







参考网址:https://www.jianshu.com/p/6282b04fe06a
https://www.elastic.co/guide/en/beats/filebeat/current/index.html
配置方法:https://www.cnblogs.com/louis2008/p/filebeat.html
Filebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件(tail file),并将它们转发给Elasticsearch或Logstatsh进行索引、kafka等。带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
1 工作原理
Filebeat涉及两个组件:查找器prospector和采集器harvester,来读取文件(tail file)并将事件数据发送到指定的输出。
启动Filebeat时,它会启动一个或多个查找器,查看你为日志文件指定的本地路径。对于prospector所在的每个日志文件,prospector启动harvester。每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到您为Filebeat配置的输出。
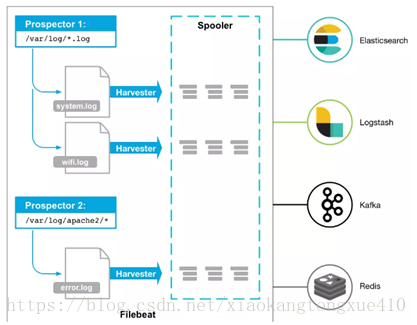
当发送数据到Logstash或Elasticsearch时,Filebeat使用一个反压力敏感(backpressure-sensitive)的协议来解释高负荷的数据量。当Logstash数据处理繁忙时,Filebeat放慢它的读取速度。一旦压力解除,Filebeat将恢复到原来的速度,继续传输数据。
1.1 采集器Harvester
Harvester负责读取单个文件的内容。读取每个文件,并将内容发送到the output,每个文件启动一个harvester, harvester负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。
如果文件在读取时被删除或重命名,Filebeat将继续读取文件。这有副作用,即在harvester关闭之前,磁盘上的空间被保留。默认情况下,Filebeat将文件保持打开状态,直到达到close_inactive状态
关闭harvester会产生以下结果:
1)如果在harvester仍在读取文件时文件被删除,则关闭文件句柄,释放底层资源。
2)文件的采集只会在scan_frequency过后重新开始。
3)如果在harvester关闭的情况下移动或移除文件,则不会继续处理文件。
要控制收割机何时关闭,请使用close_ *配置选项
1.2 查找器Prospector
Prospector负责管理harvester并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。每个prospector都在自己的Go协程中运行。
以下示例将Filebeat配置为从与指定的匹配的所有日志文件中收集行:
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.log
Filebeat目前支持两种prospector类型:log和stdin。每个prospector类型可以定义多次。日志prospector检查每个文件以查看harvester是否需要启动,是否已经运行,或者该文件是否可以被忽略(请参阅ignore_older)。
只有在harvester关闭后文件的大小发生了变化,才会读取到新行。
注:Filebeat prospector只能读取本地文件,没有功能可以连接到远程主机来读取存储的文件或日志。
2 配置
配置文件:$FILEBEAT_HOME/filebeat.yml
按要求清空配置文件内容,并根据需求添加必要配置,filebeat收集日志后发往logstash。配置如下:
#开始配置prospectors
filebeat.prospectors:
#以“-”标明一个prospector开始,输入类型log,根据应用组件配置多个
- input_type: log
#配置文件列表,每一个路径以“- ”开始
paths:
- /var/log/tomcat/httpd-*.log
#- /var/log/messages
#配置文档类型,默认log,按日志来源配置,tomcat日志设置为tomcat
document_type: tomcat
# 在输入中排除符合正则表达式列表的那些行
exclude_lines: ["^DBG",”^debug”]
#每天4h处理约4g-5g数据,每条日志0.2-0.5kb,5*1024*1024/(4*3600)
#大约每秒处理364kb数据,每秒需发送730-1700条日志
filebeat.spool_size: 2048 #攒够2048条日志发送一次
filebeat.idle_timeout: 5s #否则每5s 发送一次
#配置java报错“多行转成一行”
multiline:
pattern: '^[[:space:]]+|^Caused by:'
negate: false
match: after
# Filebeat默认每10s 取一次文件。
scan_frequency: 10s
#- input_type: log #配置第二个prospector
# ...
#输出到logstash
output.logstash:
#配置logstash的host,端口可自行修改,logstash接收Beats端口与之一致即可
hosts: [“localhost:10008”]
注:根据需要添加压缩级别,默认压缩为3
3 启动和停止
3.1 开启filebeat
# cd FILEBEAT_HOME
# nohup ./bin/filebeat -f config/test.conf >>/FILEBEAT_HOME/logs/filebeat.log &
启动多个filebeat配置,新建一个目录(conf)存放多个filebeat的配置文件,
# nohup ./bin/filebeat -f conf/* >>/FILEBEAT_HOME/logs/filebeat.log &
注意:一台服务器只能启动一个filebeat进程。
3.2 停止filebeat
# ps -ef |grep filebeat
# kill -9 $pid
注意: 非紧急情况下,杀进程只能用优雅方式退出。
4 注意问题
4.1 Filebeat如何保持文件的状态?
Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
在Filebeat运行时,每个prospector内存中也会保存文件状态信息,当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
每个prospector为它找到的每个文件保留一个状态。由于文件可以被重命名或移动,因此文件名和路径不足以识别文件。对于每个文件,Filebeat存储唯一标识符以检测文件是否先前已被采集过。
如果您的使用案例涉及每天创建大量新文件,您可能会发现注册文件增长过大。请参阅注册表文件太大?编辑有关您可以设置以解决此问题的配置选项的详细信息。
4.2 Filebeat如何确保至少一次交付?
Filebeat保证事件至少会被传送到配置的输出一次,并且不会丢失数据。 Filebeat能够实现此行为,因为它将每个事件的传递状态存储在注册文件中。
在输出阻塞或未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到接收端确认已收到。如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有收到事件。
发送到输出但在Filebeat关闭前未确认的任何事件在重新启动Filebeat时会再次发送。这可以确保每个事件至少发送一次,但最终会将重复事件发送到输出。
也可以通过设置shutdown_timeout选项来配置Filebeat以在关闭之前等待特定时间。
注意:Filebeat的至少一次交付保证包括日志轮换和删除旧文件的限制。如果将日志文件写入磁盘并且写入速度超过Filebeat可以处理的速度,或者在输出不可用时删除了文件,则可能会丢失数据。
在Linux上,Filebeat也可能因inode重用而跳过行。有关inode重用问题的更多详细信息,请参阅filebeat常见问题解答。
4.3 Filebeat如何保证在日志文件被切割(或滚动rolling)时依然正确读取文件?
Logback日志切割用的是JDK里File#renameTo()方法。如果该方法失败,就再尝试使用复制数据的方式切割日志。查找该方法相关资料得知,只有当源文件和目标目录处于同一个文件系统、同volumn(即windows下的C, D盘)下该方法才会成功,切不会为重命名的后的文件分配新的inode值。也就是说,如果程序里一直保存着该文件的描述符,那么当程序再写日志时,就会向重命名后的文件中写。那么问题来了,filebeat是会一直打开并保存文件描述符的,那么它是怎么得知日志被切割这件事的呢?
如果只用当前文件描述符一路监控到天黑的话,那么当logback把日志重命名后,filebeat仍然会监控重命名后的日志,新创建的日志文件就看不到了。实际上,filebeat是通过close_inactive和scan_frequency两个参数(机制)来应对这种情况的:
(1)close_inactive
该参数指定当被监控的文件多长时间没有变化后就关闭文件句柄(file handle)。官方建议将这个参数设置为一个比文件最大更新间隔大的值。比如文件最长5s更新一次,那就设置成1min。默认值为5min.
(2)scan_frequency
该参数指定Filebeat搜索新文件的频率(时间间隔)。当发现新的文件被创建时, Filebeat会为它再启动一个 harvester 进行监控。默认为10s。
综合以上两个机制,当logback完成日志切割后(即重命名),此时老的harvester仍然在监控重命名后的日志文件,但是由于该文件不会再更新,因此会在close_inactive时间后关闭这个文件的 harvester。当scan_frequency时间过后,Filebeat会发现目录中出现了新文件,于是为该文件启动 harvester 进行监控。这样就保证了切割日志时也能不丢不重的传输数据。(不重是通过为每个日志文件保存offset实现的)















 5146
5146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









