





论文翻译(2020回声消除挑战赛):ACOUSTIC ECHO CANCELLATION WITH THE DUAL-SIGNAL TRANSFORMATION LSTM NETWORK

文章地址:https://arxiv.org/pdf/2010.14337.pdf
摘要
本文将双信号变换LSTM网络(DTLN)应用于实时回声消除(AEC)任务中。DTLN结合了短时傅里叶变换和堆叠网络方法中的学习特征表示,这使得在时频和时域(也包括相位信息)中能够进行鲁棒的信息处理。该模型仅在60小时的真实和合成回波场景下训练。训练设置包括多语言语音、数据增强、附加噪声和混响,以创建一个模型,应该很好地适用于各种现实世界的条件。DTLN方法在纯净和有噪声的回波条件下产生了最先进的性能,可以鲁棒地减少回声和附加噪声。该方法在平均意见得分(MOS)方面优于AEC-Challenge基线0.30。
引言
在音视频通话中,如果说话人的声音被近端扬声器播放,并被近端麦克风接收,远端话者就会听到回声。。消除回声的一种标准方法是通过自适应滤波器(如归一化最小均方(NLMS)[1])估计扬声器到麦克风的房间脉冲响应,并用估计的脉冲响应对远端信号进行滤波。这个估计信号从近端麦克风信号中减去。这种方法在只有远端信号存在且没有近端语音时效果最好。在远端和近端语音的情况下,也称为双话场景,滤波器将不能正确收敛[2]。在这种情况下,通常使用双讲检测器暂停滤波器收敛。
最近,深度学习已被应用于声学回声消除,并取得了令人信服的结果[3,4,5,6]。有几种方法将神经网络和自适应滤波器结合在混合系统中[4,5,6]。从深度学习的角度来看,AEC任务可以看作是一个音源分离问题[3]。语音分离领域近年来发展迅速[7,8,9]。然而,扬声器分离模型往往集中在序列处理而不是因果实时处理。由于高延迟不是理想化结果,并且会增加语音通信的工作量,因此需要能够在帧基础上进行实时处理的系统。循环神经网络(RNN)如门控循环单元(GRU)[10]或长期短期记忆(LSTM)[11]网络通常用于具有实时性的模型。由于lstm和gru的单元结构具有门和状态,因此它们可以根据语音信号的需要在帧基础上对时间序列进行建模。RNNs已在[3,4,5]中应用于AEC问题。Interspeech 2020[12]的深度噪声抑制挑战表明,各种架构都可以应用于实时信号增强[13,14,15]。为了将AEC作为一个具有类似相关性的主题,提出了AEC挑战[16],其目的是提供一套公共的训练数据和基于 ITU P.808的客观评价体系以比较各种方法。
本文将dual-signal transformation LSTM网络[15]用于实时回声抵消(DTLN-aec)。原始的DTLN模型被证明,在在无回声,有混响和真实案例的盲测试集中可以鲁棒的降低噪声。它将短时傅里叶变换(STFT)与基于一维卷积层的学习特征表示结合在堆叠网络方法中。该模型基于时频域和学习特征域的比值掩蔽。由于这种设计选择,它可以利用到来自STFT的信息,以及学习到的特征信息。由于尚不清楚该方法是否有利于AEC,我们将该模型应用于此背景下,旨在构建一个直接的基于RNN的端到端AEC系统,该系统可以很容易地集成在常见的信号处理链中。对于这个新的应用程序,通过向每个模型块提供远端信号作为附加信息来扩展原始模型。这种扩展类似于[3]中所进行的过程,重要的区别是我们使用了因果LSTM而不是因果BLSTM。最近的论文表明,精心选择的训练设置和数据增强[18,19]对于实现高语音质量的语音增强至关重要。因此,本研究追求的第二个目标是通过广泛的数据增强来增加AEC的鲁棒性,以覆盖混响和多语言样本。
方法
问题公式化

对于声学回声抵消系统,通常有两个输入信号,近端麦克风信号y(n)和远端麦克风信号x(n)。近端麦克风信号可以描述为如下信号的组合:
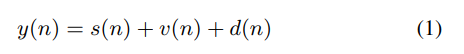
s(n):纯净近端语音
v(n):其他噪声
d(n):回声:是远端麦克风信号x(n)与传输路径h(n)的脉冲响应的卷积,该传输路径是由音频设备的缓冲所产生的系统延迟、扬声器与放大器结合的特性以及近端扬声器与近端麦克风之间的传递函数的组合
y(n):近端麦克风信号
s_hat(n):预估的纯净近端信号
适用于AEC的DTLN模型
该网络由两个核心块组成。每个块有两个LSTM层和一个全连接层,通过sigmoid激活函数来预测mask。输入特征为近端与远端麦克的归一化对数功率谱串联。每个麦克风信号通过 instant layer normalization单独归一化。 instant layer normalization类似于标准层标准化[20],其中每一帧都单独标准化,但不随时间累积统计数据。这个概念在[21]中被引入为通道层面的规范化。第一块预测了一个时频掩模,该掩模和近端麦克风信号的未归一化短时傅里叶幅度谱相乘,利用原始近端麦克风信号的相位,通过反FFT将估计的频谱幅度变换回时域。
第二个核心使用了通过1D-Conv层提取学习特征。这种方法受到[9,22]的启发。将先前预测信号的归一化特征表示和远端麦克风信号的归一化特征表示送到该块。为了将两个信号转换到时域,卷积层应用了相同的权值,但使用iLN的归一化是单独执行的,以便将每个信号的特征单独的缩放和偏差。将第二块的预测掩模与第一块输出的未归一化特征相乘。这种估计的特征通过一维卷积层后转换到时域。对于连续时间信号的重构,采用了重叠叠加的方法。模型体系结构如图2所示

选择帧长为32 ms,帧移为8 ms。FFT的大小为512,学习后的特征表示的大小也是512。由于从语音中去除语音和噪声具有相当大的挑战性,与[15]中较小的模型相比,我们选择了每层512个LSTM单元。这导致当前模型共有10.3M个参数。此外,训练每层128和256个单元的模型,以探索模型性能如何随参数大小而变化。
数据集准备
挑战提供了两个训练数据集,一个是合成数据,一个是真实记录。合成数据集来自为[12]创建的数据集。该数据集包含1万个示例,包含单端语音、双端语音、近端噪声、远端噪声和各种非线性失真情况,其中每个示例包含远端语音、回声信号、近端语音和近端麦克风信号。前500个来自说话者的例子,这些数据不包含在任何其他测试数据集中。这个数据集将用于评估,被称为双通话测试集。有关详细信息,请参阅描述AEC-Challenge[16]的论文。在训练中,只使用远端信号和回波信号,并将其分割成4 s的块。真实的数据集由不同的真实环境和不同的设备捕获的信号组成。关于该数据的详细信息在[16]中提供。和前面一样,只有远端信号和回波信号在这个数据集中以4秒为块使用。对于P. 808框架的评估,挑战组织者提供了盲测集。盲测试集由大约800个录音组成,分为一个干净的和嘈杂的子集。
从[23]采集的多语言数据中选择干净的语音作为近端信号。该数据集包含法语、德语、意大利语、普通话、英语、俄语和西班牙语。原始数据的各种来源在[23]中进行了描述。德国的数据因为质量差而被排除在外。将语音信号分割成4s长的样本。RMS小于或等于零的样本将被丢弃。舍入误差可能会导致RMS小于零。作为一种额外的排除噪声信号的机制,每个文件都由[15]中提出的语音增强模型进行处理,通过从噪声信号中减去估计的语音信号来估计语音信号和噪声信号。当信噪比低于5db时,语音文件将被丢弃。最后,从每种语言中选取20个小时来创建一个120小时的多语言语音数据集
为了覆盖回波场景中方差较大的噪声类型,我们使用[23]提供的噪声语料库。和之前一样,噪声文件被切割成4秒的样本,RMS小于或等于0的样本被丢弃。此外,添加了来自MUSAN语料库[24]的器乐(同样是在4 s分割之后)。这导致大约140小时的噪声
最后,利用为[25]采集的脉冲响应(IR)数据集,构建反映不同混响影响的真实回声场景。该数据集包含各种来源的真实脉冲响应,如[26,27,28],以及基于图像方法[29]的模拟脉冲响应。对于每个脉冲响应,直接路径的开始被识别并设置为[19]中建议的位置0。
训练数据以及数据增强
所有的训练样本都是在训练过程中在线创建的,没有使用近端语音、远端语音、噪声,脉冲响应的固定组合。总共使用60 h的回声数据,48 h进行训练,其余12 h进行训练验证。在训练中,使用挑战组织者提供的所有远端和回声信号(大约32小时的数据)。为了创建额外的回声数据,从先前创建的多语言数据集中使用28小时的语音。每个语音文件与一个随机选择的IR卷积,每个IR除以第一个样本的绝对值。在下一步中,除第一个样本外的所有样本都乘以一个从-25到0之间的均匀分布中随机抽取的增益,以增强IRs。
在50%的情况下,噪声样本的信噪比是随机从均值为5 dB、标准差为10 dB的正态分布中随机抽取的,以解释噪声远端信号。为了创建回波信号,前面创建的远端信号被延迟一个10到100毫秒之间的随机值,以模拟处理和传输延迟。延迟信号用截止频率为100 ~ 400hz和截止频率为6000 ~ 7500 Hz的随机带通信号进行滤波。这一步引入了额外的方差,并模拟了设备内扬声器通常较差的声学传输特性,特别是在低频区域。最终将回波信号与近端信号进行相同的卷积。额外的非线性不包括在内,因为最初的挑战数据集已经涵盖了这方面
对于近端信号,使用来自多语言数据集的60小时。每个语音文件由随机选择的IR卷积,这是随机缩放为合成远端信号解释。对语音信号采用[18]提出的降噪随机谱整形以提高鲁棒性,并对各种传输效果进行建模。
在70%的情况下,在信噪比为5和标准差为10的正态分布的近端语音中加入噪声,以将焦点转移到更具挑战性的近端噪声条件。对噪声信号也分别进行随机谱整形
在5%的情况下,随机持续时间的近端语音片段被丢弃,以说明仅远端场景。在90%的情况下,回波信号被添加到近端语音,语音-回波比取自平均值为0 dB、标准差为10 dB的正态分布。对回波信号和远端语音信号进行随机频谱整形。如果没有回波,则采用随机频谱整形将远端信号设置为零或在-70 ~ -120 dB RMS范围内的低噪声。作为模型输入的所有信号都受到一个随机增益的影响,从相对于截断点的-25到0 dB的均匀分布中选择一个随机增益
选取[30]中首次提出的时域信噪比损失作为代价函数。信噪比损耗是尺度相关的,这是实时应用的理想选择,因为它是在时域计算的,所以隐含地集成了相位信息。该模型使用Adam优化器[31]进行100个epoch的训练,初始学习速率为2e-4为512个LSTM单元,5e-4为256个单元,1e-3为128个单元。学习速率每两个epoch乘以0.98。梯度范数裁剪值为3。批次大小设置为16,样品长度设置为4 s。在连续的LSTM层之间,引入25%的dropout来减少过拟合。使用验证集对模型的每个历元进行评估。对验证集性能最好的模型进行了测试
Baseline systems
挑战组织者还提供了一个基于[32]的基准线。基线由两个GRU层和一个全连接的sigmoid激活网络组成,用于预测时频掩模。该模型将麦克风和远端信号的的短时对数功率谱串联起来,预测出适用于传声器信号短时傅立叶变换幅度的谱抑制掩模。利用麦克风信号的相位,将预测的幅度谱用STFT逆变换回时域。由于基线模型无法在挑战中访问,因此训练了一个额外的基线系统,以量化堆叠网络的性能,与使用时频掩蔽的连续LSTM层模型相比。该模型有4个连续的LSTM层,每个层有512个单元,然后是一个完全连接的部分,通过sigmoid激活来预测TF-mask。模型的输入等于DTLN-aec模型的第一个块。将掩模与近端麦克风信号的非规格化幅度相乘,并变换回时域。这种配置的结果是一个具有8.5M参数的模型。该模型使用与DTLN-aec模型相同的设置进行训练。
评价标准
广泛使用的用于评价AEC系统的PESQ[33]和ERLE[34]指标往往与主观评分[16]没有很好的相关性。然而,如果模型按照预期执行,客观的度量可以作为一个指示。AEC问题被视为一个源分离问题,因此SI-SDR[35]被用于评估分离性能。此外,PESQ被用来表示语音质量。


讨论
当比较不同尺寸的模型时,DTLN-aec模型在参数数量方面似乎具有良好的可扩展性:128个小模型在噪声条件下已经取得了很好的改善,256个单元的模型优于参数不到一半的基线模型。这也显示了使用堆叠模型与使用四个连续LSTM层模型相比的优势。对于AEC任务来说,使用具有更高建模能力的模型可能是一个优势,因为它不仅可以将语音从噪声中分离出来,而且还可以将语音从语音中分离出来,这可能是一个更具挑战性的任务——特别是当声音具有相似特征时。对于为特定硬件量身定制的应用程序,可以根据计算资源和功耗等约束条件选择模型的大小
由于训练集只包含英语语音样本,所以我们的研究没有评估多语言泛化的问题,这是今后需要解决的问题。在clean ST-NE条件下的结果表明,基线和DTLN-aec模型对无噪声和回波的纯净近端语音有相似的影响,它们对最优信号的不利影响非常有限。然而,在听处理过的信号时,在某些条件下仍能听到一些残余噪声。在DTLN-aec模型的未来改进中,可以添加额外的降噪来进一步提高语音质量。为了减少仅在远端条件下的残余噪声,可以添加语音活动检测来检测近端语音,并在没有近端语音的情况下对信号进行门控















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









