







网络知识
-
什么是 HTTPS?
- 项目安全的 HTTP 协议,https 需要 cs 证书,数据加密,端口为443,安全,同一网站 https seo 排名会更高
常见响应状态码

- 项目安全的 HTTP 协议,https 需要 cs 证书,数据加密,端口为443,安全,同一网站 https seo 排名会更高
-
http 请求方法的幂等性及安全性
-
-WSGI

-
RPC
-
CDN
-
SSL(Secure Sockets Layer 安全套接层),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。
-
SSH(安全外壳协议) 为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH最初是UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。SSH在正确使用时可弥补网络中的漏洞。SSH客户端适用于多种平台。几乎所有UNIX平台—包括HP-UX、Linux、AIX、Solaris、Digital UNIX、Irix,以及其他平台,都可运行SSH。
-
TCP/IP
- 虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
- 因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
- 三次握手(SYN/SYN+ACK/ACK)
- 四次挥手(FIN/ACK/FIN/ACK)
- TCP:面向连接/可靠/基于字节流
- UDP:无连接/不可靠/面向报文
- 三次握手四次挥手
- 为什么连接的时候是三次握手,关闭的时候却是四次握手?
- 为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
-
XSS/CSRF
-
HttpOnly 禁止 js 脚本访问和操作 Cookie,可以有效防止 XSS
Mysql数据库
- 索引改进过程
线性结构->二分查找->hash->二叉查找树->平衡二叉树->多路查找树->多路平衡查找树(B-Tree)
Mysql面试总结基础篇
-
https://segmentfault.com/a/1190000018371218
-
Mysql面试总结进阶篇
- https://segmentfault.com/a/1190000018380324
-
深入浅出Mysql
- http://ningning.today/2017/02/13/database/深入浅出mysql/
-
清空整个表时,InnoDB是一行一行的删除,而MyISAM则会从新删除建表
-
text/blob数据类型不能有默认值,查询时不存在大小写转换
-
什么时候索引失效
应尽量避免在 where 子句中使用 != 或 <> 操作符,否则引擎将放弃使用索引而进行全表扫描
尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,即使其中有条件带索引也不会使用,这也是为什么尽量少用 or 的原因
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引
应尽量避免在 where 子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
对于多列索引,不是使用的第一部分,则不会使用索引
以%开头的like模糊查询
出现隐式类型转换
没有满足最左前缀原则
失效场景:

不要在 where 子句中的 “=” 左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描

不适合键值较少的列(重复数据较多的列)比如:set enum列就不适合(枚举类型(enum)可以添加null,并且默认的值会自动过滤空格集合(set)和枚举类似,但只可以添加64个值)
如果MySQL估计使用全表扫描要比使用索引快,则不使用索引 -
什么是聚集索引
B+Tree叶子节点保存的是数据还是指针
MyISAM索引和数据分离,使用非聚集
InnoDB数据文件就是索引文件,主键索引就是聚集索引
Redis 命令总结
为什么这么快?
-
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。
-
基于内存,由 C 语言编写
-
使用多路I/O复用模型,非阻塞 IO
-
使用单线程减少线程间切换
-
数据结构简单
-
自己构建了 VM 机制,减少调用系统函数的时间
-
优势
- 性能高 – Redis 能读的速度是110000次/s,写的速度是81000次/s
- 丰富的数据类型
- 原子 – Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作全并后的原子性执行
- 丰富的特性 – Redis 还支持 publish/subscribe(发布/订阅), 通知, key 过期等等特性
什么是 redis 事务? - 将多个请求打包,一次性、按序执行多个命令的机制
- 通过 multi,exec,watch 等命令实现事务功能
- Python redis-py pipeline=conn.pipeline(transaction=True)
-
持久化方式
- save(同步,可以保证数据一致性)
- bgsave(异步,shutdown时,无AOF则默认使用)
- RDB(快照)
- AOF(追加日志)
-
怎么实现队列
- push
- rpop
-
常用的数据类型(Bitmaps,Hyperloglogs,范围查询等不常用)
- skiplist(跳跃表)
- intset或hashtable
- ziplist(连续内存块,每个entry节点头部保存前后节点长度信息实现双向链表功能)或double linked list
- 整数或sds(Simple Dynamic String)
- String(字符串):计数器
- List(列表):用户的关注,粉丝列表
- Hash(哈希):
- Set(集合):用户的关注者
- Zset(有序集合):实时信息排行榜
-
与 Memcached 区别
- Memcached只能存储字符串键
- Memcached用户只能通过APPEND的方式将数据添加到已有的字符串的末尾,并将这个字符串当做列表来使用。但是在删除这些元素的时候,Memcached采用的是通过黑名单的方式来隐藏列表里的元素,从而避免了对元素的读取、更新、删除等操作
- Redis和Memcached都是将数据存放在内存中,都是内存数据库。不过Memcached还可用于缓存其他东西,例如图片、视频等等
- 虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的Value 交换到磁盘
- 存储数据安全–Memcached挂掉后,数据没了;Redis可以定期保存到磁盘(持久化)
- 应用场景不一样:Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和Session等
-
Redis实现分布式锁
- 使用setnx实现加锁,可以同时通过expire添加超时时间
- 锁的value值可以是一个随机的uuid或者特定的命名
- 释放锁的时候,通过uuid判断是否是该锁,是则执行 delete释放锁
-
常见问题
- 当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级
- 数据过期,进行更新缓存数据
- 初始化项目,将部分常用数据加入缓存
- 请求访问数据时,查询缓存中不存在,数据库中也不存在
- 短时间内缓存数据过期,大量请求访问数据库
- 缓存雪崩
- 缓存穿透
- 缓存预热
- 缓存更新
- 缓存降级
-
一致性Hash算法
-
使用集群的时候保证数据的一致性
基于redis实现一个分布式锁,要求一个超时的参数 -
setnx
-
-
虚拟内存
-
内存抖动
Linux
Unix五种i/o模型
+ 项目select
+ 项目poll
+ 项目epoll
+ 项目并发不高,连接数很活跃的情况下
+ 项目比select提高的并不多
+ 适用于连接数量较多,但活动链接数少的情况
+ 阻塞io
+ 非阻塞io
+ 多路复用io(Python下使用selectot实现io多路复用)
+ 信号驱动io
+ 异步io(Gevent/Asyncio实现异步)
比 man 更好使用的命令手册
*tldr:一个有命令示例的手册
kill -9和-15的区别
*-15:程序立刻停止/当程序释放相应资源后再停止/程序可能仍然继续运行
*-9:由于-15的不确定性,所以直接使用-9立即杀死进程 分页机制(逻辑地址和物理地址分离的内存分配管理方案):
+ 操作系统为了高效管理内存,减少碎片
+ 程序的逻辑地址划分为固定大小的页
+ 物理地址划分为同样大小的帧
+ 通过页表对应逻辑地址和物理地址
分段机制
+ 为了满足代码的一些逻辑需求
+ 数据共享/数据保护/动态链接
+ 每个段内部连续内存分配,段和段之间是离散分配的
查看 cpu 内存使用情况?
+ top
+ free 查看可用内存,排查内存泄漏问题
设计模式
单例模式

工厂模式

构造模式

数据结构和算法
python实现各种数据结构
快速排序

选择排序

插入排序

归并排序

堆排序heapq模块

栈

队列

二分查找

以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
小编为对Python感兴趣的小伙伴准备了以下籽料 !
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑培训的!
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
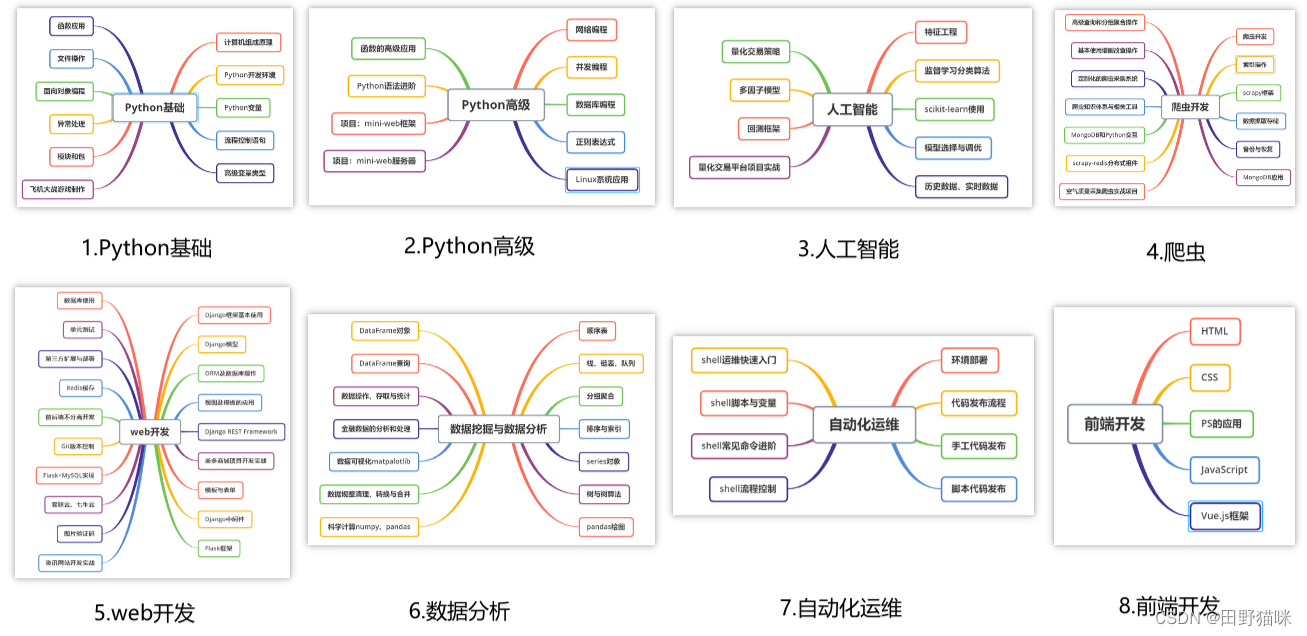
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
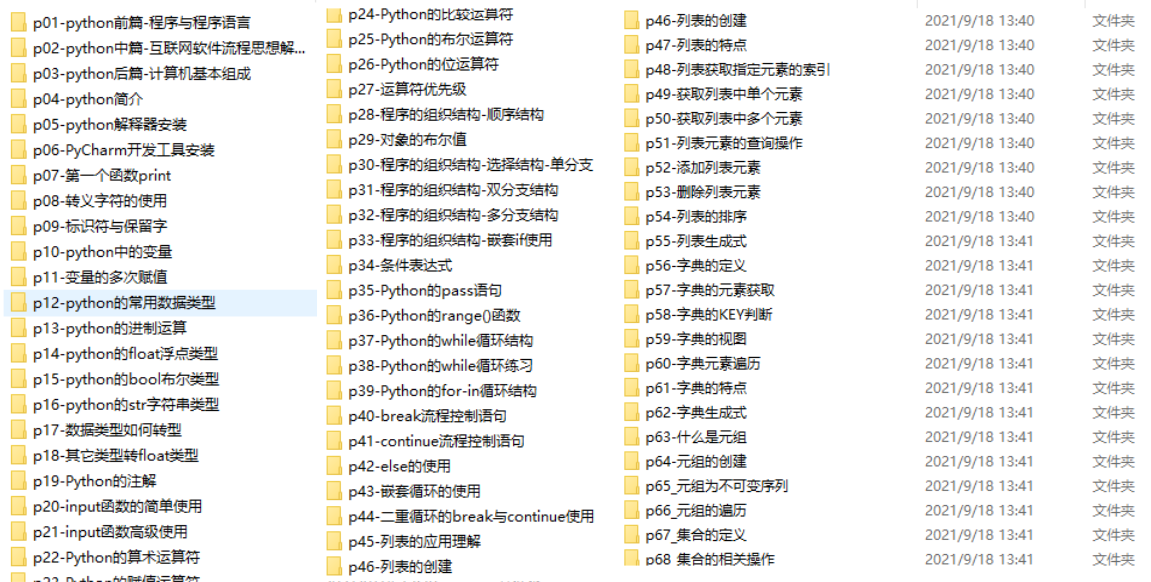
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !















 5009
5009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









