







本期重点:
1、Spark Streaming初始化
2、Spark Streaming运行结束关闭源码分析
我们以SparkStreaming的wordcount小程序为例解析源码内幕:
/**
* StreamingContext初始化
* sparkConf可以设置很多参数,包括appname、master信息、ExecutorEnv(executor环境信息),当然SparkConf中最强大的shi
* set(key: String, value: String) 这里你可以shuffle配置参数、内存百分比的配置、jvm的配置,对于性能来说是很有用的
* */
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream("Master",9000, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()我们本期研究的重点是SparkStraming初始化部分(第6、7行的代码)以及SparkStreaming关闭部分的代码(第15行),至于中间部分主要是业务业务逻辑的处理代码,并不是我们今天研究的重点
StreamingContext的初始化
/**
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}其实我们在前面的博客中也不止一次的看到这部分初始化的代码,SparkStraming实际上是SparkCode之上的一个应用程序,当然如果我们设计模式的角度来看这是装饰器模式,因为SparkStraming其本质就是在SparkCode基础之上进行了一层封装和修饰,当然还加上了一个batchDuration的时间维度,这个时间维度对SparkStreaming来说主要体现在两个定时器上面,一个是executor的定时器,主要作用是:不断接受数据和存储数据并将数据的元数据信息汇报给driver;另外一个定时器主要在driver层面,主要用于根据每个batchDuration不断的产生job并将job提交给集群运行
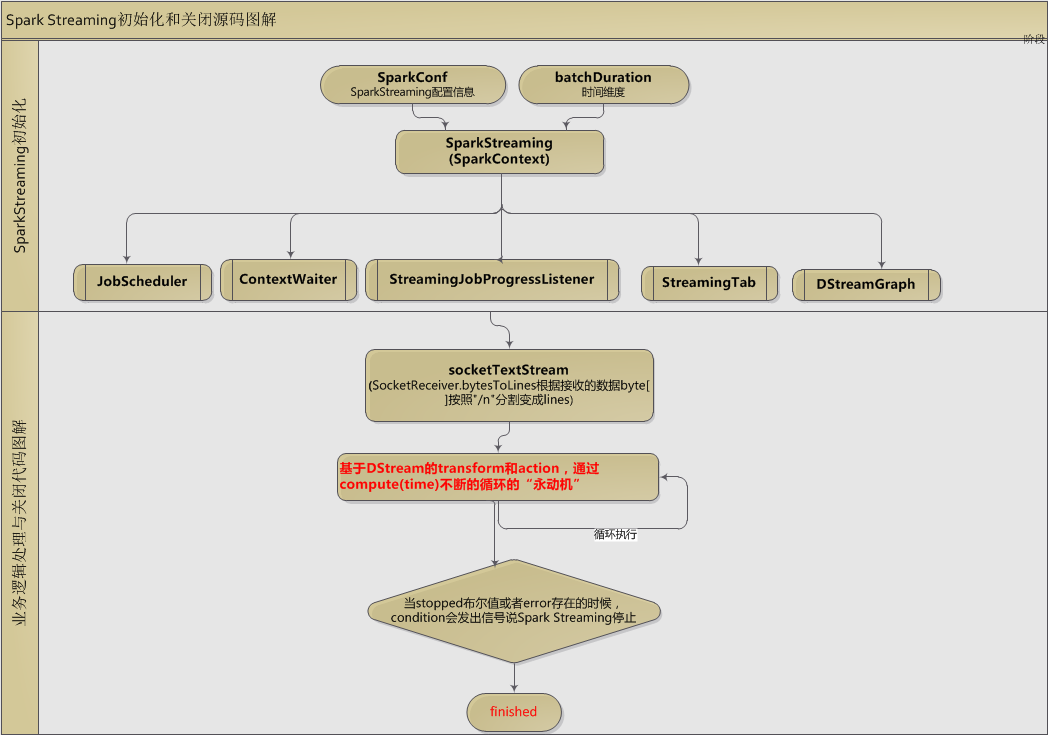
如上图我们暂且wordcount代码逻辑简单粗暴的分为两个主要部分:1、初始部分;2、关闭部分(因为我们本节关注的也是这两部分)
初始部分
SparkStreaming根据SparkConf和batchDuration两个参数,初始化SparkStreaming对象,在这时同时也初始化了5个重要的对象:
1、JobScheduler
JobScheduler主要作用在于其调度Job运行在Spark集群之上,并启动JobGenerator根据batchDuration不断产生Job
2、DStreamGraph
DStreamGraph主要根据输入流和输出流构建DStream的有向无环图
3、StreamingJobProgressListener
主要作用在于SparkJob的各种状态的监听,主要包括:onReceiverStarted、onReceiverError、onJobStart、onOutputOperationCompleted等
4、StreamingTab
主要用于SparkStreaming Job 各种统计信息的Web UI展示
5、ContextWaiter
主要构建一个线程的同步锁对象,这个对象主要在停止部分会被调用
停止部分
我们来看这句代码:ssc.awaitTermination()的背后源码:
/**
* Wait for the execution to stop. Any exceptions that occurs during the execution
* will be thrown in this thread.
*/
def awaitTermination() {
waiter.waitForStopOrError()
}这里的这个waiter对象其实就是初始化部分的ContextWaiter,其主要作用:等待执行停止。执行期间发生的任何异常将被扔在这个线程。
/**
* Return `true` if it's stopped; or throw the reported error if `notifyError` has been called; or
* `false` if the waiting time detectably elapsed before return from the method.
*/
def waitForStopOrError(timeout: Long = -1): Boolean = {
lock.lock()
try {
if (timeout < 0) {
while (!stopped && error == null) {
condition.await()
}
} else {
var nanos = TimeUnit.MILLISECONDS.toNanos(timeout)
while (!stopped && error == null && nanos > 0) {
nanos = condition.awaitNanos(nanos)
}
}
// If already had error, then throw it
if (error != null) throw error
// already stopped or timeout
stopped
} finally {
lock.unlock()
}
}














 3231
3231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









