






1 为什么ui卡顿 , ui卡顿产生的几种原因
1.1 屏幕显示机制
一般包括CPU、GPU、display三个部分,
CPU一般负责计算数据,把计算好数据交给GPU,
GPU会对图形数据进行渲染,渲染好后放到buffer里存起来,
然后display(有的文章也叫屏幕或者显示器)负责把buffer里的数据呈现到屏幕上
CPU负责包括Measure , Layout , Record , Execute 的计算操作, GPU 负责asterization(栅格化)操作
1.1.1卡顿和CPU的关系
CPU 绘制视图树来计算下一帧画面数据的工作是在屏幕刷新信号来的时候才开始工作的,而当这个工作处理完毕后,也就是下一帧的画面数据已经全部计算完毕,也不会马上显示到屏幕上,而是会等下一个屏幕刷新信号来的时候再交由底层将计算完毕的屏幕画面数据显示出来。
界面性能取决于UI 渲染性能,CPU 和GPU 的处理时间因为各种原因都大于一个VSync 的间隔(16.6ms),导致了卡顿。渲染操作通常依赖于两个核心组件:CPU 与GPU。
1.1.2 双缓冲机制
保存在两个Buffer 缓冲区中,A 缓冲用来显示当前帧,那么B 缓冲就用来缓存下一帧的数据,
同理,B 显示时,A 就用来缓冲!这样就可以做到一边显示一边处理下一帧的数据。
1.1.3 什么是卡顿
从用户角度说,App操作起来缓慢,响应不及时,列表滑动一顿一顿的,动画刷新不流畅等等一些直观感受。
从系统角度来说,屏幕刷新的帧率不稳定,无法保证每秒绘制60帧,也就是说有掉帧的情况发生。
Android 系统的屏幕刷新频率为 60 fps, 也就是每隔 16 ms 刷新一次。
如果在某次绘制过程中,我们的操作不能在 16 ms 内完成,那它则不能赶上这次的绘制公交车,只能等下一轮。这种现象叫做掉帧”,用户看到的就是界面绘制不连续、卡顿。
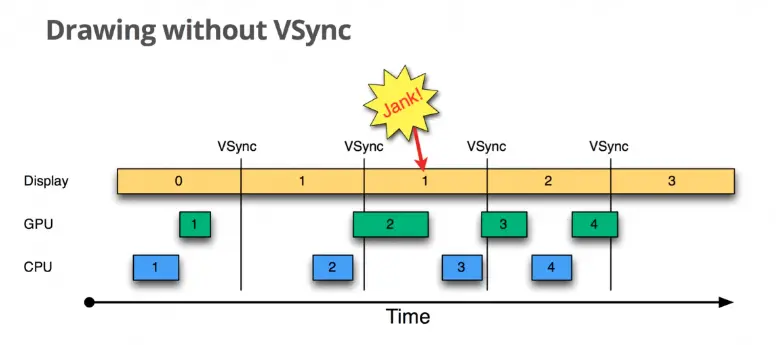
1.2 根本原因: view刷新机制有关
1.3 常见卡顿原因及解决方案
在onDraw这种频繁调用的方法要避免对象的创建操作,因为他会迅速增加内存的使用,引起频繁的gc,甚至内存抖动。
第一:耗时,计算。导致cpu
第二:绘制太久,导致GPU
问题: 局层级较多/主线程耗时 是如何造成 丢帧的呢?
第三. GC太频繁。导致的内存抖动。导致
1.4 卡顿和Anr的关系:
假如我在一个button的onClick事件中,有一个耗时操作,这个耗时操作的时间是10秒,但这个耗时操作并不会引发ANR,它只是一次卡顿。
在大部分Android平台的设备上,Android系统是16ms刷新一次,也就是一秒钟60帧。要达到这种刷新速度就要求在ui线程中处理的任务时间必须要小于16ms,如果ui线程中处理时间长,就会导致跳过帧的渲染,也就是导致界面看起来不流畅,卡顿。如果用户点击事件5s中没反应就会导致ANR。
一方面,两者息息相关,长时间的UI卡顿是导致ANR的最常见的原因;
但另一方面,从原理上来看,两者既不充分也不必要,是两个纬度的概念。
2.屏幕刷新机制Choreographer
2.1 源码分析:
1). ViewRootImpl#requestLayout
protected ViewParent mParent;
...
public void requestLayout() {
...
if (mParent != null && !mParent.isLayoutRequested()) {
mParent.requestLayout(); //1
}
}
2). ViewRootImpl#scheduleTraversals
void scheduleTraversals() {
//1、注意这个标志位,多次调用 requestLayout,要这个标志位false才有效
if (!mTraversalScheduled) {
mTraversalScheduled = true;
// 2. 同步屏障
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// 3. 向 Choreographer 提交一个任务
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
//绘制前发一个通知
notifyRendererOfFramePending();
//这个是释放锁,先不管
pokeDrawLockIfNeeded();
}
}
3). DisplayEventReceiver #dispatchVsync()
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this); //1 callback是this,会回调run方法
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame); //2
}
}
4). 卡顿第一地方: 如果Handler此时存在耗时操作,那么需要等耗时操作执行完,Looper才会轮循到下一条消息,run方法才会调用,然后才会调用到doFrame(mTimestampNanos, mFrame);
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
...
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
// 1 当前时间戳减去vsync来的时间,也就是主线程的耗时时间
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
//1帧是16毫秒,计算当前跳过了多少帧,比如超时162毫秒,那么就是跳过了10帧
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
// SKIPPED_FRAME_WARNING_LIMIT 默认是30,超时了30帧以上,那么就log提示
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
// 取余,计算离上一帧多久了,一帧是16毫秒,所以lastFrameOffset 在0-15毫秒之间,这里单位是纳秒
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Missed vsync by " + (jitterNanos * 0.000001f) + " ms "
+ "which is more than the 8frame interval of "
+ (mFrameIntervalNanos * 0.000001f) + " ms! "
+ "Skipping " + skippedFrames + " frames and setting frame "
+ "time to " + (lastFrameOffset * 0.000001f) + " ms in the past.");
}
// 出现掉帧,把时间修正一下,对比的是上一帧时间
frameTimeNanos = startNanos - lastFrameOffset;
}
//2、时间倒退了,可能是由于改了系统时间,此时就重新申请vsync信号(一般不会走这里)
if (frameTimeNanos < mLastFrameTimeNanos) {
if (DEBUG_JANK) {
Log.d(TAG, "Frame time appears to be going backwards. May be due to a "
+ "previously skipped frame. Waiting for next vsync.");
}
//这里申请下一次vsync信号,流程跟上面分析一样了。
scheduleVsyncLocked();
return;
}
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
//3 能绘制的话,就走到下面
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
}
}
1. 不正常, 请求下一帧vsync信号, 计算收到vsync信号到doFrame被调用的时间差,vsync信号间隔是16毫秒一次,大于16毫秒就是掉帧了,如果超过30帧(默认30),就打印log提示开发者检查主线程是否有耗时操作。
2.正常情况: 执行TraversalRunnable()的run()
5). ViewRootImpl$TraversalRunnable
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
2.2 总结:
1). 我要去刷新ui-----View 的 requestLayout 会调到ViewRootImpl 的 requestLayout方法(请求刷新)
2). 然后通过 scheduleTraversals 方法向Choreographer 提交一个绘制任务, 同步屏障 (提交请求任务)
3).然后再通过DisplayEventReceiver向底层请求vsync信号, (发vsync信号 )
4).通过JNI回调回来, 收到VSync通知,在doFrame()方法里面, CPU和GPU就立刻开始计算然后把数据写入buffer(doframe)
5).通过Handler往主线程消息队列post一个异步任务,
最终是ViewRootImpl去执行那个绘制任务,调用performTraversals方法,用view的绘制流程,onmeasure(),onlayout(),onDraw();
2.3卡顿的2个根本原因:
那么有两个地方会造成掉帧
1).一个是主线程有其它耗时操作,handler的异步消息没有来得及处理, 导致doFrame,在Choreographer没有机会在vsync信号发出之后16毫秒内调用,对应下图的3;(主线程耗时,导致dofrme没有及时执行)
计算收到vsync信号到doFrame被调用的时间差,vsync信号间隔是16毫秒一次,大于16毫秒就是掉帧了onVsync信号,就是底层16.6s会回调一次过来的! 2次doFrame间隔时间是16.6!
2).还有一个就是当前doFrame方法耗时,绘制太久,下一个vsync信号来的时候这一帧还没画完,造成掉帧,对应下图的2。1是正常的(过度绘制)
2.4 重要的类分析
Choreographer 两个主要作用
1)、承上:负责接收和处理 App 的各种更新消息和回调,等到 Vsync 到来的时候统一处理。比如集中处理 Input(主要是 Input 事件的处理) 、Animation(动画相关)、Traversal(包括 measure、layout、draw 等操作) ,判断卡顿掉帧情况,记录 CallBack 耗时等。
2)、启下:负责请求和接收 Vsync 信号。接收 Vsync 事件回调(通过 FrameDisplayEventReceiver.onVsync );请求 Vsync(FrameDisplayEventReceiver.scheduleVsync) .
2.5 相关的vsync重点问题
- .问题: VSYNC是由谁发出来的? 比如 VSync 信号是从哪里来的?发到哪里去?有什么作用?
Android系统每隔16ms会发出VSYNC信号重绘我们的界面(Activity)。
源码分析:在SurfaceFingler里面的HWcompose。由硬件发出,如果发生失败,通过一个线程模拟!
在SurfaceFlinger到Screen之间,还有一个可选的模块HWC(Hardware Composer),
用于最终把内容显示到屏幕上。如果存在HWC,那么SurfaceFlinger就只需要告诉HWC显示哪些内容即可,无需关心如何显示
源码分析:SurfaceFling发送,是有一个连接。不会主动发送给app。需要app主动发送RequestLayout,然后设置连接
app会请求VSync信号, 第一次是用户更新UI,后面应该也是系统发的. 如果超时了那么在doframe,会去请求下一帧
- . 问题: 丢帧(掉帧) ,是说 这一帧延迟显示 还是丢弃不再显示 ?
答:延迟显示,因为缓存交换的时机只能等下一个VSync了。
布局层级较多/主线程耗时 是如何造成 丢帧的呢?
答:布局层级较多, 3个流程会比较慢, 会影响CPU/GPU的执行时间,大于16.6ms时只能等下一个VSync了。
布局层级较多, doFrame里面的方法执行超过16.6ms,就会等下一次VSync信号了
if (frameTimeNanos < mLastFrameTimeNanos) {
if (DEBUG_JANK) {
Log.d(TAG, "Frame time appears to be going backwards. May be due to a "
+ "previously skipped frame. Waiting for next vsync.");
}
scheduleVsyncLocked();
return;
}
问题: 主线程耗时为什么会导致卡顿?
一个是主线程有其它耗时操作,导致异步消息没有执行, 最后导致doFrame没有机会在vsync信号发出之后16毫秒内调用、
深入理解: 消息机制!
这个原因,系统已经引入了同步屏障消息的机制,尽可能的保证遍历绘制 View 树的工作能够及时进行,但仍没办法完全避免,所以我们还是得尽可能避免主线程耗时工作。
其实第二个原因,可以拿出来细讲的,比如有这种情况, message 不怎么耗时,但数量太多,这同样可能会造成丢帧。如果有使用一些图片框架的,它内部下载图片都是开线程去下载,但当下载完成后需要把图片加载到绑定的 view 上,这个工作就是发了一个 message 切到主线程来做,如果一个界面这种 view 特别多的话,队列里就会有非常多的 message,虽然每个都 message 并不怎么耗时,但经不起量多啊。
这2个是同一个原因还是不同原因?不同, 所以卡顿是2个方面!
问题: 内存抖动为什么会引起卡顿?
- . 问题: 16.6ms刷新一次 是啥意思?是每16.6ms都走一次 measure/layout/draw ?
答:屏幕的固定刷新频率是60Hz,即16.6ms。不是每16.6ms都走一次 measure/layout/draw,而是有绘制任务才会走,并且绘制时间间隔是取决于布局复杂度及主线程耗时。
不是。measure/layout/draw 走完后 会在VSync到来时进行缓存交换和刷新。
measure/layout/draw 走完,界面就立刻刷新了吗?
不是,会等到下一次vsync信号来. 这个下一次指最近一次vsync来的时候.
- . 问题: 如果界面没动静止了,还会刷新吗?
答:屏幕会固定每16.6ms刷新,底层会给vsync信号,然后给display,但是不会经过app!
但是,底层还是会每隔 16.6ms 发出一个屏幕刷新信号,只是我们 app 不会接收到而已,Display 还是会在每一个屏幕刷新信号到的时候去显示下一帧画面,只是下一帧画面一直是上一次的帧数据 ,CPU/GPU不走绘制流程。见下面的SysTrace图。
一个静止的页面,刷新1帧和100帧有什么区别?
- . 问题: 可能你知道VSYNC,这个具体指啥?在屏幕刷新中如何工作的?
答:当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时会出现的vertical sync pulse(垂直同步脉冲)来保证双缓冲在最佳时间点才进行交换。并且Android4.1后 CPU/GPU的绘制是在VSYNC到来时开始。
- . 问题: 可能你还听过神秘的Choreographer,这又是干啥的?
答:用于实现——“CPU/GPU的绘制是在VSYNC到来时开始”
界面卡顿的原理是怎样的?
- .问题: ViewRootImpl 与 SurfaceFlinger 是怎么通信的?
8). 问题: 可能你还听过屏幕刷新使用 双缓存、三缓存,这又是啥意思呢?
答:双缓存是Back buffer、Frame buffer,用于解决画面撕裂。三缓存增加一个Back buffer,用于减少Jank。
- . 问题: SurfaceView / GLSurfaceView 的底层实现原理?
为什么说频繁的GC会导致卡顿呢?
简而言之, 就是执行GC操作的时候,任何线程的任何操作都会需要暂停,等待GC操作完成之后,其他操作才能够继续运行, 故而如果程序频繁GC, 自然会导致界面卡顿.
- .问题: cpu,Gpu,display,app的关系
数据是从app里面获取得到的,但是要通过cpu计算出来
-
.问题: 通过手动刷新,才会有sync信号,那么更新一次u,vsync会i刷新多少次, 也就是会有多少帧 这个在doframe里面,它会去请求下一帧
-
.问题: 有了同步屏障消息的控制就能保证每次一接收到屏幕刷新信号就第一时间处理遍历绘制 View 树的工作么?
只能说,同步屏障是尽可能去做到,但并不能保证一定可以第一时间处理。因为,同步屏障是在 scheduleTraversals() 被调用时才发送到消息队列里的,也就是说,只有当某个 View 发起了刷新请求时,在这个
3.线下用什么工具检测和分析ui卡顿
3.1 安卓检测原理:
第一种: 计算收到vsync信号到doFrame被调用的时间差,vsync信号间隔是16毫秒一次,大于16毫秒就是掉帧了,如果超过60帧(默认60),就打印log提示开发者检查主线程是否有耗时操作。
第二种: handler
第三种: ASM插桩
3.2. 市面上的一些卡顿监控工具,经常被用来监控ANR(卡顿阈值设置为5秒),这其实很不严谨
首先,5秒只是发生ANR的其中一种原因(Touch事件5秒未被及时消费)的阈值,而其他原因发生ANR的阈值并不是5秒;
另外,就算是主线程卡顿了5秒,如果用户没有输入任何的Touch事件,同样不会发生ANR,更何况还有后台ANR等情况。真正意义上的ANR监控方案应该是类似matrix里面那样监控signal信号才算
方案一: handler检测卡顿
主线程从ActivityThread的main方法开始,准备好主线程的looper,启动loop循环。在loop循环内,无消息则利用epoll机制阻塞,有消息则处理消息。因为主线程一直在loop循环中,所以要想在主线程执行什么逻辑,则必须发个消息给主线程的looper然后由这个loop循环触发,由它来分发消息,然后交给msg的target(Handler)处理。举个例子:ActivityThread.H。
public static void loop() {
......
for (;;) {
Message msg = queue.next(); // might block
......
msg.target.dispatchMessage(msg);
}
}
loop循环中可能导致卡顿的地方有2个:
queue.next() :有消息就返回,无消息则使用epoll机制阻塞(nativePollOnce里面),不会使主线程卡顿。
dispatchMessage耗时太久:也就是Handler处理消息,app卡顿的话大多数情况下可以认为是这里处理消息太耗时了
问题: 为什么主线程Looper.loop进行消息分发耗时就代表APP卡顿?
答:为了保证应用的平滑性,每一帧渲染时间不能超过16ms,达到60帧每秒;如果UI渲染慢的话,就会发生丢帧,这样用户就会感觉到不连贯性,我们称之为Jank(APP卡顿);VSync信号由SurfaceFlinger实现并定时发送(每16ms发送),Choreographer.FrameDisplayEventReceiver收到信号后,调用onVsync方法组织消息发送到主线程处理。Choreographer主要功能是当收到VSync信号时,去调用使用通过postCallBack设置的回调函数,在postCallBack调用doFrame,在doFrame中渲染下一帧;FrameDisplayEventReceiver相关代码如下:
Choreographer.java
/**
* FrameDisplayEventReceiver继承自DisplayEventReceiver接收底层的VSync信号开始处理UI过程。
* VSync信号由SurfaceFlinger实现并定时发送。FrameDisplayEventReceiver收到信号后,
* 调用onVsync方法组织消息发送到主线程处理。这个消息主要内容就是run方法里面的doFrame了,
* 这里mTimestampNanos是信号到来的时间参数。
*/
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
mTimestampNanos = timestampNanos;
mFrame = frame;
// 发送Runnable(callback参数即当前对象FrameDisplayEventReceiver)到FrameHandler,请求执行doFrame
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
// 此处mHandler为FrameHandler,该Handler对应的Looper是主线程的Looper
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
通过以上流程可以发现,Android渲染每一帧都是通过消息机制来实现的,最终都会在主线Looper.loop()方法中开始渲染下一帧,因为Looper.loop方法在进行消息分发时是串行执行的,这样如果上一个消息分发时间过长即msg.target.dispatchMessage(msg)执行时间过长,就会导致在VSYNC到来时进行下一帧渲染延迟执行,就不能保证该帧在16ms内完成渲染,从而导致丢帧;所以主线程Looper.loop方法中msg.target.dispatchMessage(msg)执行时间过长就会导致APP卡顿;因此通过检测msg.target.dispatchMessage(msg)执行时间就可以检测APP卡顿;
4. UI卡顿监控方案微信Matrix, 4种方案比较
自动化卡顿检测方案原理
- 方案1:(插入探针, 子线程不断轮询主线程)WatchDog,或者blockCanary 往主线程发消息,然后延迟看该消息是否被处理,从而得出主线程是否卡顿的依据。
- 方案2:(Looper Printer)利用loop循环时的消息分发前后的日志打印(微信线下: matrix使用了这个)
- 方案3:Choreographer FrameCallback(也可以参考微信如何监控帧率)
- 方案4:ASM:****插桩的方式对函数的出入口进行记录****(微信线上: matrix使用了这个)
**4.1 **AnrWatchDog或者blockCanary ****Android系统中,有硬件WatchDog用于定时检测关键硬件是否正常工作, 类似地,在framework层有一个软件WatchDog用于定期检测关键系统服务是否发生死锁事件。 WatchDog功能主要是分析系统核心服务和重要线程是否处于Blocked状态。 AnrWathcDog它的原理, 缺陷,如何改进? 源码: 就2个类 开启一个子线程,死循环往主线程发消息,发完消息后等待5秒,判断该消息是否被执行,没被执行则主线程发生ANR,此时去获取主线程堆栈。 优点:简单,稳定,结果论,可以监控到各种类型的卡顿 缺点:轮询不优雅,不环保,有不确定性,随机漏报 轮询的时间间隔越小,对性能的负面影响就越大,而时间间隔选择的越大,漏报的可能性也就越大。 UI线程要不断处理我们发送的Message,必然会影响性能和功耗

**随机漏报:**ANRWatchDog默认的轮询时间间隔为5秒,当主线程卡顿了2秒之后,ANRWatchDog的那个子线程才开始往主线程发送消息,并且主线程在3秒之后不卡顿了,此时主线程已经卡顿了5秒了,子线程发送的那个消息也随之得到执行,等子线程睡5秒起床的时候发现消息已经被执行了,它没意识到主线程刚刚发生了卡顿。
ANRWatchDog 漏检测的问题,根本原因是因为线程睡眠5s,不知道前一秒主线程是否已经出现卡顿了,如果改成每间隔1秒检测一次,就可以把误差降低到1s内。
ANRWatchDog 会出现漏检测的情况,看图
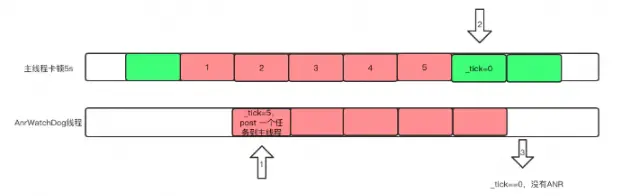
如上图这种情况,红色表示卡顿,
- 假设主线程卡顿了2s之后,ANRWatchDog这时候刚开始一轮循环,将_tick 赋值为5,并往主线程post一个任务,把_tick修改为0
- 主线程过了3s之后不卡顿了,将_tick赋值为0
- 等到ANRWatchDog睡眠5s之后,发现_tick的值是0,判断为没有发生ANR。而实际上,主线程中间是卡顿了5s,ANRWatchDog误差是在5s之内的(5s是默认的,线程的睡眠时长)
针对这个问题,可以做一下优化。
改进:
监控到发生ANR时,除了获取主线程堆栈,再获取一下CPU、内存占用等信息
还可结合ProcessLifecycleOwner,app在前台才开启检测,在后台停止检测
另外有些方案的思路,如果我们不断缩小轮询的时间间隔,用更短的轮询时间,连续几个周期消息都没被处理才视为一次卡顿。则更容易监控到卡顿,但对性能损耗大一些。即使是缩小轮询时间间隔,也不一定能监控到。假设每2秒轮询一次,如果连续三次没被处理,则认为发生了卡顿。在02秒之间主线程开始发生卡顿,在第2秒时开始往主线程发消息,这样在到达次数,也就是8秒时结束,但主线程的卡顿在68秒之间就刚好结束了,此时子线程在第8秒时醒来发现消息已经被执行了,它没意识到主线程刚刚发生了卡顿。
总结: 轮询的时间间隔越小,对性能的负面影响就越大,而时间间隔选择的越大,漏报的可能性也就越
问题: 都把时间设置为5s, 但是anr其他都不是5s!
4.2 Looper Printer(微信用这种方案) BlockCanary就是这种方案!
注意的几个点
1)无法监控的几个, 是如何处理的
2).监控时间dump,这个不一定准确,像oom一样,只是大概率比较准确的,应该如何处理
3).时间差5s, 如何可以说明卡顿了
4)打印, 字符串拼接是否有内存抖动(Matrix就是)
替换主线程Looper的Printer,监控dispatchMessage的执行时间(大部分主线程的操作最终都会执行到这个dispatchMessage中)。这种方案在微信上有较大规模使用,总体来说性能不是很差,matrix就是用这个来实现的。
**缺陷: 需要注意的是,**监听到发生卡顿之后,dispatchMessage 早已调用结束,已经出栈,此时再去获取主线程堆栈,堆栈中是不包含卡顿的代码的。
所以需要在后台开一个线程,定时获取主线程堆栈,将时间点作为key,堆栈信息作为value,保存到Map中,在发生卡顿的时候,取出卡顿时间段内的堆栈信息即可。
不过这种方案只适合线下使用,原因如下:
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);存在字符串拼接,频繁调用,会创建大量对象,造成内存抖动。- 后台线程频繁获取主线程堆栈,对性能有一定影响,获取主线程堆栈,会暂停主线程的运行。
优点:不会随机漏报,无需轮询,一劳永逸
缺点:内存抖动不能用于线上???某些类型的卡顿无法被监控到,但有相应解决方案
**比喻:**打个不太恰当的比方,相当于闭路电视监控只拍下了凶案发生后的惨状,而并没有录下这个案件发生的过程,那么作为警察的你只看到了结局,依然很难判断案情和凶手。
我们记录了整个卡顿过程的多个高频采样堆栈。由此精确地记录下整个凶案发生的详细过程
海量卡顿堆栈后该如何处理?
减轻服务端压力, 我们把堆栈hash后尝试去重,发现排重后只有2个堆栈,而其中某个堆栈重复了59次,我们可以重点关注和处理这个堆栈反映出的卡顿问题。
为什么说是大部分?因为有些情况的卡顿,这种方案从原理上就无法监控到。看到上面的queue.next(),这里给了注释:might block,直接跟你说这里是可能会卡住的,这时候再计算dispatchMessage方法的耗时显然就没有意义了
queue.next()可能会阻塞,这种情况下监控不到。
//Looper.java
for (;;) {
//这里可能会block,Printer无法监控到next里面发生的卡顿
Message msg = queue.next(); // might block
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
}
//MessageQueue.java
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
//......
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
//IdleHandler的queueIdle,如果Looper是主线程,那么这里明显是在主线程执行的,虽然现在主线程空闲,但也不能做耗时操作
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
//......
}
通过看queue.next()的源码发现:
无法监控的3种情况:
主线程空闲时会阻塞next(),具体是阻塞在nativePollOnce(),这种情况下无需监控
Touch事件大部分是从nativePollOnce直接到了InputEventReceiver,然后到ViewRootImpl进行分发
IdleHandler的queueIdle()回调方法也无法监控到
还有一类相对少见的问题是SyncBarrier(同步屏障)的泄漏同样无法被监控到
————————————————
解决办法: 看字节团队的解决方案!
3.2.1监控TouchEvent卡顿(nativePollOnce)
为什么touch事件无法被监控到?
onTouchEvent监控
首先,Touch是怎么传递到Activity的?给一个view设置一个OnTouchListener,然后看一些Touch的调用栈。
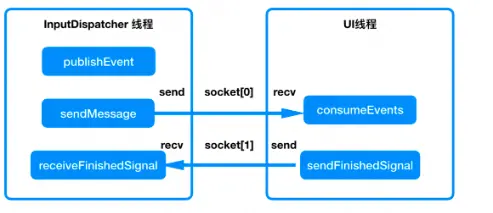
通过PLT Hook,去Hook这对Socket的send和recv方法来监控Touch事件
我们通过PLT Hook,成功hook到libinput.so中的recvfrom和sendto方法,使用我们自己的方法进行替换。当调用到了recvfrom时,说明我们的应用接收到了Touch事件,当调用到了sendto时,说明这个Touch事件已经被成功消费掉了,当两者的时间相差过大时即说明产生了一次Touch事件的卡
3.2.2 监控IdleHandler卡顿
这个方法会在主线程空闲的时候被调用!
IdleHandler任务最终会被存储到MessageQueue的mIdleHandlers (一个ArrayList)中,在主线程空闲时,也就是MessageQueue的next方法暂时没有message可以取出来用时,会从mIdleHandlers 中取出IdleHandler任务进行执行。那我们可以把这个mIdleHandlers 替换成自己的,重写add方法,添加进来的 IdleHandler 给它包装一下,包装的那个类在执行 queueIdle 时进行计时,这样添加进来的每个IdleHandler在执行的时候我们都能拿到其 queueIdle 的执行时间 。如果超时我们就进行记录或者上报
解决办法: hook, 我们只需要把ArrayList类型的mIdleHandlers,通过反射,替换为MyArrayList
3.3 .3监控SyncBarrier泄漏(比较少)
到值卡死的原因: 多线程异步调用导致
当我们每次通过invalidate来刷新UI时,最终都会调用到ViewRootImpl中的scheduleTraversals方法,会向主线程的Looper中post一个SyncBarrier,其目的是为了在刷新UI时,主线程的同步消息都被跳过,此时渲染UI的异步消息就可以得到优先处理。但是我们注意到这个方法是线程不安全的,如果在非主线程中调用到了这里,就有可能会同时post多个SyncBarrier,但只能remove掉最后一个,从而有一个SyncBarrier就永远无法被remove,就导致了主线程Looper无法处理同步消息(Message默认就是同步消息),导致卡死,参考源码frameworks/base/core/java/android/view/ViewRootImpl.java:
什么是SyncBarrier泄漏?在说这个之前,我们得知道什么是SyncBarrier,它翻译过来叫同步屏障,听起来很牛逼,但实际上就是一个Message,只不过这个Message没有target。没有target,那这个Message拿来有什么用?当MessageQueue中存在SyncBarrier的时候,同步消息就得不到执行,而只会去执行异步消息。我们平时用的Message一般是同步的,异步的Message主要是配合SyncBarrier使用。当需要执行一些高优先级的事情的时候,比如View绘制啥的,就需要往主线程MessageQueue插个SyncBarrier,然后ViewRootlmpl 将mTraversalRunnable 交给 Choreographer ,Choreographer 等到下一个VSYNC信号到来时,及时地去执行mTraversalRunnable ,交给Choreographer 之后的部分逻辑优先级是很高的,比如执行mTraversalRunnable 的时候,这种逻辑是放到异步消息里面的。回到ViewRootImpl之后将SyncBarrier移除。
4.3 方案3:Choreographer FrameCallback(也可以参考微信如何监控帧率)
Android 从4.1开始加入 Choreographer 用于同 VSync 机制配合,实现统一调度绘制界面。我们可以设置 Choreographer 类的 FrameCallback 函数,当每一帧被渲染时会触发 FrameCallback 回调,FrameCallback 回调 doFrame(long frameTimeNanos) 函数,一次界面渲染会回调 doFrame,如果两次 doFrame 间隔大于16.6ms 则发生了卡顿。而 1s 内有多少次 callback,就代表了实际的帧率。
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {
// 这里可以统计相邻间隔,判断卡顿,也可以统计doFrame 帧率
Choreographer.getInstance().postFrameCallback(this);
}
});
源码:Choreographer的postFrameCallback()通常用来计算丢帧情况,使用方式如下:
public class FPSFrameCallback implements Choreographer.FrameCallback {
private static final String TAG = "FPS_TEST";
private long mLastFrameTimeNanos = 0;
private long mFrameIntervalNanos;
public FPSFrameCallback(long lastFrameTimeNanos) {
mLastFrameTimeNanos = lastFrameTimeNanos;
mFrameIntervalNanos = (long)(1000000000 / 60.0);
}
@Override
public void doFrame(long frameTimeNanos) {
//初始化时间
if (mLastFrameTimeNanos == 0) {
mLastFrameTimeNanos = frameTimeNanos;
}
final long jitterNanos = frameTimeNanos - mLastFrameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if(skippedFrames>30){
//丢帧30以上打印日志
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
}
mLastFrameTimeNanos=frameTimeNanos;
//注册下一帧回调
Choreographer.getInstance().postFrameCallback(this);
}
}
这种方式优点:使用简单,不仅支持卡顿监控,还支持计算帧率.
缺点就是 , 但其最大的不足在于,无法获取到各个函数的执行耗时,对于稍微复杂一点的堆栈,很难找出可能耗时的函数,也就很难找到卡顿的原因。
另外,通过其他线程循环获取主线程的堆栈,如果稍微处理不及时,很容易导致获取的堆栈有所偏移,不够准确,加上没有耗时信息,卡顿也就不好定位。所以我们需要借助字节码插桩技术来解决这一个痛点问题
:需要另开子线程来获取堆栈信息,会消耗部分系统资源
监控使用Choreographer.FrameCallback, 采样频率设52ms,最终结果是性能消耗带来的影响很小,可忽略:
1)监控代码本身对主线程有一定的耗时,但影响很小,约0.1ms/S;
2)卡顿监控开启后,增加0.1%的CPU使用;
3)卡顿监控开启后,增加Davilk Heap内存约1MB;
4)对于流量,文件可按天写入,压缩文件最大约100KB,一天上传一次
4.4 方式4: ASM插桩
为什么会诞生这个, 因为looperprint,像会在blockCanary出现的问题! 用插桩就可以解决了!
通过前面我们对于Blockcanary的了解,通过Handler虽然能够获取卡顿时的堆栈信息,但是无法获取到方法的执行耗时,所以通过ASM字节码插桩统计方法耗时配合Handle

对于线上卡顿监控,需要了解****字节码插桩****技术。
目前微信的Matrix 使用的卡顿监控方案就是字节码插桩,如下图所示
通过Gradle Plugin+ASM,编译期在每个方法开始和结束位置分别插入一行代码,统计方法耗时,
在 Android 的编译流程中,在 class 文件编译成 dex 之前,我们可以通过 plugin 提供的 Transform 机制,来对编译好的 class 文件进行二次处理,每个Transform 的输出作为下个 Transform 的输入,从而对字节码进行改造。推荐使用 ASM,具体的插桩方法就不在这里说了,后续有机会介绍。
插桩的目的在于:对函数的出入口进行记录,包括动作、方法名称、时间戳,方便我们统计耗时和还原调用栈
实际项目使用中,我们一开始两种监控方式都用上,上报的两种方式收集到的卡顿信息我们分开处理,发现卡顿的监控效果基本相当。同一个卡顿发生时,两种监控方式都能记录下来。 由于Choreographer.FrameCallback的监控方式不仅用来监控卡顿,也方便用来计算实时帧率,因此我们现在只使用Choreographer.FrameCallback来监控app卡顿情况。
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《Android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。

相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
欢迎大家一键三连支持,若需要文中资料,直接扫描文末CSDN官方认证微信卡片免费领取↓↓↓(文末还有ChatGPT机器人小福利哦,大家千万不要错过)

PS:群里还设有ChatGPT机器人,可以解答大家在工作上或者是技术上的问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









