









数据库同步中间件Canal+Otter - 前日篇(1)
启 - 我们为什么需要数据库跨机房同步
随着业务的增长和技术的演进,在应用架构上,我们经历了单一用用架构->垂直应用架构->分布式应用架构的发展。对应的,后台数据库也出现了分布式的解决方案。读写分离,负载均衡读写以及两点双写集群甚至于多点多写集群这些,都离不开数据库的同步。一般的,这些同步都是在同一机房内的。
渐渐的,我们的业务扩展到了全国各地甚至与全世界各地。我们不能也不再满足于将应用和数据库部署在一个机房之中。在多个机房中,我们部署相同的服务。那么一个比较严峻的问题就是数据库跨机房的镜像如何做,也就是我们如何保证不同机房间的数据一致性?
承 - 跨机房同步的要求
举个例子,假设我们在北京和深圳各部署了一个机房。快递员和客户都按照所在位置来接入离自己最近的机房。假设我从北京发了一票快递到深圳,那我快递员在收件时,我的这票快递的数据在北京的机房。经过收件入仓,中转到深圳时,在深圳的机房必须有这条快递的记录,这样快递员才会被分配这个运单并更新这个运单的状态。同时,对这个运单的更新在深圳机房完成,我访问的北京机房也必须同步到这个运单的最新状态。
CAP理论在这里,P已经是背景条件,我们肯定要做。接下来就是在C和A中取得平衡。
可能有人会想到通过应用去访问这两个机房,去双写,这个是一个明显的重C轻A的方案。或者通过微服务去实现双写。但是对于未来多个机房,一个运单可能跨越多个机房,应用双写很难做,并且建立一个新机房,我们就要修改应用,这不是一个明智之举。同时,应用去双写还涉及到分布式事务的问题,影响应用效率。
对于我们的业务,我们每天的运单量很大,但是客户对于快递当前的状态以及快递员对于状态的更新并不要求那么敏感,客户最关心最后运单是否送到,快递员最关心他今天送了多少单赚了多少钱。我们更倾向于一个重A轻C的方案。同时,我们保证数据的最终一致性即可。
参考nigix的微服务架构系列博客:https://www.nginx.com/blog/event-driven-data-management-microservices/ 我们可以利用如下的思路去做: 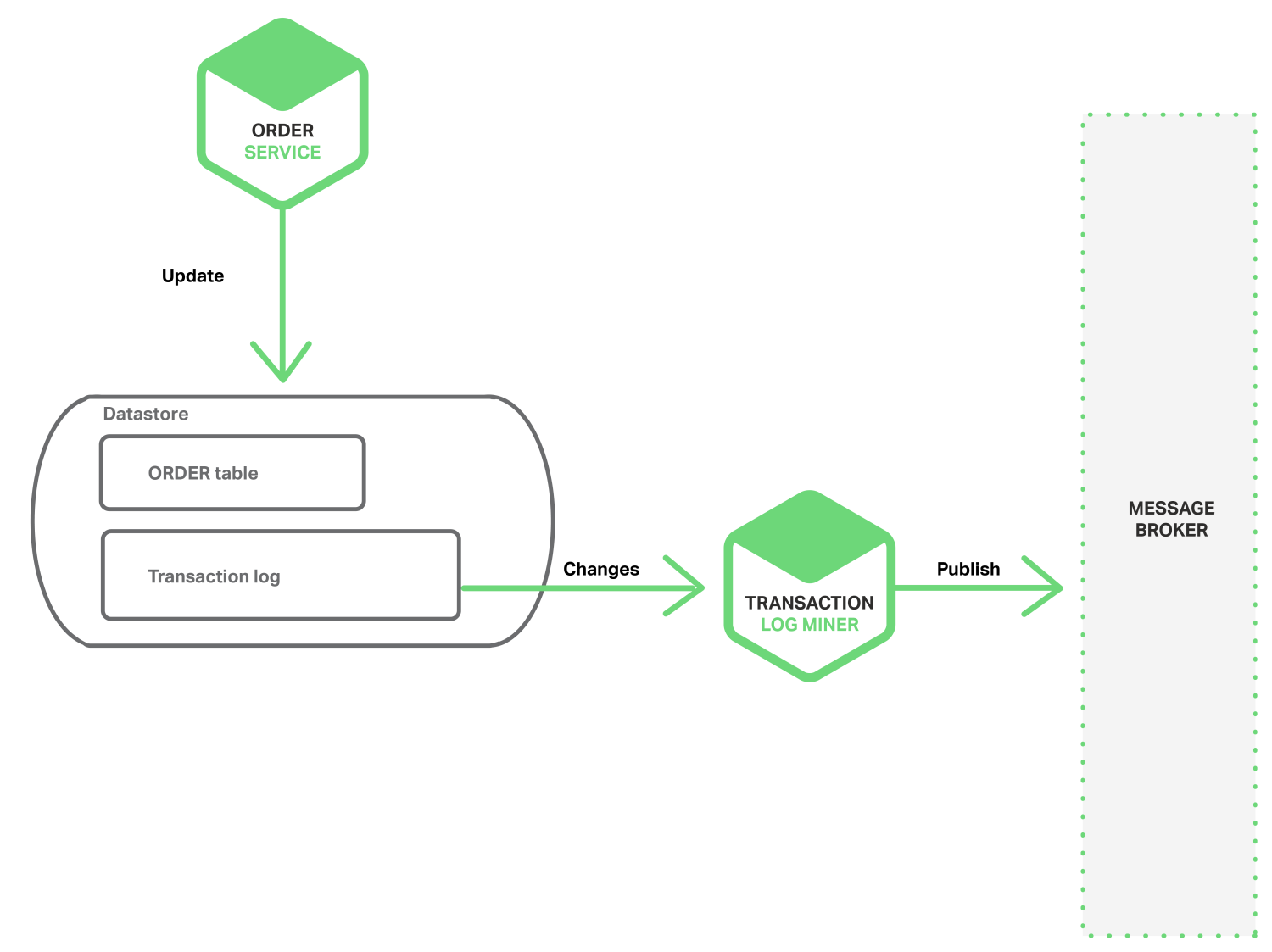
MySQL在执行transaction时,会产生binlog记录。MySQL本身有自己的主从同步机制: 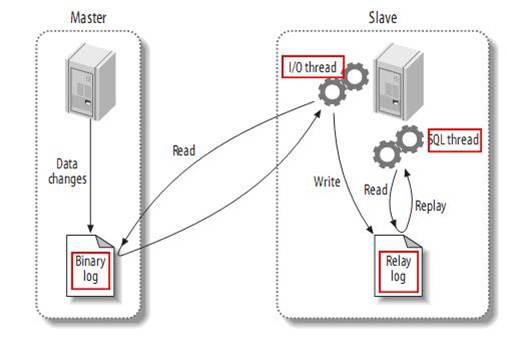
1. master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
2. slave将master的binary log events拷贝到它的中继日志(relay log);
3. slave重做中继日志中的事件,将改变反映它自己的数据。
MySQL本身的binlog主从同步的限制:
首先,架构单一,不灵活:MySQL本身支持双主同步,不会发生回环的原因是执行relay log中的sql不会再被写回binlog。多机房同步一般采用如下架构: 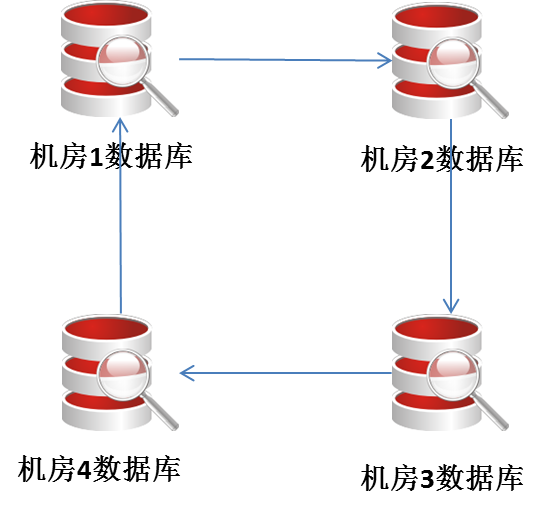
注意,这里的同步不能采用默认配置的自增ID,否则会丢失数据。需要配置好步长以及起始值。
第二,主从同步受限于同构表级别的同步。而且,不能控制是否同步DDL。
第三,MySQL的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率很比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施。DML和DDL的IO操作是随即的,不是顺序的,成本高很多。
第四,MySQL的主从同步传输的binlog包是完整的binlog,未经压缩,有时候网络压力会很大。
转 - 更合适的同步方案Canal+Otter
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。ps. 目前内部使用的同步,已经支持mysql5.x和oracle部分版本的日志解析。这时,Canal这个基于日志增量订阅&消费支持的中间件诞生了。
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
目前,阿里利用Canal+Otter同步的数据量级:
- 同步数据量6亿
- 文件同步1.5TB(2000w张图片)
- 涉及200+个数据库实例之间的同步
- 80+台机器的集群规模
结 - 为什么选择Canal+Otter
利用Canal+Otter,我们可以实现:
1.更灵活的架构,多机房同步可以这么做: 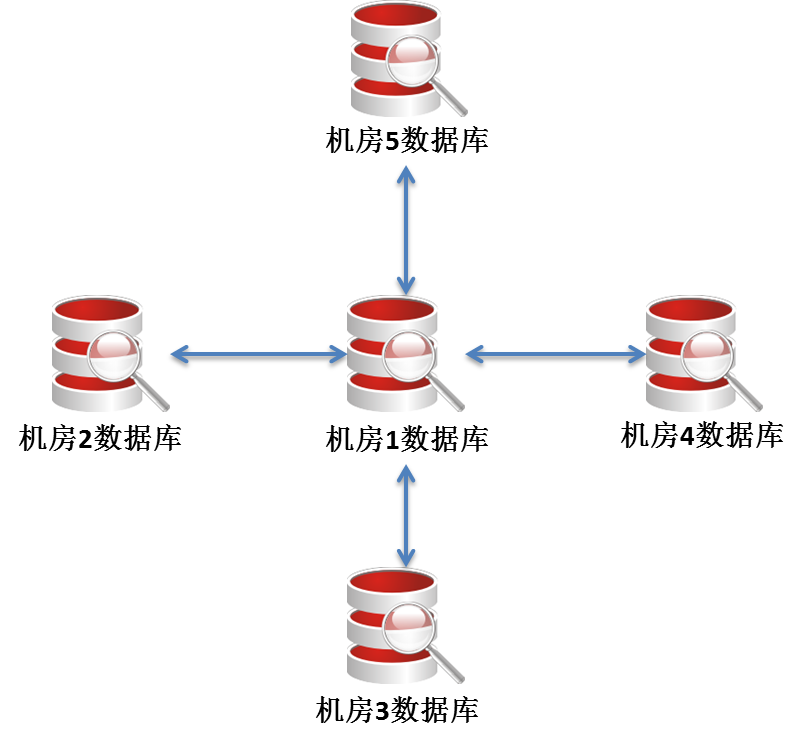
2.异构表之间也可以同步,同时,可以控制不同步DDL以免出现数据丢失和不一致。
3.Canal+Otter可以实现一个表一线程多个表多线程的同步,速度更快。同时会压缩简化要传输的binlog,减少网络压力。
4.双A机房同步. 目前mysql的M-M部署结构,不支持解决数据的一致性问题,基于otter的双向复制+一致性算法,可一定程度上解决这个问题,实现双A机房.
http://blog.csdn.net/zhxdick/article/details/50808040















 2971
2971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









