






11.8课堂总结
根据索引删除数据
drop
注意点:
删除指定的索引,必须配合axis使用,axis=1 表示列,axis=0表示的是行
drop()这个方法,返回删除之后的dataframe,原始数据不受影响
指定行列的时候不使用0或1,使用index和columns
del
del 这个方法,只能删除列,不能删除行
而且实在原始数据上做的操作
pandas的对齐操作
四种主要的运算:加add()减sub()乘mul()除div()
加法如下:
import numpy as np
import pandas as pd
print('######series对齐运算####')
ser1 = pd.Series(data=range(10,15),index=list('abcde'))
ser2 = pd.Series(data=range(20,25),index=list('cdefg'))
print('###################ser1')
print(ser1)
print('###################ser2')
print(ser2)
print('###################add()')
ser_obj3 = ser1.add(ser2)
print(ser_obj3)
运行结果如下:

减法,乘法跟加法类似,除法这里特殊提一下:
ser_obj3 = ser1.div(ser2,fill_value=0)
ser_obj3

series对象与dataframe对象做对齐操作
数据类型不同的时候做对齐操作,不支持fill_value

数据清洗
import numpy as np
import pandas as pd
# 先判断是否存在缺失值
df1 = pd.DataFrame([np.random.randint(10,50,4),[1.1,2.2,3.3,]],columns=list('ABCD'))
df1
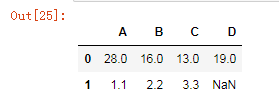
df1.isnull()

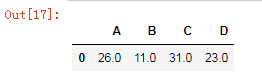
# 删除空值,删除空值所在的行或列
df1.dropna(axis='index')
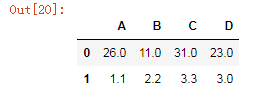
# 填充空值
df1.fillna(3,axis='index')
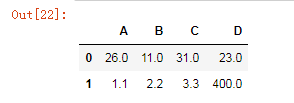
df1.fillna({
'A':100,
'B':200,
'C':300,
'D':400
})
# 判断重复数据
df2 = pd.DataFrame([np.random.randint(10,15,5),[11,12,13,14,15],[11,12,13,14,15]],columns=list('ABCDE'))
df2
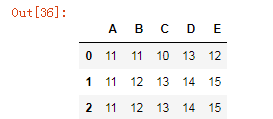
df2.duplicated('A')

# 直接删除重复行数据
df2.drop_duplicates('A')

# 替换
df3 = pd.DataFrame(np.random.randint(-5,10,(3,4)),index=list('abc'),columns=list('ABCD'))
df3

df3.replace(-3,300)

df4 = pd.DataFrame([np.array(['a','1'])],columns=list('AB'))
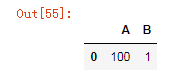
df4.replace(regex=['a'],value=100)
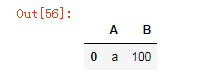
df4.replace(regex=['\d'],value=100)
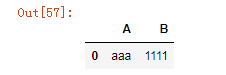
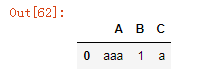
df4.replace({'a':'aaa','1':'1111'})
df4.replace(['a','1'],100)

df5 = pd.DataFrame([np.array(['a','1','a'])],columns=list('ABC'))
df5
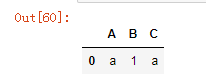
df5.replace({'A':'a'},'aaa')
函数的使用
import numpy as np
import pandas as pd
ser1 = pd.Series(np.random.randint(-10,10,10),index=list('adcdefghop'))
df1 = pd.DataFrame(np.random.randint(-10,10,(4,5)),index=list('abcd'),columns=list('ABCDE'))
def func(x):
print('这是自定义的')
print(x)
print('###############')
print('最大值',np.max(x))
print('最小值',np.min(x))
return np.max(x)-np.min(x)
df1.apply(func,axis='columns')
nt('这是自定义的')
print(x)
print('###############')
print('最大值',np.max(x))
print('最小值',np.min(x))
return np.max(x)-np.min(x)
df1.apply(func,axis='columns')
















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









