







对于从事统计自然语言处理来说,了解概率论、信息论以及语言学知识都是很有必要的。
一、下面内容主要介绍了在统计自然语言处理中需要了解的概率论基础。
概率
如果P(A)作为事件A的概率,Ω是试验的样本空间,则概率函数满足下面三条公理:
- 非负性 P(A) >= 0
- 规范性 P(Ω) = 1
- 可列可加性:对于不相交的集合Aj ∈F
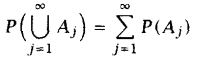
条件概率和独立性
假设事件B的概率已知,那么事件A发生的条件概率为(P(B) > 0):
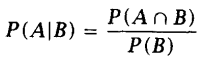
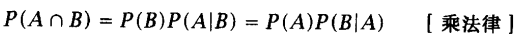
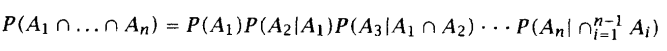
在统计自然语言处理中,上面那个链式法则很有用处,比如推导马尔可夫模型的性质。
贝叶斯定理
由条件概率和链式规则推得:
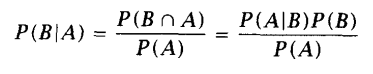
右边的分母P(A)可以看作是归一化常数,以保证其满足概率函数的性质。
如果我们感兴趣的仅仅是事件发生的相对可能性,这时可以忽略分母:
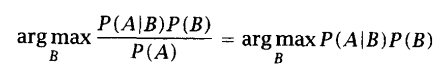
随机变量
设X为一离散型随机变量,其全部可能的值为{a1,a2,···}。那么:
pi = P(X = ai), i = 1, 2, ····
称为X的概率函数。
P(X <= x) = F(x), x∈R
称为X的分布函数。
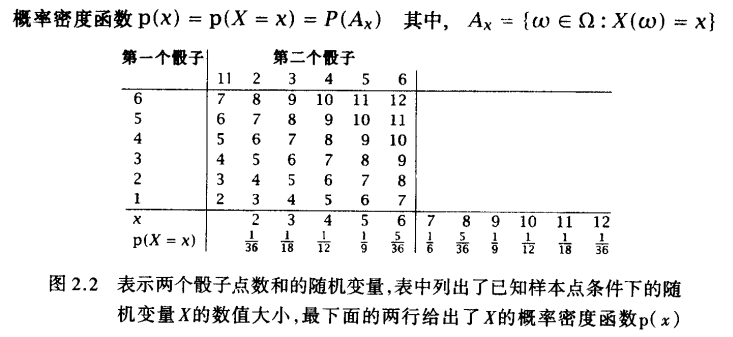
期望和方差
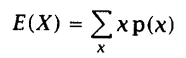
联合分布和条件分布
设两个离散随机变量X和Y,它们的联合密度函数可以写为:
描述其中单个随机变量的概率密度函数称为边缘密度函数:
标准分布
离散分布函数:二项分布
重复一个只有两种输出的实验,并且每次实验之间相互独立时,我们认为实验结果服从二项分布(例如抛硬币实验)。
在自然语言处理中,语料库中的句子间肯定不是完全相互独立的。但是为了简化问题的复杂性,我们通常可能会做独立性假设,假设一个句子的出现独立于它前面的其他句子,近似认为它们服从二项分布。
当实验有两个以上结果时,二项分布问题就转化为多项式分布(multi-nomial distribution)。
连续分布函数:正态分布
1、 概率论基本概念-概率;
2、 概率论基本概念-最大似然估计;
3、 概率论基本概念-条件概率(概率的乘法规则)
4、 概率论基本概念-贝叶斯法则(全概率公式)
例题:
一个多义词某一义项被使用的概率为1/100 000。
现有一程序判断该词在某个句子中是否使用了该义项。
如果句子中使用了该义项,程序判为“使用”的概率为0.95。
如果句子中没使用该义项,程序判为“使用”的概率为0.005。
问:该程序判断句子使用该词的这一义项的结论是正确的概率是多大?
设G:句子中使用该词的这一义项,T:程序判断句子使用该词的这一义项
P(G) = 1/100 0000 = 0.000 01
P(G’) = 1-P(G) = 0.999 99
P(T|G) = 0.95
P(T|G’) = 0.005
于是可得:
P(G|T) = [P(T|G)P(G)]/[P(T|G)P(G)+P(T|G’)P(G’)]≈0.002
5、 概率论基本概念-随机变量
6、 概率论基本概念-二项式分布B(n,p)
在NLP中,一般以句子为处理单位,为了简化问题的复杂性,通常假设一个句子的出现独立于它前面的其他语句,句子的概率分布近似地被认为符合二项式分布。
7、 概率论基本概念-联合概率分布和条件概率分布【看课本去】
8、 概率论基本概念-贝叶斯决策理论(统计方法处理模式分类问题的基本理论之一)
先验概率、后验概率
9、 概率论基本概念-期望和方差
期望值指随机变量所取值的概率平均。
例题:
某个网页主菜单上有6个关键词,每个关键词被点击的概率一样,过一段时间后,这6个关键词分别被点击1,2,…,6次。
那么,平均每个关键词被点击次数的期望值就是:
E(N) = SUM(t)*p(w) = (1+2+3…+6)*1/6 = 7/2
其中t为关键词被点击次数,p为关键词被点击概率;
一个随机变量的方差描述的是该随机变量的值偏离其期望值的程度。如果X为一随机变量,那么,其方差var(X)为:
var(X) = E((X-E(X))2) = E(X2) – E2(X)
X的标准差就是sqrt(var(X))
二、信息论基础
信息是个相当宽泛的概念,很难用一个简单的定义将其完全准确的把握。然而,对于任何一个概率分布,可以定义一个称为熵(entropy)的量,它具有许多特性符合度量信息的直观要求。这个概念可以推广到互信息(mutual information),互信息是一种测度,用来度量一个随机变量包含另一个随机变量的信息量。熵恰好变成一个随机变量的自信息。相对熵(relative entropy)是个更广泛的量,它是刻画两个概率分布之间距离的一种度量,而互信息又是它的特殊情形。
信息熵
——随机变量不确定度的度量
设p(x)为随机离散变量X的概率密度函数,x属于某个符号或者字符的离散集合 X:
p(x) = P(X = x), x ∈ X
熵表示单个随机变量的不确定性的均值,随机变量的熵越大,它的不确定性越大,也就是说,能正确估计其值的概率越小。熵的计算公式 :
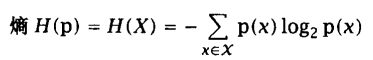
将负号移入对数公式内部:
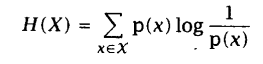
上式实际上表达的是一个加权求值的概念,权重就是随机变量X的每个取值的概率。
用E表示数学期望。如果X~p(x),则随机变量g(X)的期望值可表示为:

当

注:X的熵又解释为随机变量 
熵的属性
- H(X) >= 0;
- H(X) = 0, 当且仅当随机变量X的值是确定的,没有任何信息量可言;
- 熵值随着信息长度的增加而增加。
例子:世界杯足球赛冠军、中文书的信息量和冗余度。
信息的作用
信息的作用在于消除不确定性,自然语言处理的大量问题就是寻找相关信息。
不确定性U,信息I,新的不确定性: U’= U - I
如果没有信息,任何公式或者数字的游戏都无法排除不确定性。合理利用信息,而非玩弄什么公式和机器学习算法,是做好搜索的关键。
例子:网页搜索
联合熵和条件熵
如果(X,Y)是一对离散随机变量,其联合概率分布密度函数为p(x,y),(X,Y)的联合熵H(X,Y)定义为:

已知随机变量X的情况下随机变量Y的条件熵:

上式实际上表示的是在已知X的情况下,传输Y额外所需的平均信息量。
例子:自然语言的统计模型,一元模型就是通过某个词本身的概率分布,来消除不确定因素;而二元及更高阶的语言模型还是用了上下文的信息,那就能准确预测一个句子中当前的词汇了。
熵的链式法则:
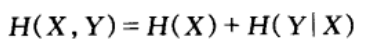
互信息
根据熵的链式法则,我们有如下的计算公式:
H(X,Y) = H(X) + H(Y|X) = H(Y) + H(X|Y)
所以有:
H(X) - H(X|Y) = H(Y) - H(Y|X)
这个差值称为随机变量X和Y之间的互信息(mutual information),用I(X;Y)表示。
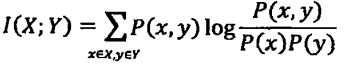

互信息是一个取值在0到min(H(X), H(y))之间的函数,当X和Y完全相关时,取值为1;当二者完全无关时,取值为0。
互信息被广泛用于度量一些语言现象的相关性。例如可以用于词的聚类和语义消岐。
例子:机器翻译中词义的二义性问题
相对熵
相对熵是两个随机分布之间距离的度量。在统计学中,它对应的是似然比的对数期望。相对熵D(p||q)度量当真实分布为p而假定分布为q时的无效性。
例如,已知随机变量的真实分布为p,可以构造平均描述长度为H(p)的码。但是如果使用针对分布q的编码,那么在平均意义上就需要H(p) + D(p||q)比特来描述这个随机变量。
给定两个概率密度函数p(x)和q(x),它们的相对熵(relative entropy)又称为Kullback-Leibler(KL)距离:
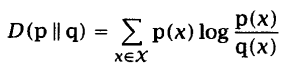
结论:
- 对于两个完全相同的函数,它们的相对熵等于零。
- 相对熵越大,两个函数差异越大;反之,相对熵越小,两个函数的差异越小。
- 对于概率分布或者概率密度函数,如果取值均大于零,相对熵可以对量两个随机分布的差异性。
Google自动问答系统,采用类似方法衡量两个答案的相似性。
互信息与相对熵

交叉熵
设 X~p(x),q(x)为我们估计的近似p(x)的一个概率分布,则p(x)和q(x)的交叉熵表示为:

因为H(X)的值一般是固定不变的,因此交叉熵的最小化等同于相对熵的最小化,即估计出概率分布和真实数据分布之间的差值。
模型的交叉熵越低,一般就意味着它在应用中的性能越好。
混乱度
在设计语言模型时,我们通常用混乱度(perplexity)衡量一个语言模型的好坏。

小结
语言模型是为了用上下文预测当前的文字,模型越好,预测的越准,那么当前文字的不确定性 就越小。
信息熵正是对不确定性的衡量,因此可以想象信息熵能够直接用来衡量语言模型的好坏。
当然,因为有了上下文的条件,所以对于高阶的语言模型,应该用条件熵。
如果再考虑从训练语料和真实应用的文本中得到的概率函数有偏差,就需要再引入相对熵的概念。
贾里尼克从条件熵和相对熵出发,定义了一个称为语言模型复杂度(Perplexity)的概念,直接衡量语言模型的好坏。复杂度有很清晰的物理含义,它是在给定上下文的条件下,句子中的每个位置平均可以选择的单词数量。一个模型的复杂度越小,每个位置的词就越确定,模型越好。
1 · 信息论基础概念--熵(entropy)
熵又称为自信息(self-information),可以视为描述一个随机变量的不确定性的数量。它表示信源X每发一个符号所提供的平均信息量。一个随机变量的熵越大,它的不确定性越大,那么,正确估计其值的可能性就越小。越不确定的随机变量越需要大的信息量用以确定其值。
例如:假设a、b、c、d、e、f这6个字符在某一简单语言中随机出现,每个字符出现的概率是:1/8,1/4,1/8,1/4,1/8,1/8。那么,每个字符的熵为:
H(P) = -SUM(P(x)*logP(x))
= -[4*1/8*log(1/8) + 2*1/4*log(1/4)]
= 5/2 bit
这个结果表明,我们可以设计一种编码,传输一个字符平均只需要2.5个bit:
字符:a b c d e f
编码:100 00 101 01 110 111
1、信息论基本概念-联合熵和条件熵
联合熵:描述一对随机变量平均所需要的信息量;
即:H(X,Y) = -SUM(p(x,y)*log(p(x,y)))
2、信息论基本概念-互信息
互信息是一个均衡非负的信息测度,I(X;Y)反映的是在知道了Y的值以后X的不确定性的减少量。可以理解为Y的值透露了多少关于X的信息量。
3、信息论基本概念-相对熵
相对熵又称KL差异、KL距离,是衡量相同事件空间中两个概率分布相对差距的测度。
4、信息论基本概念-交叉熵
交叉熵就是衡量估计模型与真实概率分布之间的差异情况。
5、信息论基本概念-困惑度
在设计语言模型时,我们通常用困惑度来代替交叉熵衡量语言模型的好坏。
语言模型设计的任务就是寻找困惑度最小的模型,使其最接近真实语言的情况。
6、信息论基本概念-噪声信道模型

7、支持向量机-线性分类
8、支持向量机-线性不可分
9、支持向量机-构造核函数
参考 《Elements of Information Theory》、《Foundations of Statistical Natural Language Processing》、 《统计自然语言处理》、《数学之美》
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









