






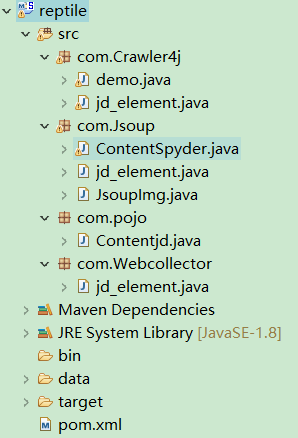
1.安装maven、jdk等,myeclipse配置好二者环境。
2.代码
(pom.xml和各个jd_element.java)
运行:右键jd_element.java->Run as->Java Application
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>reptile</groupId>
<artifactId>reptile</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://github.com/CrawlScript/WebCollector -->
<dependency>
<groupId>cn.edu.hfut.dmic.webcollector</groupId>
<artifactId>WebCollector</artifactId>
<version>2.52</version>
</dependency>
<!-- https://github.com/yasserg/crawler4j -->
<dependency>
<groupId>edu.uci.ics</groupId>
<artifactId>crawler4j</artifactId>
<version>4.4.0</version>
</dependency>
</dependencies>
</project>
Contentjd.java
package com.pojo;
public class Contentjd {
private String title;
private String img;
private String price;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
}
Jsoup.jd_element.java
package com.Jsoup;
import java.net.URL;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.pojo.Contentjd;
public class jd_element {
public static void main(String[] args) throws Exception {
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
String startTime = df.format(new Date());// newDate()为获取当前系统时间,也可使用当前时间戳
List<Contentjd> contents1 = parseJD("Java");
// if (contents1 != null && contents1.size() > 0) {
// for (Contentjd con : contents1) {
// //System.out.println("title:" + con.getTitle());
// }
// }
String endTime = df.format(new Date());
Date d1 = df.parse(startTime);
Date d2 = df.parse(endTime);
long time = (d2.getTime() - d1.getTime());
int count = contents1.size();
System.out.println("-----jsoup爬取耗时" + time + "毫秒/" + count + "条-----");
}
public static List<Contentjd> parseJD(String keywords) throws Exception {
//获取请求https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword="+keywords+"&enc=utf-8";
//解析网页(就是js页面对象)
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
//System.out.println(element.html());
Elements elements = element.getElementsByTag("li");
ArrayList<Contentjd> contents = new ArrayList<>();
for (Element el : elements) {
//图片地址
String img = el.getElementsByTag("img").eq(0).attr("src");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
// System.out.println("======================");
// System.out.println(img);
// System.out.println(price);
// System.out.println(title);
Contentjd content = new Contentjd();
content.setImg(img);
content.setTitle(title);
content.setPrice(price);
contents.add(content);
}
return contents;
}
}

WebCollector.jd_element.java
package com.Webcollector;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.pojo.Contentjd;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.RegexRule;
public class jd_element extends BreadthCrawler {
private final static String crawlPath = "/code/myeclipseworkplace/reptile/data/webcollector";
//F:\code\myeclipseworkplace\reptile\data\webcollector
//static String keywords = "Java";
private final static String seed1 = "https://search.jd.com/Search?keyword=Java&enc=utf-8";;
RegexRule regexRule = new RegexRule();
public jd_element() {
super(crawlPath, false);
//添加爬取种子,也就是需要爬取的网站地址,以及爬取深度
CrawlDatum datum = new CrawlDatum(seed1).meta("depth", "1");
addSeed(datum);
//设置线程数,根据自己的需求来搞
setThreads(1);
//添加正则表达式规则
regexRule.addRule("http://.*");
}
@Override
public void visit(Page page, CrawlDatums next){
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
String startTime = df.format(new Date());// newDate()为获取当前系统时间,也可使用当前时间戳
Elements elements = page.select("div[id=J_goodsList]>ul>li");
//String text = page.select("div[id=J_goodsList]").text();
ArrayList<Contentjd> contents = new ArrayList<>();
for (Element el : elements) {
//System.out.println("test" + el.text());
//图片地址
String img = el.select("img").attr("src");
String price = el.select("div[class=p-price]>strong").text();
String title = el.select("div[class=p-name p-name-type-2]>a").text();
// String img = el.getElementsByTag("img").eq(0).attr("src");
// String price = el.getElementsByClass("p-price").eq(0).text();
// String title = el.getElementsByClass("p-name").eq(0).text();
// System.out.println("======================");
// System.out.println(img);
// System.out.println(price);
// System.out.println(title);
Contentjd content = new Contentjd();
content.setImg(img);
content.setTitle(title);
content.setPrice(price);
contents.add(content);
}
String endTime = df.format(new Date());
Date d1 = null;
try {
d1 = df.parse(startTime);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Date d2 = null;
try {
d2 = df.parse(endTime);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long time = (d2.getTime() - d1.getTime());
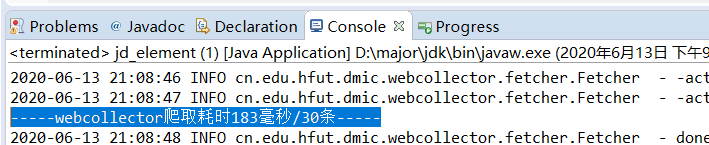
System.out.println("-----webcollector爬取耗时" + time + "毫秒/" + contents.size() + "条-----");
}
public static void main(String[] args) throws Exception {
//测试
jd_element crawler = new jd_element();
crawler.start(2);//运行爬虫,可通过入参控制同步或异步方式运行
}
}
Crawler4j.jd_element.java
package com.Crawler4j;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.regex.Pattern;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.pojo.Contentjd;
import edu.uci.ics.crawler4j.crawler.CrawlConfig;
import edu.uci.ics.crawler4j.crawler.CrawlController;
import edu.uci.ics.crawler4j.crawler.Page;
import edu.uci.ics.crawler4j.crawler.WebCrawler;
import edu.uci.ics.crawler4j.fetcher.PageFetcher;
import edu.uci.ics.crawler4j.parser.HtmlParseData;
import edu.uci.ics.crawler4j.robotstxt.RobotstxtConfig;
import edu.uci.ics.crawler4j.robotstxt.RobotstxtServer;
import edu.uci.ics.crawler4j.url.WebURL;
public class jd_element extends WebCrawler {
private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg" + "|png|mp3|mp4|zip|gz))$");
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase();
return !FILTERS.matcher(href).matches() && href.startsWith("https://search.jd.com/search");
}
@Override
public void visit(Page page) {
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
String startTime = df.format(new Date());// newDate()为获取当前系统时间,也可使用当前时间戳
String url = page.getWebURL().getURL();
//System.out.println("URL: " + url);
ArrayList<Contentjd> contents = new ArrayList<>();
// 判断page是否为真正的网页
if (page.getParseData() instanceof HtmlParseData) {
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();
String html = htmlParseData.getHtml();// 页面html内容
Document doc = Jsoup.parse(html);// 采用jsoup解析html,这个大家不会可以简单搜一下
Element element = doc.getElementById("J_goodsList");
// System.out.println(element.html());
Elements elements = element.getElementsByTag("li");
if(elements.size()==0){
return;
}
for (Element el : elements) {
// 图片地址
String img = el.getElementsByTag("img").eq(0).attr("src");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
// System.out.println("======================");
// System.out.println(img);
// System.out.println(price);
// System.out.println(title);
Contentjd content = new Contentjd();
content.setImg(img);
content.setTitle(title);
content.setPrice(price);
contents.add(content);
}
}
String endTime = df.format(new Date());
Date d1 = null;
try {
d1 = df.parse(startTime);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Date d2 = null;
try {
d2 = df.parse(endTime);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long time = (d2.getTime() - d1.getTime());
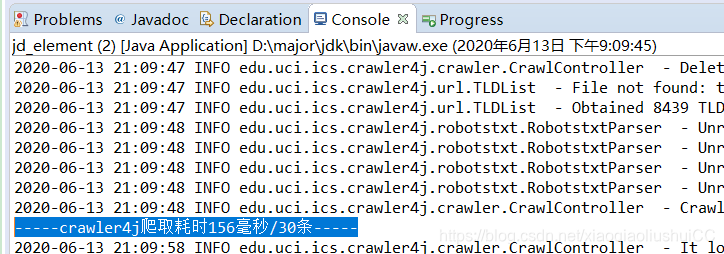
System.out.println("-----crawler4j爬取耗时" + time + "毫秒/" + contents.size() + "条-----");
}
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "/code/myeclipseworkplace/reptile/data/crawler4j/";
int numberOfCrawlers = 1;
CrawlConfig config = new CrawlConfig();
config.setCrawlStorageFolder(crawlStorageFolder);
config.setMaxDepthOfCrawling(0);//深度
// Instantiate the controller for this crawl.
PageFetcher pageFetcher = new PageFetcher(config);
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
//String keywords = "Java";
controller.addSeed("https://search.jd.com/Search?keyword=Java&enc=utf-8");
CrawlController.WebCrawlerFactory<jd_element> factory = jd_element::new;
controller.start(factory, numberOfCrawlers);
}
}














 3731
3731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









