









1、数据如下:
user_id,dep_id,group_id,salary
10001,a,101,13000
10002,a,101,17000
10003,a,101,9000
10004,a,101,11000
10005,a,101,18000
10006,a,102,16000
10007,a,102,10000
10008,b,103,18000
10009,b,103,11000
10010,b,103,16000
10011,b,103,12000
10012,c,104,16000
10013,c,105,18000
10014,c,105,18000
10015,c,106,12000
10016,c,106,14000
10017,c,106,14000
10018,c,106,9000
10019,c,106,8000
10020,c,106,9000
10021,c,106,10000
2、建表如下:
create external table test.salaryinfo(
user_id string,
dep_id string,
group_id string,
salary int
)
row format delimited
fields terminated by ','
stored as textfile
location '/test'
tblproperties("skip.header.line.count"="1")
;
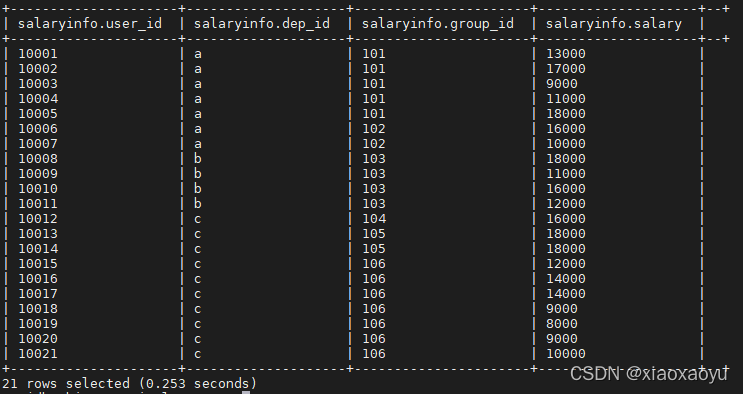
3、grouping sets
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
按照dep_id,group_id两个字段分别分组
select dep_id,group_id,count(1)
from salaryinfo
group by dep_id,group_id
grouping sets (dep_id,group_id)
;
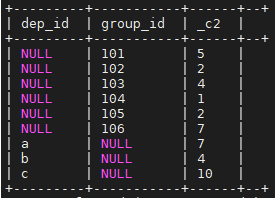
按照dep_id,group_id两个字段以及以及(dep_id,group_id)组合起来分别分组
select dep_id,group_id,count(1)
from salaryinfo
group by dep_id,group_id
grouping sets (dep_id,group_id,(dep_id,group_id))
;
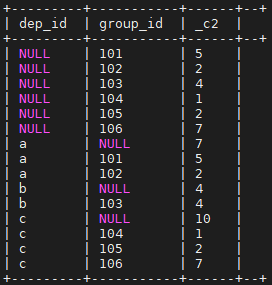
grouping__id表示结果属于哪一个分组集合,一般用来排序,看上去更清晰
select dep_id,group_id,count(1),grouping__id
from salaryinfo
group by dep_id,group_id
grouping sets (dep_id,group_id)
;
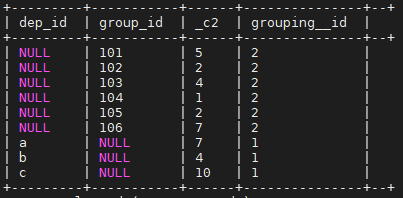
4、cube
根据GROUP BY的维度的所有组合进行聚合,和grouping sets类似,只不过grouping sets更加自定义,可以根据需求来;cube是所有的分组组合
以下SQL等于分组字段分别为以下4种的union all
- 分组字段为空,即整张表的聚合
- 分组字段为dep_id
- 分组字段为group_id
- 分组字段为dep_id,group_id
select dep_id,group_id,count(1),grouping__id
from salaryinfo
group by dep_id,group_id
with cube
order by grouping__id
;
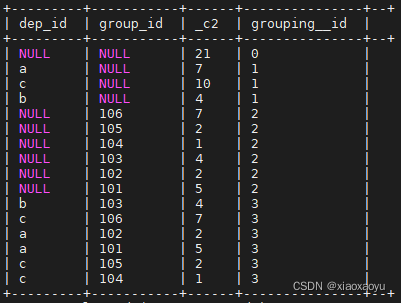
5、rollup
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合
select dep_id,group_id,count(1),grouping__id
from salaryinfo
group by dep_id,group_id
with rollup
order by grouping__id
;
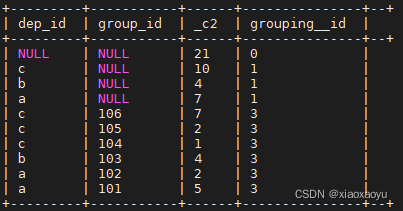
select dep_id,group_id,count(1),grouping__id
from salaryinfo
group by group_id,dep_id
with rollup
order by grouping__id
;















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









