






摘要简介
Inception深度卷积神经网络架构,这种架构提升利用计算机内部资源,增加网络的深度和网络的宽度,但是不增加计算量。
优化质量以Hebbian理论和多尺度直觉为基础。
随着深度学习和神经网络的发展,目标分类和检测的能力显著提高。其一是GoogLeNet参数使用更少,并且结果更加准确。第二点是考虑到算法效率,电力和内存的使用,考虑这个得出本文的深度框架设计。
计算机视觉深度神经网络架框Inception。
Serre使用了一系列固定大小的Gabor滤波器来处理多尺度,相反,Inception结构中所有的滤波器都是学习到的。
在Network-in-Network中大量运用了11的卷积。我们也使用11的卷积来作为降维模块来移除卷积瓶颈,否则会限制网络的大小。不仅允许深度的增加,还允许了宽度的增加,没有造成明显的性能损失。
R-CNN将检测问题分为2个子问题:利用低层次的信号例如颜色,纹理以跨类别的方式来产生目标位置候选区域,然后用CNN分类器来识别那些位置上的对象类别。
思想及方法
提高神经网络性能是增加宽度和深度。造成了俩个缺点,第一是更大的尺寸意味着更多的参数,使增大的网络更加容易过拟合。第二是计算资源的显著增加。解决方法为引入稀疏性并将全连接层替换成稀疏的全连接层,甚至是卷积层。
Arora主要成果说明如果数据集的概率分布可以通过一个大型稀疏的深度神经网络表示,则最优的网络拓扑结构可以通过分析前一层激活的相关性统计和聚类高度相关的神经元来一层层的构建。这个声明与著名的赫布理论产生共鸣——神经元一起激发,一起连接。
通常全连接是为了更好的优化并行计算,而稀疏连接是为了打破对称来改善学习,传统常常利用卷积来利用空间域上的稀疏性,但卷积在网络的早期层中的与patches的连接也是稠密连接,因此考虑到能不能在滤波器层面上利用稀疏性,而不是神经元上。但是在非均匀稀疏数据结构上进行数值计算效率很低,并且查找和缓存未定义的开销很大,而且对计算的基础设施要求过高,因此考虑到将稀疏矩阵聚类成相对稠密子空间来倾向于对稀疏矩阵的计算优化。因此提出了inception结构。
Inception架构的主要想法是考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集组件进行覆盖。
我们所需要做的是找到最优的局部构造并在空间上重复它。Arora等人[2]提出了一个层次结构,其中应该分析最后一层的相关统计并将它们聚集成具有高相关性的单元组。这些聚类形成了下一层的单元并与前一层的单元连接。目前Inception架构形式的滤波器的尺寸仅限于1×1、3×3、5×5,这也意味着提出的架构是所有这些层的组合,其输出滤波器组连接成单个输出向量形成了下一阶段的输入。由于这些“Inception模块”在彼此的顶部堆叠,其输出相关统计必然有变化:由于较高层会捕获较高的抽象特征,其空间集中度预计会减少。这表明随着转移到更高层,3×3和5×5卷积的比例应该会增加。输出滤波器的数量等于前一阶段滤波器的数量。池化层输出和卷积层输出的合并会导致这一阶段到下一阶段输出数量不可避免的增加。虽然这种架构可能会覆盖最优稀疏结构,但它会非常低效,导致在几个阶段内计算量爆炸。见图(a).
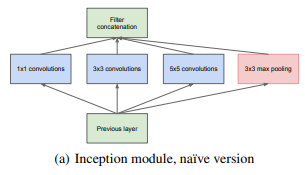
对图(a)进行说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
这导致了Inception架构的第二个想法:在计算要求会增加太多的地方,明智地减少维度。也就是说,在昂贵的3×3和5×5卷积之前,1×1卷积用来计算降维。除了用来降维之外,它们也包括使用线性修正单元使其两用。如图(b)。
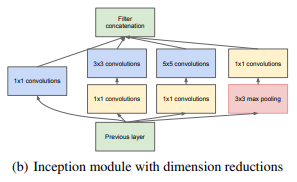
出于技术原因(训练过程中内存效率),只在更高层开始使用Inception模块而在更低层仍保持传统的卷积形式似乎是有益的。该架构的一个有用的方面是它允许显著增加每个阶段的单元数量,而不会在后面的阶段出现计算复杂度不受控制的爆炸。
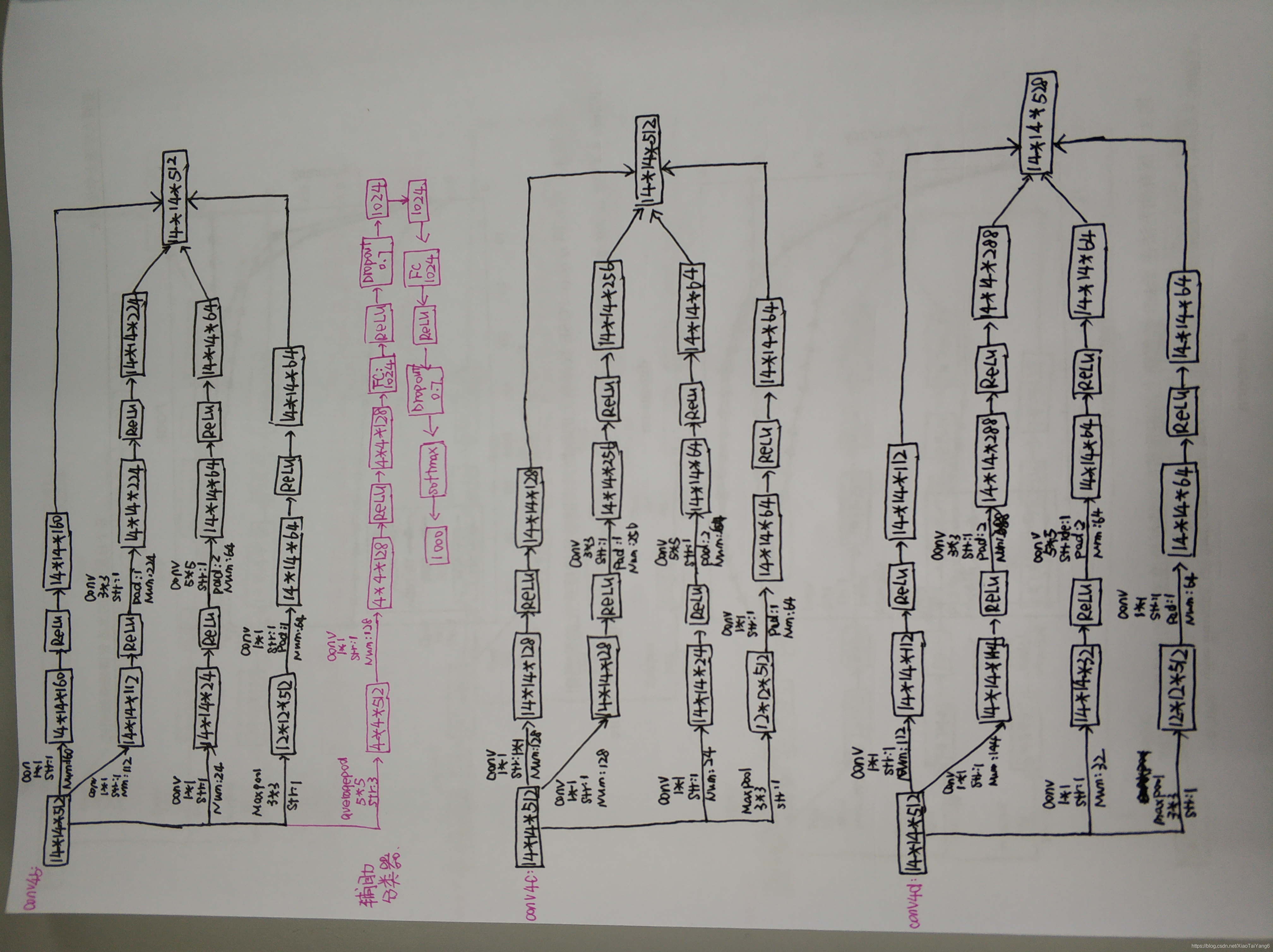
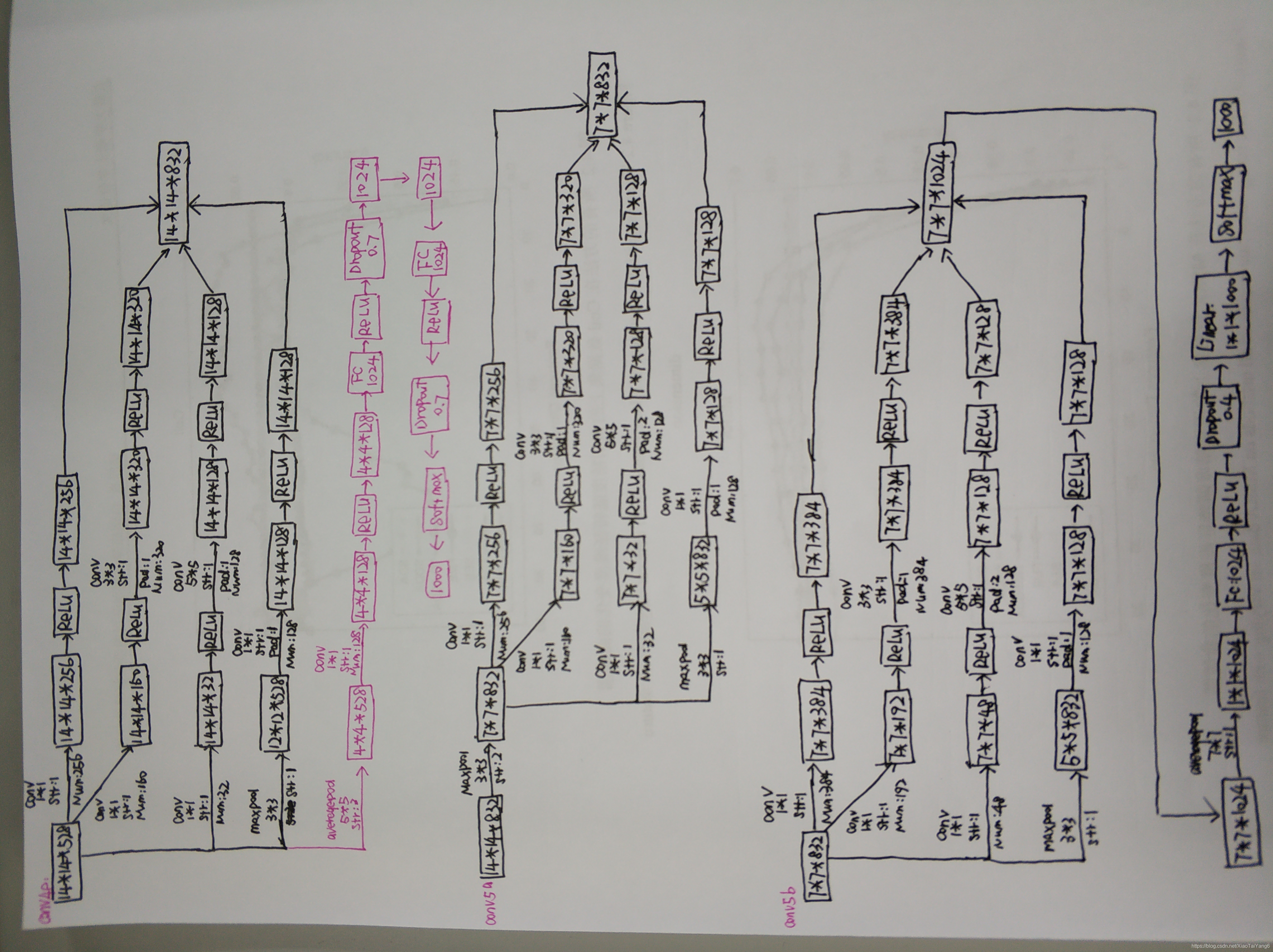
GoogLeNet整体结构
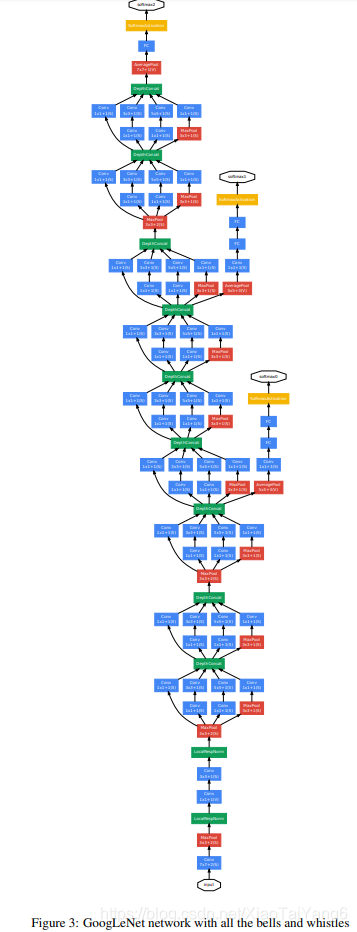
1 . 显然GoogLeNet采用了模块化的结构,方便增添和修改;
2 . 网络最后使用了average pooling来代替全连接层,Top-1的错误率减少了0.6%。但是,最后还是加了一个全连接层,主要是为了方便以后大家finetune;
3 . 虽然移除了全连接,但是网络中依然使用了Dropout ;
4 . 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
优秀博客链接:https://blog.csdn.net/qq_31531635/article/details/72232651














 9751
9751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









