







一、概述
HBase有以下几个特点:
- HBase列的可以动态增加,并且列为空就不存储数据,节省存储空间.
- hbase自动切分数据,使得数据存储自动具有水平scalability.
- Hbase可以提供高并发读写操作的支持。
- HBase不能支持条件查询,只支持按照Row key来查询.
- 暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉.
因为HBase的这些特点,是它和Mysql的等关系型数据库的应用场景和设计理念完全不同。传统关系型数据库(mysql,oracle)数据存储方式主要如下:
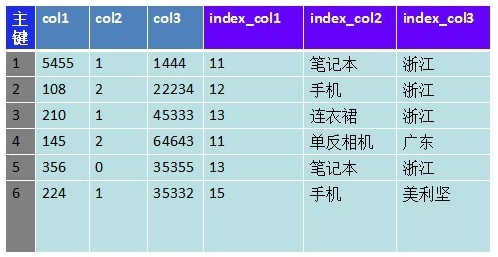
上图是个很典型的数据储存方式,我把每条记录分成3部分: 主键、记录属性、索引字段 。我们会对索引字段建立索引,达到二级索引的效果。
但是随着业务的发展,查询条件越来越复杂,需要更多的索引字段,且很多值都不存在,如下图:
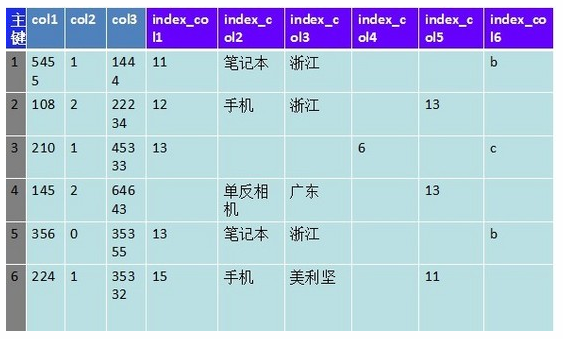
上图是6个索引字段, 实际情况可能是上百个甚至更多,并且还需要根据多个索引字段刷选。查询性能越来越低,甚至无法满足查询要求。关系型数据里的局限也开始显现,于是很就出现了Nosql等非关系数据库。
HBase作为一个列族数据库很强大,很多人就想把数据从mysql迁到hbase,存储的内容还是跟上图一样,主键设为为rowkey。其他各个字段的数据,存储一个列族下的不同列。但是想对索引字段查询就没有办法,目前还没有比较好的基于bigtable的二级索引方案,所以无法对索引字段做查询。这时候其实可以转换下思维,可以把数据倒过来,如下图:
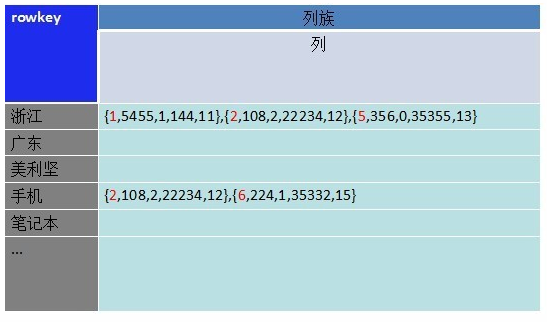
把各个索引字段的值作为rowkey,然后把记录的主键和属性值按照一定顺序存在对应rowkey的value里。上图只有一个列族,是最简单的方式。 Value里的记录可以设置成定长的byte[],多个记录集合通过移位快速查询到。
但是上面只适合单个索引字段的查询。如果要同时对多个索引字段查询,比如查询“浙江”and“手机”,需要取出两个value,再解析出各自的主键求交集。如果每条记录的属性有上百个,对性能影响很大。
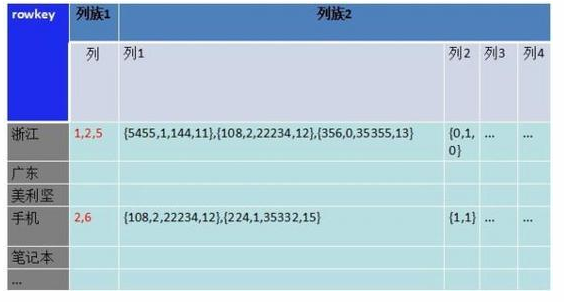
接下来的的问题就是解决多索引字段查询的问题。我们将主键字段和属性字段分开存储 ,储存在不同的列族下,多索引查询只需要取出列族1下的数据,再去最小集合的列族2里取得想要的值。储存如下图:
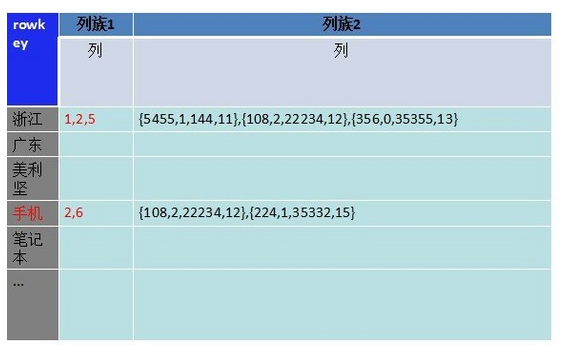
为什么是不同列族,而不是一个列族下的两个列?
列族数据库数据文件是按照列族分的。在取数据时,都会把一个列族的所有列数据都取出来,事实上我们并不需要把记录明细取出来,所以把这部分数据放到了另一个列族下。
接下来是对列族2扩展,列族2储存更多的列,用来做各种刷选、计算处理。如下图:
二、HBase和RDBMS的区别
1、数据类型
Hbase只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。用户需要自己进行类型转换。而关系数据库有丰富的类型和存储方式。
2、数据操作
HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系。而传统数据库通常有各式各样的函数和连接操作。
3、存储模式
HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的 。
4、数据维护
HBase的更新操作不应该叫更新,它实际上是插入了新的数据原来的旧版本仍然保留着,而传统数据库是替换修改。
5、可伸缩性
Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能。
三、Hbase检索时间复杂度
既然使用Hbase的目的是高效、高可靠、高并发的访问海量非结构化数据,那么Hbase检索数据的时间复杂度是关系到基于Hbase的业务系统开发设计的重中之重,Hbase的运算有多快,我们从计算机算法的数学角度做简要分析,以便读者理解后文的项目实例中Hbase业务建模及设计模式中的考量因素。
我们先以如下变量定义Hbase的相关数据信息:
n=表中KeyValue条目数量(包括Put结果和Delete留下的标记)
b=HFile里数据库(HFileBlock)的数量
e=平均一个HFile里面KeyValue条目的数量(如果知道行的大小,可以计算得到)
c=每行里列的平均数量我们知道Hbase中有两张特殊表:-ROOT-&.META.,其中.META.表记录Region分区信息,同时,.META.也可以有多个Region分区,同时-ROOT-表又记录.META.表的Region信息,但-ROOT-只有一个Region,而-ROOT-表的位置由Hbase的集群管控框架,即Zookeeper记录。
关于-ROOT-&.META.表的细节这里不再累述,感兴趣的读者可以参阅Hbase–ROOT-及.META.表资料,理解HbaseIO及数据检索时序原理。
Hbase检索一条数据的流程如下图所示。
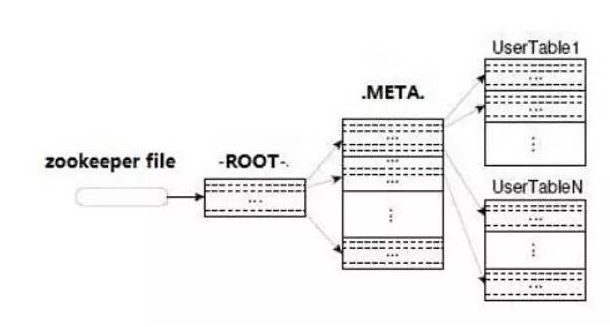
如上图我们可以看出,Hbase检索一条客户数据需要的处理过程大致如下:
(1)如果不知道行健,直接查找列key-value值,则
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









