








Apache Mesos 是 Apache 基金会下的一个分布式资源管理框架,它被称为是分布式系统的内核。Mesos 结合容器化技术提供了有效的,跨分布式应用或框架的资源隔离和分享机制,可以做为 Hadoop、Mpi、Hypertable、Spark、 Elasticsearch 等各种分布式应用的资源管理平台。网络上已经有很多关于 Mesos 架构及分配策略的文章博客,这里我将抛开这些基本原理,从实践的角度出发,畅谈 Mesos 的生态圈。我会结合 Marathon、 Chronos、Jenkins、 Spark 等在 Mesos 上的使用实践来介绍人们是如何基于 Mesos 来搭建容器应用分发管理,CI/CD 测试,运维管理以及大数据平台的,同时我也会尝试辩证的分析 Mesos 在上述实践中的利弊。
从去年到现在,我一直在开发基于 Mesos/Docker 的数人云产品,整个团队对 Mesos/Docker 及其周边的工具都在关注及使用中,所以积累了一定的实践经验。目前网上已经有很多关于 Mesos 架构及分配策略的文章,以前我也分享过关于 Mesos 持久化存储的技术。这里我就不再讨论Mesos的原理了,我会从实践的角度出发,聊一下利用 Mesos 我们可以做什么,以及在使用 Mesos 搭建各种平台时,有什么坑,当然,这些坑也不全是我自己碰到的,有一些是其他使用Mesos的伙伴总结出来的。
另外,因为内容比较多,我计划把这个分享做成一个系列,这次我首先简单介绍一下可以运行在Mesos之上的框架,然后主要围绕 Marathon、 Mesos、 Docker、 Chronos 这几个关键词展开本次分享。
首先通过一张图来介绍都有哪些软件可以或者必须运行在Mesos之上,然后, 探讨如何围绕 Marathon、, Mesos、 Docker 搭建一个PaaS 平台,以及其中遇到的问题。
Frameworks On Mesos
这张图是我摘自Mesosphere官网的关于运行在 Mesos 上的不同 Framework。其中不同颜色代表了不同类型的应用。
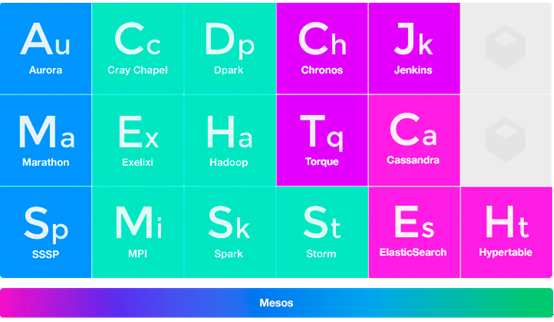
- 蓝色: 支持运行 Long-Running 的应用,我们就是基于这些工具来搭建 PaaS 平台的
- 绿色:大数据处理的工具,这些工具是搭建大数据平台的基础
- 紫色:批处理工具,利用批处理工具可以搭建一个基本的持续集成平台,尤其是 Jenkins
- 红色:大数据存储的工具,其中 Cassandra 是无中心分布式存储的, Es 是一个基于Apache Lucene(Tm)的开源搜索引擎
除此之外,比较常见的工具还有 - Singularity: 同时支持运行 Long-Running 应用与批处理 Job
如何将应用部署到 Mesos 平台
无论是开源的应用还是我们自己开发的python,Java等应用,目前主要有三种方式来让应用使用 Mesos 资源池里面的资源。我们可以通过下图来看一下:
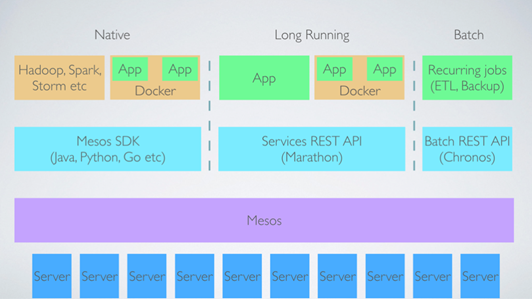
Frameworks-On-Mesos/Native
这种方式就是为你的应用开发相应的调度组件来调用 Mesos 的 Api 接口(应用的 Scheduler),同时包装你应用的 Executor,将其下发到 Mesos-Slave 上运行, 并且我们一般会将应用的 Scheduler 通过 Marathon 部署,这样可以利用 Marathon 的特性来保证应用 Scheduler 的高可用。譬如,Cisco Sponsored 的开源项目 Elasticsearch On Mesos 就是通过这种让 Es 做为Framework 运行在 Mesos 上的。还有 Myriad/Yarn-On-Mesos。 这种方式优点是可定制程度高,可以使用 Mesos 的各种特性,譬如动态保留,持久化存储,超售等。 缺点是这种方式工作量比较大, 额外增加了开发负担。
将应用的模块拆解并 Docker 容器化/Long-Running
然后将这些模块各自独立的发布到 Marathon 上,当然 Docker 容器化并不是必须的,但是为了降低环境依赖,避免在 Slave 机器上装过多的东西,我们最好还是容器化。以 Hdfs 为例,我们将 Hdfs-Namenode, 与 Hdfs-Datanode 做为 Marathon 的两个 App 部署到 Mesos 上,并通过 Constraints 和环境变量来设置两者通信,相较于 Mesosphere 的 Hdfs-On-Mesos(Hdfs 作为框架运行于 Mesos 之上), 这种方式看上去很low,没有 Mesosphere 的方式优雅,但是在实际使用过程中,运维更喜欢将 Namenode,Datanode 分清楚,单独部署的方式,毕竟运维需要了解软件的架构。Mesosphere 的框架方式隐藏掉了 Hdfs 的细节,部署方便,但同时也增加了 Debug 的难度。所以说这个需要权衡。
批处理
这种方式比较直观,不再介绍。
下面结合 PPT 中的图片简单介绍下 Es-On-Mesos的架构,首先我们需要将 Es 的调度器部署到 Mesos-Master 或者某台机器上,并注册到 Mesos-Master 上, 从而 Es 的调度器就会收到 Mesos-Master Offer 的资源,Es 的调度器接受了资源后就会将Es的执行器(和Es的节点)部署到相应的 Mesos-Slave 机器上;接下来,Es 的节点实例会通过注册到 Zookeeper 集群来发现彼此;进而,Es 组成了一个集群了。为了保证 Es 运行到 Mesos 上,我们看到实际上社区做了很多改造。
Myriad/Yarn-On-Mesos 也使用了类似的做法来将 Yarn 部署到 Mesos 集群上,额外需要注意的是,部署成功后,Nm与Rm就可以绕开Mesos-Master直接通信了。另外,如果一个公司只是使用 Yarn,那么这种做法非常鸡肋,但是如果追求 Yarn 与其他应用的资源混用,那么就有意义。
PaaS
PaaS 想要解决的问题简单说就是让用户关注自己的应用,PaaS服务提供方负责解决应用的高可用及失败重启的问题。前面我们已经提到过,利用Mesos,Marathon,Docker等相关的技术可以搭建一个PaaS平台,同时,通过开发一些插件,并结合持续集成,我们可以通过这个PaaS平台为用户解决很多问题。另外,我们可以认为这一套PaaS平台的用户就是开发者,维护方就是 Devops。这里是一个基本完善的基于 Marathon 的 PaaS 平台需要的东西:
- Marathon
- Mesos
- 私有的 Docker 镜像仓库,建立自己公司的私有Docker仓库是非常有必要的,首先是国外的官方镜像源太慢,其次是公司有安全性的考虑。
- Jenkins,这个我们前面提到过,利用jenkins搭建持续集成环境,这里将是开发与运维交接应用的地方,我们可以认为jenkins的输入就是开发在Github上提交的代码,Jenkins的输出就是 Docker 镜像,然后通过Marathon部署到Mesos上对外提供服务,Jenkins输出部分无需开发Touch。
- Github/Gitlab,或者其它的代码控制仓库,这个相信大家都明白,开发需要它来做代码版本控制,好多时候Jenkins也需要它来做构建的触发器。
- Metrics,Metrics, Metrics!!! 重要的事情说三遍。无论是Marathon还是Mesos,在可视化监控方面还都有所欠缺。有很大的定制开发工作量,这也是Mesosphere正在干的活。关于Metrics,我们后面细聊。
- 日志归档,以及Debug的问题,通过Marathon部署分布式应用与单机部署应用很大的不同就是增加了Debug的难度,分布式应用由于其异步性,没有全局时钟,应用日志在全局看是乱序的。这为日志的归档,基于日志的审计,以及基于日志的Debug都带来了很大难度。
Marathon
相信很多同学已经了解 Marathon,因为这几乎成为了Mesos的标配,我这里只简单介绍下它的一些比较关键的技术点。作为一个PaaS工具,Marathon在UI方面没有商业版的好,譬如Heroku,Tutum等。我们在使用Marathon时,需要自己额外定制一些东西,譬如根据Metrics进行Scale等,这些我们后面会讲到。
- Marathon是集群的Init.D, 应用的启动器。
- 尽管Mesos有自己容器化技术,我仍然推荐使用Docker,Mesos自己的容器化技术仍然没有解决环境依赖问题,还需要在宿主机上安装一些东西。但是Docker可以解决这个问题。
- 扩展方便,这也是借了容器化的东风。相较于虚拟化,容器镜像更小,同时启动也更快。这里需要注意的是, 对于Docker来说,Docker容器启动快,并不代表Docker容器里承载的服务启动快。以一个Java程序为例,虽然Docker容器已经run起来,其实,里面的Java程序还需要一段时间去加载。 Docker容器是无法感知到程序的初始化状态的。
- 利用Marathon可以实现蓝绿部署。这里Marathon只负责启动蓝,绿两个环境,这其中容错,流量切换等还需要应用自身支持才行。
- Restfulapi,Marathon的Restful接口非常完善,我平时都是通过它来完成操作的。
- 再一个就是利用Haproxy做服务发现,和负载均衡。
使用Marathon,我们可以:
- 在通过Marathon部署我们的应用时,我们不再需要Supervisord, 使用Health Check代替Supervisord效果会更好。Marathon支持基于Tcp和Http协议的健康检查,它的大体逻辑是Marathon会周期性的扫描应用的健康检查路径,如果响应时间连续n次超出阈值,那么Marathon会直接重启这个应用。这就是我们所说的 Fastfailed,只要应用响应过慢,我们就应该杀掉它,因为响应过慢的应用会大大拖慢全局服务的响应速度。我们不再需要容器内部的失败重启,应该直接杀掉容器。
- Constraints: 通过Constraints,我们可以限制应用部署在指定的一台或者几台slave机器上,这类应用一般是有状态应用,或存储型应用,必须将应用的数据目录挂载出来的情况下;又或者应用需要部署在有特殊配置的Slave机器上,譬如,应用需要使用Gpu资源,而只有特定的几台机器有Gpu资源时。
- Resources: Resources 与 Constraints 的不同在于Resources是可以量化的。所以Resources的切分粒度要比Constraints更细,而Constraints对资源的量化只有0或1两种。所以使用Resource时会更灵活,随之而来的问题时,只有 CPU、内存、 端口、带宽等可以量化,其它的资源我们可能需要为Mesos集成资源的量化模块支持。
- Force Pull Image:可以每次部署应用时强制拉取一次 Docker 镜像。考虑到性能损耗的问题,我不推荐这种做法,更好的办法是拉取配置。
- Docker Image 的预热: 为了缩短应用的部署时间,最好是先把Image Pull到Slave机器上,同时可以避免 Marathon 因镜像下载问题频繁发布应用,如果使用内网的Registry时镜像的拉取问题可以不用考虑。另外有人提到通过网络存储部分解决镜像的拉取问题。
- 应用部署的数量上来之后,瓶颈在Zookeeper。实际使用中,成千上万个应用实例在Marathon上频繁的失败重启会导致Zookeeper阻塞,具体原因跟Zookeeper的性能有关。
Private Docker Registry
搭建私有镜像仓库是必须的,网上也已经有很多关于私有镜像仓库的搭建方法了,我这里只说一下需要重点考虑的几点,
- 第一个就是存储策略。一般来说,我们需要为我们的Registry准备数据盘,并提前规划好大小,特别要注意的是要把Inode设置大些,Docker小文件比较多。这个可以借助一些开源的工具来做,比如,Devicemapper就有相应的格式化工具。另一个就是存储的Driver,现在比较常见的是Devicemapper,Aufs,这两个之间的优劣可以参照数人云的FAQ或者我的博客。一般建议Centos用Devicemapper,Ubuntu用Aufs。
- 第二个就是权限管理的问题,运维为了控制Registry的Size,我们可以配置registry为有权限的Push,和无权限的Pull。这样也解决了Slave的部署问题,同时又不会导致Registry的大小失控。
- 最后一个就是我们最好为Registry配置一个Frontend,这样便于维护,搜索,和删除无用的Docker Images。
Docker
关于Docker,有两点需要注意的:
- 第一个是Docker镜像的制作方式。我们可以认为一般有两种 Docker 镜像制作方式,第一种就是制作一个Docker的Base Image,然后在启动时动态拉取可执行程序;第二种,基于程序的的Release版本来做Docker Image的Tag。这两种方式都可以,第二种方式更直观一些,只是增加了些运维成本,需要定时回收老的Tag。
- 第二尤其要注意的是异常退出的Docker容器回收问题。目前Mesos可以设置定时回收他自己容器Garbage,但是无法回收异常退出的Docker容器。Marathon不停重试发布异常的应用会导致磁盘被压爆。
服务发现
目前在 Mesos 社区常见的有如下三种服务发现方式
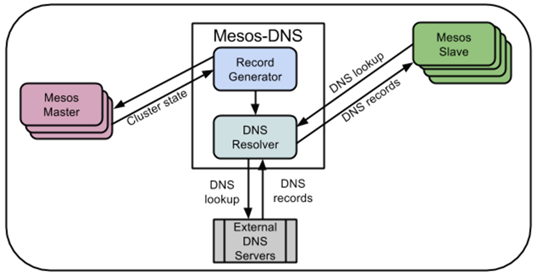
- Mesos-DNS
Mesos-DNS 仍在紧锣密鼓的开发之中,Mesos-DNS 是无状态的,可以自由的Replica,所以我们可以通过为每个Slave部署Mesos-DNS 的方式来保证高可用;同时,Mesos-DNS 支持Restfulapi,调用方便。通过下图我们可以大致看出 Mesos-DNS 通过监听 Mesos-Master 来将发现的服务地址生成DNS解析,(并同步到外部的DNS服务器,如有必要),内部的服务发现就可以直接通过内部的DNS解析来保证。
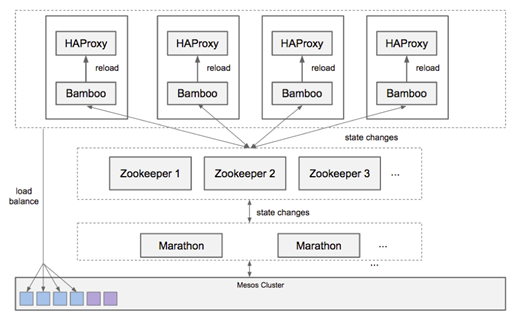
- Bamboo/Haproxy
基于 Bamboo/Haproxy 的服务发现技术使用十分广泛,Bamboo通过监听Marathon来动态的更新Haproxy里面的服务映射。与 Mesos-DNS 类似, Haproxy 也是无状态的并且支持 Restfulapi ,局限是Bamboo只能通过监听Marathon来进行应用的服务发现。
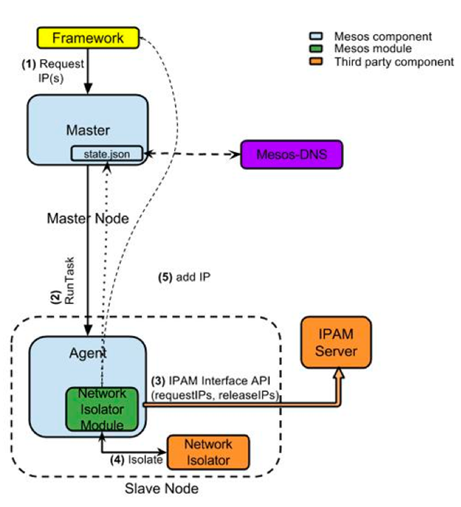
- 一容器一IP
作为 Mesos 当中的一容器一 IP 机制,其设计目标之一在于建立一套可插拔架构,允许用户从现有第三方网络供应商处选择解决方案并作为网络实现基础。对此作者没有过多研究,摘抄官方的架构图及组件解释:
- 负责为即将启用的容器指定 IP 要求的框架/调度标签。这是一项可选服务,能够在不带来任何副作用的前提下将一容器一 IP 能力引入现有框架当中。
- 由一个 Mesos Master 节点与一个 Mesos Agent 节点共同构建的 Mesos 集群。
- 一套第三方 IP 地址管理(简称 IPam)服务器,负责根据需要进行 IP 地址分配,并在 IP 地址使用完毕后将其回收。
- 第三方网络隔离方案供应程序负责对不同容器系统加以隔离,并允许运维人员通过配置调整其可达性及路由方式。
- 作为轻量级 Mesos 模块被加载至 Agent 节点当中的网络隔离模块将负责通过调度程序进行任务要求审查,同时利用 IP 地址管理与网络隔离服务为对应容器提供 IP 地址。在此之后,其会进一步将IP地址交付至 Master 节点以及框架。 虽然 IP 分配与网络隔离功能完全可以由单一单元负责实现,不过立足于概念层面,Mesos 提供了两项不同的服务方案。其一设想由两家彼此独立的服务供应程序分别提供IP地址管理与网络隔离服务。举例来说,其中之一利用 Ubuntu Fan 实现 IP 地址分配,而另一方则利用 Calico 项目进行网络隔离。
受此启示,笔者正在尝试将 Docker-Weave 集成到现有的 Paas 平台当中来。
负载均衡
这里主要探讨 Mesos-DNS 和 Haproxy 的负载均衡。我可能不应该把 Mesos-DNS 作为负载均衡放在这里,DNS 与负载均衡还是有点儿不同的。我们可以认为Mesos-DNS只有roundrobin(或者随机转发)的负载均衡策略,而 Haproxy 的负载均衡策略就比较多了,除 Roundrobin 之外,Haproxy 还支持最小链接,IP哈希等多种策略。另外,需要提到的是, Mesos-DNS 与 Haproxy 都支持配置的动态加载。
调度
我这里的调度指的是PaaS平台应该按什么策略将应用部署到哪一台Slave上,这里我特别想拿Docker-Swarm 的调度策略来与Mesos的调度策略做对比,两者的的调度策略切入点,或者说维度非常不一样。 前者是从Docker的角度出发,而后者由于更Generic,是从资源的角度出发。如果纯从使用Docker来说, Docker-Swarm的策略更给力。
- Docker-Swarm 对容器的调度已经相当丰富:
通过参数 Constraint 将容器发布到带有指定label的机器上。譬如将 Mysql 发布到Storage==SSD 的机器上来保证数据库的IO性能;
通过参数 Affinity 将容器发布到已经运行着某容器的机器上,或者已经Pull了某镜像的机器上;
通过参数 Volumes-From, Link, Net 等将容器自动发布到其依赖的容器所在的机器上;
通过参数 Strategy 可以指定 Spread,Binpack和random 3种不同 Ranking Node 策略,其中 Spread 策略会将容器尽量分散的调度到多个机器上来降低机器宕机带来的损失,反之binpack策略会将容器尽量归集到少数机器上来避免资源碎片化,Random策略将会随机部署容器。
- 由于 Mesos 更加 Generic,其在容器调度方面稍显欠缺,目前我们可以通过设置主机Attribute或者Resources的限制来将容器调度到指定的机器上。下面是Resource 和 Attributes的相关例子。
Resource:
Cpus:24;Mem:24576;Disk:409600;Ports:[21000-24000,30000-34000];Bugs(Debug_Role):{A,B,C}’
Attributes:
‘Rack:Abc;Zone:West;Os:Centos5;Level:10;Keys:[1000-1500]’
Metrics&Auto-Scaling
对于PaaS平台来说,监控是必不可少的,而这也恰好是Marathon/Mesos欠缺的,需要很多的定制开发。一般来说,我们需要从三个维度:物理主机层面、Docker 层面和应用业务层面来立体监控。物理主机层面的监控方案已经非常成熟;Docker层面的监控一般是使用Cadvisor或Sysdig等监控软件;应用层的业务逻辑监控需要与业务绑定。
另一个问题就是自动扩展,首先明确下自动扩展的定义,我们可以认为自动扩展就是根据业务负载动态的调整资源。自动扩展主要包括下面三个问题:
- 自动扩展的触发器: 由于自动扩展是依赖于业务的,所以说触发器也是依赖于具体场景的。譬如说根据CPU或者内存的Metrics负载,或者根据App的请求失败率,又或者如果我们已经预估了每天的访问高峰,那么就可以用定时触发的机制。
- 怎样扩展: 一般来说,自动扩展分为两层,Iaas层与应用层: Iaas层一般需要调用Iaas层的Api去增加或者减少机器资源;而应用层则是通过调用Marathon的Api去伸缩应用实例。
- 弹性/扩展策略: 增加或者减少多少资源是一个需要不断优化的问题。简单点,我们可以根据实际业务制定固定的资源扩展粒度,并逐步调整;更高级一点就是引入机器学习的方法,根据历史负载动态确定资源扩展的Size。
Log&Debug
前面我们已经提过,分布式应用与普通应用不同,其日志分布在多台未知的机器上。所以我们需要将日志采集到一个地方来集中管理。目前比较常见的日志方案是Elk,这里主要说一下Docker的日志问题。收集Docker里面应用的日志主要有两种方法:
- 将应用的日志输出到 Stdout/Stderr,对于这种方式我们可以通过 Logspout/Heka 来采集日志:这种方式在Docker异常退出时会丢掉部分应用日志。
- 将应用的日志输出到固定目录并通过 -V 命令挂载出来,对于这种方式,我们可以通过 Logstash 采集宿主机固定目录的日志。
作者简介:周伟涛,数人科技技术总监/研发总监 嘉宾介绍:现数人科技云平台负责人,曾就职于国际开源解决方案供应商 Red Hat, 红帽认证工程师, Mesos contributor,高级 Python 开发工程师。 是国内较早一批接触使用Docker,Mesos等技术的开发者。
http://geek.csdn.net/news/detail/53574















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









