







1、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
3、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
4、尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5、下面的查询也将导致全表扫描:(不能前置百分号)
select id from t where name like ‘�c%’
若要提高效率,可以考虑全文检索。
6、in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
7、如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
8、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’–name以abc开头的id
select id from t where datediff(day,createdate,’2005-11-30′)=0–’2005-11-30′生成的id
应改为:
select id from t where name like ‘abc%’
select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′
10、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11、在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使 用,并且应尽可能的让字段顺序与索引顺序相一致。
12、不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)
13、很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
14、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18、尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19、任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20、尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21、避免频繁创建和删除临时表,以减少系统表资源的消耗。
22、临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使 用导出表。
23、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26、使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27、与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28、在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
30、尽量避免大事务操作,提高系统并发能力。
文/未来码农(简书作者)
原文链接:http://www.jianshu.com/p/25c958196a0b
著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”。
Sql Server优化之路
本文只限coder级别层次上对Sql Server的优化处理简结,为防止专业DB人士有恶心、反胃等现象,请提前关闭此页面。
首先得有一个测试库,使用数据生成计划生成测试数据库(参考:http://developer.51cto.com/art/201102/245165.htm),或者下一个MS白给的库(AdventureWorks2008)。
一、架构设计
库表的合理设计对项目后期的响应时间和吞吐量起到至关重要的地位,它直接影响到了业务所需处理的sql语句的复杂程度,为提高数据库的性能,更多的把逻辑主外键、级联删除、减少check约束、给null字段添加default值等操作放到了程序端;就如,虽然修改存储过程有时候可以避免发布程序,但过多的逻辑判断也随之带来了性能问题;所以出发点不同 取其平衡就好。
二、语句优化
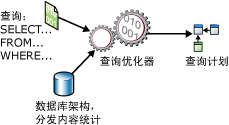
优化sql语句最基本的原则就是将sql语句简单化,将一个复杂的sql语句拆解执行,如图可以看出我们所执行的sql语句都是经过查询优化器分析得到高效的执行计划,那么简单的sql语句很大程度上提高了执行效率。
1、select
a、执行一条合理的sql语句,IO和数据的显示可能占据了整个过程的90%,而Sql Server后台的处理却少之又少
select colum1,colum2,colum3 from tbb、对于实时性不强的数据可以使用with (nolock),使用强制索指导执行计划
select * from Person.Person with (nolock)
select * from Person.Person with (index(PK_Person_BusinessEntityID))c、避免子查询
select * from Person.Password where BusinessEntityID in (select BusinessEntityID from Person.Person where FirstName='Ken');
--替换为
with tb(BusinessEntityID) as (select BusinessEntityID from Person.Person where FirstName='Ken')
select * from Person.Password where exists(select 1 from tb where BusinessEntityID=Person.Password.BusinessEntityID);2、where
a、导致index scan或table scan
select * from tb where like '%value%' -- like 'value%'
select * from tb where colum1<>0
select * from tb where colum1=1 or colum2=2 --colum1或colum2没有索引则导致全表扫描
--尽量使用exists代替in
select * from tb1 where colum in (select colum from tb2); -- select * from tb1 where exists(select 1 from tb2 where colum=tb1.colum);b、在有索引的字段中避免使用函数和表达式,导致索引无法使用
select * from tb where datediff(mm,'2015-1-1',colum1)=1;
select * from tb where substring(colum1,1,6)='value';3、jion
--join连接最好不要超过5个表,有更新的大数据表先放进临时表,然后再join
select BusinessEntityID,FirstName into #tmptable from Person.Person;
select * from Person.Password,#tmptable where Person.Password.BusinessEntityID=#tmptable.BusinessEntityID
drop table #tmptable4、insert
--批量插入数据,select into一定比逐条insert快
insert into tb values(colum1,colum2,colum3),(colum1,colum2,colum3),(colum1,colum2,colum3);
--文件批处理bulk insert和openrowset
https://technet.microsoft.com/zh-cn/library/ms188365(v=sql.105).aspx5、procedure,存储过程优点是执行速度快,因为它是预编译过的,并且执行之后会缓存到plan cache中。
--1、因为参数值的改变会导致重新生成执行计划,缓存过多执行计划,导致效率变低。
execute proc_tb_xx with recompile --强制在执行存储过程时对其重新编译
create proc pro_tb_xx with recompile --不为该存储过程缓存计划,每次执行存储过程时都必须对其重新编译(导致存储过程变慢)
--2、数据库进行了索引或其他会影响数据库统计的更改后,已编译的存储过程和触发器可能会失去效率。
execute sp_recompile N'object'; --通过对作用于表上的存储过程和触发器进行重新编译,可以重新优化查询
--object:当前数据库中存储过程、触发器、表或视图的限定或未限定名称;object 是存储过程或触发器的名称,则该存储过程或触发器将在下次运行时重新编译。如果 object 是表或视图的名称,则所有引用该表或视图的存储过程或触发器都将在下次运行时重新编译。6、漏洞注入,动态语句参数化查询时不要忘记sp_executesql代替exec
create proc proc_xxx
@addressid int,
@city nvarchar(16)
as
begin
declare @sql nvarchar(1148);
set @sql='select * from (select *,num=(row_number() over(order by AddressID asc)) from Person.Address where 1=1';
if(@city<>'')
begin
set @sql=@sql+' and City like @city';
end
if(@addressid<>0)
begin
set @sql=@sql+' and ID=@addressid';
end
set @sql=@sql+' ) A where A.num between @sindex and @eindex';
exec sp_executesql @sql,N'@city nvarchar(64),@addressid int,@sindex int,@eindex int',@city,@addressid,@sindex,@eindex;
end三、索引优化
众所周知,索引可以很大程度提升查询的效率,有时候通过添加一个索引 性能可以起到数以百倍的提升;但因为业务数据过大,过多的索引反而事到其反,一些作用不大的索引维护时也占用了性能的开销;这时就需要分析索引的使用情况,删除一些作用不大的索引,通过SQL Server提供的系统动态管理视图分析即可。
在创建聚集索引之前,应先了解您的数据是如何被访问的。可考虑将聚集索引用于:
包含大量非重复值的列。
使用下列运算符返回一个范围值的查询:BETWEEN、>、>=、< 和 <=。
被连续访问的列。
返回大型结果集的查询。
经常被使用联接或 GROUP BY 子句的查询访问的列;一般来说,这些是外键列。对 ORDER BY 或 GROUP BY 子句中指定的列进行索引,可以使 SQL Server 不必对数据进行排序,因为这些行已经排序。这样可以提高查询性能。
OLTP 类型的应用程序,这些程序要求进行非常快速的单行查找(一般通过主键)。应在主键上创建聚集索引。
聚集索引不适用于:
频繁更改的列
这将导致整行移动(因为 SQL Server 必须按物理顺序保留行中的数据值)。这一点要特别注意,因为在大数据量事务处理系统中数据是易失的。
宽键
来自聚集索引的键值由所有非聚集索引作为查找键使用,因此存储在每个非聚集索引的叶条目内。1、创建索引的关键在于减少sql语句执行时的逻辑读取次数,逻辑次数读取越少,执行所需的内容和cup时间也越少,则sql语句执行的越快;如果逻辑读取次数过大,返回数据较少则需考虑索引优化。
set statistics io on
go
select * from Production.WorkOrder where WorkOrderID=1
go
set statistics io off
--表 'WorkOrder'。扫描计数 0,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。对查询次数最多且显示scan的where条件进行优化。
--显示预计的执行计划 showplan_all、showplan_text、showplan_xml
set showplan_all on
go
select * from Production.WorkOrder where WorkOrderID=1
go
set showplan_all off
--显示真实的执行计划 statistics profile、statistics xml
set statistics profile on
go
select * from Production.WorkOrder where OrderQty=8
go
set statistics profile off2、分析所缺少的索引,通过语句查询自从上次SQL Server服务重启之后到当前时间为止全部数据库中可能缺少哪些索引。
select b.name , --数据库名称
a.statement , --缺少索引表的名称
a.equality_columns , --经常用于等值比较的列名,如 ID=value
inequality_columns , --经常用于不等值比较的列名,如 ID>value ID<>value
included_columns --建议在索引中涵盖或者包含的列
from sys.[dm_db_missing_index_details] a
join sys.databases b on a.database_id = b.database_id3、分析索引的使用情况,通过语句查询自从上次SQL Server服务重启之后到当前时间为止数据库中所有索引的使用情况。
a、seek过少,而scans或update过大,证明索引不被经常使用,而是用于修改和全表扫描,那么就可以考虑删除此索引了;
b、seek过多,而scans和update也过大,维护索引成本较高,就要考虑权衡利弊了。
--更新表索引的统计信息
update statistics tablename with fullscan
select
db_name() as DBNAME, --数据库名称
object_name(a.object_id) as table_name, --表名称
coalesce(name,'object with no clustered index') as index_name, --索引名称
type_desc as index_type, --索引类型
user_seeks, --使用索引查询的次数
user_scans, --使用全表扫描的次数
user_lookups, --使用书签的次数,使用书签会造成二次IO,考虑是否加入非聚集索引
user_updates --索引的更新次数
from sys.dm_db_index_usage_stats a inner join sys.indexes b
on a.index_id = b.index_id and a.object_id = b.object_id
where database_id = db_id('AdventureWorks2008')4、对于一些不再修改的历史数据,只为查询出报表等可以新建存储建立列存储索引-Apollo,而列存储索引也是自Sql Server2012之后引入主要处理海量数据仓储的高效查询;而且在查询优化器运行查询时也会优先访问列存储索引,其次才是基于行的聚集和非聚集索引
--列存储索引的限制,只支持一些常用的业务数据类型(int, real, string, money, datetime, decimal <= 18),Sql Server2012之后才加入了更新
--创建列存储索引
create nonclustered columnstore index cs_index on tb(colum);
--强制索引
select * from tb with (index(cs_index));
--禁用索引(Sql Server2014已支持数据的读和写)
alter index cs_index on tb disable
--重建列存储索引
alter index cs_index on tb rebuild四、并发控制
与并发密不可分的就是事务和锁了,在大并发事务争抢资源之下,数据库锁应运而生;Sql Server在处理过程中会对锁定行或索引范围放置意向锁,当意向锁升级时,会减少锁的数量,也是对性能提升时Sql Server进行的锁升级,同时也是一个信号量,标识着程序设计、编码或配置方面需要优化。同理,优化时我们也是通过锁提示让Sql Server执行时采用我们业务所需要的锁,即使个别锁有时候就可以对事务和程序起到至关重要的性能提高;同时避免死锁的出现,通过sql profile和活动监视器跟踪和处理死锁。
五、存储优化
磁盘IO有瓶颈,日常的windows操作已经证明了多线程读多个小文件比读一个大文件来的快,即使可以数据库缓存或主从库提高查询效率,但是在数以百G的数据面前,没有强悍的配置 主从同步快照一次的时间就够瞧的,拆库拆表就成了最好的选择。
--创建分区文件组
alter database Test add filegroup testgf1
alter database Test add filegroup testgf2
--创建分区文件
alter database Test add file
(
name=testdata1,
filename='D:\testdb\testdata1.ndf',
size=5MB,
maxsize=100MB,
filegrowth=5MB
) to filegroup testgf1;
alter database Test add file
(
name=testdata2,
filename='E:\testdb\testdata2.ndf',
size=5MB,
maxsize=100MB,
filegrowth=5MB
) to filegroup testgf2
--创建分区函数
create partition function testRangePF(int) as range left for values(1000,2000);
--创建分区方案
create partition scheme testRangePS as partition testRangePF to (testgf1,testgf2);
--创建分区表
create table tb(...) on testRangePS(colum);实战:上亿数据如何秒查?
最近在忙着优化集团公司的一个报表。优化完成后,报表查询速度有从半小时以上(甚至查不出)到秒查的质变。从修改SQL查询语句逻辑到决定创建存储过程实现,花了我3天多的时间,在此总结一下,希望对朋友们有帮助。
数据背景
首先,项目是西门子中国在我司实施部署的MES项目,由于项目是在产线上运作(3 years+),数据累积很大。在项目的数据库中,大概上亿条数据的表有5个以上,千万级数据的表10个以上,百万级数据的表,很多…
(历史问题,当初实施无人监管,无人监控数据库这块的性能问题。ps:我刚入职不久…)
不多说,直接贴西门子中国的开发人员在我司开发的SSRS报表中的SQL语句:
select distinct b.MaterialID as matl_def_id, c.Descript, case when right(b.MESOrderID, 12) < '001000000000' then right(b.MESOrderID, 9)
else right(b.MESOrderID, 12) end as pom_order_id, a.LotName, a.SourceLotName as ComLot,
e.DefID as ComMaterials, e.Descript as ComMatDes, d.VendorID, d.DateCode,d.SNNote, b.OnPlantID,a.SNCUST
from
(
select m.lotname, m.sourcelotname, m.opetypeid, m.OperationDate,n.SNCUST from View1 m
left join co_sn_link_customer as n on n.SNMes=m.LotName
where
( m.LotName in (select val from fn_String_To_Table(@sn,',',1)) or (@sn) = '') and
( m.sourcelotname in (select val from fn_String_To_Table(@BatchID,',',1)) or (@BatchID) = '')
and (n.SNCust like '%'+ @SN_ext + '%' or (@SN_ext)='')
) a
left join
(
select * from Table1 where SNType = 'IntSN'
and SNRuleName = 'ProductSNRule'
and OnPlantID=@OnPlant
) b on b.SN = a.LotName
inner join MMdefinitions as c on c.DefID = b.MaterialID
left join Table1 as d on d.SN = a.SourceLotName
inner join MMDefinitions as e on e.DefID = d.MaterialID
where not exists (
select distinct LotName, SourceLotName from ELCV_ASSEMBLE_OPS
where LotName = a.SourceLotName and SourceLotName = a.LotName
)
and (d.DateCode in (select val from fn_String_To_Table(@DCode,',',1)) or (@DCode) = '')
and (d.SNNote like '%'+@SNNote+'%' or (@SNNote) = '')
and ((case when right(b.MESOrderID, 12) < '001000000000' then right(b.MESOrderID, 9)
else right(b.MESOrderID, 12) end) in (select val from fn_String_To_Table(@order_id,',',1)) or (@order_id) = '')
and (e.DefID in (select val from fn_String_To_Table(@comdef,',',1)) or (@comdef) = '')
--View1是一个嵌套两层的视图(出于保密性,实际名称可能不同),里面有一张上亿数据的表和几张千万级数据的表做左连接查询
--Table1是一个数据记录超过1500万的表这个查询语句,实际上通过我的检测和调查,在B/S系统前端已无法查出结果,半小时,一小时 … 。因为我直接在SQL查询分析器查,半小时都没有结果。
(原因是里面对一张上亿级数据表和3张千万级数据表做全表扫描查询)
不由感慨,西门子中国的素质(或者说责任感)就这样?
下面说说我的分析和走的弯路(思维误区),希望对你也有警醒。
探索和误区
首先相关表的索引,没有建全的,把索引给建上。
索引这步完成后,发现情况还是一样,查询速度几乎没有改善。后来想起相关千万级数据以上的表,都还没有建立表分区。于是考虑建立表分区以及数据复制的方案。
这里有必要说明下:我司报表用的是一个专门的数据库服务器,数据从产线订阅而来。就是常说的“读写分离”。
如果直接在原表上建立表分区,你会发现执行表分区的事物会直接死锁。原因是:表分区操作本身会锁表,产线还在推数据过来,这样很容易“阻塞”,“死锁”。
我想好的方案是:建立一个新表(空表),在新表上建好表分区,然后复制数据过来。
正打算这么干。等等!我好像进入了一个严重的误区!
分析: 原SQL语句和业务需求,是对产线的数据做产品以及序列号的追溯,关键是查询条件里没有有规律的”条件”(如日期、编号),贸然做了表分区,在这里几乎没有意义!反而会降低查询性能!
好险!还是一步一步来,先做SQL语句分析。
一、对原SQL语句的分析
1、查询语句的where条件,有大量@var in … or (@var =”) 的片段
2、where条件有like ‘%’+@var+’%’
3、where条件有 case … end 函数
4、多次连接同一表查询,另外使用本身已嵌套的视图表,是不是必须,是否可替代?
5、SQL语句有号,视图中也有号出现
二、优化设计
首先是用存储过程改写,好处是设计灵活。
核心思想是:用一个或多个查询条件(查询条件要求至少输入一个)得到临时表,每个查询条件如果查到集合,就更新这张临时表,最后汇总的时候,只需判断这个临时表是否有值。以此类推,可以建立多个临时表,将查询条件汇总。
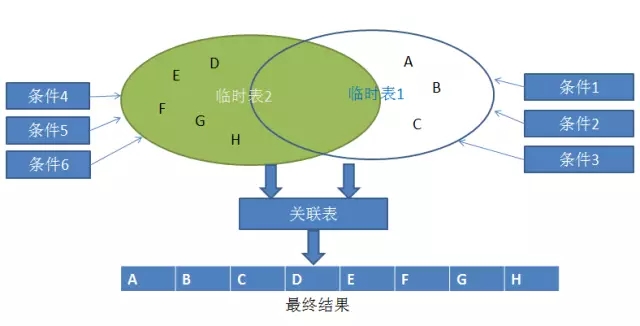
这样做目前来看至少两点好处:
1、省去了对变量进行 =@var or (@var=”)的判断;
2、抛弃sql拼接,提高代码可读性。
再有就是在书写存储过程,这个过程中要注意:
1、尽量想办法使用临时表扫描替代全表扫描;
2、抛弃in和not in语句,使用exists和not exists替代;
3、和客户确认,模糊查询是否有必要,如没有必要,去掉like语句;
4、注意建立适当的,符合场景的索引;
5、踩死 “*” 号;
6、避免在where条件中对字段进行函数操作;
7、对实时性要求不高的报表,允许脏读(with(nolock))。
三、存储过程
如果想参考优化设计片段的详细内容,请参阅SQL代码:
(PS代码太多,可以去博客查看顶头灰色部分)
虽然牺牲了代码的可读性,但创造了性能价值。本人水平有限,还请各位不吝赐教!
最后,将SSRS报表替换成此存储过程后,SQL查询分析器是秒查的。B/S前端用时1~2秒!
四、总结
平常的你是否偶尔会因急于完成任务而书写一堆性能极低的SQL语句呢?写出可靠性能的SQL语句不难,难的是习惯。
本文的优化思想很简单,关键点是避免全表扫描 & 注重SQL语句写法 & 索引,另外,如果你查询的表有可能会在查询时段更新,而实际业务需求允许脏读,可加with(nolock)预防查询被更新事物阻塞。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









