









关于Kswapd的理解(一)
之前跟踪了MemAvailable的计算方式,其中watermark的计算花了很多精力,在学习的过程中看到一些资料中说watermark是给swapd使用的,于是乎,研究一下看看咯
本部分主要记录两个方面:
- 对于kswapd这个东西,从初学者(我)的角度出发会考虑哪些内容?
- 跟踪kswapd 初始化结构部分;
1. KSwapd机制
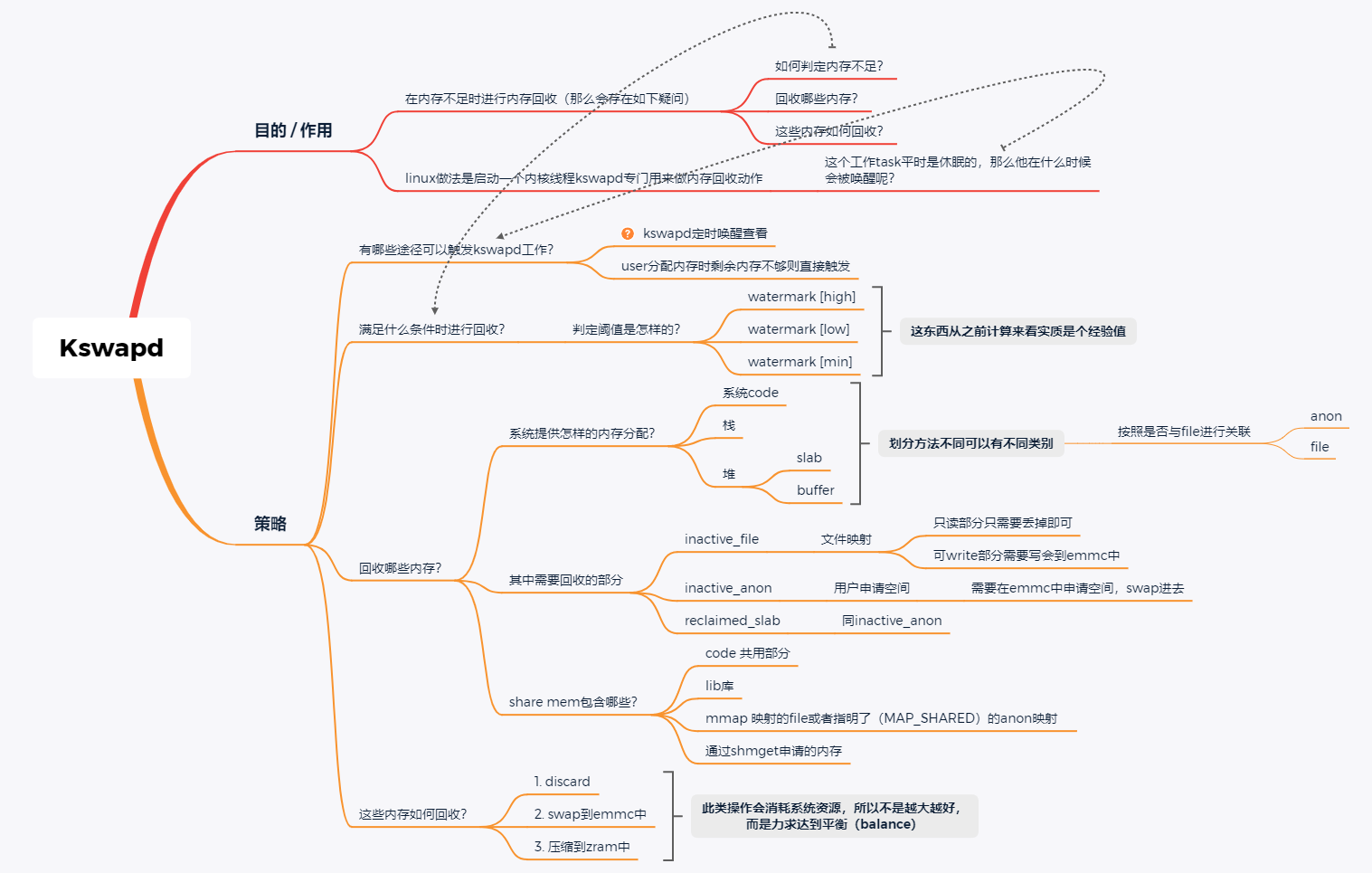
上图是还没有跟踪kswapd code的时候,对自己提出的一些疑问和自身的理解,主要是如下内容:
- kswapd 机制用来做什么:内存不足时回收内存;
- kswapd 机制的载体是什么:启动一个内核线程用于回收mem,平时进入sleep状态;
- kswapd 线程满足什么条件会被唤醒:当前来看分配mem时低于watermark[high] 的时候会被唤醒;
- kswapd 机制会回收哪些内存:anon & file ,即我们俗称的cache;
- kswapd 机制如何回收:从根本上讲,主要是discard、swap到emmc、zram等几种方式;
- kswapd 机制回收内存的具体策略是:还在学习中,后续持续补充;
2. code 跟踪
接下来具体来跟踪code来理解kswapd
2.1 kswapd 初始化
初始化部分的调用逻辑非常简单:

这部分平平无奇:主要逻辑就是kthread_run 起一个线程运行kswapd这个功能函数;
//task 初始化部分,这种task很明确的,在init的时候run起来,在需要的时候唤醒;
static int __init kswapd_init(void)
{
int nid;
swap_setup();
for_each_node_state(nid, N_MEMORY) //每个node run一个task
kswapd_run(nid);
hotcpu_notifier(cpu_callback, 0);
return 0;
}
int kswapd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
int ret = 0;
if (pgdat->kswapd)
return 0;
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);//起一个线程执行kswapd
if (IS_ERR(pgdat->kswapd)) {//失败后处理,不重要
BUG_ON(system_state == SYSTEM_BOOTING);
pr_err("Failed to start kswapd on node %d\n", nid);
ret = PTR_ERR(pgdat->kswapd);
pgdat->kswapd = NULL;
}
return ret;
}
2.2 swapd 功能函数
这里是本小节中最核心的部分了:
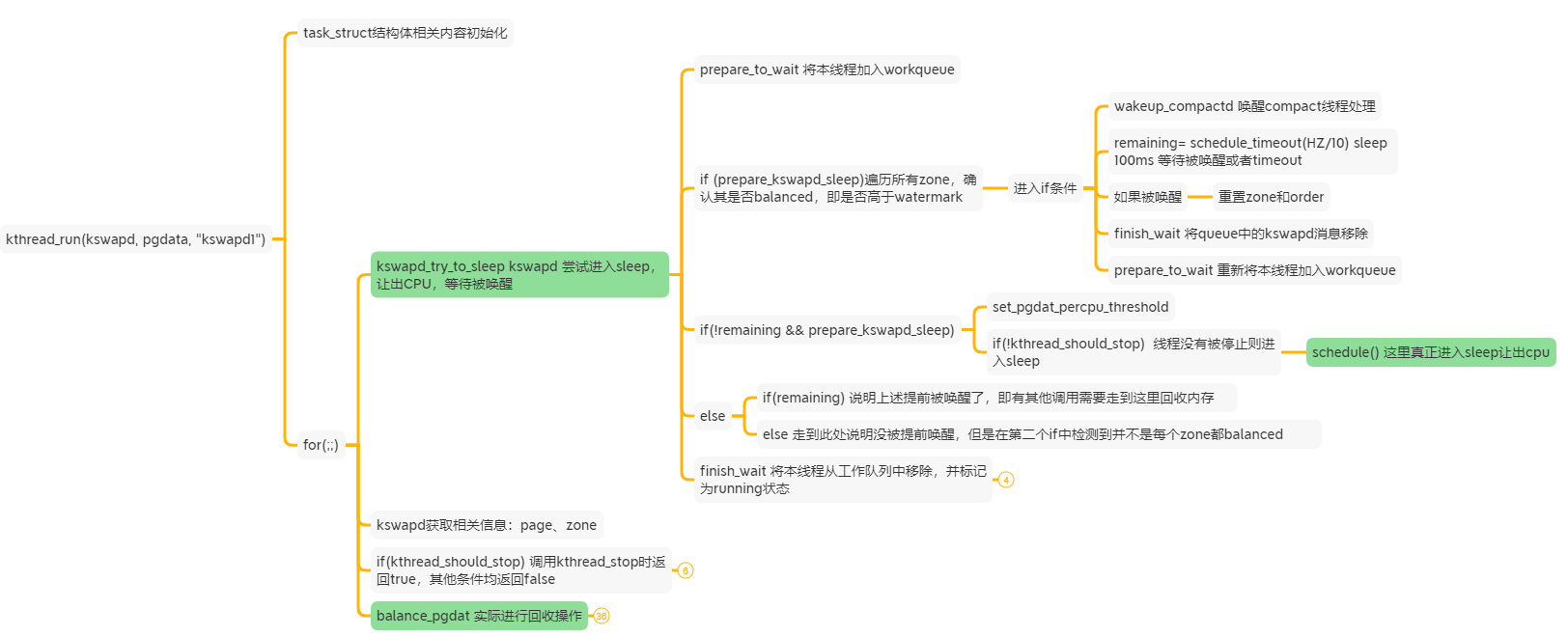
跟常规理解的一样:
- 主要逻辑是一个for循环,检测到满足条件(zone_balanced)就让出CPU进入睡眠等待;
- 被唤醒后根据条件不同,主要会进行balance_pgdat操作进行内存回收;
具体来看code(注释):
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order, classzone_idx;
pg_data_t *pgdat = (pg_data_t*)p; //当前node指针
struct task_struct *tsk = current;//获取到current_task
struct reclaim_state reclaim_state = {
.reclaimed_slab = 0,
};
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
lockdep_set_current_reclaim_state(GFP_KERNEL);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(tsk, cpumask);
current->reclaim_state = &reclaim_state;
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;//给task设置标志位;
set_freezable();
pgdat->kswapd_order = alloc_order = reclaim_order = 0;//申请的order,即2^order这么多pages
pgdat->kswapd_classzone_idx = classzone_idx = 0;//处理的zone的标号
for ( ; ; ) {//进入循环
bool ret;
kswapd_try_sleep:
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order, classzone_idx);
//核心处理1,实质的就是判断各个zone是否为balanced,是否balanced即判断zone内可申请的mem数量是否在watermark[high] 之上;
alloc_order = reclaim_order = pgdat->kswapd_order; //赋值操作
classzone_idx = pgdat->kswapd_classzone_idx;
pgdat->kswapd_order = 0;
pgdat->kswapd_classzone_idx = 0;
ret = try_to_freeze();//判断下当前是否是休眠操作
if (kthread_should_stop())//是否有人调用thread_stop,正常情况下就是在module_exit时候调用;
break;
if (ret)//如果是suspend状态的话,就啥也不干,继续循环
continue;
trace_mm_vmscan_kswapd_wake(pgdat->node_id, classzone_idx, alloc_order);//trace 埋点,对于理解流程不需要关注;
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx);//核心处理2,进行实质回收操作
if (reclaim_order < alloc_order)//回收数量不够,则再来一次;
goto kswapd_try_sleep;
alloc_order = reclaim_order = pgdat->kswapd_order;
classzone_idx = pgdat->kswapd_classzone_idx;
}
tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);
current->reclaim_state = NULL;
lockdep_clear_current_reclaim_state();
return 0;
}
这个主循环实际上干了两件事:
- 判断当前是否可以sleep,如果可以就让出了CPU(kswapd_try_to_sleep);
- 被唤醒后调用balance_pgdat 进行mem 回收操作;
2.2.1 kswapd_try_to_sleep
本接口即判断各个zone是否都balanced,如果都满足,就进入sleep让出CPU:
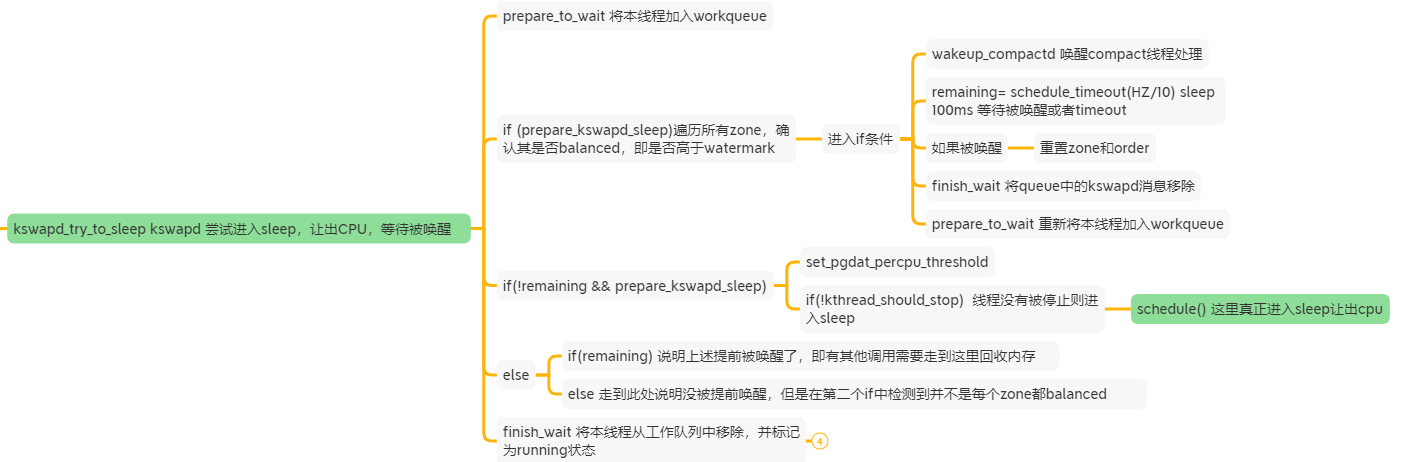
直接上code:
static void kswapd_try_to_sleep(pg_data_t *pgdat, int alloc_order, int reclaim_order,
unsigned int classzone_idx)
{
long remaining = 0;
DEFINE_WAIT(wait);//当前task
if (freezing(current) || kthread_should_stop())//如果需要退出,则直接返回
return;
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);// wait加入kswap_wait queue中,即等待被唤醒,注意此时没有让出CPU
if (prepare_kswapd_sleep(pgdat, reclaim_order, classzone_idx)) {//核心处理1:判断是否各个zone都是balanced
reset_isolation_suitable(pgdat);
wakeup_kcompactd(pgdat, alloc_order, classzone_idx);//唤醒compact线程处理,这个是压缩内存的一个机制,这里不做详细讨论;
remaining = schedule_timeout(HZ/10); //sleep 100ms
if (remaining) {//remaining > 0说明被唤醒而非100ms结束
pgdat->kswapd_classzone_idx = max(pgdat->kswapd_classzone_idx, classzone_idx);
pgdat->kswapd_order = max(pgdat->kswapd_order, reclaim_order);
}
finish_wait(&pgdat->kswapd_wait, &wait);//将wait从kswapd_wait queue中移除,并将当前状态配置为running
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);//将wait加入kswapd wait queue,这里看起来是确保queue中只有一个等待事件;
}
if (!remaining &&//上述没有被唤醒
prepare_kswapd_sleep(pgdat, reclaim_order, classzone_idx)) {//各个zone都是balanced
trace_mm_vmscan_kswapd_sleep(pgdat->node_id);
set_pgdat_percpu_threshold(pgdat, calculate_normal_threshold);
if (!kthread_should_stop())//没有需要退出thread,则真正的进入睡眠,主动调用schedule调度下一个事件;
schedule();
set_pgdat_percpu_threshold(pgdat, calculate_pressure_threshold);
} else {
if (remaining)//之前是被唤醒的,则记录vm
count_vm_event(KSWAPD_LOW_WMARK_HIT_QUICKLY);
else
count_vm_event(KSWAPD_HIGH_WMARK_HIT_QUICKLY);
}
finish_wait(&pgdat->kswapd_wait, &wait);//将wait从kswapd_wait queue中移除,并将当前状态配置为running,额 睡醒了
}
这里充分的演示了如何进入睡眠的整个操作:
- prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE)
- if (!kthread_should_stop()) schedule()
- finish_wait(&pgdat->kswapd_wait, &wait)
2.2.2 prepare_kswapd_sleep
本接口功能即判断是否各个zone都属于balanced,如果属于则可以sleep,意味着做好了入睡的准备
static bool prepare_kswapd_sleep(pg_data_t *pgdat, int order, int classzone_idx)
{
int i;
if (waitqueue_active(&pgdat->pfmemalloc_wait))//判断performance中有无等待task,有的话唤醒
wake_up_all(&pgdat->pfmemalloc_wait);
for (i = 0; i <= classzone_idx; i++) {//遍历每个zone
struct zone *zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
if (!zone_balanced(zone, order, classzone_idx))//是否balanced
return false;
}
return true;
}
//第一层遍历每一个zone,判断是否balanced
static bool zone_balanced(struct zone *zone, int order, int classzone_idx)
{
unsigned long mark = high_wmark_pages(zone);//注意这个mark是watermark[high]
if (!zone_watermark_ok_safe(zone, order, mark, classzone_idx))//判断是否ok,这里就是判断是否高于watermark[high]
return false;
clear_bit(PGDAT_CONGESTED, &zone->zone_pgdat->flags);
clear_bit(PGDAT_DIRTY, &zone->zone_pgdat->flags);
return true;
}
//第二层获取到了mark的值,又套了一层
bool zone_watermark_ok_safe(struct zone *z, unsigned int order,
unsigned long mark, int classzone_idx)
{
long free_pages = zone_page_state(z, NR_FREE_PAGES);
if (z->percpu_drift_mark && free_pages < z->percpu_drift_mark)
free_pages = zone_page_state_snapshot(z, NR_FREE_PAGES);//获取freepage数量
return __zone_watermark_ok(z, order, mark, classzone_idx, 0, free_pages);//又套了一层,终于进来了
}
//第三层获取到freepage的值,又套了一层
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & ALLOC_HARDER);//我们是否需要更harder的申请内存呢?
free_pages -= (1 << order) - 1;//去除申请order的pages
if (alloc_flags & ALLOC_HIGH)//对于highmem,不需要保留那么多,去除一半;
min -= min / 2;
if (likely(!alloc_harder))//我们还没到那么艰难,则在free中去除rserved数量
free_pages -= z->nr_reserved_highatomic;
else //假如我们已经很艰难了,那么保留的值再减少1/4吧,这里跟计算high的过程挺像;
min -= min / 4;
#ifdef CONFIG_CMA//CMA部分先不care
if (!(alloc_flags & ALLOC_CMA))
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
if (free_pages <= min + z->lowmem_reserve[classzone_idx])//free比起min + reserve要小,即不balance
return false;
if (!order)//order为0,即申请一个page,而且上边一个判断过去了,说明可以申请到,即balanced
return true;
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
if (alloc_harder)
return true;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
}
return false;
}
//第四层终于看到了实际的判断逻辑,其实就是watermark + reserve这些,另外需要考虑迁移策略;
本部分用一句话描述就是,判断各个zone的内存是否够用;
2.3 kswapd回收
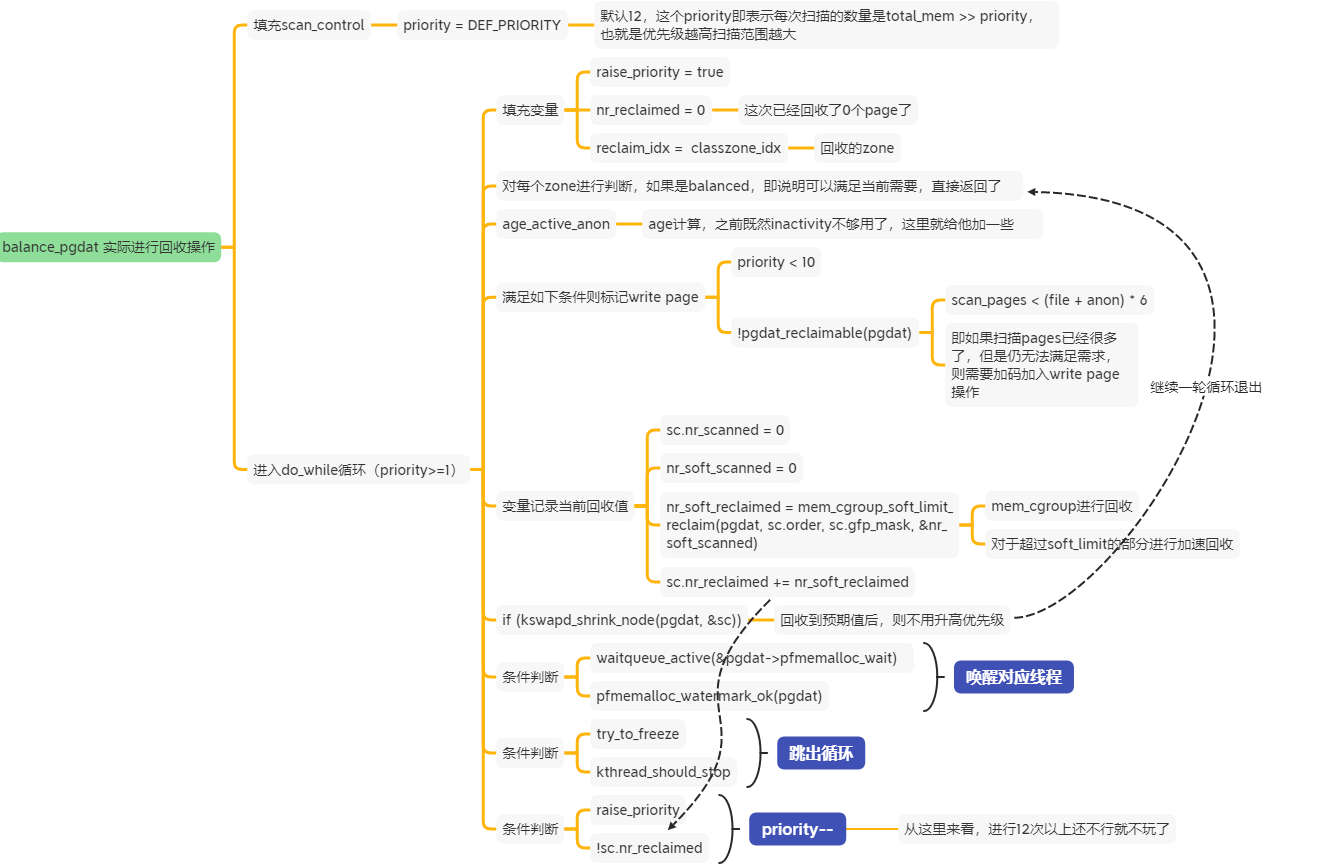
这里是kswapd被唤醒后的处理,被唤醒的话,那就要进行kswapd实际回收操作了:
static int balance_pgdat(pg_data_t *pgdat, int order, int classzone_idx)
{
int i;
unsigned long nr_soft_reclaimed;
unsigned long nr_soft_scanned;
struct zone *zone;
struct scan_control sc = {
.gfp_mask = GFP_KERNEL,
.order = order,
.priority = DEF_PRIORITY,
.may_writepage = !laptop_mode,
.may_unmap = 1,
.may_swap = 1,
};
count_vm_event(PAGEOUTRUN);
do {
bool raise_priority = true; //默认将raise_priority配置为true
sc.nr_reclaimed = 0;
sc.reclaim_idx = classzone_idx;
if (buffer_heads_over_limit) {
//这里是判断buffer_head的limit,如果是buffer_head内存较多的话优先从highmem进行,这里标记了进行回收的zone
for (i = MAX_NR_ZONES - 1; i >= 0; i--) {//按照high -- normal -- dma的顺序进行
zone = pgdat->node_zones + i;
if (!managed_zone(zone))//如果没有managed mem则直接进行下一个zone
continue;
sc.reclaim_idx = i;
break;
}
}
for (i = classzone_idx; i >= 0; i--) {//
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
if (zone_balanced(zone, sc.order, classzone_idx))//如果该zone满足分配order后仍属于balanced的情况,则说明分配OK,直接跳出;
goto out;
}
age_active_anon(pgdat, &sc);//走到这里说明将各个zone都判断过之后,回收内存仍不够用,所以对anon 进行老化处理;
if (sc.priority < DEF_PRIORITY - 2 || !pgdat_reclaimable(pgdat))
sc.may_writepage = 1;
//优先级高于10还没有搞到足够内存的时候,需要打开writepage
//pgdat_reclaimable 这里是做个判断,当前scan的pages数量是否足够多,如果够多还没有out出去的话,加码
/* Call soft limit reclaim before calling shrink_node. */
sc.nr_scanned = 0;
nr_soft_scanned = 0;
nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(pgdat, sc.order, sc.gfp_mask, &nr_soft_scanned);//先进行一次 mem_cgroup的回收
sc.nr_reclaimed += nr_soft_reclaimed;
if (kswapd_shrink_node(pgdat, &sc))//关键部分,进行shrink_node回收
raise_priority = false;
if (waitqueue_active(&pgdat->pfmemalloc_wait) && pfmemalloc_watermark_ok(pgdat))//唤醒performance malloc申请
wake_up_all(&pgdat->pfmemalloc_wait);
if (try_to_freeze() || kthread_should_stop())//suspend或者退出的话,这里直接跳出去;
break;
if (raise_priority || !sc.nr_reclaimed)//没回收够,则priority--
sc.priority--;
} while (sc.priority >= 1);
out:
return sc.order;//返回回收的order数量
}
暂时只能这样了,搞这个的时候突然来了个紧急的活儿














 1452
1452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









