










文章目录
前言
本章节将使用xinference启动 LLM+检索模型服务,然后使用Langchain-chatchat接收模型服务api,并录入知识库,实现本地知识库部署。
一、平台环境准备
镜像选择:pytorch:v24.10-torch2.4.0-torchmlu1.23.1-ubuntu22.04-py310
【请注意仔细查看自己的镜像版本,老版本改法,请查阅之前文章】
卡选择:任意一款MLU3系列及以上卡
二、模型下载
1.DeepSeek-R1-Distill-Qwen-14B模型下载
apt install git-lfs
git-lfs clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B.git
2.bge-large-zh-v1.5检索模型下载
git-lfs clone https://www.modelscope.cn/AI-ModelScope/bge-large-zh-v1.5.git
rerank模型也可自行下载方式与下面一致,这里不做展示
3.基础环境安装
pip install sentence-transformers transfromers accelerate
三、Xinference部署
git clone -b v1.2.1 https://githubfast.com/xorbitsai/inference.git #拷贝源代码
python /torch/src/torch_mlu/tools/torch_gpu2mlu/torch_gpu2mlu.py -i inference/
#webui安装
apt install npm -y
cd inference && python setup.py build_web
cd .. && pip install -e ./inference_mlu #源码编译
##全局搜索【可以用vscode全局替换】
bfloat16 -> float16 #仅370
至此环境安装完成,简单起一个webui测试下环境
xinference-local #命令行运行
找到对应模型按照红框配置
1.LLM模型启动

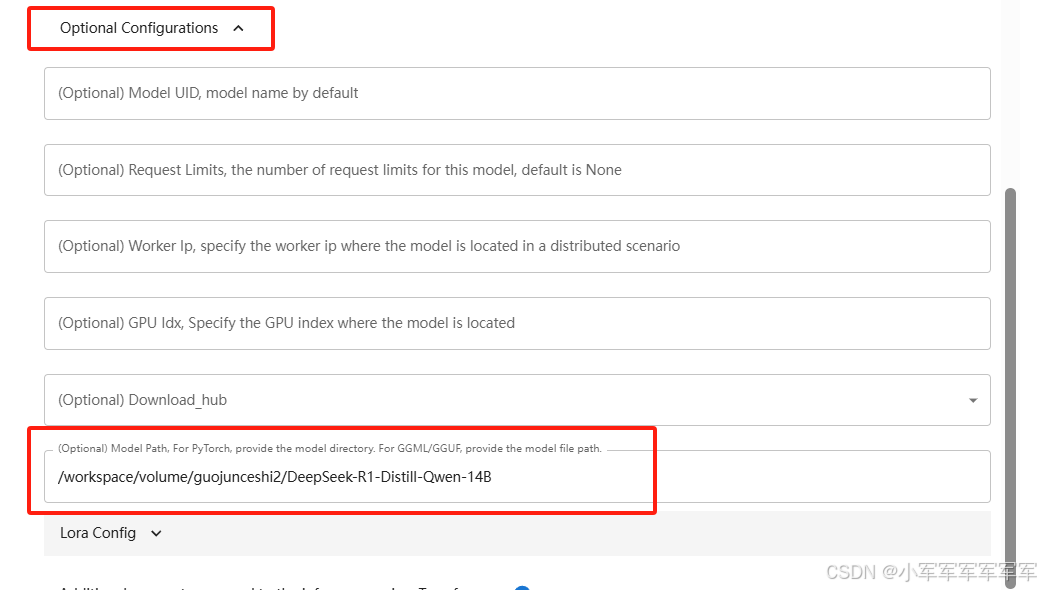
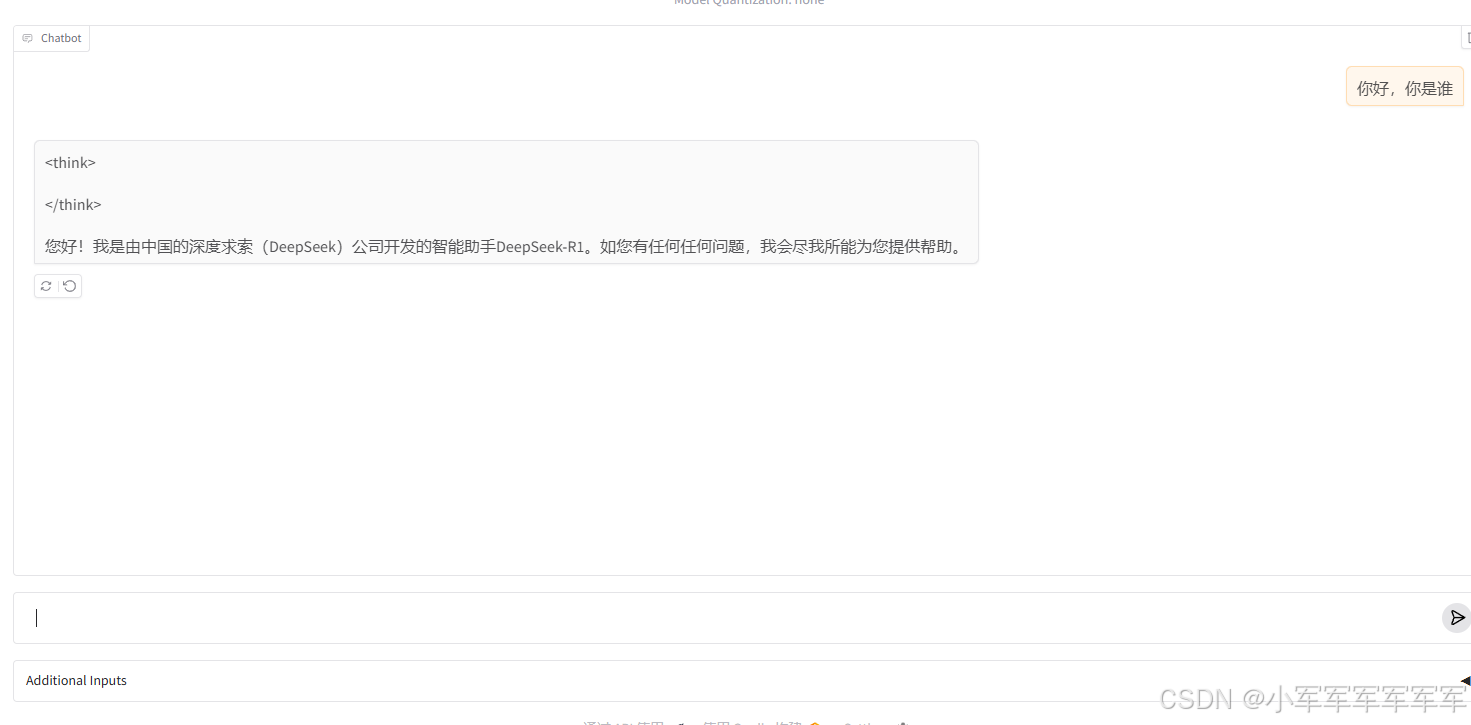
至此大模型启动完成,
2.EMBEDDING 模型启动
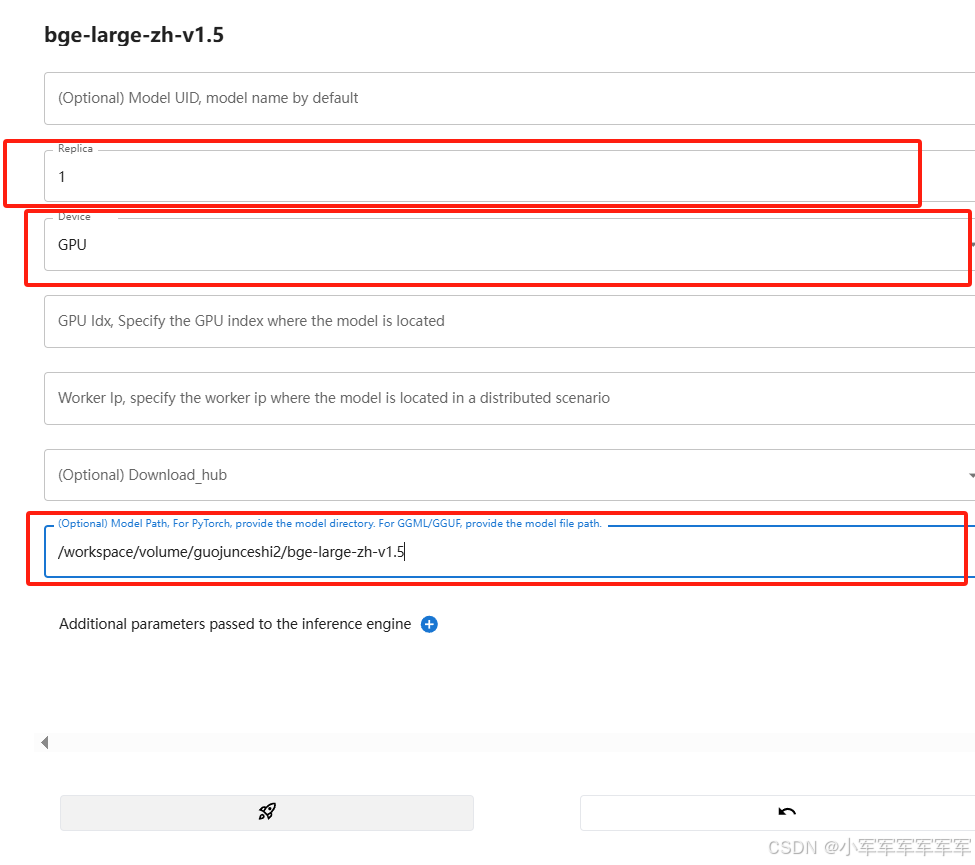

出现IP+端口即服务部署完成,接着开始部署langchain-chatchat
四、Langchain-chatchat部署
pip install langchain-chatchat -U
#回到刚才路径在
pip install -e ./inference_mlu
export CHATCHAT_ROOT=/workspace/volume/guojunceshi2/set_langchain/ #设置该环境变量可以让我们找到自己的Yaml配置文件
cp -r bge-large-zh-v1.5/ set_langchain/data/knowledge_base/samples/vector_store/ #检索模型拷贝到这个路径下
# 解决nltk_data问题
cd set_langchain/data/ && rm -rf nltk_data && git clone https://gitee.com/maximnum/nltk_data.git
#如果你已经启动了 Xinference 服务,可以直接指定 Xinference API 地址、LLM 模型、Embedding 模型
chatchat init -x http://127.0.0.1:9997/v1 -l deepseek-r1-distill-qwen -e bge-large-zh-v1.5 -r
#如果你有自己的数据集你可以不用开源的数据集做测试,直接开始下一步
注意安装完langchain后,建议在执行一次,pip install -e ./inference_mlu ,因为两个包感觉有点冲突
五、部署结果展示 or 用自己的数据集做问答
chatchat start -a
#之后访问8501端口界面
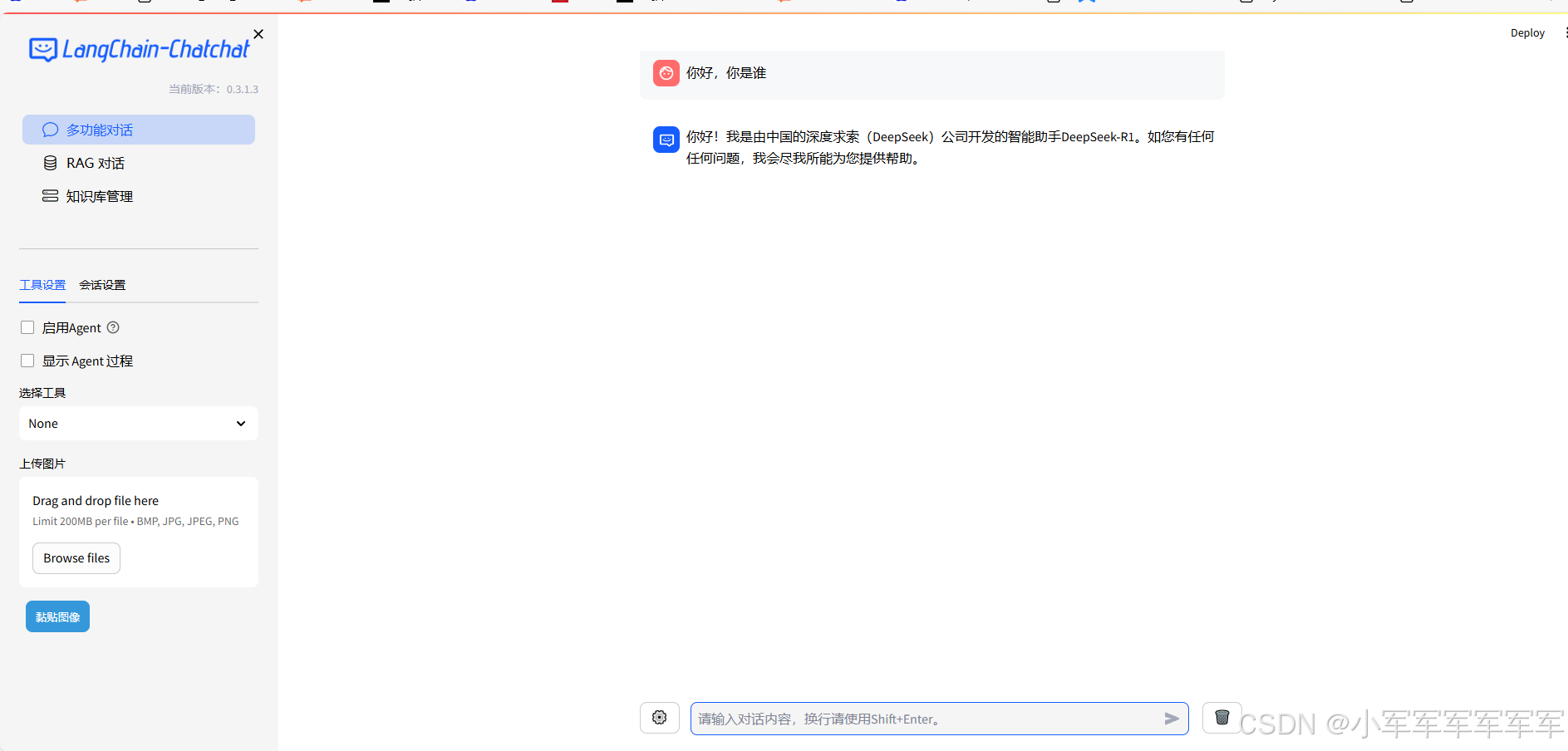
LLM能力如上,接着开始演示如何用自己的数据集做问答
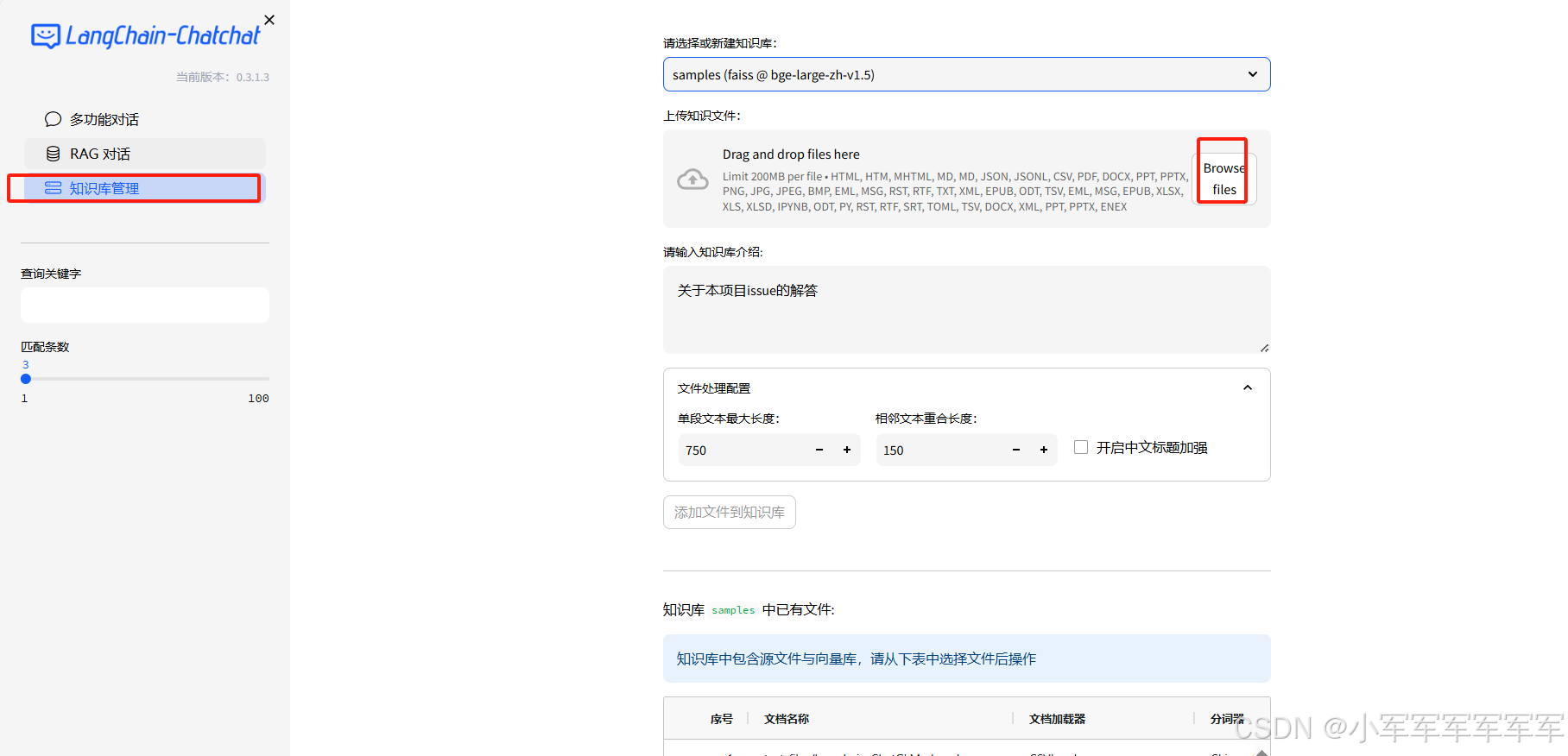

简单上传一个自我介绍文档,看下效果
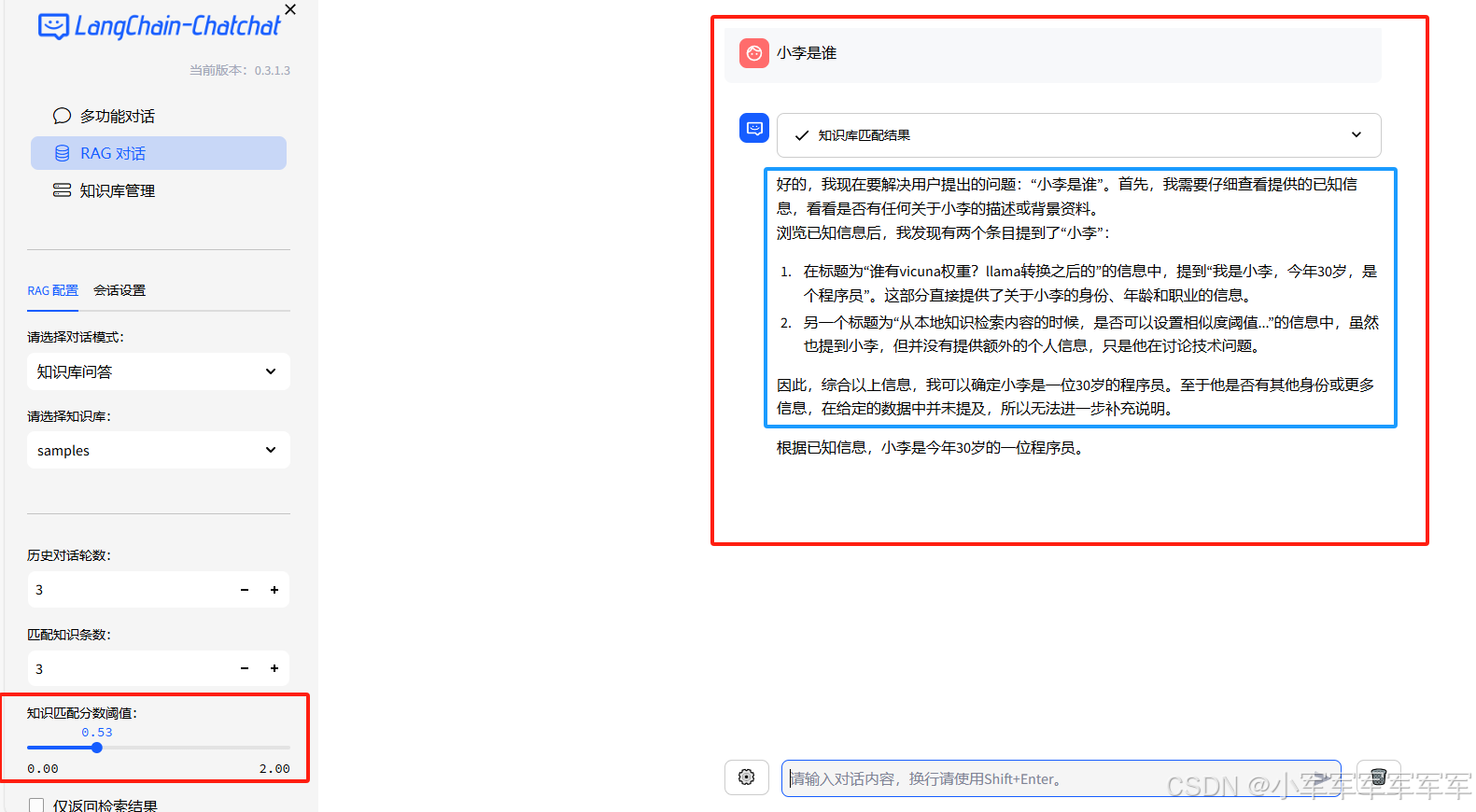
可以适当调整阈值,蓝色框为思考,其他部分为最后结果。

















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









