







 对于更新主键的操作,会先把原来的数据deletemark标识打开,这时并没有真正的删除数据,真正的删除会交给清理线程去判断,然后在后面插入一条新的数据,新的数据也会产生undolog,并且undolog的序号会递增。可以发现每次对数据的变更都会产生一个undolog,当一条记录被变更多次时,那么就会产生多条undolog,undolog记录的是变更前的日志,并且每个undolog的序号是递增的,那么当要回滚的时候,按照序号。undolog会记录undolog的序号、插入主键的列和值…...
对于更新主键的操作,会先把原来的数据deletemark标识打开,这时并没有真正的删除数据,真正的删除会交给清理线程去判断,然后在后面插入一条新的数据,新的数据也会产生undolog,并且undolog的序号会递增。可以发现每次对数据的变更都会产生一个undolog,当一条记录被变更多次时,那么就会产生多条undolog,undolog记录的是变更前的日志,并且每个undolog的序号是递增的,那么当要回滚的时候,按照序号。undolog会记录undolog的序号、插入主键的列和值…...
事务有4种特性:原子性、一致性、隔离性和持久性。那么事务的四种特性到底是基于什么机制实现呢?
-
事务的隔离性由锁机制实现。
-
而事务的原子性、一致性和持久性由事务的redo日志和undo日志来保证。
①REDO LOG称为重做日志,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。
②UNDO LOG称为回滚日志,回滚行记录到某个特定版本,用来保证事务的原子性、一致性。 -
有的DBA或许会认为UNDo是REDo的逆过程,其实不然。REDO和UNDO都可以视为是一种恢复操作,但是:
redo log:是存储引擎层(innodb)生成的日志,记录的是"物理级别"上的页修改操作,比如页号xx、偏移量y写入了’zzz’数据。主要为了保证数据的可靠性;
undo log: 是存储引擎层(innodb)生成的日志,记录的是逻辑操作日志,比如对某一行数据进行了INSERT语句操作,那么undo log就记录一条与之相反的DELETE操作。主要用于事务的回滚(undo log 记录的是每个修改操作的逆操作)和一致性非锁定读(undo log回滚行记录到某种特定的版本—MVCC,即多版本并发控制)。
1、redo 日志
InnoDB存储引擎是以页为单位来管理存储空间的。在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。所有的变更都必须先更新缓冲池中的数据,然后缓冲池中的脏页会以一定的频率被刷入磁盘( checkPoint机制),通过缓冲池来优化CPU和磁盘之间的鸿沟,这样就可以保证整体的性能不会下降太快。
1.1 为什么需要redo日志?
一方面,缓冲池可以帮助我们消除CPU和磁盘之间的鸿沟,checkpoint机制可以保证数据的最终落盘,然而由于checkpoint并不是每次变更的时候就会触发的,而是master线程隔一段时间去处理的。所以最坏的情况就是事务提交后,刚写完缓冲池,数据库就宕机看,那么这段数据就是丢失的,无法恢复。
另一方面,事务包含持久性的特性,就是说对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库所做的更改也不能丢失。
那么如何保证这个持久性呢?一个简单的做法:在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘,但是这个简单粗暴的做法存在一些问题:
-
修改量与刷新磁盘工作量严重不成比例
有时候我们仅仅修改了某个页面中的一个字节,但是我们知道在InnoDB中是以页为单位来进行磁盘Io的,也就是说我们在该事务提交时不得不将一个完整的页面从内存中刷新到磁盘,我们又知道一个页面默认是16KB大小,只修改一个字节就要刷新16KB的数据到磁盘上显然是太小题大做了。 -
随机IO刷新较慢
一个事务可能包含很多语句,即使是一条语句也可能修改许多页面,假如该事务修改的这些页面可能并不相邻,这就意味着在将某个事务修改的Buffer Pool中的页面刷新到磁盘时,需要进行很多的随机IO,随机lo比顺序Io要慢,尤其对于传统的机械硬盘来说。
另一个解决的思路︰我们只是想让已经提交了的事务对数据库中数据所做的修改永久生效,即使后来系统崩溃,在重启后也能把这种修改恢复出来。所以我们其实没有必要在每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好。比如,某个事务将系统表空间中第10号页面中偏移量为100处的那个字节的值1改成2。我们只需要记录一下:将第0号表空间的10号页面的偏移量为100处的值更新为2。
InnoDB引擎的事务采用了WAL技术(Write-Ahead. Logging ),这种技术的思想就是先写日志,再写磁盘,只有日志写入成功,才算事务提交成功,这里的日志就是redo log。当发生宕机且数据未刷到磁盘的时候,可以通过redo log来恢复,保证ACID中的D,这就是redo log的作用。
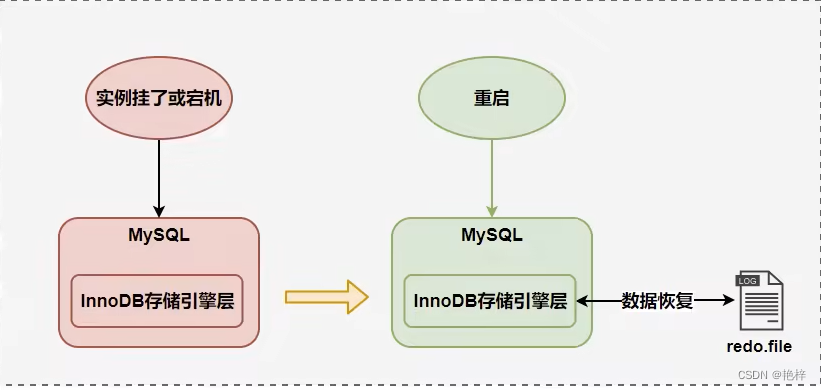
1.2 redo 日志的好处和特点
1.好处:
- redo日志降低了刷盘频率
- redo日志占用的空间非常小
存储表空间ID,页号,偏移量以及需要更新的值,所需的存储空间是很小的,刷盘快。
2.特点:
-
redo日志是顺序写入磁盘的
在执行事务的过程中,每执行一条语句,就可能产生若干条redo日志,这些日志是按照产生的顺序写入磁盘的,也就是使用顺序IO,效率比随机IO快。 -
事务执行过程中,redo log不断记录
redo log 跟bin log 的区别,redo log是存储引擎层产生的,而bin log是数据库层产生的。假设一个事务,对表做10万行的记录插入,在这个过程中,一直不断的往redo log顺序记录,而bin log不会记录,直到这个事务提交
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









