







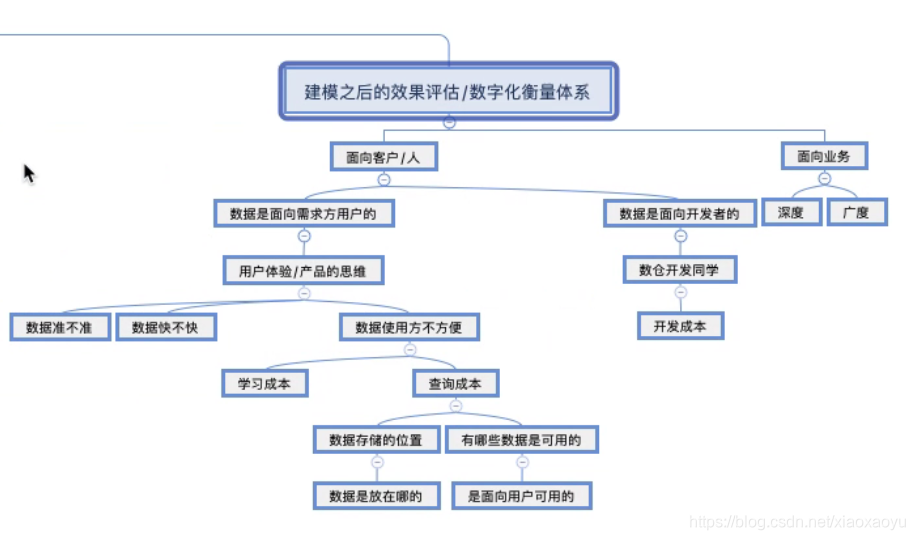
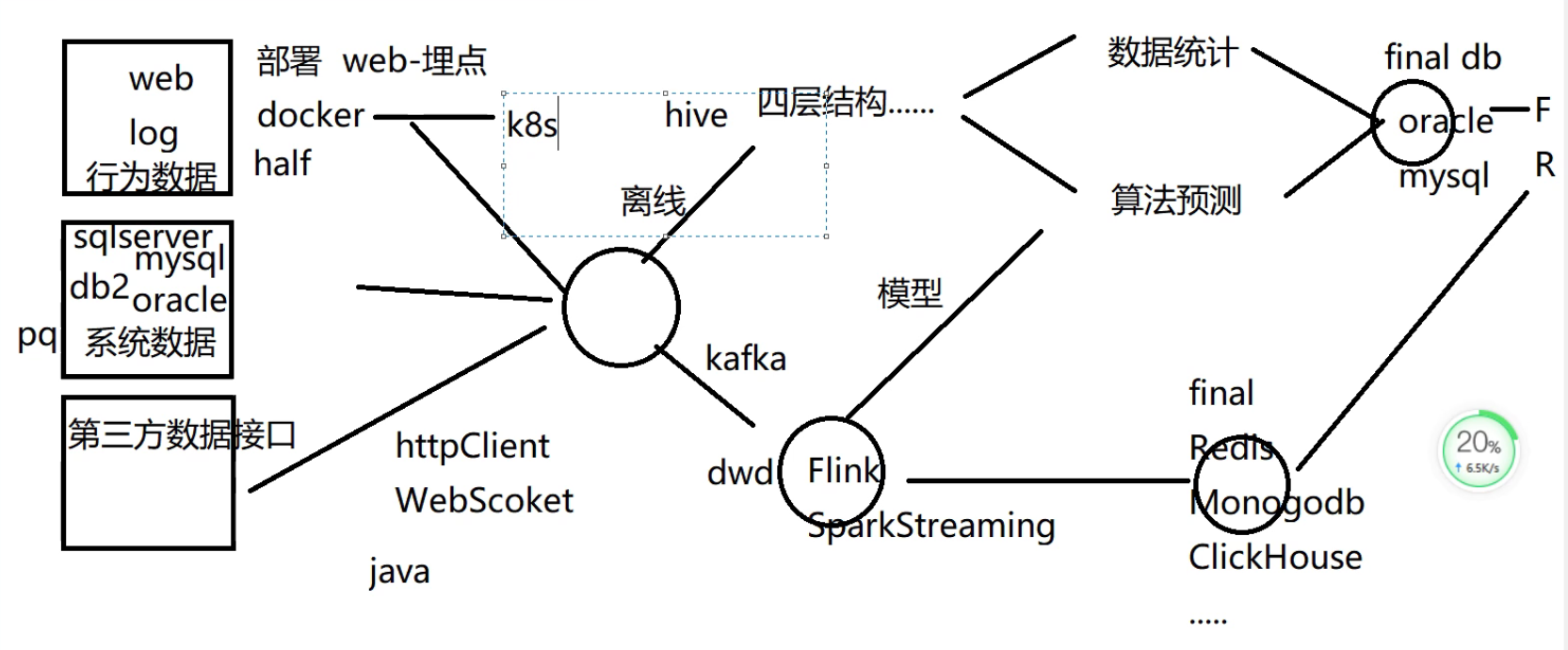
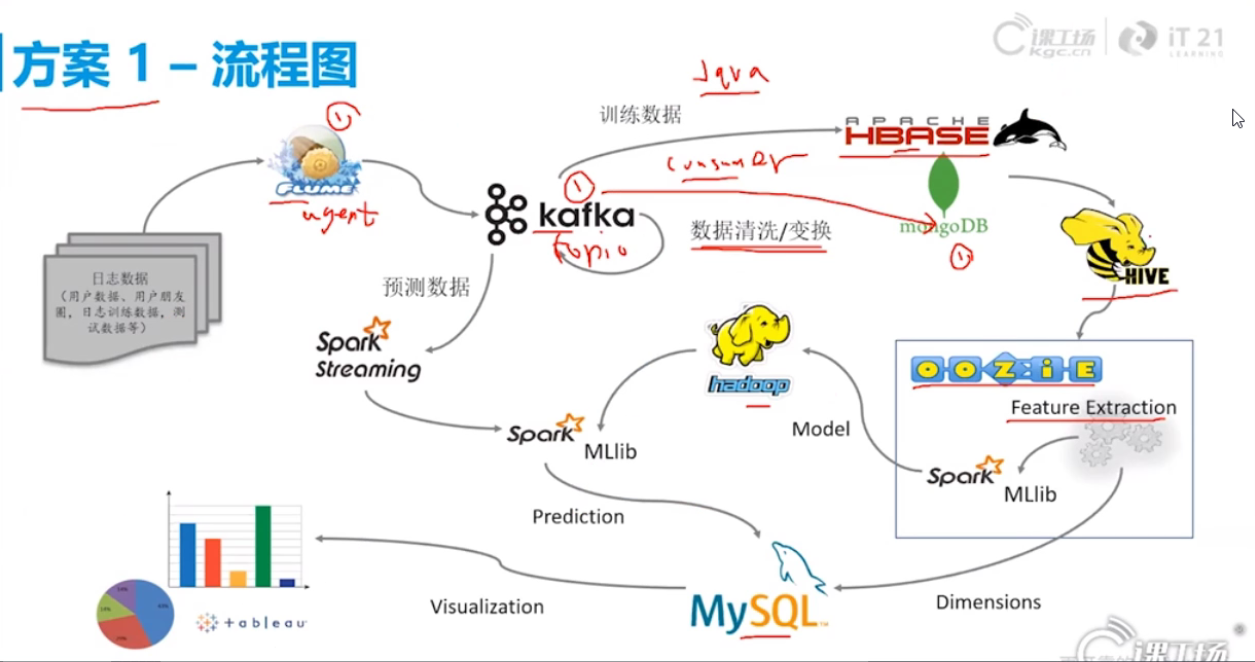
 文章详述了大数据处理流程,包括数据上传、SparkSQL数据清洗、SparkStreaming与Flink处理Kafka数据,及HBase存储、Hive数仓构建、PowerDesigner模型设计等。进一步介绍了KMeans与Random Forest算法应用,实现数据分类与预测,最终通过MySQL与Finereport展示分析结果。
文章详述了大数据处理流程,包括数据上传、SparkSQL数据清洗、SparkStreaming与Flink处理Kafka数据,及HBase存储、Hive数仓构建、PowerDesigner模型设计等。进一步介绍了KMeans与Random Forest算法应用,实现数据分类与预测,最终通过MySQL与Finereport展示分析结果。
文章目录
- 1、上传表
- 2、使用SparkSQL对问题数据进行探索和处理
- 3、kafka多线程并行写进不同分区
- 4、Flume采集数据流向kafka
- 5、使用spark-Streaming读取kafka的topic,然后通过SparkStreaming的RDD算子可以对表进行数据处理
- 6、sparkStreaming对topic数据进行清洗完之后,再重新写入kafka——面向过程
- 6.1、sparkStreaming对topic数据进行清洗完之后,再重新写入kafka——面向对象
- 7、flink读取kafka数据对数据进行清洗,然后再重新写入kafka——面向过程
- 7.1、flink读取kafka数据对数据进行清洗,然后再重新写入kafka——面向对象
- 8、读取Kafka通过HBase的JavaAPI写入到HBase中
- 9、建立Hive映射HBase的表,构建数仓的ODS层
- 10、使用powerdesigner设计模型
- 11、构建DWD层数据:清洗异常值
- 12、构建DWS层数据:轻度聚合
- 13、初步构建DM层宽表,不过还缺聚会特征那列,后面加上
- 14、使用python用Kmeans算法对events表的特征列进行分类
- 15、构建最终的DM层宽表
- 16、使用随机森林对宽表的特征数据进行分类,得出预测label值的预测分类模型
- 17、通过SparkStreaming从kafka里读取test测试数据
- 18、使用sparkml读取训练模型,传入同等格式的数据,得到预测结果
- 19、把预测结果写入MySQL
- 20、把维度表导入到MySQL中和结果表对应上
- 21、使用finereport可视化
1、上传表
[root@singlelinux data]# hdfs dfs -mkdir -p /events/data
[root@singlelinux data]# hdfs dfs -put -f /opt/data/*.csv /events/data
2、使用SparkSQL对问题数据进行探索和处理
探索思路:
思路1,对空值进行处理:
舍弃、根据数量判断是否保留、加盐、平均数或中位数代替
用新值代替时,用agg求出新值(表的形式),然后crossjoin笛卡尔积上,然后可以用正则或者casewhen函数代替
思路2,对重复值进行去重:
删掉、加盐
- 去重后验证前后数量是否相等
- repartiton重新根据列进行分区,然后对分区进行排序,再使用dropDuplicates方法删除第一个之后的数据
- repartition可以用分组列直接作为参数,类似sql里窗口函数的distribute by XX,进行逻辑分区
思路3,行转列:
使用split+explode处理
思路4,规范化字段内容
比如异常日期格式
2.1、User表
- 正则提取生日符合1950-2020以内的,把其他的使用自定义函数直接修改为平均值
- 清理性别列的无效值
- 把注册时间(2012-10-02T06:40:55.524Z)为null的值修改为平均值,原时间函数规则不能直接用unix_timestamp
//user表生日那列不符合范围()的数据全部替换为平均值
object DataDisc2_Users {
//自定义函数udf,求平均年份
val calAge = udf((age: String, defyear: String) => {
val reg = "^(19[5-9][0-9]|20[0-1][0-9]|2020)$".r
if (reg.findAllMatchIn(age).hasNext) {
age
} else defyear
})
//性别判断
val genderUnique = udf((sex: String) => {
if (sex == null) {
"unknow"
} else if (sex.equals("男") || sex.equals("1")) {
"male"
} else {
"female"
}
})
//yyyMMdd格式转换
val ymd = udf((str: String) => {
if (str == null || str.equals("None")) {
null
} else {
// val tms = str.split("[T.]")
val r = "[T.]"
val tms = str.split(r)
tms(0) + " " + tms(1)
}
})
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("cl").getOrCreate()
val sc = spark.sparkContext
val df: DataFrame = spark.read.format("csv").option("header", "true")
.load("hdfs://single:9000/events/data/users.csv").cache()
import spark.implicits._
import org.apache.spark.sql.functions._
//正则提取生日符合1950-2020以内的,把其他的使用自定义函数直接修改为平均值
println("正则提取生日符合1950-2020以内的,把其他的使用自定义函数直接修改为平均值")
val pj = df.filter("birthyear rlike '19[5-9]{1}[0-9]{1}|20[0-1]{1}[0-9]|2020'")
.agg(floor(avg($"birthyear")).as("pjyear"))
df.crossJoin(pj).withColumn("byear", calAge($"birthyear", $"pjyear"))
.show()
//方法2:用case when函数,方法3:用union all
println("用case when把非法值直接修改为平均值")
df.crossJoin(pj)
.withColumn("birthyear2", when(df("birthyear") < 2020 && df("birthyear") > 1950, df("birthyear")).otherwise(pj("pjyear")))
.show()
//用cast,不是数字型的自动转化为null
println("用cast,不是数字型的自动转化为null")
// df.withColumn("birthyear", $"birthyear".cast(IntegerType)).filter("birthyear").show()
//清理性别列的无效值1
println("清理性别列的无效值1")
df.groupBy($"gender").agg(max($"gender")).show()
df.withColumn("gender", when($"gender".isNull, "unknown").otherwise($"gender")).groupBy($"gender").agg(count($"gender")).show()
//清理性别列的无效值2
println("清理性别列的无效值2")
df.withColumn("gender", genderUnique($"gender")).groupBy($"gender").agg(count($"gender")).show()
//把注册时间(2012-10-02T06:40:55.524Z)为null的值修改为平均值,原时间函数规则不能直接用unix_timestamp
df.filter($"joinedAt".isNotNull)
.withColumn("joinedAt2",unix_timestamp(regexp_replace(regexp_replace($"joinedAt","Z",""),"T"," ")))
.agg(avg($"joinedAt2").as("pjtime"))
.select(from_unixtime($"pjtime","yyyy-MM-dd'T'hh:mm:ss'Z'"))
.show()
//使用regexp_extract函数
df.withColumn("joinedAt3",
concat_ws(" ",
regexp_extract($"joinedAt","(.*)T(.*).[0-9]{3}Z",1),
regexp_extract($"joinedAt","(.*)T(.*).[0-9]{3}Z",2)))
.show(false)
//使用自定义函数
val pjtime = df.filter($"joinedAt".isNotNull).withColumn("joinedAt", ymd($"joinedAt"))
.agg(floor(avg(unix_timestamp($"joinedAt"))).alias("pjtime"))
df.crossJoin(pjtime).withColumn("joinedAt",
when(ymd($"joinedAt").isNull,from_unixtime(pjtime("pjtime")))
.otherwise(ymd(df("joinedAt"))))
.drop($"pjtime").show()
//使用lit
val l = df.filter($"joinedAt".isNull).withColumn("joinedAt", ymd($"joinedAt")).count()
df.withColumn("joinedAt",lit(l)).show()
df.show(false)
spark.close()
}
}
- 判断id列是否存在空值
- 清理users表上的locale空值
- 用朋友表friends的地区更换空值
//数据清洗users表
object DataDisc_Users {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("cl").getOrCreate()
val sc = spark.sparkContext
val df: DataFrame = spark.read.format("csv").option("header", "true")
.load("hdfs://single:9000/events/data/users.csv").cache()
import spark.implicits._
import org.apache.spark.sql.functions._
// 1、判断id列是否存在空值
df.select($"user_id").filter(_.anyNull).show()
// 判断id列去重后和不去重的计数是否相同
df.agg(countDistinct($"user_id").as("aaa"), count($"user_id").as("bbb")).show()
// 去掉在locale里没有的
val localeds = sc.textFile("hdfs://single:9000/events/data/locale.txt").map(x => x.split("\t")).map(x => Row(x(1)))
val structType = StructType(
Array(
StructField("local", StringType)
)
)
val locale = spark.createDataFrame(localeds, structType)
df.join(locale, df("locale") === locale("local"), "left").filter(locale("local").isNull).show()
// 清理users表上的locale空值
df.filter(df("locale").isNotNull)
// df--user.csv表上local有空值,用此人朋友中最多的local替代,关联friend表
// val friends = sc.textFile("hdfs://single:9000/events/data/user_friends.csv").filter(x=>(!x.startsWith("user"))).map(_.split(",")).map(x => (x(0), x(1).split(" ")))
// .flatMapValues(x => x).toDF().select($"_1".as("user"),$"_2".as("friendid"))
//2、用朋友的地区更换空值
//读取friend表
val fr: DataFrame = spark.read.format("csv").option("header", "true")
.load("hdfs://single:9000/events/data/user_friends.csv").cache()
//筛选出user表locale为空的值
val tmp = df.filter($"locale".isNull).withColumnRenamed("user_id", "user")
//把friend表的第二列朋友列表炸开,或者用flatmapvalue拉平映射
.join(fr, Seq("user"), "inner").select("user", "friends")
.withColumn("friendid", explode(split($"friends", " "))).drop("friends")
//窗口函数
val wnd = Window.partitionBy("user").orderBy(desc("peoplenum"))
//
val tmp2 = tmp.join(df, $"user_id" === $"friendid", "inner")
.select("user", "locale").groupBy("user", "locale")
.agg(count($"locale").alias("peoplenum"))
.select($"user", $"locale".alias("loc"), row_number().over(wnd).alias("rank"))
.filter("rank==1").cache()
df.join(tmp2, $"user" === $"user_id", "left")
.withColumn("localename", coalesce($"locale", $"loc"))
.drop("locale", "loc", "user", "rank")
.show()
spark.close()
}
}
2.2、events表
- 判断id列是否有重复
- 第二列主持人是否为空
- 那个主持人的主持的活动最多
object DataDisc_Events{
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]").appName(this.getClass.getSimpleName).getOrCreate()
val df = spark.read.format("csv").option("header", "true").load("hdfs://single:9000/events/data/events.csv")
import spark.implicits._
import org.apache.spark.sql.functions._
/**
//验证有多少行 3137973
//[root@single ~]# hdfs dfs -cat /events/data/events.csv |wc -l 3137973
val linenum = spark.read.format("csv").load("hdfs://single:9000/events/data/events.csv").count()
//判断id列是否有重复
//方法1:可以看到输出是空值
df.select($"event_id").groupBy($"event_id").agg(count($"event_id").as("num")).filter($"num"=!=1).show()
//方法2:求出聚合后的行数,和之前的行数作对比
val distinctnum = df.groupBy($"event_id").agg(count("event_id")).count()
df.agg(countDistinct($"event_id"))
//第二列主持人是否为空
df.select($"user_id").filter(_.anyNull).show()
df.select($"user_id").where($"user_id".isNull).show()
//那个主持人的主持的活动最多
df.groupBy($"user_id").agg(count($"user_id").as("cnt"))
.orderBy($"cnt".desc).limit(1).show()
df.groupBy($"user_id").agg(count($"user_id").as("cnt"))
.orderBy($"cnt".desc).take(1).foreach(println)
*/
//判断events。csv里的user_id在user.csv里有没有
val userdf: DataFrame = spark.read.format("csv").option("header", "true")
.load("hdfs://single:9000/events/data/users.csv")
userdf.limit(5).show()
println(df.select(df("user_id".distinct))
.join(userdf.select($"user_id", $"locale").distinct(), Seq("user_id"), "left")
.where($"locale".isNull).count())
//except、intersect,交集差集
println("差集")
println(df.select($"user_id").except(userdf.select($"user_id")).count())
println("交集")
println(df.select($"user_id").intersect(userdf.select($"user_id")).count())
}
}
2.3、user_friends表
- explode一对多变成一对一,在hive中配合lateral view侧视图用
object DataDisc_userfriend{
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]").appName(this.getClass.getSimpleName).getOrCreate()
val df = spark.read.format("csv").option("header", "true").load("hdfs://single:9000/events/data/user_friends.csv")
import spark.implicits._
//user_friends.csv 的一对多变成一对一
//用explode炸开,不用laterview
df.show(5)
val dfexplode: DataFrame = df.withColumn("friendid", explode(split($"friends", " "))).drop($"friends")
dfexplode.show()
println(dfexplode.count())
//使用侧视图炸开
df.createOrReplaceTempView("user_friends")
spark.sql(
"""
|select user,friendid
|from user_friends
|lateral view explode(split(friends,' ')) fs as friendid
|""".stripMargin).show()
spark.sql(
"""
|select user,index,friendid
|from user_friends
|lateral view posexplode(split(friends,' ')) fs as index,friendid
|""".stripMargin).show()
}
}
2.4、event_attendees
- 炸开多列Union回去
//侧视图炸开多列然后union回去
object DataDisc_event_attendees{
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()
val df: DataFrame = spark.read.format("csv").option("header", "true").load("hdfs://single:9000/events/data/event_attendees.csv")
import spark.implicits._
val yes: DataFrame = df.select($"event", explode(split($"yes", " ")).as("userid")).withColumn("action", lit("yes")).drop($"yes")
val maybe: DataFrame = df.select($"event", explode(split($"maybe", " ")).as("userid")).withColumn("action", lit("maybe")).drop($"maybe")
val invited: DataFrame = df.select($"event", explode(split($"invited", " ")).as("userid")).withColumn("action", lit("invited")).drop($"invited")
val no: DataFrame = df.select($"event", explode(split($"no", " ")).as("userid")).withColumn("action", lit("no")).drop($"no")
val cnt: Dataset[Row] = yes.union(maybe).union(invited).union(no)
println(cnt.count())
}
}
2.5、trains表
- 求每个用户的每个聚会的最后时间的那条信息
object DataDisc_Trains{
def main(args: Array[String]): Unit = {
///events/data/train.csv
//每个用户对应的每个聚会的最后时间的那条信息
val spark: SparkSession = SparkSession.builder().master("local[*]").appName(this.getClass.getSimpleName).getOrCreate()
import spark.implicits._
val df: DataFrame = spark.read.format("csv").option("header", "true").load("hdfs://single:9000/events/data/train.csv")
df.show(5,false)
val lastpereventDF: Dataset[Row] = df.select($"user", $"event", $"invited", $"timestamp", $"interested", $"not_interested",
row_number().over(Window.partitionBy($"user", $"event").orderBy(desc("timestamp"))).as("rn"))
.filter($"rn" === 1)
//使用自定义函数转化时间后再处理
df.withColumn("timestamp2",unix_timestamp(invitedTime($"timestamp"))).show(false)
//dropDuplicates
}
//正则提取获取时间
val invitedTime=udf((time:String)=>{
val reg = "(.*)\\..*".r
val reg(a)=time
a
})
val invitedTime2=udf((time:String)=>{
val r: Regex = "(\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}:\\d{2})".r
val matches: Iterator[Regex.Match] = r.findAllMatchIn(time)
matches.mkString
})
val inviteTime3=udf((time:String)=>{
})
//FileInputFormat
}
drop database if exists events cascade;
create database events;
use events;
create external table event_attendees(
event string,
yes string,
maybe string,
invited string,
no string
)
row format delimited
fields terminated by ','
location '/events/data/event_attendees'
tblproperties("skip.header.line.count"="1");
select * from event_attendees limit 1;
use events;
create table if exists events.event_attendees_new;
create table events.event_attendees_new as
with
t1 as (
select event,userid,'yes'
from event_attendees
lateral view explode(split(yes,' ')) a as userid),
t2 as (
select event,userid,'maybe'
from event_attendees
lateral view explode(split(yes,' ')) a as userid),
t3 as (
select event,userid,'invited'
from event_attendees
lateral view explode(split(yes,' ')) a as userid),
t4 as (
select event,userid,'no'
from event_attendees
lateral view explode(split(yes,' ')) a as userid)
select distinct * from t1
union all
select distinct * from t2
union all
select distinct * from t3
union all
select distinct * from t4;
3、kafka多线程并行写进不同分区
3.1、基本的生产者消费者API
- java
- scala
3.2、producer多线程往不同分区写数据的API
- 代码
- 打包成jar包,在windows环境下使用java -jar 运行配置(胖包)
https://blog.csdn.net/xiaoxaoyu/article/details/115315577
4、Flume采集数据流向kafka
4.1、配置文件event_attendees、events、users、test、train、user_friends
4.2、依次创建kafka中对应主题
topic:
event_attendees_raw
events_raw
test_raw
train_raw
user_friends_raw
users_raw
创建主题
kafka-topics.sh --create --topic event_attendees_raw --zookeeper single:2181 --replication-factor 1 --partitions 1
4.3、打开消费者,执行对应flume-ng命令
4.4、查看最终flume条数
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic event_attendees_raw --time -1
4.5、flume脚本案例(event_attendees)
其他的修改组件名即可
######任务配置文件
#组件名称缩写
a1.channels = c1
a1.sources = s1
a1.sinks = k1
# 组件类型名
a1.sources.s1.type = spooldir
a1.sources.s1.channels = c1
a1.sources.s1.spoolDir = /opt/data/event_attendees
#单行最大长度
a1.sources.s1.deserializer.maxLineLength=120000
#正则去掉首行
a1.sources.s1.interceptors=i1
a1.sources.s1.interceptors.i1.type=regex_filter
a1.sources.s1.interceptors.i1.regex=\s*event.*
a1.sources.s1.interceptors.i1.excludeEvents=true
# channel组件类型为file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flume/checkpoint
a1.channels.c1.dataDirs = /opt/flume/data
#指定sink组件类型为kafka
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = event_attendees
a1.sinks.k1.kafka.bootstrap.servers = single:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
#kafka 参数调优
a1.sinks.k1.kafka.producer.linger.ms = 10
a1.sinks.k1.kafka.producer.batch.size=524288
#压缩需要安装GCC,要不然不能用
#a1.sinks.k1.kafka.producer.compression.type = snappy
#指定sink的 channel
a1.sinks.k1.channel = c1
执行其他脚本的命令
event_attendees:24144
打开消费者
kafka-console-consumer.sh --bootstrap-server single:9092 --topic event_attendees_raw --from-beginning
执行flume脚本
flume-ng agent -n a1 --conf /opt/software/flume160/conf/ -f /opt/flumeconf/event_attendees.conf -Dflume.root.logger=DEBUG,console
查看是否导进去
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic event_attendees_raw --time -1
events:3137972
kafka-topics.sh --create --topic event_attendees_raw --zookeeper single:2181 --replication-factor 1 --partitions 1
kafka-topics.sh --zookeeper single:2181 --delete --topic events_raw
打开消费者
kafka-console-consumer.sh --bootstrap-server single:9092 --topic events_raw --from-beginning
执行flume脚本
flume-ng agent -n a2 --conf /opt/software/flume160/conf/ -f /opt/flumeconf/events.conf -Dflume.root.logger=INFO,console
查看是否导进去
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic events_raw --time -1
test:10237
kafka-topics.sh --create --topic test_raw --zookeeper single:2181 --replication-factor 1 --partitions 1
kafka-topics.sh --zookeeper single:2181 --delete --topic test_raw
打开消费者
kafka-console-consumer.sh --bootstrap-server single:9092 --topic test_raw --from-beginning
执行flume脚本
flume-ng agent -n a6 --conf /opt/software/flume160/conf/ -f /opt/flumeconf/test.conf -Dflume.root.logger=DEBUG,console
查看是否导进去
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic test_raw --time -1
train:15398
kafka-topics.sh --create --topic train_raw --zookeeper single:2181 --replication-factor 1 --partitions 1
kafka-topics.sh --zookeeper single:2181 --delete --topic train_raw
打开消费者
kafka-console-consumer.sh --bootstrap-server single:9092 --topic train_raw --from-beginning
执行flume脚本
flume-ng agent -n a5 --conf /opt/software/flume160/conf/ -f /opt/flumeconf/train.conf -Dflume.root.logger=DEBUG,console
查看是否导进去
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic train_raw --time -1
user_friends:38202
打开消费者
kafka-console-consumer.sh --bootstrap-server single:9092 --topic user_friends_raw --from-beginning
执行flume脚本
flume-ng agent -n a4 --conf /opt/software/flume160/conf/ -f /opt/flumeconf/user_friends.conf -Dflume.root.logger=DEBUG,console
查看是否导进去
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic user_friends_raw --time -1
users:38209
kafka-topics.sh --create --topic users_raw --zookeeper single:2181 --replication-factor 1 --partitions 1
kafka-topics.sh --zookeeper single:2181 --delete --topic users_raw
打开消费者
kafka-console-consumer.sh --bootstrap-server single:9092 --topic users_raw --from-beginning
执行flume脚本
flume-ng agent -n a3 --conf /opt/software/flume160/conf/ -f /opt/flumeconf/users.conf -Dflume.root.logger=DEBUG,console
查看是否导进去
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list single:9092 --topic users_raw --time -1
5、使用spark-Streaming读取kafka的topic,然后通过SparkStreaming的RDD算子可以对表进行数据处理
连接kafka主题:
需要的pom依赖
#spark的版本用2.1.0,不能用2.3.4这种过高的
spark-streaming_2.11
spark-sql_2.11
spark-streaming-kafka-0-10_2.11
kafka_2.12
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spark.version>2.1.0</spark.version>
<kafka.version>2.0.0</kafka.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>${kafka.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
配置中,StringDeserializer的包容易导错,要注意
需要一个kafka utils工具包,导入依赖
object ReadKafkaTopic_event_attendees_raw {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.streaming.kafka.consumer.poll.ms", "10000") //解决:Exception:after polling for 512
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("checkpoint")
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "single:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "xym",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest",
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> "500" //一次拉取条数
)
//需要一个kafka utils工具包,spark Streaming kafka,版本不能太高,0-8_2.11
val ea = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("event_attendees_raw"), kafkaParams)
)
/**
* val yes = ea.map(x => {
* val info = x.value().split(",",-1)
* (info(0), info(1))
* }).filter(_._2!="")
* .flatMap(x=> {
* x._2.split(" ").map((x._1, _, "yes"))
* })
*/
val result = ea.map(x => {
val info = x.value().split(",", -1)
Array((info(0), info(1).split(" "), "yes"), (info(0), info(2).split(" "), "maybe"), (info(0), info(3).split(" "), "invited"), (info(0), info(4).split(" "), "no"))
}).flatMap(x => x).flatMap(x => x._2.map(y => (x._1, y, x._3))).filter(_._2!="")
result.foreachRDD(x=>x.foreach(println))
ssc.start()
ssc.awaitTermination()
}
}
object ReadKafkaTopic_user_friends_raw {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.streaming.kafka.consumer.poll.ms", "10000") //解决:Exception:after polling for 512
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("checkpoint")
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "single:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "xym",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest",
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> "500" //一次拉取条数
)
//需要一个kafka utils工具包,spark Streaming kafka,版本不能太高,0-8_2.11
val ku = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("user_friends_raw"), kafkaParams)
)
// ku.foreachRDD(cr=>println(cr))//可以拿到ConsumerRecorder的值
//删除空值
ku.filter(x => {
val reg = ",$".r
val iter = reg.findAllMatchIn(x.value())
!iter.hasNext
}).flatMap(x => {
var info = x.value().split(",")
info(1).split(" ").map(y => (info(0), y))
}).foreachRDD(x => x.foreach(println))
ssc.start()
ssc.awaitTermination()
}
}

6、sparkStreaming对topic数据进行清洗完之后,再重新写入kafka——面向过程
参考文章:Spark Streaming将处理结果数据写入Kafka
方法1:
- KafkaProducer不可序列化,只能在foreachPartition内部创建
- 对于每个KafkaProducer都创建一次连接,不灵活且低效
方法2:
- 使用伴生类创建KafkaProducer包装器,构造参数为生产者对象(懒加载,遇到action算子才真正创建),方法为
生产者对象KafkaProducer发送一条生产记录producerRecord;然后在伴生对象的apply方法中new对应伴生类的对象(因为该类构造器需要传入参数,所以顺便使用匿名函数创建一个生产者作为对象的参数),这样在其他地方就可以函数式调用该类下的方法了(可以理解为调用时已经创建好该类的匿名对象了)
class KafkaSink[K, V](producer: () => KafkaProducer[K, V]) extends Serializable {
//懒汉模式,定义一个producer
lazy val prod: KafkaProducer[K, V] = producer()
def send(topic: String, key: K, value: V) = {
prod.send(new ProducerRecord[K, V](topic, key, value))
}
def send(topic: String, value: V) = {
prod.send(new ProducerRecord[K, V](topic, value))
}
}
object KafkaSink {
import scala.collection.JavaConversions._
def apply[K, V](config: Map[String, Object]) = {
val createKafkaProducer = () => {
val produ = new KafkaProducer[K, V](config)
// //销毁数据时做检查,删了的话,出现垃圾时无法回收
// sys.addShutdownHook{
// produ.close()
// }
produ
}
new KafkaSink[K, V](createKafkaProducer)
}
def apply[K, V](config: Properties): KafkaSink[K, V] = apply(config.toMap)
}
- 配置消费者参数:SparkStreaming使用直连的方式连接kafkatopic(策略为:消费本地数据且按照topic订阅)
- SparkStreaming在消费时,会同时进行数据处理(根据用户需求),然后再将清洗后的数据写入一个新的topic
- 处理后的数据,把它封装后通过生产者写入到对应分区内即可。这里我们采用广播变量的方式,把封装好的KafkaSink对象(传入生产者的参数到伴生对象KafkaSink里,自动调用apply方法执行,apply方法返回的是KafkaSink(producer)对象)传到每个executor上,每个executor创建一次kafka消费者的连接,提高效率
- 在进行数据处理时,调用广播变量的方法把结果数据封装写入到topic中
- 最后,懒加载需要行动算子才会触发执行,可以加个foreach(x=>x)触发
- 广播变量里连接consumer的变量
KafkaSink[String, String](producerParams)因为是伴生对象,直接省略apply方法用伴生类型代替,如果不好理解的话,可以换成KafkaSink.apply(producerParams)
object ReadKafkaTopic_event_attendees_raw {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.streaming.kafka.consumer.poll.ms", "10000") //解决:Exception:after polling for 512,服务器不稳定
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("checkpoint")
//Kafka消费者参数
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "single:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "ea1",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest",
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> "500" //一次拉取条数
)
val ea: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("event_attendees_raw"), kafkaParams)
)
//kafka生产者参数
val producerParams = Map (
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG->"single:9092",
ProducerConfig.ACKS_CONFIG->"1",
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG->classOf[StringSerializer],
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG->classOf[StringSerializer]
)
//用kafkaSink作为广播的对象
val ks = ssc.sparkContext.broadcast(KafkaSink[String,String](producerParams))
ea.flatMap(x => {
val info = x.value().split(",", -1)
Array(
(info(0), info(1).split(" "), "yes"),
(info(0), info(2).split(" "), "maybe"),
(info(0), info(3).split(" "), "invited"),
(info(0), info(4).split(" "), "no")
)
}).flatMap(x => x._2.map(y => (x._1, y, x._3))).filter(_._2!="").foreachRDD(rdd=>rdd.foreachPartition(iter=>{
iter.map(msg=>{
ks.value.send("event_attendees_ss",msg.productIterator.mkString(","))
}).foreach(x=>x)//懒执行需要行动算子,否则会一直卡着不动
}))
//.toStream.foreach(_.get())迭代器转化为流,仅触发行动操作。foreach也是行动算子,就够了
ssc.start()
ssc.awaitTermination()
}
}
输出结果:
6.1、sparkStreaming对topic数据进行清洗完之后,再重新写入kafka——面向对象
参考文章:sparkStreaming对kafka topic数据进行处理后再重新写入kafka(2)
7、flink读取kafka数据对数据进行清洗,然后再重新写入kafka——面向过程
- 读:设置kafka消费者为flink数据源
- transform
- 写:设置kafka生产者为flink数据源
object FlinkReadWriteKafka_event_attendees_raw {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val prop = new Properties()
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "single:9092")
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "xym")
prop.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val ds = env.addSource(
new FlinkKafkaConsumer[String](
"event_attendees_raw",
new SimpleStringSchema(),
prop
)
)
val dataStream = ds.map(x => {
val info = x.split(",", -1)
Array(
(info(0), info(1).split(" "), "yes"),
(info(0), info(2).split(" "), "maybe"),
(info(0), info(3).split(" "), "invited"),
(info(0), info(4).split(" "), "no")
)
}).flatMap(x => x).flatMap(x => x._2.map(y => (x._1, y, x._3))).filter(_._2!="")
.map(_.productIterator.mkString(","))
val prop2 = new Properties()
prop2.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092")
prop2.setProperty(ProducerConfig.RETRIES_CONFIG,"0")
prop2.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
prop2.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
dataStream.addSink( new FlinkKafkaProducer[String](
"single:9092",
"event_attendees_ff",
new SimpleStringSchema()) )
env.execute("event_attendees_ff")
}
}
object FlinkReadWriteKafka_user_friends_raw {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val prop = new Properties()
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "single:9092")
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "xym")
prop.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val ds = env.addSource(
new FlinkKafkaConsumer[String](
"user_friends_raw",
new SimpleStringSchema(),
prop
)
)
val dataStream = ds.flatMap(x => {
val info = x.split(",", -1)
info(1).split(" ").map((info(0),_))
}).filter(_._2!="")
.map(_.productIterator.mkString(","))
val prop2 = new Properties()
prop2.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092")
prop2.setProperty(ProducerConfig.RETRIES_CONFIG,"0")
prop2.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
prop2.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
dataStream.addSink( new FlinkKafkaProducer[String](
"single:9092",
"user_friends_ff",
new SimpleStringSchema()) )
env.execute("user_friends_ff")
}
}
7.1、flink读取kafka数据对数据进行清洗,然后再重新写入kafka——面向对象
参考文章:sparkStreaming对kafka topic数据进行处理后再重新写入kafka(2)
与前文一样,实际上flink读取和写入kafka比SparkStreaming还要更简单写,整体思路就不多说了,可以参考前文
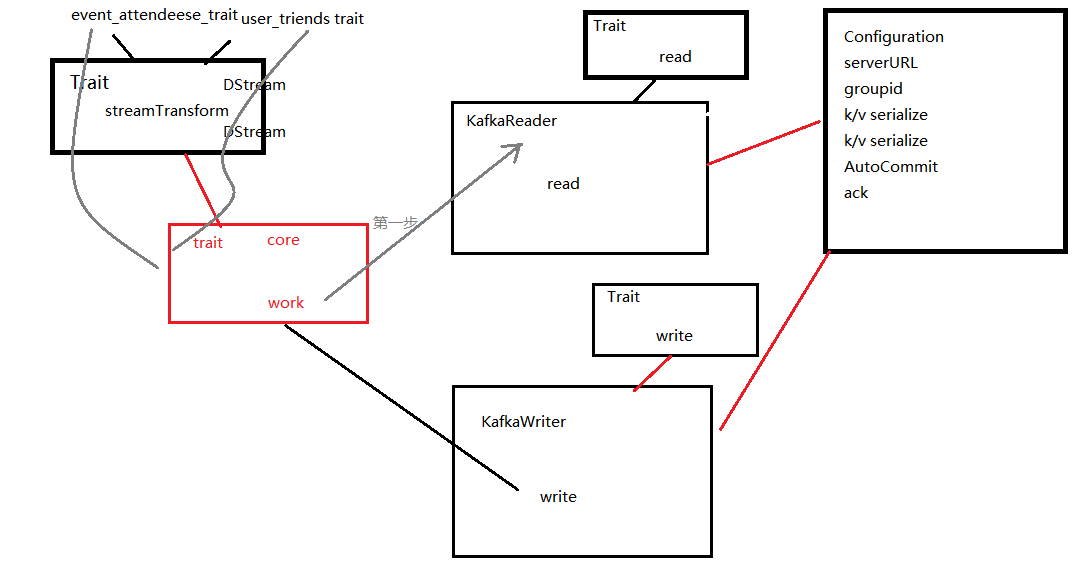
7.1.1、抽象接口读、写、数据处理
trait Read[T] {
def read(prop:Properties,tableName:String):DataStream[T]
}
trait Write[T] {
def write(localhost:String,tableName:String,dataStream:DataStream[T]):Unit
}
trait Transform[T,V] {
def transform(in:DataStream[T]):DataStream[V]
}
7.1.2、开发人员实现数据源添加和写入某数据平台
class KafkaSink[T] extends Write[String] {
override def write(localhost: String, tableName: String, dataStream: scala.DataStream[String]): Unit = {
dataStream.addSink(new FlinkKafkaProducer[String](
localhost,
tableName,
new SimpleStringSchema()
)
)
}
}
object KafkaSink{
def apply[T](): KafkaSink[T] = new KafkaSink()
}
class KafkaSource(env:StreamExecutionEnvironment) extends Read[String]{
override def read(prop: Properties,tableName:String): DataStream[String] = {
env.addSource(
new FlinkKafkaConsumer[String](
tableName,
new SimpleStringSchema(),
prop
)
)
}
}
object KafkaSource{
def apply(env: StreamExecutionEnvironment): KafkaSource = new KafkaSource(env)
}
7.1.3、用户方针对不同数据实现的特质
trait FlinkTransform extends Transform[String,String] {
override def transform(in: DataStream[String]): DataStream[String] = {
in.map(x => {
val info = x.split(",", -1)
Array(
(info(0), info(1).split(" "), "yes"),
(info(0), info(2).split(" "), "maybe"),
(info(0), info(3).split(" "), "invited"),
(info(0), info(4).split(" "), "no")
)
}).flatMap(x => x).flatMap(x => x._2.map(y => (x._1, y, x._3))).filter(_._2!="")
.map(_.productIterator.mkString(","))
}
}
7.1.4、执行器,混入特质
class KTKExcutor(readConf:Properties,writelocalhost:String) {
tran:FlinkTransform=>
def worker(intopic:String,outputtopic:String)={
val env = StreamExecutionEnvironment.getExecutionEnvironment
val kr = new KafkaSource(env).read(readConf, intopic)
val ds = tran.transform(kr)
KafkaSink().write(writelocalhost,outputtopic,ds)
env.execute()
}
}
7.1.5、动态混入用户的方法,执行
object EAtest {
def main(args: Array[String]): Unit = {
val prop = new Properties()
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092")
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"xym")
prop.setProperty(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,"1000")
prop.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
prop.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
prop.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest")
val localhost="single:9092"
(new KTKExcutor(prop,localhost) with FlinkTransform)
.worker("event_attendees_raw","event_attendees_kk")
}
}
8、读取Kafka通过HBase的JavaAPI写入到HBase中
8.1、先把消费者组的游标重置,防止该消费者组消费过数据无法再消费(执行操作前做就可以)
# 消费者组的游标重置
kafka-consumer-groups.sh --bootstrap-server single:9092 --group xym2 --reset-offsets --all-topics --to-earliest --execute
8.2、创建HBase表
hbase(main):001:0> create_namespace 'intes'
hbase(main):001:0> create 'intes:event_attendees_hb','base'
hbase(main):001:0> create 'intes:users_hb','base'
hbase(main):001:0> create 'intes:train_hb','base'
hbase(main):001:0> create 'intes:user_friends_hb','base'
hbase(main):001:0> create 'intes:events_hb','base','other'
8.3、模板模式批量消费kafka插入hbase
- java连接hbase,首先要在hosts里建立主机映射,可以加快连接速度
- 本次工作的核心为:用户从Kafka里读数据,然后把数据写进Hbase,因此核心为读和写,所以抽象出来的核心为读和写,而读kafka和写HBase则分别作为实现类
8.3.1、接口层读和写
public interface Read {
void readKafka(Properties prop,String topic);
}
public interface Write {
//不同的表写不同的save方法
void saveDataToHBase(ConsumerRecords<String,String> records);
}
8.3.2、工具类:读写之前,需要分别创建消费者对象和hbase的连接connection,创建连接需要配置。
public class KafkaUtils {
//kafka读:获取一个消费者
public static KafkaConsumer<String,String> createConsumer(Properties prop){
return new KafkaConsumer<String, String>(prop);
}
}
//配置类
public class HBaseConf {
public static Configuration getConf(){
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","single:2181");
return conf;
}
}
public class HBaseUtils {
public static Connection getConnection(Configuration conf) throws IOException {
//使用连接池,每个线程创建一个连接,这个连接用完之后不关闭,因此要把connection建在外边
ExecutorService es = Executors.newFixedThreadPool(8);
//池子里放了8个创建好的connection,谁要用谁就从中拿,而不需要额外创建或等待
Connection connection = ConnectionFactory.createConnection(conf, es);
return connection;
}
}
8.3.3、读kafka的实现类
public class KafkaReadImpl implements Read {
private Write write;
public KafkaReadImpl(Write write){
this.write = write;
}
@Override
public void readKafka(Properties prop,String topic) {
KafkaConsumer<String, String> consumer = KafkaUtils.createConsumer(prop);
consumer.subscribe(Arrays.asList(topic));
//每100ms来一批数据,创建一个connection,一共可以创建10个
while (true){
ConsumerRecords<String, String> res = consumer.poll(Duration.ofMillis(100));
//这100ms的批次读完之后,直接就先写入到table中
write.saveDataToHBase(res);
}
}
}
8.3.4、写HBase的实现类
表intes:event_attendees_hb
public class Event_Attendees_Impl implements Write {
Connection connection =null;
public Event_Attendees_Impl(Connection connection) {
this.connection = connection;
}
@Override
public void saveDataToHBase(ConsumerRecords<String, String> records) {
try {
Table table = connection.getTable(TableName.valueOf("intes:event_attendees_hb"));
List<Put> puts = new ArrayList<>();
for (ConsumerRecord<String,String> line:records){
//准备批量向hbase中添加数据
String[] info = line.value().split(",",-1);
Put put = new Put((info[0]+info[1]+info[2]).getBytes());
put.addColumn("base".getBytes(),"eventid".getBytes(),info[0].getBytes());
put.addColumn("base".getBytes(),"userid".getBytes(),info[1].getBytes());
put.addColumn("base".getBytes(),"actions".getBytes(),info[2].getBytes());
puts.add(put);
table.close();
}
table.put(puts);
} catch (IOException e) {
e.printStackTrace();
}
}
}
表intes:events_hb
public class Events_Impl implements Write {
private Connection connection;
public Events_Impl(Connection connection) {
this.connection = connection;
}
@Override
public void saveDataToHBase(ConsumerRecords<String, String> records) {
try {
Table table = connection.getTable(TableName.valueOf("intes:events_hb"));
List<Put> puts = new ArrayList<>();
for (ConsumerRecord<String,String> line:records){
//准备批量向hbase中添加数据,使用正则提取每列数据,把后面的特征列算作一个列,需要的的时候再提取,要不然数据太多
Pattern pattern = Pattern.compile("(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*)");
Matcher matcher = pattern.matcher(line.value());
matcher.find();
Put put = new Put((matcher.group(1)).getBytes());//作为rowkey
put.addColumn("base".getBytes(),"eventid".getBytes(),matcher.group(1).getBytes());
put.addColumn("base".getBytes(),"userid".getBytes(),matcher.group(2).getBytes());
put.addColumn("base".getBytes(),"starttime".getBytes(),matcher.group(3).getBytes());
put.addColumn("base".getBytes(),"city".getBytes(),matcher.group(4).getBytes());
put.addColumn("base".getBytes(),"state".getBytes(),matcher.group(5).getBytes());
put.addColumn("base".getBytes(),"zip".getBytes(),matcher.group(6).getBytes());
put.addColumn("base".getBytes(),"country".getBytes(),matcher.group(7).getBytes());
put.addColumn("base".getBytes(),"lat".getBytes(),matcher.group(8).getBytes());
put.addColumn("base".getBytes(),"lng".getBytes(),matcher.group(9).getBytes());
put.addColumn("other".getBytes(),"features".getBytes(),matcher.group(10).getBytes());
puts.add(put);
}
table.put(puts);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* event_id,user_id,start_time,city,state,zip,country,lat,lng,
* c_1,c_2,......
*/
}
表intes:train_hb:
public class Train_Impl implements Write {
//user,event,invited,timestamp,interested,not_interested
private Connection connection;
public Train_Impl(Connection connection) {
this.connection = connection;
}
@Override
public void saveDataToHBase(ConsumerRecords<String, String> records) {
try {
Table table = connection.getTable(TableName.valueOf("intes:train_hb"));
List<Put> puts = new ArrayList<>();
for (ConsumerRecord<String,String> line:records){
//准备批量向hbase中添加数据
String[] info = line.value().split(",",-1);
Put put = new Put((info[0]+info[1]).getBytes());
put.addColumn("base".getBytes(),"userid".getBytes(),info[0].getBytes());
put.addColumn("base".getBytes(),"event".getBytes(),info[1].getBytes());
put.addColumn("base".getBytes(),"invited".getBytes(),info[2].getBytes());
put.addColumn("base".getBytes(),"timestamp".getBytes(),info[3].getBytes());
put.addColumn("base".getBytes(),"interested".getBytes(),info[4].getBytes());
put.addColumn("base".getBytes(),"not_interested".getBytes(),info[5].getBytes());
puts.add(put);
}
table.put(puts);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
表intes:user_friends_hb:
public class User_Friends_Impl implements Write {
//userid,friendid
private Connection connection;
public User_Friends_Impl(Connection connection) {
this.connection = connection;
}
@Override
public void saveDataToHBase(ConsumerRecords<String, String> records) {
try {
Table table = connection.getTable(TableName.valueOf("intes:user_friends_hb"));
List<Put> puts = new ArrayList<>();
for (ConsumerRecord<String,String> line:records){
//准备批量向hbase中添加数据
String[] info = line.value().split(",",-1);
Put put = new Put((info[0]+info[1]).getBytes());
put.addColumn("base".getBytes(),"userid".getBytes(),info[0].getBytes());
put.addColumn("base".getBytes(),"friendid".getBytes(),info[1].getBytes());
puts.add(put);
}
table.put(puts);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
表intes:users_hb:
public class Users_Impl implements Write {
//user_id,locale,birthyear,gender,joinedAt,location,timezone
private Connection connection;
public Users_Impl(Connection connection) {
this.connection = connection;
}
@Override
public void saveDataToHBase(ConsumerRecords<String, String> records) {
try {
Table table = connection.getTable(TableName.valueOf("intes:users_hb"));
List<Put> puts = new ArrayList<>();
for (ConsumerRecord<String,String> line:records){
//准备批量向hbase中添加数据
String[] info = line.value().split(",",-1);
Put put = new Put((info[0]).getBytes());
put.addColumn("base".getBytes(),"userid".getBytes(),info[0].getBytes());
put.addColumn("base".getBytes(),"locale".getBytes(),info[1].getBytes());
put.addColumn("base".getBytes(),"birthyear".getBytes(),info[2].getBytes());
put.addColumn("base".getBytes(),"gender".getBytes(),info[3].getBytes());
put.addColumn("base".getBytes(),"joinedAt".getBytes(),info[4].getBytes());
put.addColumn("base".getBytes(),"location".getBytes(),info[5].getBytes());
put.addColumn("base".getBytes(),"timezone".getBytes(),info[6].getBytes());
puts.add(put);
}
table.put(puts);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
8.3.5、简单工厂模式创建连接执行器
public class NormalFactory {
public static void run(String topic) throws Exception {
Connection connection = HBaseUtils.getConnection(HBaseConf.getConf());
Write write = null;
switch (topic){
case "event_attendees_ff":write=new Event_Attendees_Impl(connection);break;
case "events_raw":write=new Events_Impl(connection);break;
case "users_raw":write=new Users_Impl(connection);break;
case "train_raw":write=new Train_Impl(connection);break;
case "user_friends_ff":write=new User_Friends_Impl(connection);break;
default:throw new Exception("Not found topic!!!不要瞎写");
}
Read read = new KafkaReadImpl(write);
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092");
prop.put(ConsumerConfig.GROUP_ID_CONFIG,"xym2");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getTypeName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getTypeName());
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
read.readKafka(prop,topic);
}
}
//exe
public class App {
public static void main(String[] args) throws Exception {
// NormalFactory.run("event_attendees_ff");
// NormalFactory.run("user_friends_ff");
// NormalFactory.run("events_raw");
// NormalFactory.run("users_raw");
NormalFactory.run("train_raw");
}
}
8.3.5、检验
全部执行完之后,通过hbase计数的命令(count方法只适用于百万行的数据),和kafka里的消息条数核对,看是否正确
# 进入hbase的bin目录 计数:
cd /opt/software/hbase/bin
./hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'intes:event_attendees_hb'
./hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'intes:users_hb'
./hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'intes:train_hb'
./hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'intes:user_friends_hb'
./hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'intes:events_hb'
# 得到结果如下:该数据和kafka里的行数相匹配,只有event_attendees_hb表因为hbase自动去重掉两条,结果全部正确
intes:event_attendees_hb:ROWS=11245008
intes:users_hb:ROWS=38209
intes:train_hb:ROWS=15220
intes:user_friends_hb:ROWS=30386387
intes:events_hb:ROWS=3137972
9、建立Hive映射HBase的表,构建数仓的ODS层
这个没啥好说的,建立表映射就好了
drop database if exists ods_intes cascade;
create database ods_intes;
use ods_intes;
create external table ods_intes.ods_users(
usid string,
userid string,
locale string,
birthyear string,
gender string,
joinedAt string,
location string,
timezone string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,base:userid,base:locale,base:birthyear,base:gender,base:joinedAt,base:location,base:timezone") tblproperties("hbase.table.name"="intes:users_hb");
create external table ods_intes.ods_user_friends(
ufid string,
userid string,
friendid string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,base:userid,base:friendid") tblproperties("hbase.table.name"="intes:user_friends_hb");
create external table ods_intes.ods_train(
trid string,
userid string,
event string,
invited string,
timestamp string,
interested string,
not_interested string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,base:userid,base:event,base:invited,base:timestamp,base:interested,base:not_interested") tblproperties("hbase.table.name"="intes:train_hb");
create external table ods_intes.ods_events(
evid string,
eventid string,
userid string,
starttime string,
city string,
state string,
zip string,
country string,
lat string,
lng string,
features string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,base:eventid,base:userid,base:starttime,base:city,base:state,base:zip,base:country,base:lat,base:lng,other:features") tblproperties("hbase.table.name"="intes:events_hb");
create external table ods_intes.ods_event_attendees(
eaid string,
eventid string,
userid string,
actions string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,base:eventid,base:userid,base:actions") tblproperties("hbase.table.name"="intes:event_attendees_hb");
查询行数是否与HBase相同,本例得到结果是一致的,就不贴图了
select count(*) from ods_intes.ods_users;
select count(*) from ods_intes.ods_user_friends;
select count(*) from ods_intes.ods_train;
select count(*) from ods_intes.ods_events;
select count(*) from ods_intes.ods_event_attendees;
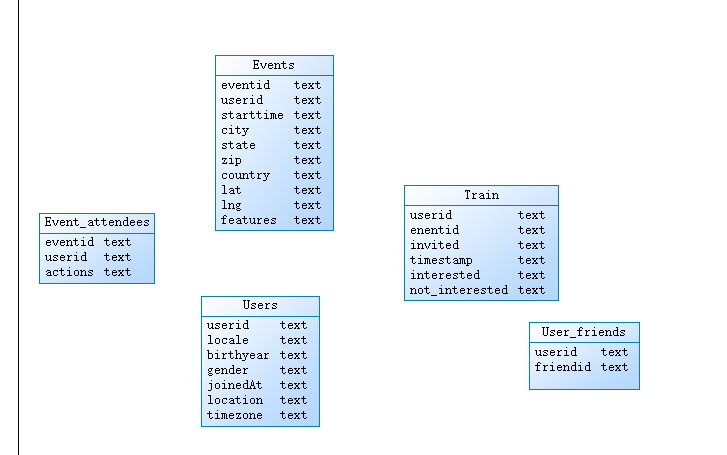
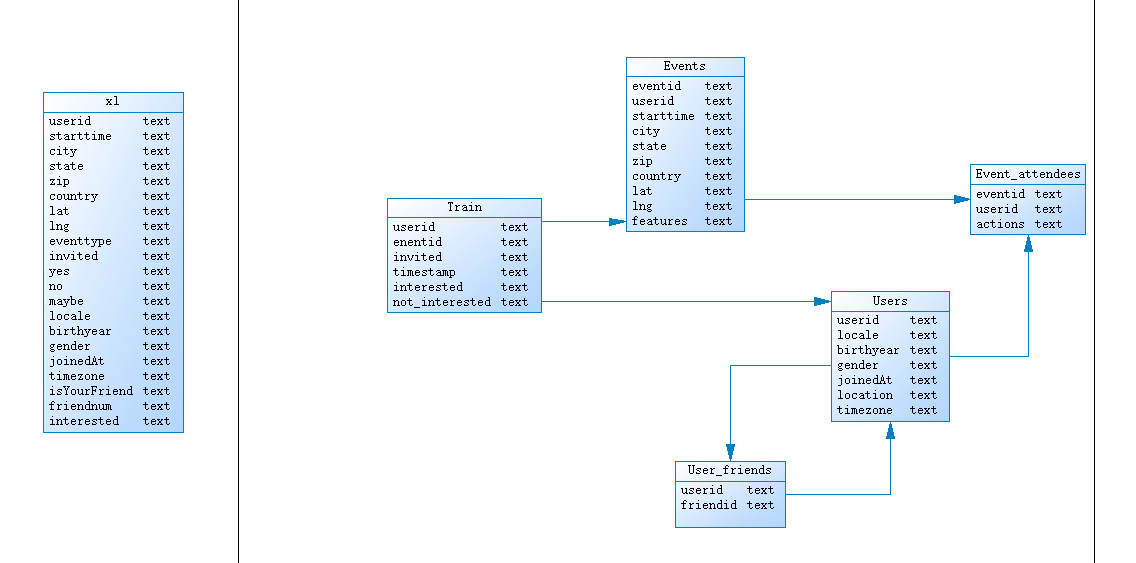
10、使用powerdesigner设计模型
11、构建DWD层数据:清洗异常值
创建dwd、dws层数据库
create database dwd_intes;
create database dws_intes;
11.1、创建dwd_users表,并插入数据
处理思路:
- 对于空值,替换为平均值:使用crossjoin添加新列然后if判断更新空值
- 对于空值,替换为新的默认值:使用自定义函数(宏函数)替换
- 怎么替换?使用rlike正则匹配判断是否要替换,使用regexp_replace替换
create table dwd_intes.dwd_users(
userid string,
locale string,
birthyear string,
gender string,
joinedat string,
location string,
timezone string
)
row format delimited fields terminated by ','
stored as orc;
create temporary macro cal_sex(g string) if(g rlike 'male|female',g,'unknown');
create temporary macro cal_joinedat(g string) if(g rlike '[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}\.[0-9]{3}Z',trim(regexp_replace(g,'T|\.[0-9]{3}Z',' ')),'1989-01-01 12:00:00');
insert overwrite table dwd_intes.dwd_users
select uu.userid,uu.locale,if(uu.birthyear rlike '19[5-9][0-9]|20[0-1][0-9]|2020',uu.birthyear,uu.avg_age) birthyear,cal_sex(uu.gender) gender,cal_joinedat(uu.joinedat) joinedat,uu.location,uu.timezone
from(
select * from ods_intes.ods_users u
cross join (
select floor(avg(birthyear)) avg_age
from ods_intes.ods_users
where birthyear rlike '19[5-9][0-9]|20[0-1][0-9]|2020'
)g
)uu;
11.2、清洗user_friends表
create table dwd_intes.dwd_user_friends(
userid string,
friendid string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_user_friends
select userid,friendid from ods_intes.ods_user_friends;
11.3、清洗train训练集表
create table dwd_intes.dwd_train(
userid string,
eventid string,
invited string,
times string,
label string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_train
select userid,event eventid,invited,timestamp times,interested label
from ods_intes.ods_train;
11.4、清洗events表
- 把其中的starttime格式调一下,去掉分隔符和后面的毫秒
create external table dwd_intes.dwd_events(
eventid string,
userid string,
starttime string,
city string,
state string,
zip string,
country string,
lat string,
lng string,
features string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_events
select eventid,userid,cal_joinedat(starttime) starttime,city,state,zip,country,lat,lng,features
from ods_intes.ods_events;
11.5、清洗event_attendees表
???和user_friends表为啥要在kafka里处理而不是在dws层处理?
create table dwd_intes.dwd_event_attendees(
eventid string,
userid string,
actions string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_event_attendees
select eventid,userid,actions
from ods_intes.ods_event_attendees;
11.6、汇总DWD层脚本
create table dwd_intes.dwd_users(
userid string,
locale string,
birthyear string,
gender string,
joinedat string,
location string,
timezone string
)
row format delimited fields terminated by ','
stored as orc;
create temporary macro cal_sex(g string) if(g rlike 'male|female',g,'unknown');
create temporary macro cal_joinedat(g string) if(g rlike '[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}\.[0-9]{3}Z',trim(regexp_replace(g,'T|\.[0-9]{3}Z',' ')),'1989-01-01 12:00:00');
insert overwrite table dwd_intes.dwd_users
select uu.userid,uu.locale,if(uu.birthyear rlike '19[5-9][0-9]|20[0-1][0-9]|2020',uu.birthyear,uu.avg_age) birthyear,cal_sex(uu.gender) gender,cal_joinedat(uu.joinedat) joinedat,uu.location,uu.timezone
from(
select * from ods_intes.ods_users u
cross join (
select floor(avg(birthyear)) avg_age
from ods_intes.ods_users
where birthyear rlike '19[5-9][0-9]|20[0-1][0-9]|2020'
)g
)uu;
create table dwd_intes.dwd_user_friends(
userid string,
friendid string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_user_friends
select userid,friendid from ods_intes.ods_user_friends;
create table dwd_intes.dwd_train(
userid string,
eventid string,
invited string,
times string,
label string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_train
select userid,event eventid,invited,timestamp times,interested label
from ods_intes.ods_train;
create external table dwd_intes.dwd_events(
eventid string,
userid string,
starttime string,
city string,
state string,
zip string,
country string,
lat string,
lng string,
features string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_events
select eventid,userid,cal_joinedat(starttime) starttime,city,state,zip,country,lat,lng,features
from ods_intes.ods_events;
create table dwd_intes.dwd_event_attendees(
eventid string,
userid string,
actions string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dwd_intes.dwd_event_attendees
select eventid,userid,actions
from ods_intes.ods_event_attendees;
12、构建DWS层数据:轻度聚合
create database dws_intes;
本层数据主要为轻聚合:
- 把维度数据聚合到事实表中
- 把维度数据做归一化处理
12.0、准备工作
- 导入语言对照表:locale.txt
- 创建时区临时表:id+时区
- 年龄数据进行归一化处理:使用自定义宏函数
hdfs dfs -mkdir -p /events/data/locale
hdfs dfs -mv /events/data/locale.txt /events/data/locale
-- 创建语言对照表
create table dws_intes.dws_locale (
localeid string,
localename string
)
row format delimited fields terminated by '\t'
location '/events/data/locale'
-- 导入时区表
create table dws_intes.dws_timezonetab(
timezone string,
id string
)
row format delimited fields terminated by ','
stored as orc;
insert overwrite table dws_intes.dws_timezonetab
select timezone,row_number() over() id
from (
select timezone
from dwd_intes.dwd_users
group by timezone
)T
-- 计算年龄段占比,就是每个年龄在总年龄段中的占比,比如说最小1,最大10,那么8的位置就是70%
create remporary macro cal_age_prec(cage int,maxage int,minage int)
(cage-minage)/(maxage-minage)
-- 创建一个宏,把日期调整为yyyymmdd的格式
create temporary macro cal_memberday(tm string)
datediff(date_format(current_date(),'yyyy-MM-dd'),date_formate(tm,'yyyy-MM-dd'))
12.1、聚合训练数据集和用户信息表=>用户训练集表
-- 聚合训练数据集和用户信息表=>用户训练集表
create table dws_intes.dws_user_train as
select
t.userid,t.eventid,t.invited,t.times,t.label,
coalesce(l.localeid,0) locale,
cal_age_prec(u.birthyear,u.maxage,u.minage) age,
case when u.gender='male' then 1 when u.gender='female' then 0 else -1 end gender,
cal_memberday(u.joinedat) member_day,
tz.id timezone
from dwd_intes.dwd_train t
inner join (
select *
from dwd_intes.dwd_users
cross join (
select max(birthyear) maxage,min(birthyear) minage
from dwd_intes.dwd_users
)b
) u on t.userid=u.userid
left join dws_intes.dws_locale l on u.locale=l.localename
inner join dws_intes.dws_timezonetab tz on u.timezone=tz.timezone
12.2、聚会意向反馈信息表=>聚会信息统计表行转列
对某人是否拒绝、收到邀请、统一、可能情况的统计
create table dws_intes.dws_user_count as
select userid,
max(case when actions='yes' then num else 0 end) attended_count,
max(case when actions='invited' then num else 0 end) invited_event_count,
max(case when actions='maybe' then num else 0 end) maybe_attended_count,
max(case when actions='no' then num else 0 end) no_attended_count
from (
select userid,actions,count(*) num
from dwd_intes.dwd_event_attendees
group by userid,actions
)T
group by userid
12.3、对会议是否拒绝、收到邀请、统一、可能情况的统计
create table dws_intes.dws_event_count as
select eventid,
max(case when actions='yes' then num else 0 end) event_attended_count,
max(case when actions='invited' then num else 0 end) event_invited_count,
max(case when actions='maybe' then num else 0 end) event_maybe_count,
max(case when actions='no' then num else 0 end) event_not_att_count
from (
select eventid,actions,count(userid) num
from dwd_intes.dwd_event_attendees
group by eventid,actions
)T
group by eventid
12.4、聚合训练集、聚会表、聚会反馈表、用户朋友表=>聚会信息表
create table dws_intes.dws_user_train_1 as
select t.eventid,t.userid,
datediff(date_format(e.starttime,'yyyy-MM-dd'),substr(t.times,0,10)) invite_days,
coalesce(event_count,0) event_count,
coalesce(uf.friend_count,0) friend_count,
coalesce(uc.attended_count,0) attended_count,
coalesce(uc.invited_event_count,0) invited_event_count,
coalesce(uc.maybe_attended_count,0) maybe_attended_count,
coalesce(uc.no_attended_count,0) not_attended_count,
coalesce(t.invited,0) user_invited
from dwd_intes.dwd_train t
inner join dwd_intes.dwd_events e on t.eventid=e.eventid
left join (
select userid,count(eventid) event_count
from dwd_intes.dwd_train
group by userid
)c on t.userid=c.userid
left join (
select userid,count(friendid) friend_count
from dwd_intes.dwd_user_friends
group by userid
)uf on t.userid=uf.userid
left join dws_intes.dws_user_count uc
on t.userid=uc.userid
12.5、聚会与训练集信息聚合=>聚会概况gk统计表
-- 城市等级的表
select city,
row_number() over(order by city_event_count) rank
from (
select city,count(eventid) city_event_count
from dwd_intes.dwd_events
group by city
)a
-- 国家等级
select country,row_number() over(order by country_event_count desc) crank
from (
select country,count(eventid) country_event_count
from dwd_intes.dwd_events
group by country
)b
计算经纬度占比的宏
create temporary macro cal_latlng_prec(currll string,maxll string,minll string)
if(currll is null,0,(currll-minll))/(maxll-minll)
判断用户与聚会是否在同地(如果用户地址在会议的城市、省份、国家)
create temporary macro cal_similar(location string,city string,states string,country string)
if(instr(location,city)>0 or instr(location,states)>0 or instr(location,country)>0,1,0)
-- -- 3、聚会与训练集信息聚合=>聚会概况gk统计表
create table dws_intes.dws_event_gk as
select t.eventid,t.userid,month(substr(times,0,10)) event_month,
dayofweek(substr(times,0,10)) event_dayofweek,
hour(substr(times,0,19)) event_hour,
coalesce(ec.event_attended_count,0) event_attended_count,
coalesce(ec.event_invited_count,0) event_invited_count,
coalesce(ec.event_maybe_count,0) event_maybe_count,
coalesce(ec.event_not_att_count,0) event_not_att_count,
f.rank city_level,
k.crank country_level,
cal_latlng_prec(de.lat,g.max_lat,g.min_lat) lat_prec,
cal_latlng_prec(de.lng,g.max_lng,g.min_lng) lng_prec,
cal_similar(u.location,de.city,de.state,de.country) location_similar
from dwd_intes.dwd_train t
left join dws_intes.dws_event_count ec on t.eventid=ec.eventid
inner join dwd_intes.dwd_events de on t.eventid=de.eventid
inner join(
select city,
row_number() over(order by city_event_count desc) rank
from (
select city,count(eventid) city_event_count
from dwd_intes.dwd_events
group by city
)a
)f on f.city=de.city
inner join(
select country,
row_number() over(order by country_event_count desc) crank
from (
select country,count(eventid) country_event_count
from dwd_intes.dwd_events
group by country
)b
)k on k.country=de.country
cross join(
select max(cast(lat as double)) max_lat,min(cast(lat as double)) min_lat,max(cast(lng as double)) max_lng,min(cast(lng as double)) min_lng
from dwd_intes.dwd_events
)g
inner join dwd_intes.dwd_users u on t.userid=u.userid
12.6、聚会用户朋友信息统计
12.6.1、聚会用户有朋友信息统计有朋友信息的人
create table dws_intes.dws_event_friend_count as
select k.eventid,k.userid,
max(case k.actions when 'invited' then k.friend_num else 0 end) uf_invited_count,
max(case k.actions when 'yes' then k.friend_num else 0 end) uf_attended_count,
max(case k.actions when 'no' then k.friend_num else 0 end) uf_not_attended_count,
max(case k.actions when 'maybe' then k.friend_num else 0 end) uf_maybe_count
from (
select g.eventid,g.userid,g.actions,count(g.friendid) friend_num
from(
select t.eventid,t.userid,uf.friendid,da.actions
from dwd_intes.dwd_train t
inner join dwd_intes.dwd_user_friends uf on t.userid=uf.userid
inner join dwd_intes.dwd_event_attendees da on t.eventid=da.eventid and uf.friendid=da.userid
)g
group by g.eventid,g.userid,g.actions
)k
group by k.eventid,k.userid
12.6.2、聚会用户有朋友信息统计加没有朋友信息的人
create table dws_intes.dws_event_allfriend_count as
select * from(
select * from dws_intes.dws_event_friend_count
union all
select t.eventid,t.userid,
0 uf_invited_count,
0 uf_attended_count,
0 uf_not_attended_count,
0 uf_maybe_count
from dwd_intes.dwd_train t
where not exists(
select 1
from dws_intes.dws_event_friend_count fc
where t.userid=fc.userid and t.eventid=fc.eventid
)
)c
12.7、判断用户是不是聚会主持人的朋友
create table dws_intes.dws_is_friends as
select eventid,userid,max(creator_is_friend) creator_is_friend
from(
select distinct t.eventid,t.userid,if(e.userid is null,0,1) creator_is_friend
from dwd_intes.dwd_train t
left join dwd_intes.dwd_user_friends uf on t.userid=uf.userid
left join dwd_intes.dwd_events e on t.eventid=e.eventid and uf.friendid=e.userid
)a
group by eventid,userid
13、初步构建DM层宽表,不过还缺聚会特征那列,后面加上
- 创建宏函数:生成用户朋友是否愿意参加活动的占比
create temporary macro cal_friend_back_prec(cval string,fall string)
cast(cval as double)/cast(fall as double)
13.1、宽表
create table dm_intes.dm_user_interest as
select
t1.label,
t1.userid,
t1.eventid,
t1.locale,
t1.gender,
t1.age,
t1.timezone,
t1.member_day,
t2.invite_days,
t2.event_count,
t2.friend_count,
t2.invited_event_count,
t2.attended_count,
t2.not_attended_count,
t2.maybe_attended_count,
t2.user_invited,
ac.uf_invited_count,
ac.uf_attended_count,
ac.uf_not_attended_count,
ac.uf_maybe_count,
cal_friend_back_prec(ac.uf_invited_count,t2.friend_count) uf_invited_prec,
cal_friend_back_prec(ac.uf_attended_count,t2.friend_count) uf_attended_prec,
cal_friend_back_prec(ac.uf_not_attended_count,t2.friend_count) uf_not_attended_prec,
cal_friend_back_prec(ac.uf_maybe_count,t2.friend_count) uf_maybe_prec,
df.creator_is_friend,
gk.event_month,gk.event_dayofweek,gk.event_hour,gk.event_invited_count,gk.event_attended_count,gk.event_not_att_count,gk.event_maybe_count,gk.city_level,gk.country_level,gk.lat_prec,gk.lng_prec,gk.location_similar
from dws_intes.dws_user_train t1
inner join dws_intes.dws_user_train_1 t2 on t1.eventid=t2.eventid and t1.userid=t2.userid
inner join dws_intes.dws_event_gk gk on t2.eventid=gk.eventid and t2.userid=gk.userid
inner join dws_intes.dws_event_allfriend_count ac on gk.eventid=ac.eventid and gk.userid=ac.userid
inner join dws_intes.dws_is_friends df on df.eventid=ac.eventid and df.userid=ac.userid
14、使用python用Kmeans算法对events表的特征列进行分类
14.1、判断聚类质心点数量的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.ml.clustering import KMeans
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import Row, DoubleType
from pyspark.sql.functions import col
from pyspark.ml.feature import VectorAssembler
import matplotlib.pyplot as plt
if __name__ == '__main__':
spark = SparkSession.builder.master("local[2]")\
.config("spark.executor.memory","4g")\
.config("spark.debug.maxToStringFields","120")\
.appName("mymodel").getOrCreate()
df = spark.read.format("csv").option("header","true").load("hdfs://single:9000/events/data/events.csv")
# 保留所有的特征列,其他列删掉,并转为double类型 [col(c).cast(DoubleType()) for c in df.columns if c.startswith("c_")]
"""
单列:
cols = [c for c in df.columns if c.startswith("c_")]
df.select(col("event_id").cast('double')).show(10)
批量:
cols = [col(c).cast(DoubleType()) for c in df.columns if c.startswith("c_")]
df.select([col(c).cast('double') for c in cols])
"""
# df.columns拿出所有"c_"开头的列,得到一个数组
cols = [c for c in df.columns if c.startswith("c_")]
# 把上面的数组复制出来
feas = cols.copy()
# 在第一列的位置插入event_id列
cols.insert(0,"event_id")
# 使用列表生成式循环把每一列转为double类型
df1=df.select([col(c).cast('double') for c in cols])
# VectorAssembler是将给定列列表组合成单个向量列的转换器
va = VectorAssembler().setInputCols(feas).setOutputCol("features")
res = va.transform(df1).select("event_id","features")
model = KMeans().setK(35).setFeaturesCol("features").setPredictionCol("predict").fit(res)
"""测试不同质心数量对分类的效果拐点,找出适合的质心数量,过多太慢,过少分类不够细
# 准备一个距离数组
dists=[]
# 准备个点的数组,为什么用50个点,因为一共313W行,开根号再开根号得到42,按50来,寻找拐点,如果没到拐点就增加点的数量,乘以2,再多就吃不消了
points = range(2,51)
# 循环质心点的数量,根据距离远近判断每个数量的质心点的模型平均距离
for po in points:
# 创建模型,设置特征列,设置预测列,然后训练
model = KMeans().setK(po).setFeaturesCol("features").setPredictionCol("predict").fit(res)
# computeCost这个方法通过计算数据集中所有的点到最近中心点的平方和来衡量聚类的效果。一般来说,同样的迭代次数,这个cost值越小,说明聚类的效果越好
dists.append(model.computeCost(res))
# 使用matplotlib绘制线形图
plt.plot(points,dists)
plt.show()
"""
# 根据上面的模型选取合适的质心数,本例选35个。写到hdfs上
"""linux环境下:
pip3 install findspark
pip3 install numpy
pip3 install matplotlib
配置spark环境变量
python3 /opt/
"""
r = model.transform(res).select(col("event_id").alias("eventid"),col("predict").alias("eventtype"))
r.coalesce(1).write.option("sep",",").option("header","true").csv("hdfs://single:9000/events/eventtype",mode="overwrite")
# # transform就是predict
# val = model.transform(res)
# val.show(10)
# # res.show(10,False)
spark.stop()
14.2、根据上述步骤确定了质心的数量,然后进行聚类,写入到hdfs上
本例主要做的是,把聚会按照特征进行分类,然后把分类值作为dm层宽表上的一个特征
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.ml.clustering import KMeans
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import Row, DoubleType
from pyspark.sql.functions import col
from pyspark.ml.feature import VectorAssembler
import matplotlib.pyplot as plt
if __name__ == '__main__':
spark = SparkSession.builder.master("local[2]")\
.config("spark.executor.memory","4g")\
.config("spark.debug.maxToStringFields","120")\
.appName("mymodel").getOrCreate()
df = spark.read.format("csv").option("header","true").load("hdfs://single:9000/events/data/events.csv")
# 保留所有的特征列,其他列删掉,并转为double类型 [col(c).cast(DoubleType()) for c in df.columns if c.startswith("c_")]
cols = [c for c in df.columns if c.startswith("c_")]
feas = cols.copy()
cols.insert(0,"event_id")
df1=df.select([col(c).cast('double') for c in cols])
# VectorAssembler是将给定列列表组合成单个向量列的转换器
va = VectorAssembler().setInputCols(feas).setOutputCol("features")
res = va.transform(df1).select("event_id","features")
model = KMeans().setK(35).setFeaturesCol("features").setPredictionCol("predict").fit(res)
# 根据上面的模型选取合适的质心数,本例选35个。写到hdfs上
"""linux环境下:
pip3 install findspark
pip3 install numpy
pip3 install matplotlib
配置spark环境变量
python3 /opt/
"""
r = model.transform(res).select(col("event_id").alias("eventid"),col("predict").alias("eventtype"))
r.coalesce(1).write.option("sep",",").option("header","true").csv("hdfs://single:9000/events/eventtype",mode="overwrite")
spark.stop()
14.3、经过Kmeans算法后获取会议分类表
上一步的算法得到的聚会分类特征值导入到hdfs后,建hive映射表在dwd层
create external table dwd_intes.dwd_eventType(
eventid double,
eventgrp string
)
row format delimited fields terminated by ','
location '/events/eventtype'
tblproperties("skip.header.line.count"="1")
15、构建最终的DM层宽表
特征值归一化:创建宏函数,把较大的值归一到0-1之间
create temporary macro alltoone(curr double,maxval double,minval double)(curr-minval)/(maxval - minval)
最终宽表:
create table dm_intes.dm_final_user_interest as
select
label,
userid,
t.eventid,
locale,
gender,
age,
timezone,
alltoone(member_day,a.maxval,a.minval) member_day,
invite_days,
event_count,
alltoone(friend_count,b.maxval,b.minval) friend_count,
invited_event_count,
attended_count,
not_attended_count,
maybe_attended_count,
user_invited,
uf_invited_count,
uf_attended_count,
uf_not_attended_count,
uf_maybe_count,
uf_invited_prec,
uf_attended_prec,
uf_not_attended_prec,
uf_maybe_prec,
creator_is_friend,
event_month,
event_dayofweek,
event_hour,
alltoone(event_invited_count,c.maxval,c.minval) event_invited_count,
event_attended_count,
event_not_att_count,
event_maybe_count,
city_level,
country_level,
lat_prec,
lng_prec,
location_similar,
p.eventgrp
from dm_intes.dm_user_interest t
inner join dwd_intes.dwd_eventType p on t.eventid=p.eventid
cross join (
select max(member_day) maxval,min(member_day) minval
from dm_intes.dm_user_interest
)a
cross join (
select max(friend_count) maxval,min(friend_count) minval
from dm_intes.dm_user_interest
)b
cross join (
select max(event_invited_count) maxval,min(event_invited_count) minval
from dm_intes.dm_user_interest
)c
16、使用随机森林对宽表的特征数据进行分类,得出预测label值的预测分类模型
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.feature import VectorAssembler
from pyspark.sql.functions import *
if __name__ == '__main__':
spark = SparkSession.builder.master("local[4]").appName("uf")\
.config("spark.executor.memory","3g")\
.config("hive.metastore.uris","thirft://single:9083").enableHiveSupport().getOrCreate()
df = spark.sql("select * from dm_intes.dm_final_user_interest")
# 把所有列都转为double类型
cols = [ col(c).cast('double') for c in df.columns ]
# 原始表不动,把表拷贝一份出来,把所有列转为Double型
df1 = df.select(cols)
# 使用数组切片的方式拿出特征列(特征数据集),也就是第三列之后的列,
colname = [col for col in df1.columns[3:]]
# VectorAssembler是将给定列列表组合成单个向量列的转换器
va = VectorAssembler(inputCols=colname,outputCol="features")
# 把特征数据及传入到向量转换器中进行转换,这样后面的所有特征集,就都被转成一个稀疏数组了
res = va.transform(df1).select("label","eventid","userid","features")
# 将res分割为训练数据及和测试数据集,使用randomSplit方法,参数分别为分割比例数组和随机数种子
trainData,testData = res.randomSplit([0.8,0.2],1024)
# 定义一个随机森林模型,传入参数为特征列、结果列、子树数量、深度、随机种子
rf = RandomForestClassifier(featuresCol="features",labelCol="label",numTrees=128,maxDepth=9,seed=5)
# 传入训练集数据进行训练,得到一个训练好的模型
rfmodel = rf.fit(trainData)
# 传入测试集数据到训练好的模型中,得到预测结果
predictionResult = rfmodel.transform(testData)
# 对预测结果和实际结果进行对比,算出准确率
print(predictionResult.filter(predictionResult.label == predictionResult.prediction).count()/predictionResult.count())
# 输出预测结果
predictionResult.show()
spark.stop()
16.2、把训练好的模型保存到hdfs上
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.feature import VectorAssembler
from pyspark.sql.functions import *
from pyspark.ml import Pipeline
if __name__ == '__main__':
spark = SparkSession.builder.master("local[4]").appName("uf")\
.config("spark.executor.memory","3g")\
.config("hive.metastore.uris","thirft://single:9083").enableHiveSupport().getOrCreate()
df = spark.sql("select * from dm_intes.dm_final_user_interest")
# 把所有列都转为double类型
cols = [ col(c).cast('double') for c in df.columns ]
# 原始表不动,把表拷贝一份出来,把所有列转为Double型
df1 = df.select(cols)
# 使用数组切片的方式拿出特征列(特征数据集),也就是第三列之后的列,
colname = [col for col in df1.columns[3:]]
# VectorAssembler是将给定列列表组合成单个向量列的转换器
va = VectorAssembler(inputCols=colname,outputCol="features")
rf = RandomForestClassifier(featuresCol="features",labelCol="label",numTrees=128,maxDepth=9,seed=5)
# Pipeline内部自动调用transform转换
pip = Pipeline(stages=[va,rf])
# 训练出模型
model = pip.fit(df1)
# 写入到hdfs上
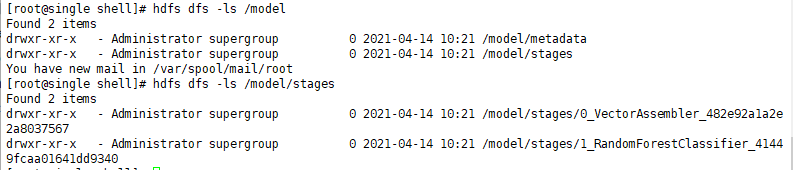
model.write().overwrite().save("hdfs://single:9000/model")
"""加载本地存储的管道训练模型执行数据预测的方法:
m3 = PipelineModel.read().load("d:/model")
print(m3)
testing = spark.createDataFrame([
(0, "aa bb cc dd aa "),
(0, "ss dd aa")
], ["id", "text"])
res3 = m3.transform(testing)
res3.show(truncate=False)
"""
17、通过SparkStreaming从kafka里读取test测试数据
17.1、新建maven工程,把test表(event_attendees表里去掉label标签的格式)和其他表关联起来,找出test对应userid和eventid的各种特征,形成一个宽表
log4j:https://harder.blog.csdn.net/article/details/79518028
思路:
- 创建SparkStreaming窗口,读取数据,在内部foreachRDD里转为DataFrame格式
- 新建数据转换类,方法入口参数为SparkStreaming里输出的DataFrame数据
- 我们要做的是把这个新数据,跟数据仓库里的维度表结合起来,把对应的特征都拼上去形成一张宽表,然后把这张宽表传入到算法模型里,生成预测数据
- 因此我们导入dwd层的数据,把这部分数据根据userid、eventid进行特征提取。和之前的hive数仓建模的步骤基本上一直。最后整合为一张宽表,以csv格式写在hdfs上
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Demo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName)
val ssc = new StreamingContext(conf, Seconds(1))
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "single:9092",
ConsumerConfig.GROUP_ID_CONFIG->"xym",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest"
)
val ds = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Set("test_raw"), kafkaParams)
)
ds.map(record=>record.value())
.window(Seconds(1))//对每个RDD进行处理时,一个RDD会执行一次,多次执行的话
.foreachRDD(line=>DataTransform.trans(line))
ssc.start()
ssc.awaitTermination()
}
}
import java.text.SimpleDateFormat
import java.util.{Calendar, Date}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
object DataTransform {
val spark = SparkSession.builder().master("local[*]").appName("eee")
.config("hive.metastore.uris", "thirft://single:9083")
.enableHiveSupport().getOrCreate()
/**
* ods_event_attendees
* ods_events
* ods_train
* ods_user_friends
* ods_users
* *
* dwd_event_attendees
* dwd_events
* dwd_eventtype
* dwd_train
* dwd_user_friends
* dwd_users
* *
* dws_event_allfriend_count
* dws_event_count
* dws_event_friend_count
* dws_event_gk
* dws_is_friends
* dws_locale
* dws_timezonetab
* dws_user_count
* dws_user_train
* dws_user_train_1
*/
var event_attendees = spark.sql("select * from dwd_intes.dwd_event_attendees").cache()
var events = spark.sql("select * from dwd_intes.dwd_events").cache()
var eventtype = spark.sql("select * from dwd_intes.dwd_eventtype").cache()
var user_friends = spark.sql("select * from dwd_intes.dwd_user_friends").cache()
var users = spark.sql("select * from dwd_intes.dwd_users").cache()
def trans(lines:RDD[String]) = {
//获取预测数据集
val test = rddToDF(lines)
//第一部分组装数据
//test、user表
var part1 = userbase(test)
//第二部分组装数据
var part2 = eventbase(test)
//第三部分组装数据
var part3 = eventext(test)
//第四部分统计用户该次聚会的朋友信息
var part4 = event_user_friend_count(test)
// 将四个部分聚合为最后的宽表
var widthtab = aggtab(test, part1, part2, part3, part4).cache()
widthtab.coalesce(1).write.mode(SaveMode.Overwrite).option("header","true").csv("hdfs://single:9000/prediction")
widthtab.show()
}
import spark.implicits._
def aggtab(test: DataFrame, part1: DataFrame, part2: DataFrame, part3: DataFrame, part4: DataFrame) = {
//计算用户是否是会议主持人的朋友
var is_friend = test.drop("invited", "timestamp") //userid,eventid
.join(user_friends, Seq("userid"), "left") //userid friendid==>userid,eventid,friendid
.join(
events.select("eventid", "userid"),
test("eventid") === events("eventid") and user_friends("friendid") === events("userid"),
"left"
).drop(events("eventid"))
.withColumn("creator_is_friend", when(events("userid").isNull, 0).otherwise(1))
.drop(events("userid")).drop("friendid").groupBy("userid", "eventid")
.agg(max($"creator_is_friend").as("creator_is_friend"))
// .na.fill(0)
//创建朋友占比计算函数
var cal_friend_back_prec = udf((call: Double, fall: Double) => {
call / fall
})
//统计宽表
part1
.join(part2, Seq("userid", "eventid"), "inner")
.join(part3, Seq("userid", "eventid"), "inner")
.join(part4, Seq("userid", "eventid"), "inner")
.join(is_friend, Seq("userid", "eventid"), "inner")
.join(eventtype, Seq("eventid"), "left")
.withColumn("uf_invited_prec", cal_friend_back_prec($"uf_invited_count", $"friend_count"))
.withColumn("uf_attended_prec", cal_friend_back_prec($"uf_invited_count", $"friend_count"))
.withColumn("uf_not_attended_prec", cal_friend_back_prec($"uf_not_attended_count", $"friend_count"))
.withColumn("uf_maybe_prec", cal_friend_back_prec($"uf_maybe_count", $"friend_count"))
.drop("birthyear", "joinedat", "maxage", "minage", "invited", "timestamp", "location").na.fill(0)
.select(
$"userid",
$"eventid",
$"locale",
$"gender",
$"age",
$"timezone",
$"member_day",
$"invite_days",
$"event_count",
$"friend_count",
$"invited_event_count",
$"attended_count",
$"not_attended_count",
$"maybe_attended_count",
$"user_invited",
$"uf_invited_count",
$"uf_attended_count",
$"uf_not_attended_count",
$"uf_maybe_count",
$"uf_invited_prec",
$"uf_attended_prec",
$"uf_not_attended_prec",
$"uf_maybe_prec",
$"creator_is_friend",
$"event_month",
$"event_dayofweek",
$"event_hour",
$"event_invited_count",
$"event_attended_count",
$"event_not_att_count",
$"event_maybe_count",
$"city_level",
$"country_level",
$"lat_prec",
$"lng_prec",
$"location_similar",
$"eventgrp"
)
}
def event_user_friend_count(test: DataFrame) = {
//当前聚会邀请用户的反馈统计
//聚会用户有朋友的信息统计
var event_friend_count = test.drop("invited", "timestamp").join(user_friends, Seq("userid"), "inner")
.join(
event_attendees,
test("eventid")
.equalTo(event_attendees("eventid"))
.and(user_friends("friendid")
.equalTo(event_attendees("userid"))),
"inner"
)
.drop(event_attendees("userid")).drop(event_attendees("eventid"))
.groupBy("eventid", "userid", "actions").agg(count("friendid").as("friend_num"))
.groupBy("eventid", "userid")
.pivot("actions").agg(max($"friend_num"))
// .show()
//查询没有朋友的用户信息,补充对应数据为0
test.drop("invited", "timestamp")
.join(event_friend_count, Seq("eventid", "userid"), "left")
.na.fill(0)
.select(
$"eventid", $"userid",
$"invited".as("uf_invited_count"),
$"maybe".as("uf_maybe_count"),
$"no".as("uf_not_attended_count"),
$"yes".as("uf_attended_count")
)
// .show()
}
def eventext(test: DataFrame) = {
val event_count = event_attendees.groupBy("eventid").pivot("actions")
.agg(count("userid"))
.select(
$"eventid",
$"yes".as("event_attended_count"),
$"invited".as("event_invited_count"),
$"maybe".as("event_maybe_count"),
$"no".as("event_not_att_count")
)
//根据会议的多少计算城市等级
val citywnd = Window.orderBy(desc("city_event_count"))
var city_level = events.groupBy("city").agg(count("eventid").as("city_event_count"))
.select($"city", row_number().over(citywnd).as("city_level"))
//根据会议的多少计算郭嘉等级
val countrywnd = Window.orderBy(desc("country_event_count"))
var country_level = events.groupBy("country").agg(count("eventid").as("country_event_count"))
.select($"country", row_number().over(countrywnd).as("country_level"))
//计算经纬度udf
val cal_latlng = udf((curr: Double, maxll: Double, minll: Double) => {
(curr - minll) / (maxll - minll)
})
//计算用户和聚会是否在同一地区
val cal_similar = udf((location: String, city: String, state: String, country: String) => {
if (location.indexOf(city) >= 0 || location.indexOf(state) >= 0 || location.indexOf(country) >= 0) {
1
} else {
0
}
})
//计算经纬度的最大最小值
val MMlatlng = events.agg(
max($"lat".cast(DoubleType)).as("maxlat"),
min($"lat".cast(DoubleType)).as("minlat"),
max($"lng".cast(DoubleType)).as("maxlng"),
min($"lng".cast(DoubleType)).as("minlng")
).select($"maxlat", $"minlat", $"maxlng", $"minlng")
//组装聚会情况统计信息
test
.join(event_count, Seq("eventid"), "left")
.join(events.drop("userid"), Seq("eventid"), "inner")
.join(city_level, Seq("city"), "inner")
.join(country_level, Seq("country"), "inner")
.crossJoin(MMlatlng)
.join(users.select($"userid", $"location"), Seq("userid"), "inner")
.withColumn("event_month", month(substring($"timestamp", 0, 10)))
.withColumn("event_dayofweek", lit(7) - datediff(
next_day(substring($"timestamp", 0, 10), "Sunday"),
substring($"timestamp", 0, 10))
)
.withColumn("event_hour", hour(substring($"timestamp", 0, 19)))
.withColumn("lat_prec", cal_latlng($"lat", $"maxlat", $"minlat"))
.withColumn("lng_prec", cal_latlng($"lng", $"maxlng", $"minlng"))
.withColumn("location_similar", cal_similar($"location", $"city", $"state", $"country"))
.drop(
"country", "city", "invited", "timestamp", "starttime", "state",
"zip", "lat", "lng", "features", "maxlat", "minlat", "maxlng", "minlng", "location"
)
// .show()
}
/**
* part2:建立会议参与人总数统计
*
* @param test
*/
def eventbase(test: DataFrame) = {
//建立会议参与人总数统计
val event_count = test.groupBy("userid").agg(count("userid").alias("event_count"))
//用户的朋友统计
var user_friend_count = user_friends.groupBy("userid").agg(count("friendid").as("friend_count"))
//方法1:
event_attendees.groupBy($"userid", $"actions").agg(count($"userid").as("people_num"))
.groupBy($"userid")
.agg(
max(when($"actions" === lit("yes"), $"people_num").otherwise(0)).as("attended_count"),
max(when($"actions" === lit("invited"), $"people_num").otherwise(0)).as("invited_event_count"),
max(when($"actions" === lit("maybe"), $"people_num").otherwise(0)).as("maybe_attended_count"),
max(when($"actions" === lit("no"), $"people_num").otherwise(0)).as("not_attended_count")
)
// .show()
val user_action_count = event_attendees.groupBy("userid")
.pivot("actions").agg(count($"userid"))
.select(
$"userid",
$"yes".as("attended_count"),
$"invited".as("invited_event_count"),
$"maybe".as("maybe_attended_count"),
$"no".as("not_attended_count")
)
test.join(events.select($"eventid", $"starttime"), Seq("eventid"), "inner")
.join(event_count, Seq("userid"), "left")
.join(user_friend_count, Seq("userid"), "left")
.join(user_action_count, Seq("userid"), "left")
.withColumn("invite_days", datediff(date_format($"starttime", "yyyy-MM-dd")
, date_format($"timestamp", "yyyy-MM-dd")))
.drop("starttime").na.fill(0)
// .show()
}
/**
* part1:用户表
*
* @param test
*/
def userbase(test: DataFrame) = {
//cal_age_prec
var cal_age_prec = udf((cval: Double, maxVal: Double, minVal: Double) => {
(cval - minVal) / (maxVal - minVal)
})
//性别处理
var cal_sex = udf((str: String) => {
if (str.equals("male")) {
1
} else if (str.equals("female")) {
0
} else {
-1
}
})
//memberday计算
var cal_memberday = udf((time: String) => {
val calendar = Calendar.getInstance()
val sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val joinat = sdf.parse(time).getTime
(calendar.getTimeInMillis - joinat) / (1000 * 60 * 60 * 24)
})
//先算年份的最大值和最小值
test.join(
users.crossJoin(users.agg(
max($"birthyear".cast(DoubleType)).alias("maxage"),
min($"birthyear".cast(DoubleType)).alias("minage")
)),
Seq("userid"),
"inner"
)
.withColumn("age", cal_age_prec($"birthyear".cast(DoubleType), $"maxage", $"minage"))
.withColumn("gender", cal_sex($"gender"))
.withColumn("member_day", cal_memberday($"joinedat"))
.withColumnRenamed("invited", "user_invited")
.drop("birthyear", "joinedat", "maxage", "minage")
// .show()
}
//根据用户传入的RDD转为DataFrame,这里针对的是Test表
def rddToDF(lines: RDD[String]) = {
if (lines != null) {
val schema = StructType(Array(
StructField("userid", StringType, true),
StructField("eventid", StringType, true),
StructField("invited", StringType, true),
StructField("timestamp", StringType, true)
))
val rdd = lines.map(line => {
val datas = line.split(",", -1)
Row(datas(0), datas(1), datas(2), datas(3))
})
spark.createDataFrame(rdd, schema).cache()
} else {
import spark.implicits._
//test:user,event,invited,timestamp
spark.read.format("csv").option("header", "true").load("hdfs://single:9000/events/data/test.csv")
.select($"user".alias("userid"), $"event".as("eventid"), $"invited", $"timestamp")
}
}
def main(args: Array[String]): Unit = {
trans(lines = null)
}
}
18、使用sparkml读取训练模型,传入同等格式的数据,得到预测结果
思路:
- 导入sparkml依赖,读取hdfs上的文件
- 使用StringIndexer()方法对DataFrame数据做归一化的处理,并且把归一化的数据改为原名(sparkml是根据表名而不是顺序来读取的)
- 特征列批量转为double类型,使用df.columns.map方法转,再通过df1.select(cols:_*)传给一个新的DataFrame
- 获取hdfs上之前训练好的模型,使用PiplineModel方法读取加载
- 然后调用魔性的transform方法预测,即可得到结果
package cn.kgc.myhandler
import org.apache.spark.ml.PipelineModel
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{DoubleType, StringType}
object MyPrediction {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("test").getOrCreate()
import spark.implicits._
val df = spark.read.format("csv").option("header", "true").load("hdfs://single:9000/prediction/part*")
// df.show()
//将locale列转为数值:
val locale = new StringIndexer().setInputCol("locale").setOutputCol("localeid")
val r1 = locale.fit(df).transform(df).drop("locale").withColumnRenamed("localeid", "locale")
//starndarScaler对timezone列进行归一化
val tz = r1.select(avg($"timezone").as("avgtz"), stddev("timezone").as("stdtz"))
//求方差:stdtz
r1.crossJoin(tz).withColumn("timezone", ($"timezone" - $"avgtz") / $"stdtz")
//由于standardScaler方法的值有负数,我们希望是[0,1]
val r2 = r1
.withColumn("maxtz", max($"timezone".cast(DoubleType)).over())
.withColumn("mintz", min($"timezone".cast(DoubleType)).over())
.withColumn("timezone", ($"timezone".cast(DoubleType) - $"mintz") / ($"maxtz" - $"mintz"))
.withColumn("maxmd", max($"member_day".cast(DoubleType)).over())
.withColumn("minmd", min($"member_day".cast(DoubleType)).over())
.withColumn("member_day", ($"member_day".cast(DoubleType) - $"minmd") / ($"maxmd" - $"minmd"))
.withColumn("maxfc", max($"friend_count".cast(DoubleType)).over())
.withColumn("minfc", min($"friend_count".cast(DoubleType)).over())
.withColumn("friend_count", ($"friend_count".cast(DoubleType) - $"minfc") / ($"maxfc" - $"minfc"))
.withColumn("maxfic", max($"event_invited_count".cast(DoubleType)).over())
.withColumn("minfic", min($"event_invited_count".cast(DoubleType)).over())
.withColumn("event_invited_count", ($"event_invited_count".cast(DoubleType) - $"minfic") / ($"maxfic" - $"minfic"))
.withColumn("maxcl", max($"city_level".cast(DoubleType)).over())
.withColumn("mincl", min($"city_level".cast(DoubleType)).over())
.withColumn("city_level", ($"city_level".cast(DoubleType) - $"mincl") / ($"maxcl" - $"mincl"))
// .withColumn("label",lit("0"))
.drop("maxtz", "mintz", "maxmd", "minmd", "maxfc", "minfc", "minfic", "maxfic", "maxcl", "mincl")
//经测试
//调整列位置的顺序,使用数组方法patch等,并转为double类型
// val cls = "label" +: r2.columns.dropRight(2)
// val cols = cls.patch(3, Array("locale"), 0).map(x => col(x).cast(DoubleType))
// val res = r2.select(cols: _*)
//转成double类型
val cols = r2.columns.map(x => col(x).cast(DoubleType))
val res = r2.select(cols: _*)
//获取hdfs上的模型,sparkml用的是列名字做的
val model = PipelineModel.read.load("hdfs://single:9000/model")
print(model)
val finalResult = model.transform(res)
finalResult.show()
finalResult.select($"userid".cast(StringType), $"eventid".cast(StringType), $"prediction".cast(StringType))
.rdd.map(row => {
Predictions(
row.getAs[String]("userid"),
row.getAs[String]("eventid"),
row.getAs[String]("prediction")
)
}).filter(x => x.prediction.equals("1.0"))
.foreach(println)
// r1.show()
spark.stop()
}
}
19、把预测结果写入MySQL
19.1、先建库
drop database if exists ms_dm_intes;
create database ms_dm_intes;
use ms_dm_intes;
create table predictions(
userid varchar(20),
eventid varchar(20),
prediction varchar(20)
);
19.2、创建写入jdbc的方法
package cn.kgc.myhandler
import java.sql.{Connection, DriverManager, PreparedStatement}
import scala.collection.mutable.ListBuffer
case class Predictions(userid:Double,eventid:Double,prediction:Double)
object WriteJDBC {
def getConnection()={
DriverManager.getConnection("jdbc:mysql://single:3306/ms_dm_intes","root","root")
}
def write(list:ListBuffer[Predictions]) = {
var con:Connection = null;
var pst:PreparedStatement = null;
try {
con = getConnection()
con.setAutoCommit(false)
val sql = "insert into predictions values(?,?,?)"
pst = con.prepareStatement(sql)
for (pred <- list) {
pst.setDouble(1, pred.userid)
pst.setDouble(2, pred.eventid)
pst.setDouble(3, pred.prediction)
pst.addBatch()
}
pst.executeBatch()
con.commit()
} catch {
case e:Exception =>e.printStackTrace()
} finally {
if (con!=null){
con.close()
}
}
}
}
19.3、调用模型进行预测,然后把预测结果写入MySQL
package cn.kgc.myhandler
import org.apache.spark.ml.PipelineModel
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{DoubleType, StringType}
import scala.collection.mutable.ListBuffer
object MyPrediction {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName(this.getClass.getSimpleName).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.read.format("csv").option("header", "true").load("hdfs://single:9000/prediction/part*")
// df.show()
//将locale列转为数值:
val locale = new StringIndexer().setInputCol("locale").setOutputCol("localeid")
val r1 = locale.fit(df).transform(df).drop("locale").withColumnRenamed("localeid", "locale")
//starndarScaler对timezone列进行归一化
val tz = r1.select(avg($"timezone").as("avgtz"), stddev("timezone").as("stdtz"))
//求方差:stdtz
r1.crossJoin(tz).withColumn("timezone", ($"timezone" - $"avgtz") / $"stdtz")
//由于standardScaler方法的值有负数,我们希望是[0,1]
val r2 = r1
.withColumn("maxtz", max($"timezone".cast(DoubleType)).over())
.withColumn("mintz", min($"timezone".cast(DoubleType)).over())
.withColumn("timezone", ($"timezone".cast(DoubleType) - $"mintz") / ($"maxtz" - $"mintz"))
.withColumn("maxmd", max($"member_day".cast(DoubleType)).over())
.withColumn("minmd", min($"member_day".cast(DoubleType)).over())
.withColumn("member_day", ($"member_day".cast(DoubleType) - $"minmd") / ($"maxmd" - $"minmd"))
.withColumn("maxfc", max($"friend_count".cast(DoubleType)).over())
.withColumn("minfc", min($"friend_count".cast(DoubleType)).over())
.withColumn("friend_count", ($"friend_count".cast(DoubleType) - $"minfc") / ($"maxfc" - $"minfc"))
.withColumn("maxfic", max($"event_invited_count".cast(DoubleType)).over())
.withColumn("minfic", min($"event_invited_count".cast(DoubleType)).over())
.withColumn("event_invited_count", ($"event_invited_count".cast(DoubleType) - $"minfic") / ($"maxfic" - $"minfic"))
.withColumn("maxcl", max($"city_level".cast(DoubleType)).over())
.withColumn("mincl", min($"city_level".cast(DoubleType)).over())
.withColumn("city_level", ($"city_level".cast(DoubleType) - $"mincl") / ($"maxcl" - $"mincl"))
// .withColumn("label",lit("0"))
.drop("maxtz", "mintz", "maxmd", "minmd", "maxfc", "minfc", "minfic", "maxfic", "maxcl", "mincl").na.fill(0)
//经测试
//调整列位置的顺序,使用数组方法patch等,并转为double类型,
// val cls = "label" +: r2.columns.dropRight(2)
// val cols = cls.patch(3, Array("locale"), 0).map(x => col(x).cast(DoubleType))
// val res = r2.select(cols: _*)
//转成double类型
val cols = r2.columns.map(x => col(x).cast(DoubleType))
val res = r2.select(cols: _*)
//获取hdfs上的模型,sparkml用的是列名字做的
val model = PipelineModel.read.load("hdfs://single:9000/model")
print(model)
val finalResult = model.transform(res)
// finalResult.show()
//DoubleType:类型信息类,镜子里的对象。反射,在开辟空间时,我们也不知道这个对象有多大,因此当获取到类型信息类时,就可以知道有多大了
//Double:镜子前的你,包装类
finalResult.select($"userid".cast(DoubleType), $"eventid".cast(DoubleType), $"prediction".cast(DoubleType))
.rdd.map(row => {
Predictions(
row.getAs[Double]("userid"),
row.getAs[Double]("eventid"),
row.getAs[Double]("prediction")
)
})
.repartition(10).foreachPartition(iter=>{
val list = ListBuffer[Predictions]()
iter.foreach(list.append(_))
// println(list.size)
WriteJDBC.write(list)
})
// r1.show()
spark.stop()
}
}
20、把维度表导入到MySQL中和结果表对应上
20.1、创建维度表
注意hive数据过大的话,在MySQL里一定要创建索引,否则多表join时,会很慢很慢
use ms_dm_intes;
create table dim_users(
userid varchar(100),
locale varchar(100),
birthyear varchar(100),
gender varchar(100),
joinedat varchar(100),
location varchar(100),
timezone varchar(100)
);
create table dim_events(
eventid varchar(100),
userid varchar(100),
starttime varchar(100),
city varchar(100),
state varchar(100),
zip varchar(200),
country varchar(100),
lat varchar(100),
lng varchar(100),
features varchar(380)
);
create table dim_user_friends(
userid varchar(100),
friendid varchar(100)
);
create table dim_event_attendees(
eventid varchar(100),
userid varchar(100),
actions varchar(100),
);
-- kmeans时用的double类型,转为了科学计数法,此处需要转回double来
create table dim_eventtype(
eventid double,
eventgrp varchar(100)
);
-- 数据导进来后,第一行有个null,删掉,建表时不删
delete from dim_eventtype where eventid is null;
-- 创建dim_eventtype索引
alter table dim_eventtype add index idx_eventid(eventid);
20.2、sqoop把数据从hive导入到MySQL中
从hive中导表到sqoop中,需要使用hcatalog的方法指定表,提前配置好hive目录下hcatalog的环境变量
# 使用sqoop把dwd层的维度表都导入到MySQL的dim层数据库
# users表
sqoop export \
--connect jdbc:mysql://single:3306/ms_dm_intes \
--username root \
--password root \
--table dim_users \
--num-mappers 3 \
--hcatalog-database dwd_intes \
--hcatalog-table dwd_users
# events表
sqoop export \
--connect jdbc:mysql://single:3306/ms_dm_intes \
--username root \
--password root \
--table dim_events \
--num-mappers 3 \
--hcatalog-database dwd_intes \
--hcatalog-table dwd_events
# user_friends表
sqoop export \
--connect jdbc:mysql://single:3306/ms_dm_intes \
--username root \
--password root \
--table dim_user_friends \
--num-mappers 3 \
--hcatalog-database dwd_intes \
--hcatalog-table dwd_user_friends
# event_attendees表
sqoop export \
--connect jdbc:mysql://single:3306/ms_dm_intes \
--username root \
--password root \
--table dim_event_attendees \
--num-mappers 3 \
--hcatalog-database dwd_intes \
--hcatalog-table dwd_event_attendees
# eventtype会议类型表
sqoop export \
--connect jdbc:mysql://single:3306/ms_dm_intes \
--username root \
--password root \
--table dim_eventtype \
--num-mappers 3 \
--hcatalog-database dwd_intes \
--hcatalog-table dwd_eventtype
21、使用finereport可视化
21.1、MySQL 创建索引,加快查询速度
-- 地域列创建组合索引
alter table dim_events add index region(country,state,city);
-- 但组合索引还是太慢了,新建一张表,创建主键索引
-- 还有一个原因是,sqoop导入hiveorc的原因,文件互拷
create table dim_events_bak as dim_events select * from dim_events where 0=1;
alter table dim_events_bak add primary key(eventid);
insert into dim_events_bak select * from dim_events_bak;
-- 创建完之后,查询新表,可以看到查询快多了
select country,state,count(eventid)
from dim_events_bak
group by country,state
-- 我们再创建一个主键
alter table dim_events_bak add primary key(eventid);
21.2、大屏
Hive 创建索引,可以加快查询速度:
参考文章:https://blog.csdn.net/zzq900503/article/details/79391071

create index idx_events_eventid on table dwd_intes.dwd_events(eventid)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table dwd_intes.dwd_events_idx;
alter index idx_events_eventid on dwd_intes.dwd_events rebuild;
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
SET hive.optimize.index.filter=true;
SET hive.optimize.index.filter.compact.minsize=0;
create table dws_intes.dws_week_peonum as
select case weekday
when 1 then '星期日'
when 2 then '星期一'
when 3 then '星期二'
when 4 then '星期三'
when 5 then '星期四'
when 6 then '星期五'
when 7 then '星期六' end weekday,peo_num
from (
select dayofweek(e.starttime) weekday,count(t.userid) peo_num
from (
select userid,eventid
from
dwd_intes.dwd_train
) t
left join dwd_intes.dwd_events e on e.eventid=t.eventid
group by dayofweek(e.starttime)
order by peo_num desc
)T;
21.3、使用spring boot 插入数据,代替sqoop导入orc文件,防止mysql读orc文件过慢的问题
Mybatis双源处理
mysql建一张表接这个数据
create table dim_events_bak1 as select * from dim_events_bak where 0=1;
顺便创建一个索引
alter table dim_events_bak1
如果一次性从hive读取数据装进集合的话,就会遇到数据量过大提不出来的问题,而且,insert into values后面拼接的数据过大(超过4M)也会报错
因此采用分段提取hive表数据的方法,此处创建一个临时用的表(不能是临时表,因为客户端和jdbc),设置批次索引,每个批次读完就写
create table dwd_intes.tmp_dwd_events as
select b.*,floor(rn/50000) flag from
(select *,row_number() over() rn from dwd_intes.dwd_events)b;
Mybatis里,读hive数据时不要用select * ,
# 创建时间维度表
create table dim_times(fyear varchar(20),fmonth varchar(20));
# 使用存储过程生成年月日数据
delimiter $$
create procedure insert_tm(begintime varchar(20),overtime varchar(20))
begin
declare tm int;
declare mth int;
declare y int;
declare m int;
set mth=timestampdiff(month,begintime,overtime);
set tm=0;
while tm<=mth do
set y=year(begintime);
set m=month(begintime);
insert into dim_times(fyear,fmonth) values(y,m);
set begintime=date_add(begintime,interval 1 month);
set tm=tm+1;
end while;
end;
$$


















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









