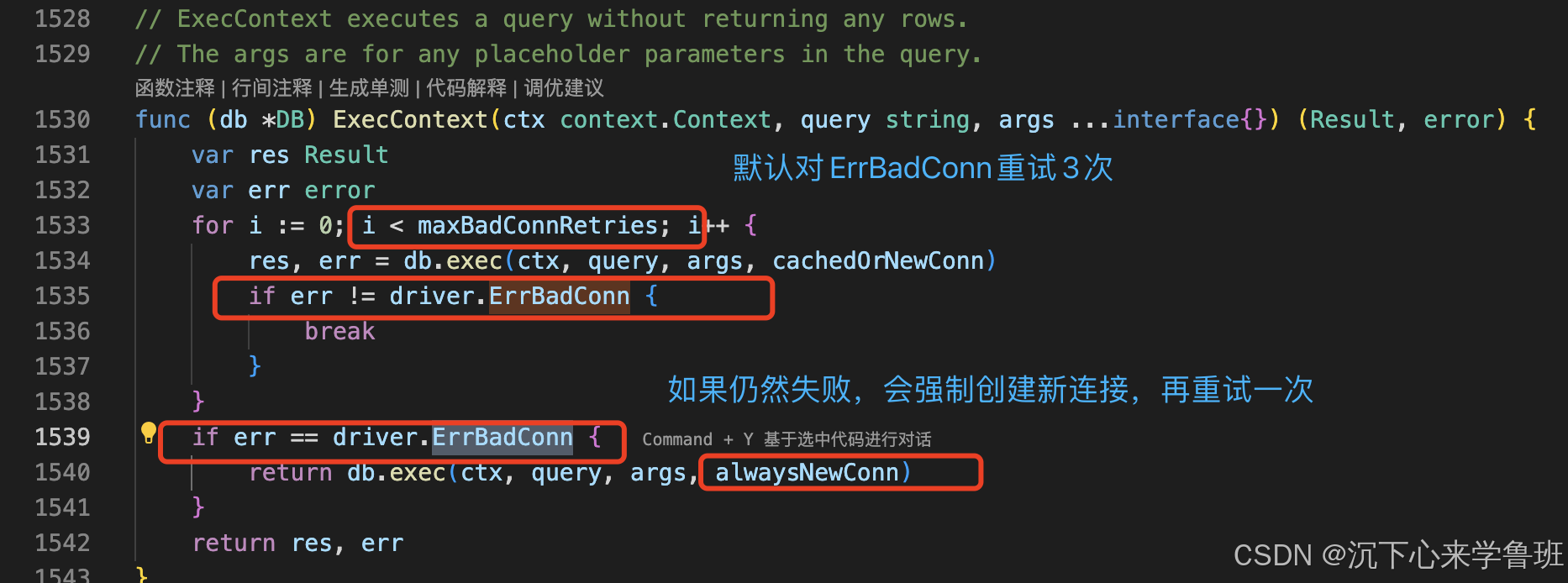
而bad connection通过自动重连未能修复,错误最终抛到了应用层,说明切换后的数据库无法连接,应该还是自动重连的配置或逻辑存在问题,需要进一步详细理解配置。
调试这类问题的难点可能就在于:驱动层的逻辑不是掌控在我们手里,包括驱动层的实现逻辑是否存在问题,我们也不得而知,我们能做的只是按照达梦的文档来不停的试参数。
配置详细理解
详细理解配置选项:
- LOGIN_DSC_CTRL=1 表示使用服务名连接数据库时只选择 DMDSC 主控节点(CONTROL NODE)的库,0:否;1:是。缺省值为 0。;
- EP_SELECTOR=N(N>=1)连接数据库时采用何种模型建立连接。
- 0:依次选取列表中的不同节点建立连接,使得所有连接均匀地分布在各个节点上(缺省值);
- 1: 表示使用服务名连接数据库时会选择“IP 地址和端口号”集合列表中最前面的节点建立连接,只有最前面节点无法建立连接时才会选择下一个节点进行连接(go版本SDK, Java SDK与此不同)。
- AUTO_RECONNECT:连接发生异常或一些特殊场景下连接处理策略
- 0:关闭连接(缺省值);
- 1:当连接发生异常时自动切换到其他库,无论切换成功还是失败都会抛一个 SQLException,用于通知上层应用进行事务执行失败时的相关处理。
- 2:配合 EP_SELECTOR>=1 使用,如果服务名列表前面的节点恢复了,将当前连接会自动切换回前面的节点上
- SWITCH_TIMES: 检测到数据库实例故障时,接口在服务器之间切换的次数;超过设置次数没有连接到有效数据库时,断开连接并报错。有效值范围 1~9223372036854775807,缺省值为 1, 官方建议3,。
- SWITCH_INTERVAL: 表示在服务器之间切换的时间间隔,单位为毫秒,缺省值为200.
- LOGIN_MODE: 指定优先登录的服务器模式,参考集群安装部署问题
- 0: 优先连接 PRIMARY 模式的库,NORMAL 模式次之,最后选择 STANTBY模式;
- 1: 表示只连主库, 官方建议在局部配置 LOGIN_MODE,不建议在全局配置 LOGIN_MODE。
- 2:只连接备库;
- 3:优先连接 STANDBY 模式的库,PRIMARY 模式次之,最后选择 NORMAL 模式;
- 4:优先连接 NORMAL 模式的库,PRIMARY 模式次之,最后选择 STANDBY 模式(缺省值)。
注:LOGIN_DSC_CTRL=1这个配置,看说明和login_mode=1有些相似,但实际试下来,没有什么作用。
注:有些配置在Java和go中的含义不完全一致,上面是在go驱动中的含义说明。
再来看我们配的这些参数:
[DMDW]
SWITCH_TIMES=(3)
SWITCH_INTERVAL=(2000)
LOGIN_MODE=(1)
EP_SELECTOR=(1)
AUTO_RECONNECT=(1)
- LOGIN_MODE=1: 控制着只连主节点,滤掉所有备机,是必要参数。
- SWITCH_TIMES和SWITCH_INTERVAL:只是控制着重连的次数和时间间隔,不会是bad connection的原因。
- EP_SELECTOR=1:此参数只是控制重连时节点选择的顺序,对于bad connection也不是决定因素
- AUTO_RECONNECT=1:此参数决定了是否会在驱动层进行重连。
但是,我们是否真的需要在驱动层进行连接的重连操作?
有此一问的原因在于:即使驱动层重连成功,它依然会向上抛一个连接重置错误,对于应用层来说处理此错误和处理bad connection error没有本质区别,除了重连重试其它什么都做不了。
是不是可以屏蔽掉驱动层的重连,将连接类问题都交给database/sql这一层的连接池来处理?
再次测试
基于上面思路,我们对配置和代码分别做了如下调整:
- 配置修改:dm_svc.conf中
去掉了重连相关的参数AUTO_RECONNECT和EP_SELECTOR,如下所示。
[DMRW]
LOGIN_MODE=(1) # 只连主机
SWITCH_TIMES=(3) # 以间隔2秒的节奏尝试连接第一个节点3次,如果连接失败再尝试下一个节点。
SWITCH_INTERVAL=(2000) # (间隔时间可能有点长,但应该不关键)
- 代码修改:对dm驱动进行了连接错误的归一,具体是将以下几类达梦驱动的自定义错误替换为标准连接错误ErrBadConn,目的是把连接类错误都交由连接池进行重试。
- ECGO_INVALID_CONN = newDmError(9008, “error.invalidConn”)
- ECGO_CONNECTION_SWITCH_FAILED = newDmError(20001, “error.connectionSwitchFailed”)
- ECGO_CONNECTION_SWITCHED = newDmError(20000, “error.connectionSwitched”)
- ECGO_COMMUNITION_ERROR = newDmError(6001, “error.communicationError”)
- ECGO_UNKOWN_NETWORK = newDmError(9007, “error.unkownNetWork”)
相关代码如下:
func replaceError(err error) error {
conn_errors := []*DmError{
ECGO_INVALID_CONN,
ECGO_UNKOWN_NETWORK,
ECGO_COMMUNITION_ERROR,
ECGO_CONNECTION_SWITCH_FAILED,
ECGO_CONNECTION_SWITCHED,
}
if isInErrors(err, conn_errors) {
log.Printf("use driver.ErrBadConn intread: %s", err.Error())
return driver.ErrBadConn
}
return err
}
此外,还对测试方法做了一个调整,进行分步验证。具体为:
- 先验证主备切换后disql命令行连接是否正常,目的是确保切换操作本身是正常的。
- 再验证主备切换后sqlproxy连接是否正常。
disql命令行响应主备切换操作的结果:
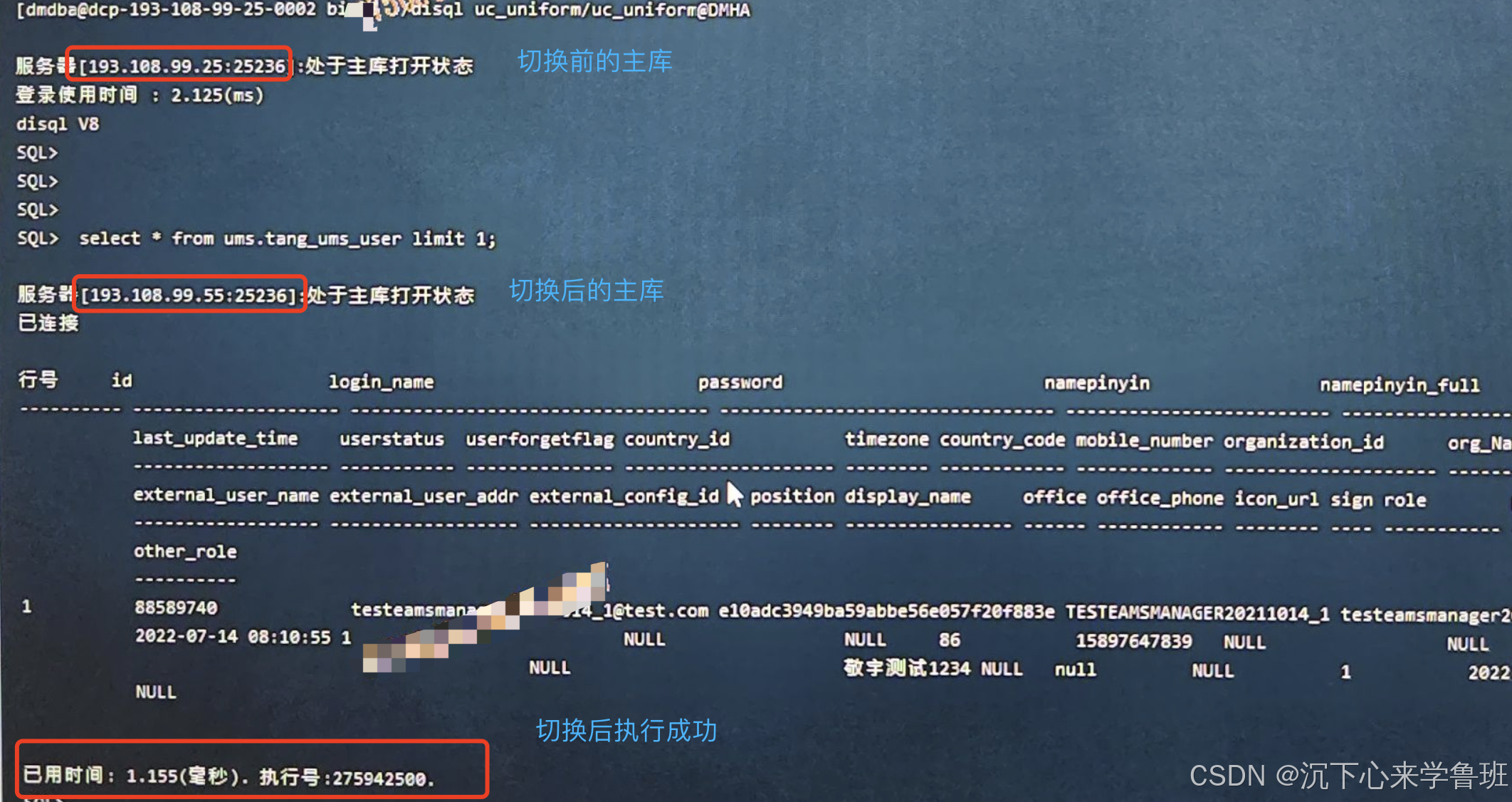
可以看到,disql命令行能正常感知主备切换,说明这个主备切换操作是正常完成的。
之后又针对sqlproxy进行了主备切换操作,意外的是:连接也正常感知了切换。
具体表现是:
- 应用客户端在切换后可以正常发起各种操作(未进行截图,正常交互可能无法用截图说明)
- sqlproxy上也未报前面的错误,包括bad connection error。
- 在控制台能看到旧连接的通信异常日志,以及达梦的通信错误替换为标准错误的记录。

至此,此问题最终用修改驱动的方式得到解决,基本思想是将连接类的错误都交给dataase/sql包里的连接池来处理,它内部会进行自动重试,这样上层应用不需要关心连接相关的异常。
达梦驱动有一些做法个人认为是不好的,包括:
- 把一些连接类错误声明成自定义的*DmError类型,导致标准连接池无法处理。
- 内部实现了AutoReconnect,却又抛出一个“连接重置错误”,对于使用标准连接池的应用来说,如何处理此错误呢?
为此,在达梦社区提了相关的贴子:遇到连接错误是否能返回官方的driver.ErrBadConn,而不是自定义的6001


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











