






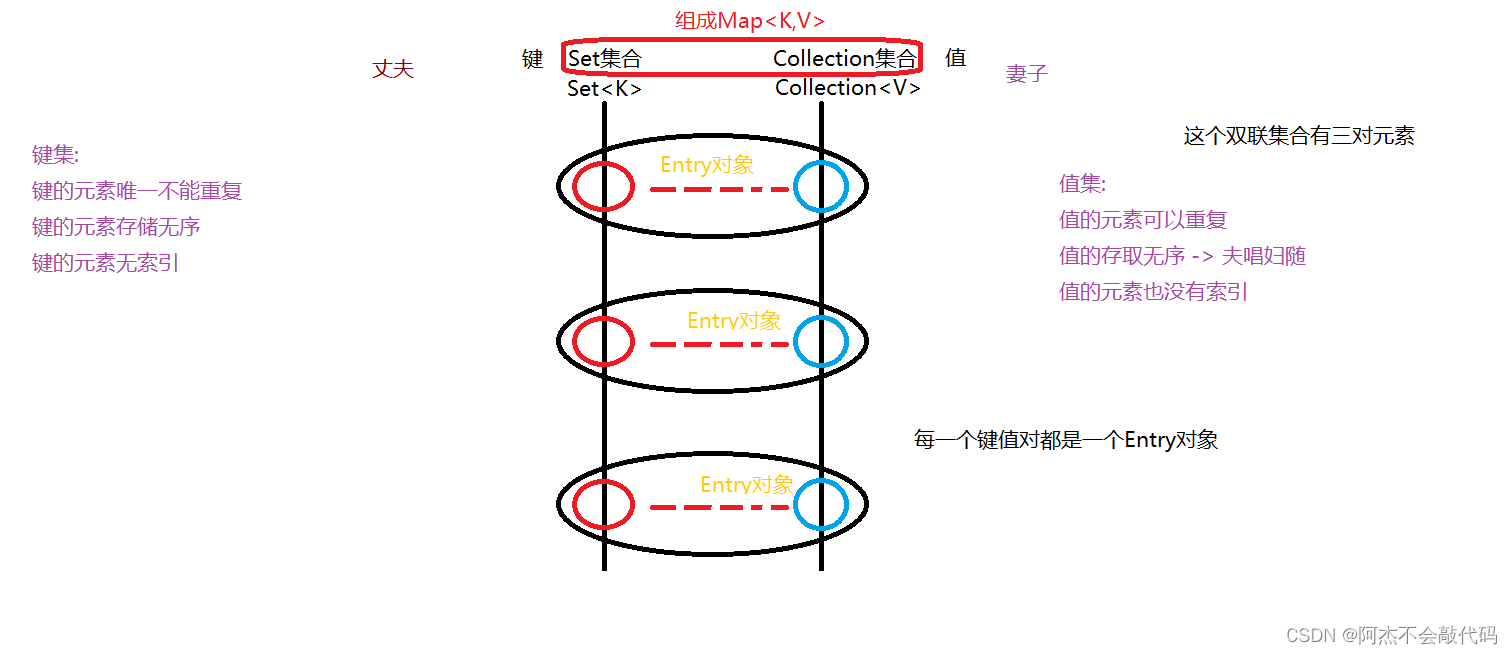
双列集合介绍
双列集合 : 由2根单列集合组成的集合叫双列集合;
双列集合表示的是一种映射关系(一一对应的关系)
双列集合是由一根Set集合(键集)和一根Collection集合(值集)进行组合
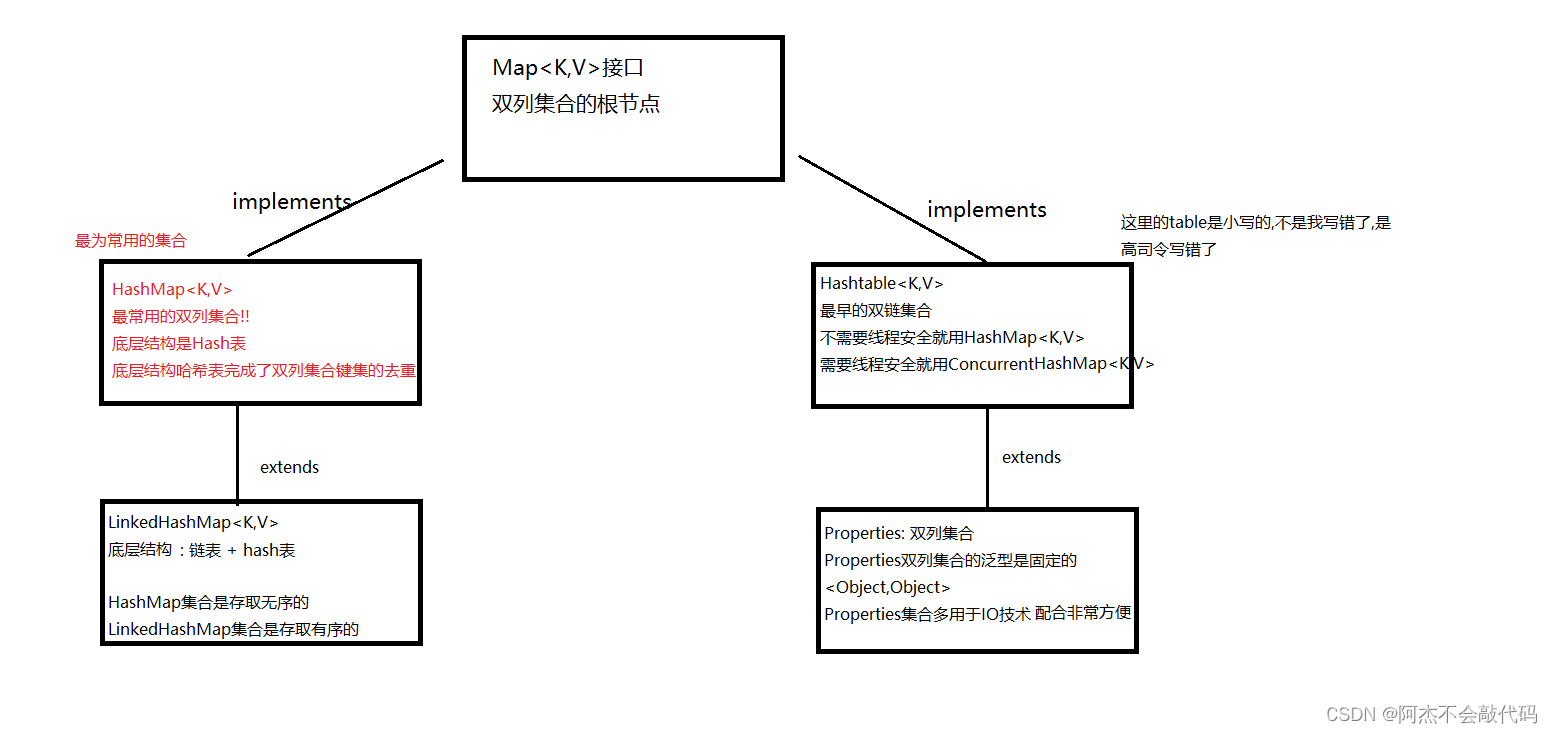
双列集合的体系
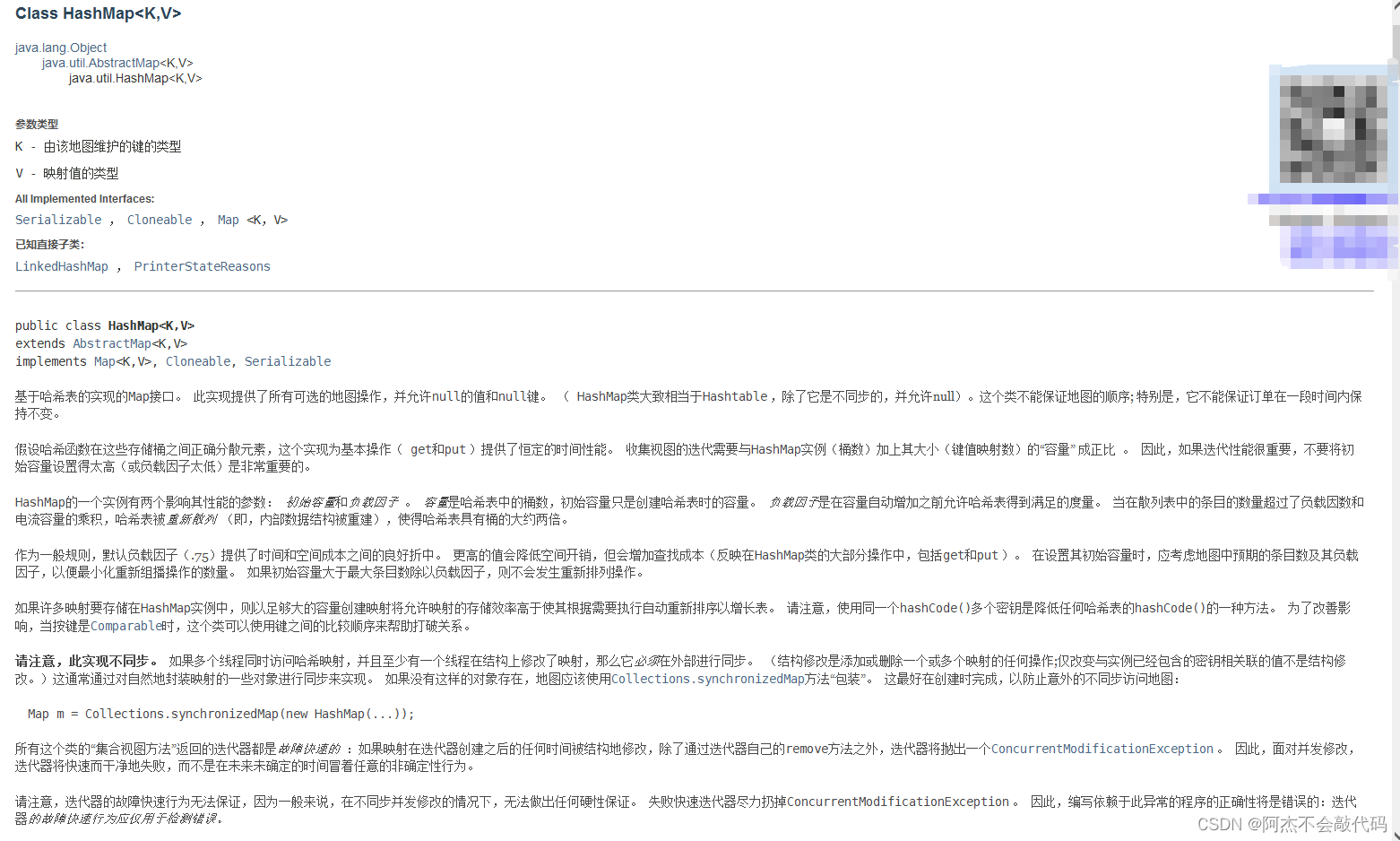
在java8中的API文档是这么描述HashMap的
HahsMap的增删改查
增加元素
public static void main(String[] args) {
HashMap<String,String> hm = new HashMap<>();
//添加元素
hm.put("刘备","诸葛亮");
hm.put("曹操","司马懿");
hm.put("孙权","孙策");
hm.put("周瑜","孙策");
Set<String> keys = hm.keySet();
for (String key : keys) {
String value = hm.get(key);
System.out.println(key +"---" + value);
}
System.out.println("------------------------------------");
ArrayList<Object> list = new ArrayList<>();
list.add(hm);
System.out.println("lsit"+list);
}
改元素
如果两个相同的key对应同一个value值呢?
public static void main(String[] args) {
HashMap<String,String> hm = new HashMap<>();
//添加元素
hm.put("刘备","诸葛亮");
hm.put("曹操","司马懿");
hm.put("孙权","孙策");
hm.put("周瑜","孙策");
hm.put("周瑜","吕蒙");
Set<String> keys = hm.keySet();
for (String key : keys) {
String value = hm.get(key);
System.out.println(key +"---" + value);
}
System.out.println("------------------------------------");
ArrayList<Object> list = new ArrayList<>();
list.add(hm);
System.out.println("lsit"+list);
}结果就是键为周瑜,值为孙策的键值对被覆盖了,这也证明了HashMap对key有去重的能力

删除元素
clear(): 清除集合中所有元素
remove(Object key) : 根据传入的键删除集合中的一对映射关系,并返回值
public static void main(String[] args) {
HashMap<String,String> hm = new HashMap<>();
//添加元素
hm.put("刘备","诸葛亮");
hm.put("曹操","司马懿");
hm.put("孙权","孙策");
hm.put("周瑜","孙策");
hm.put("周瑜","吕蒙");
hm.remove("刘备");
Set<String> keys = hm.keySet();
for (String key : keys) {
String value = hm.get(key);
System.out.println(key +"---" + value);
}
System.out.println("------------------------------------");
ArrayList<Object> list = new ArrayList<>();
list.add(hm);
System.out.println("lsit"+list);
}
查询元素
String value = hm.get(key);
如上图
如果查询不到值,就返回null
boolean containsKey(Object key) : 查询是否存在传入的key
boolean containsValue(Object value) : 查询是否存在传入的Value
Set<K> keySet(); : 获取双列集合的键集合
//keys中都是hm集合中存在的key值
Set<String> keys = hm.keySet();
for (String key : keys) {
//通过get()方法拿到每一个key的value值
String value = hm.get(key);
System.out.println(key +"---" + value);
}HashMap的几种遍历方式
上面的通过遍历key值拿到value值的遍历方式就不赘述了
第二种
HashMap<String,String> hm = new HashMap<>();
//添加元素
hm.put("刘备","诸葛亮");
hm.put("曹操","司马懿");
hm.put("孙权","孙策");
hm.put("周瑜","孙策");
hm.put("周瑜","吕蒙");
hm.remove("刘备");
//遍历取出所有对象
Set<Map.Entry<String, String>> entries = hm.entrySet();
//遍历存有对象的集合
for (Map.Entry<String, String> entry : entries) {
//在Entry接口中有getKey(),V getValue()
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "--------" + value);
}
这种方法直接拿到Entry对象,然后在Entry中再获取键和值
HashMap的底层原理
底层也是数组 : table -> hash表
HashMap集合的加载因子: 0.75 --> 何时扩容
当底层数组中的元素个数 > 容量 * 0.75 的时候就扩容
空参构造一个HashMap集合,默认底层数组的容量是 16 , 理想状态下: 当底层数组的元素达到12个(16 * 0.75),底层数组进行扩容(在原有的数组长度基础下进行翻倍
1. 添加新的元素的时候,会计算新元素键的hash值,hash值决定了这对元素在底层数组的索引位置(index);
若table[index] == null,不看数组的长度(底层容量) 直接在此索引位置添加元素
若table[index] != null,看数组的长度(底层的容量)有没有达到加载因子的触发条件
a. 若没有达到,对新元素进行挂载形成链表
b. 若达到加载因子扩容条件,对底层数组table进行扩容,然后重新计算每一个元素的Hash值对应的索引位置进行元素的重新整理,存放到新的数组中
JDK8之后出现:
2. 添加新元素的时候,若底层数组table的容量没有达到64,某个index位置的元素挂载超过8个的时候,计算总的元素个数,若达到加载因子的触发条件就对集合进行扩容,并重新计算数组元素应该存放在新数组的索引位置
3. 添加新元素的时候,若底层数组table的容量超过64,某个index位置的元素挂载超过8个的时候,不会计算总的元素个数,而是把此索引位置的链表转换成红黑树结构
HashMap/HashSet底层原理:
JDK7版本 : hash表(数组 + 链表)
JDK8版本 : hash表(数组 + 链表 + 红黑树)















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









