







目录
决策树是一种树形结构,它每一个内部节点都表示一个属性的判断,每一个分支表示的是一种结果的输出,最后的叶子节点是代表一种分类的结果。
决策树比较适合分析离散数据,如果是连续数据要先转成离散数据然后再进行分析。下面以一个例题来分析:
| RID | age | income | student | credit_rating | Class:buys_computer |
| 1 | youth | high | no | fair | no |
| 2 | youth | high | no | excellent | no |
| 3 | middle_aged | high | no | fair | yes |
| 4 | senior | medium | no | fair | yes |
| 5 | senior | low | yes | fair | yes |
| 6 | senior | low | yes | excellent | no |
| 7 | middle_aged | low | yes | excellent | yes |
| 8 | youth | medium | no | fair | no |
| 9 | youth | low | yes | fair | yes |
| 10 | senior | medium | yes | fair | yes |
| 11 | youth | medium | yes | excellent | yes |
| 12 | middle_aged | medium | no | excellent | yes |
| 13 | middle_aged | high | yes | fair | yes |
| 14 | senior | medium | no | excellent | no |
根据上边的表格,我们假设决策树为二叉树,如下图,当然,我们可以训练出很多决策树,下边这个是其中一种情况。
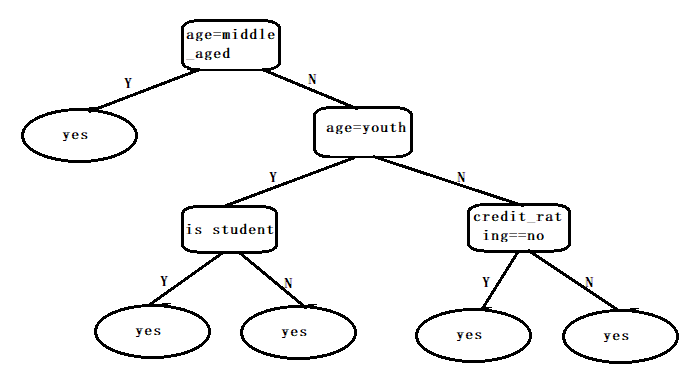
决策树学习的步骤
- 特征的选择:特征选择主要是用来决定用那些特征来做判断,每个样本可能会有很多属性,例如我们的例题,我们通过特征来选择相关度高的属性,简单来说就是选择比较容易分类的属性。选择特征的准则:信息增益
ID3算法:信息增益计算公式

C4.5算法:信息增益的算法倾向于首先选择因子数较多的变量,改进为增益率,公式如下:

CART算法:CART决策树的生成就是递归的构建二叉决策树的过程,CART用基尼系数最小化准则来进行特征选择,生成二叉树。基尼系数计算:

- 决策树生成:特征选择好后,从根节点出发,对节点计算所有的信息增益,选择最大的信息增益作为节点特征,根据该特征的不同取值建立子节点,使用相同的办法选择该节点的子节点,直到信息增益很小或者没有特征可以选取为止。
- 剪枝操作:剪枝操作主要是为了防止过拟合产生,决策树很容易会导致过拟合。
决策树优缺点
优点
- 决策树易于理解和解释,可以可视化分析,容易提取出规则;
- 可以同时处理标称型和数值型数据;
- 比较适合处理有缺失属性的样本;
- 能够处理不相关的特征;
- 测试数据集时,运行速度比较快;
- 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
缺点
- 容易发生过拟合;
- 容易忽略数据集中属性的相互关联;
- 对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向;信息增益准则对可取数目较多的属性有所偏好(典型代表ID3算法),而增益率准则(CART)则对可取数目较少的属性有所偏好,但CART进行属性划分时候不再简单地直接利用增益率尽心划分,而是采用一种启发式规则)(只要是使用了信息增益,都有这个缺点)。
- ID3算法计算信息增益时结果偏向数值比较多的特征。
对例题代码生成决策树
#导入包
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
#读入数据
Dtree = open('AllElectronics.csv','r')
reader = csv.reader(Dtree)
#获取第一行数据
headers = reader.__next__()
#print(headers)
#定义两个列表
featureList = []
labelList = []
for row in reader:
#把label存入list
labelList.append(row[-1])
rowDict = {}
for i in range(1,len(row)-1):
rowDict[headers[i]] = row[i] #建立一个数据字典
featureList.append(rowDict) #把数据字典存入list
因为我们的数据都是字符,所以在这里,我们要对数据进行处理,将它转换成0-1格式
#把数据转换成0-1表示
vec = DictVectorizer()
x_data = vec.fit_transform(featureList).toarray()
print("x_data:"+str(x_data))
#打印属性名称
print(vec.get_feature_names())
print("labelList:"+str(labelList))
#把标签转换成0-1表示
lb = preprocessing.LabelBinarizer()
y_data = lb.fit_transform(labelList)
print("y_data:"+str(y_data))转换后的代码如下,1代表的属于此属性,0代表不属于此属性,结果如下图:

#创建决策树模型
model = tree.DecisionTreeClassifier(criterion ='entropy') #criterion默认为基尼系数,在这里#我设置为熵,也就是用ID3算法
#输入数据建立模型
model.fit(x_data,y_data)这个时候模型建立完成,其实代码实现已经完成了,我们需要将决策树打印出来,如下代码
在完成代码前需要完成两个工作
- 先打开命令提示符输入:pip install graphviz
- 需要下载画图安装包: Graphviz
- 根据自己电脑的操作系统进行下载安装,完成后,我们需要将安装好的文件下的bin目录添加到环境变量里边,操作如下:
先找到该路径,复制该路径:
![]()
进入此电脑,右击选择属性:


完成后,就可以运行下边的代码了,要还是出错,可以重新启动编辑代码的软件。
import graphviz
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = vec.get_feature_names,
class_names = lb.classes_,
filled = True,
rounded = True,
special_character = True)
graph = graphviz.Source(dot_data)
graph.render('computer')结果如下图所示,就是生成的决策树:
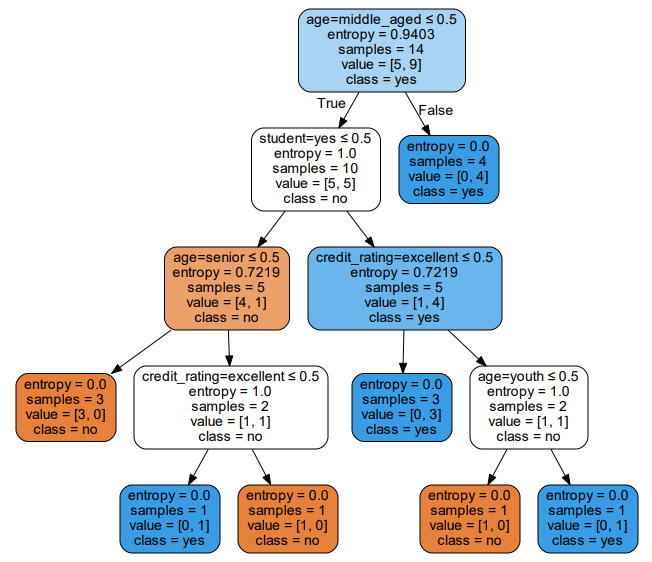

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









