/**
* 编码表
*编码表的由来:
* 计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。
* 就将各个国家的文字用数字来表示,并一一对应,形成一张表,这就是编码表。
*常见的编码表:
* ASCII:美国标准信息交换码,用一个字节的7为可以表示。
* ISO8859-1:拉丁码表。欧洲码表,用一个字节的8位表示。
* GB2312:中国的中文编码表。
* GBK:中国的中文编码表升级,融合了更多的中文文字符号。
* Unicode:国际标准码,融合了多种文字。
* 所有文字都用两个字节来表示,Java语言使用的就是unicode
* UTF-8:最多用三个字节来表示一个字符。
*/
public class Demo15 {
public static void main(String[] args) throws UnsupportedEncodingException{
//字符串-->字符数组:编码
//字符数组-->字符串:解码
String str = "您好";
//编码
byte[] buf1 = str.getBytes("GBK");
printBytes(buf1);
byte[] buf2 = str.getBytes("UTF-8");
printBytes(buf2);
//解码
String s1 = new String(buf1);
System.out.println("s1="+s1);
String s2 = new String(buf2,"UTF-8");
System.out.println("s2="+s2);
}
private static void printBytes(byte[] buf){
for(byte b:buf){
System.out.print(b+" ");
}
System.out.println();
}
}
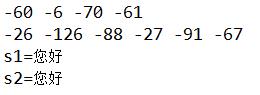
/**
*练习:
*在java中,字符串"abcd"与字符串"ab您好"的长度是一样,都是四个字符。
*但对应的字节数不同,一个汉字占两个字节。
*定义一个方法,按照最大的字节数来取子串。
*如:对于"ab你好",如果取三个字节,那么子串就是ab与"你"字的半个。
*那么半个就要舍弃。如果取四个字节就是"ab你",取五个字节还是"ab你"。
*/
public class Demo16 {
public static void main(String[] args) throws Exception{
String str = "ab你好cd谢谢";
int len = str.getBytes("GBK").length;
for(int i = 1;i<len;i++){
System.out.println("截取"+i+"个字节对应的字符为:"+cutString(str,i));
}
}
private static String cutString(String str,int len) throws Exception{
byte[] bytes = str.getBytes("GBK");
int count = 0;
for(int i=len-1;i>=0;i--){
//gbk编码的值两个字节值一般都为负,记录连续的负数个数,如果为技术,则舍弃
if(bytes[i]<0){
count++;
}else{
break;
}
}
if(count % 2 == 0){
return new String(bytes,0,len,"GBK");
}else{
return new String(bytes,0,len-1,"GBK");
}
}
}
























 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









