







 本文详细介绍了Zookeeper的基本原理,包括其架构、角色、数据模型,以及在云计算领域的广泛应用,如统一命名服务、配置管理、集群管理、分布式通知/协调和分布式锁。通过Zookeeper,分布式系统可以实现高可用和一致性,有效解决分布式环境中的各种协调问题。
本文详细介绍了Zookeeper的基本原理,包括其架构、角色、数据模型,以及在云计算领域的广泛应用,如统一命名服务、配置管理、集群管理、分布式通知/协调和分布式锁。通过Zookeeper,分布式系统可以实现高可用和一致性,有效解决分布式环境中的各种协调问题。
一、概述
Zookeeper是一个针对大型分布式系统的可靠协调系统;提供的功能包括:配置维护、名字服务、分布式同步、组服务等;目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户;Zookeeper已经成为Hadoop生态系统中的基础组件。ZooKeeper性能上的特点决定了它能够用在大型的、分布式的系统当中。从可靠性方面来说,它并不会因为一个节点的错误而崩溃。除此之外,它严格的序列访问控制意味着复杂的控制原语可以应用在客户端上。ZooKeeper在一致性、可用性、容错性的保证,也是ZooKeeper的成功之处,它获得的一切成功都与它采用的协议——Zab协议是密不可分的。
Zookeeper具有以下特点:
- 最终一致性:为客户端展示同一视图,这是zookeeper最重要的功能。
- 可靠性:如果消息被到一台服务器接受,那么它将被所有的服务器接受。
- 实时性:Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不干预快速的client的请求。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:所有Server,同一消息发布顺序一致。
正是因为Zookeeper的这些特点,使得它十分适合分布式集群的管理,在如下技术中都有Zookeeper的身影。
- HDFS
- YARN
- Storm
- HBase
- Flume
- Dubbo(阿里巴巴)
- metaq阿里巴巴)
二、Zookeeper基本原理
1、Zookeeper架构
Zookeeper的基本架构如下:
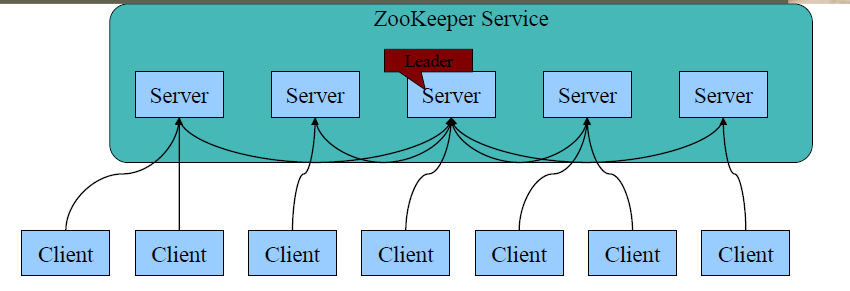
该架构具有如下特点:
- 每个Server在内存中存储了一份数据;
- Zookeeper启动时,将从实例中选举一个leader(采用Paxos协议);
- Leader负责处理数据更新等操作(采用Zab协议);
- 一个更新操作成功,当且仅当大多数Server在内存中成功修改数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4305
4305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









