







Python微信订餐小程序课程视频
https://edu.csdn.net/course/detail/36074
Python实战量化交易理财系统
https://edu.csdn.net/course/detail/35475阅读目录
论文地址:https://graz.pure.elsevier.com/en/publications/acoustic-echo-cancellation-with-cross-domain-learning
具有跨域学习的声学回声消除
回到顶部### 摘要:
本文提出了跨域回声控制器(CDEC),提交给 Interspeech 2021 AEC-Challenge。该算法由三个构建块组成:(i) 时延补偿 (TDC) 模块,(ii) 基于频域块的声学回声消除器 (AEC),以及 (iii) 时域神经网络 (TD-NN)用作后处理器。我们的系统获得了 3.80 的整体 MOS 分数,而在 32 毫秒的系统延迟下仅使用了 210 万个参数。
**关键字:**声学回声消除、神经网络、残余回声消除
回到顶部### 1 引言
回声消除 (AEC) 在当今的 VoIP 语音通信和视频会议系统中发挥着重要作用。由于室内声学,在扬声器和耳机麦克风、听筒或任何其他用于语音通信的音频硬件之间会出现回声。根据房间的混响时间,声学回声可能会非常突出,甚至会显着降低语音清晰度和语音质量 [1]。这在免提场景中尤其是一个问题 [2]。因此,高效的 AEC 解决方案是可靠语音通信的重要组成部分。典型的 AEC 将扬声器和麦克风之间的回声脉冲响应 (EIR) 建模为线性 FIR 滤波器,并使用归一化最小均方 (NLMS) 算法 [3, 4] 自适应地调整该滤波器。许多实现需要语音活动检测器 (VAD) 在双方通话期间停止适应,即当近端和远端说话者同时说话时 [3,5]。更复杂的实现通过使用状态空间模型 [6] 或卡尔曼滤波器 [7] 来解释双方对话。然而,线性回声模型不能考虑回声路径中的非线性失真,或麦克风拾取的附加噪声。 SpeexDSP [8]、WebRTC [9] 或 PjSIP [10] 等商业 AEC 框架依赖于传统的非线性回声和噪声去除方法,例如 Wienerfilters [11]、Volterra 内核 [12] 或 Hammerstein 模型 [13]。
最近,已经提出神经网络用于非线性残余回声和噪声去除[14-19]。从深度学习的角度来看,这些任务可以看作是语音或音频源分离问题 [2,14,18-23]。尽管该研究领域近年来进展迅速 [24, 25],但大多数基于 NN 的说话人分离算法对计算的要求很高,没有因果关系,并且不能在实时应用中工作。能够进行实时处理的系统在逐帧的基础上运行。特别是,循环神经网络 (RNN),如门控循环单元 (GRU) [26] 或长短期记忆 (LSTM) [27] 网络用于模拟人类语音中的时间相关性,同时遵守实时典型 AEC 应用的约束 [2, 19, 28]。类似的架构 [29-31] 已应用于实时信号增强,作为对 Interspeech 2020 [32] 的深度噪声抑制挑战和 ICASSP AEC 挑战 [33] 的贡献。
本文介绍了我们对 Interspeech 2021 AEC-Challenge 的贡献,该挑战由三个级联模块组成:(i) 基于 PHAse 变换的广义互相关 (GCCPHAT) [4] 的时延补偿 (TDC) 模块,其中补偿近端扬声器和麦克风信号之间的延迟。 (ii) 一种频域状态空间块分区 AEC 算法 [6],它去除了线性回波分量。 (iii) 时域神经网络 (TD-NN),它可以同时去除非线性残余回声和附加噪声。我们将我们的系统称为跨域回声控制器 (CDEC),因为它同时在频域和时域中运行。我们模型的评估基于使用 ITU P.808 框架 [33] 的感知语音质量指标,该框架报告平均意见分数 (MOS)。此外,我们报告了其他指标,例如 MOSnet [34] 和 ERLE [35]。最后,我们还报告了我们的 CDEC 系统在每帧音频数据的 MAC 操作方面的计算复杂性。
回到顶部### 2 提出的系统
2.1 问题表述
在典型的 AEC 系统中,有两个输入信号可用: (i) 远端麦克风信号 x(t),由本地扬声器播放。 (ii) 近端麦克风信号 d(t),可描述为以下分量的叠加:
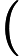
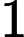
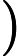 d(t)=x(t−Δt)∗h(t)+s(t)+n(t)+v(t) (1)
d(t)=x(t−Δt)∗h(t)+s(t)+n(t)+v(t) (1)
d(t)=x\left(t-\Delta_{t}\right) * h(t)+s(t)+n(t)+v(t) (1)
其中 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9LmljwlQ-1648529302429)(https://blog.csdn.net/2_7_5/fonts/HTML-CSS/TeX/png/Math/Italic/400/0064.png?V=2.7.5)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-scNiRxZR-1648529302430)(https://blog.csdn.net/2_7_5/fonts/HTML-CSS/TeX/png/Main/Regular/400/0394.png?V=2.7.5)] Δt\Delta_{t}建模为滤波器权重中的前导零。然而,更实际的做法是在 AEC 之前明确补偿此延迟,以保持建模的 EIR 较短,从而节省计算资源。虽然这种延迟可能是未知的,但我们坚持通常在实时音频处理框架中做出的假设 [8-10]。特别是,我们假设延迟不超过1s,并且至少稳定10s。
Δt\Delta_{t}建模为滤波器权重中的前导零。然而,更实际的做法是在 AEC 之前明确补偿此延迟,以保持建模的 EIR 较短,从而节省计算资源。虽然这种延迟可能是未知的,但我们坚持通常在实时音频处理框架中做出的假设 [8-10]。特别是,我们假设延迟不超过1s,并且至少稳定10s。
我们采用 GCC-PHAT 算法 [4] 在频域中比较远端信号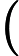
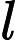
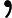
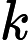
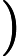

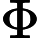
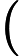
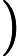
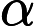

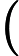
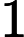

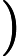
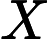
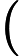
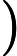
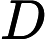
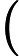
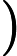
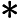
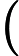
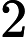
 Φ(l,k)=Φ(l,k)α+(1−α)X(l,k)D(l,k)∗ (2)
Φ(l,k)=Φ(l,k)α+(1−α)X(l,k)D(l,k)∗ (2)
\Phi(l, k)=\Phi(l, k) \alpha+(1-\alpha) X(l, k) D(l, k)^{*} (2)
其中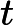

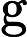
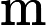
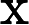
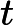

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









