







数据集的搜寻
以下内容为搜索、寻找部分合适数据集的全部过程(主要是图片和音频资源)。
功能设计
这里我们只需考虑需要图片和音频数据集的部分功能设计。
功能1:卡片学习
这里我们先分析卡片学习的一部分:用户可以根据图片的显示选择出对应正确的词语。
比如:图片为实体桌子,那么用户就要在四个选项中准确选出“桌子”这个词语。
功能2:识图搜词
用户将图片上传,软件可以分析图片内容并给出对应的词语。
比如:用户上传图片的主体为小猫,软件应当分析出图片的主体并给出对应的词语:“小猫”。
功能分析
对上述功能设计中的功能进行分析,来解释为什么需要图片和音频的数据集。
功能1:卡片学习之看图选词
机器学习模型的训练基础
“看图选词” 功能依赖计算机视觉(CV)和自然语言处理(NLP)技术,需通过图像分类模型(CNN)和图文匹配模型(CLIP)实现。
(1)图像分类:将图片分为 “动物”“食物”“动作” 等类别,对应中文词汇标签(如 “猫”“米饭”“跳跃”)。
(2)图文匹配:建立 “图片 - 词语” 的语义关联,确保模型能判断 “图片内容是否匹配某个词语”。
(3)关键依赖:这些模型需要大量标注好的 “图片 - 词语” 对作为训练数据(即图片数据集),否则算法无法学习到正确的映射逻辑。
功能2:识图搜词
1.训练图像识别模型
(1)特征学习:图片数据集是训练图像识别模型的基础。模型通过学习数据集中大量图片的特征,如颜色、纹理、形状等,来理解不同物体的外观特点。例如,通过学习各种小猫图片的特征,模型能够识别出小猫的耳朵形状、眼睛特点、毛发纹理等关键特征,从而在用户上传小猫图片时准确识别并给出 “小猫” 这个词语。
(2)泛化能力培养:丰富的图片数据集可以让模型接触到各种不同场景、不同姿态、不同品种的小猫图片,以及其他各类物体的图片,从而培养模型的泛化能力,使其能够准确识别出在不同环境和条件下的物体,而不仅仅是训练数据中出现过的特定情况。这样,当用户上传一张比较特殊或不常见角度的小猫图片时,模型也能正确分析并给出相应的词语。
2.提高识别准确性和效率
(1)优化模型参数:在训练过程中,图片数据集用于调整模型的参数,使模型能够更好地拟合数据,降低识别错误率。通过不断地在数据集上进行训练和验证,模型可以逐渐找到最优的参数组合,从而提高对各种图片内容的识别准确性。例如,对于小猫和小狗这两种容易混淆的动物,模型通过在大量标注好的小猫和小狗图片数据集上学习,可以准确地区分它们的特征,避免将小猫图片误识别为小狗。
(2)加快识别速度:经过大规模图片数据集训练的模型,在面对新的图片时,能够快速地提取特征并进行匹配,从而提高识图搜词的效率,减少用户等待时间。
通过以上分析我们就可以得知,看图选词与识图搜词功能是确确实实需要数据集的,因此接下来我们就开始寻找数据集。
数据集的寻找
数据集的寻找也经历了从困难到简单的过程。
在Gitee上搜索
最初我想在Gitee上寻找相关开源项目,这些项目中可能包含我所需要的图片或音频资源或者提供资源的获取方式。
但是当我在 Gitee 的搜索框中输入与 “外国人学中文”“中文学习软件”“中文图片单词学习”“中文情景对话音频” 等相关的关键词时,所显示的内容都是不相关的东西。
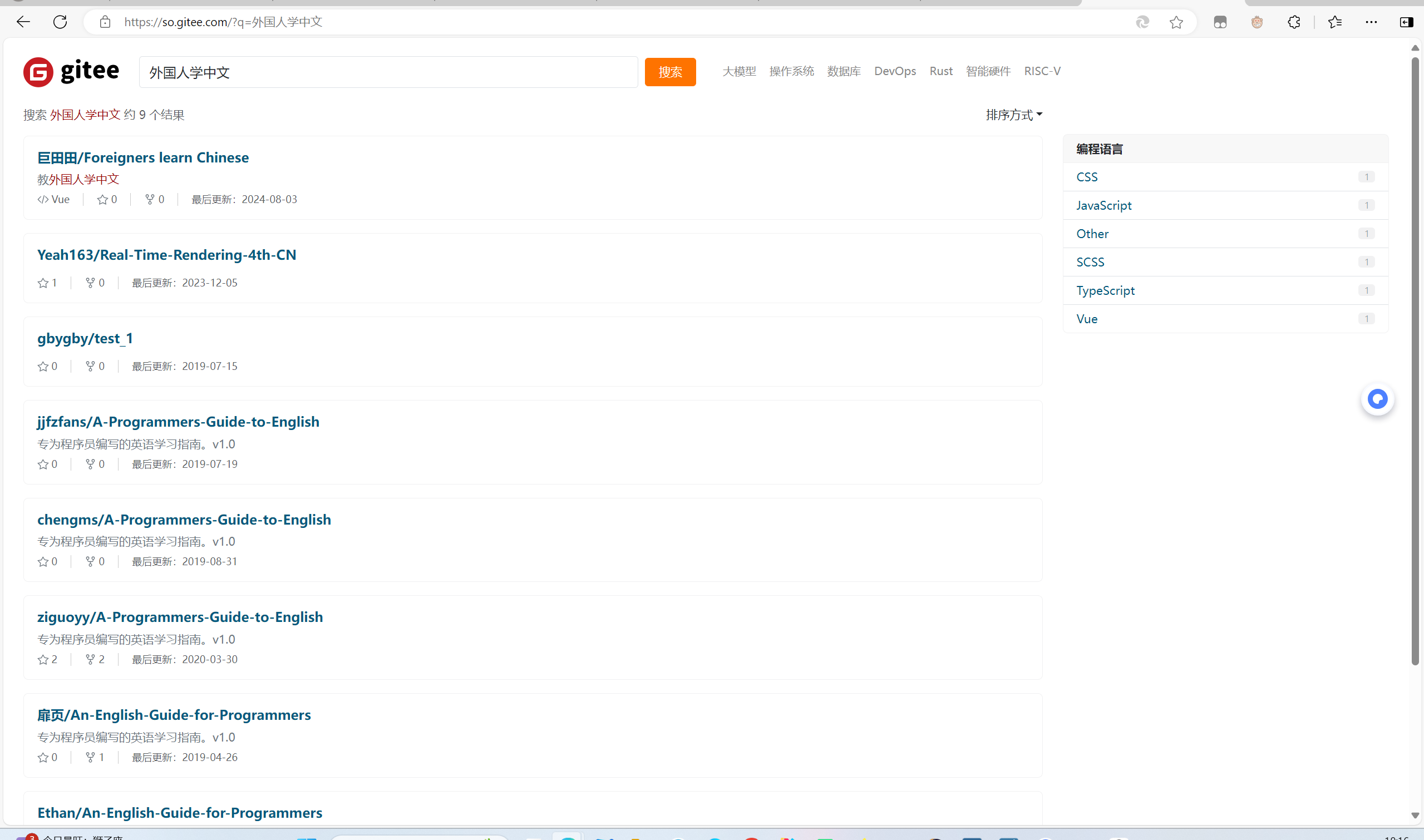
所以并没有在 Gitee 上找到合适的资源,于是我开始考虑在其他渠道获取,比如一些专门的中文学习资源网站。
在中文学习资源网站上搜索
找到了特别多的网站,这里以mandarinbean为例子,它提供 HSK 阅读和听力材料,分别有初级、中级和高级课程,每个汉字都有详细的英文解析和同步音频朗读。
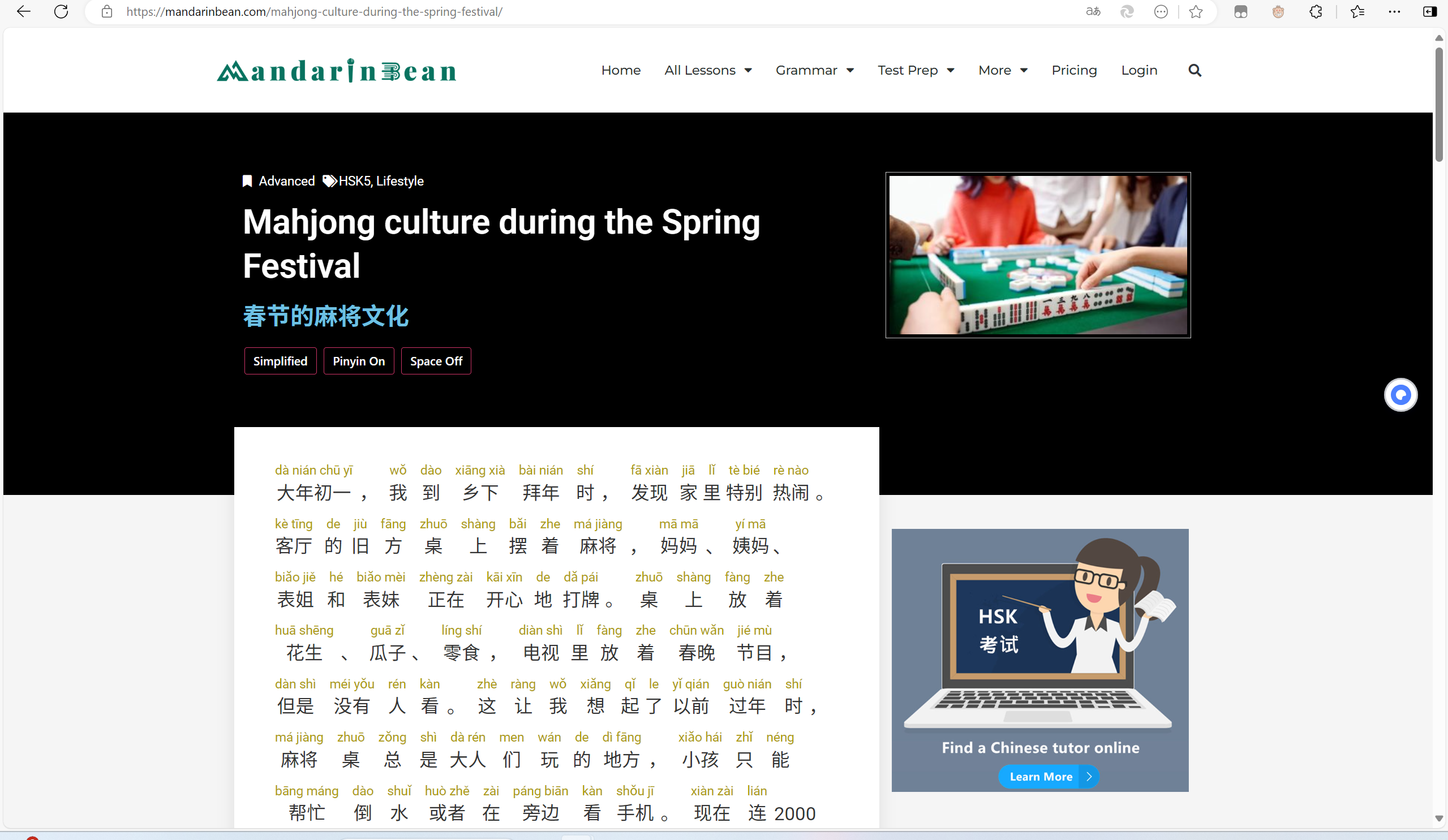
但是这些网站并没有开源的图片、音频数据集,于是又查找失败。
直接搜索
最后在浏览器直接搜索了中文词语图片、视频数据集资源,意外发现了一个数据集网站: 数据集
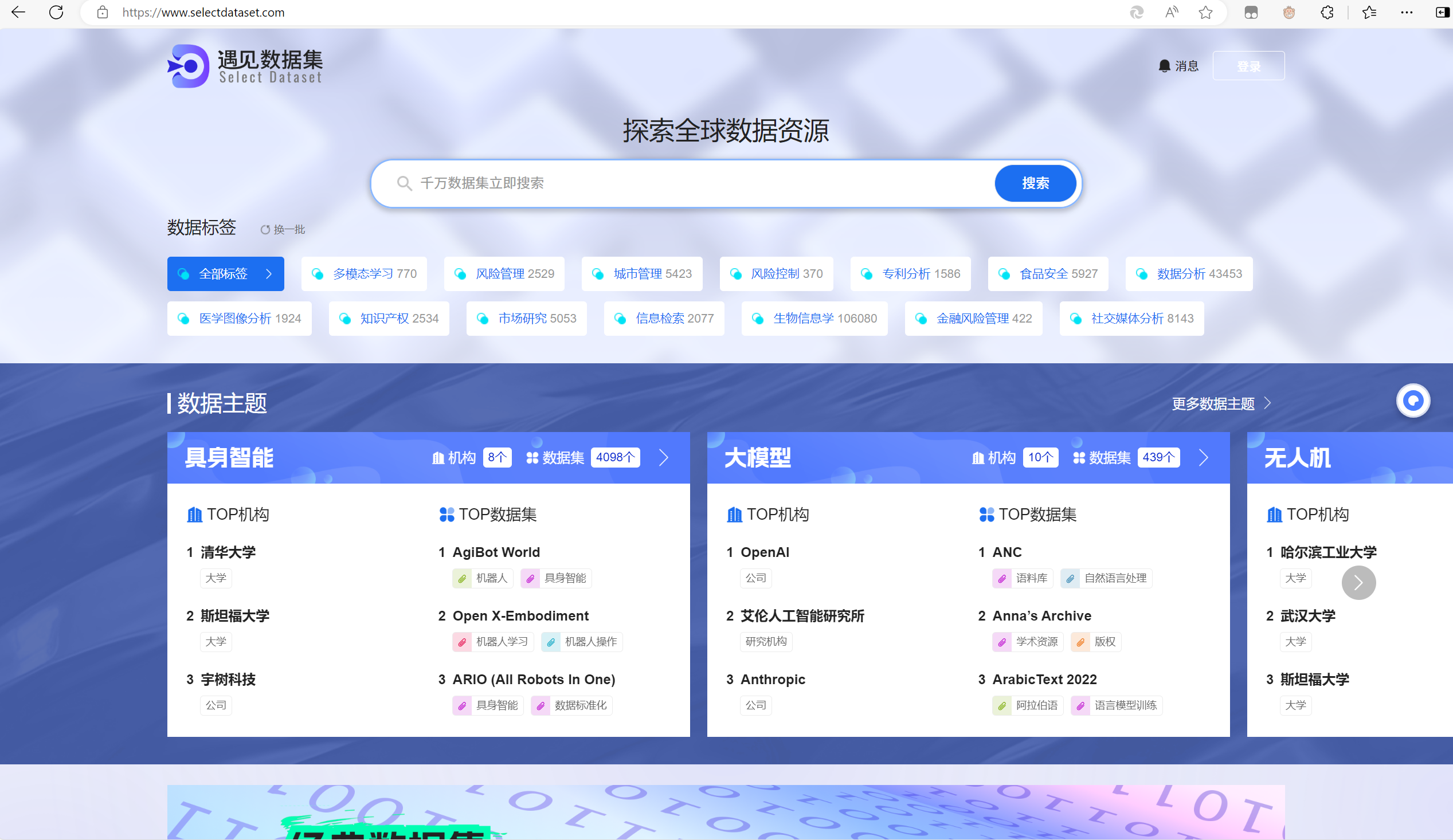 1.图片数据集
1.图片数据集
江城太素(TaiSu)

MS Coco
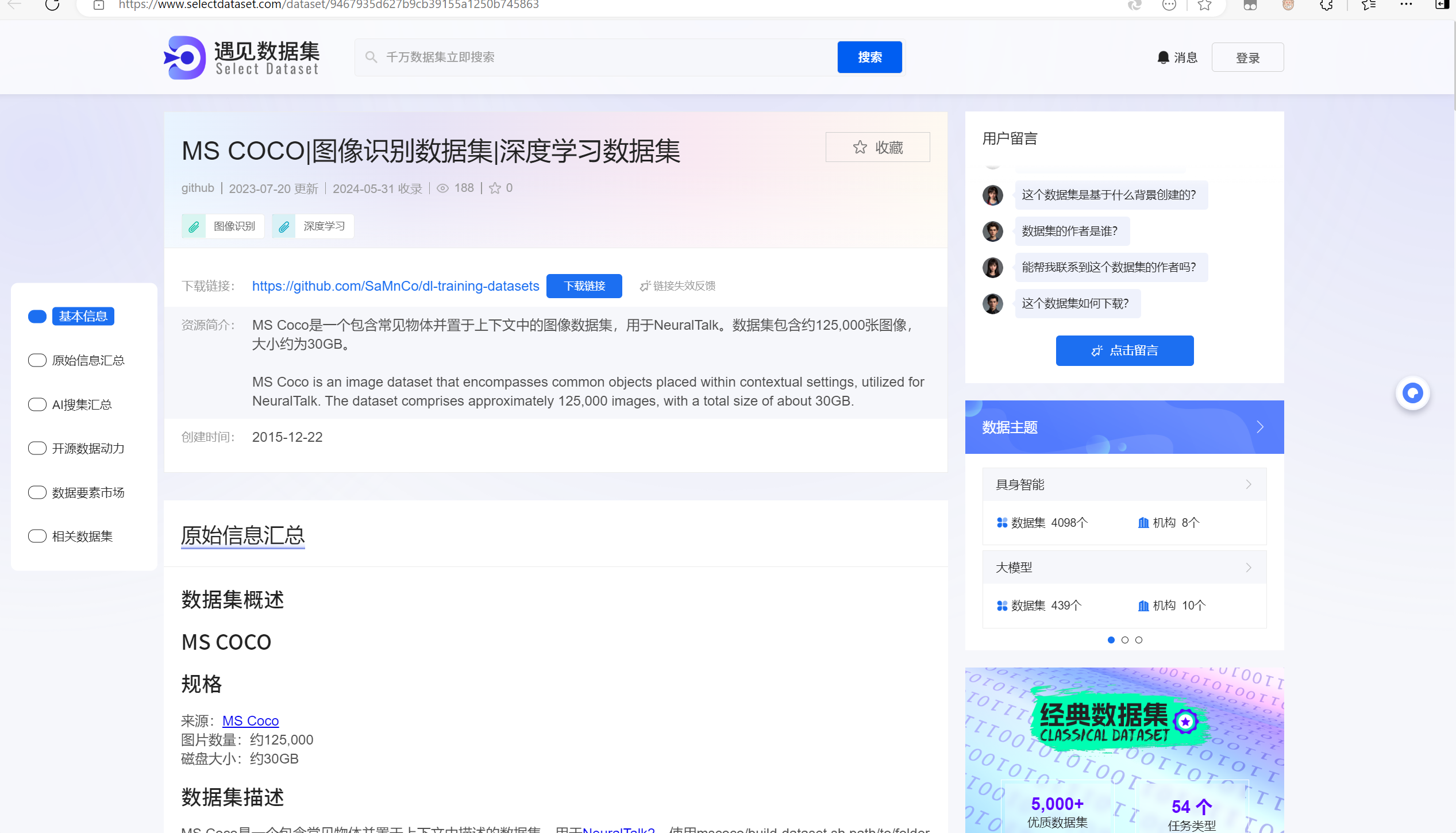
2.音频数据集
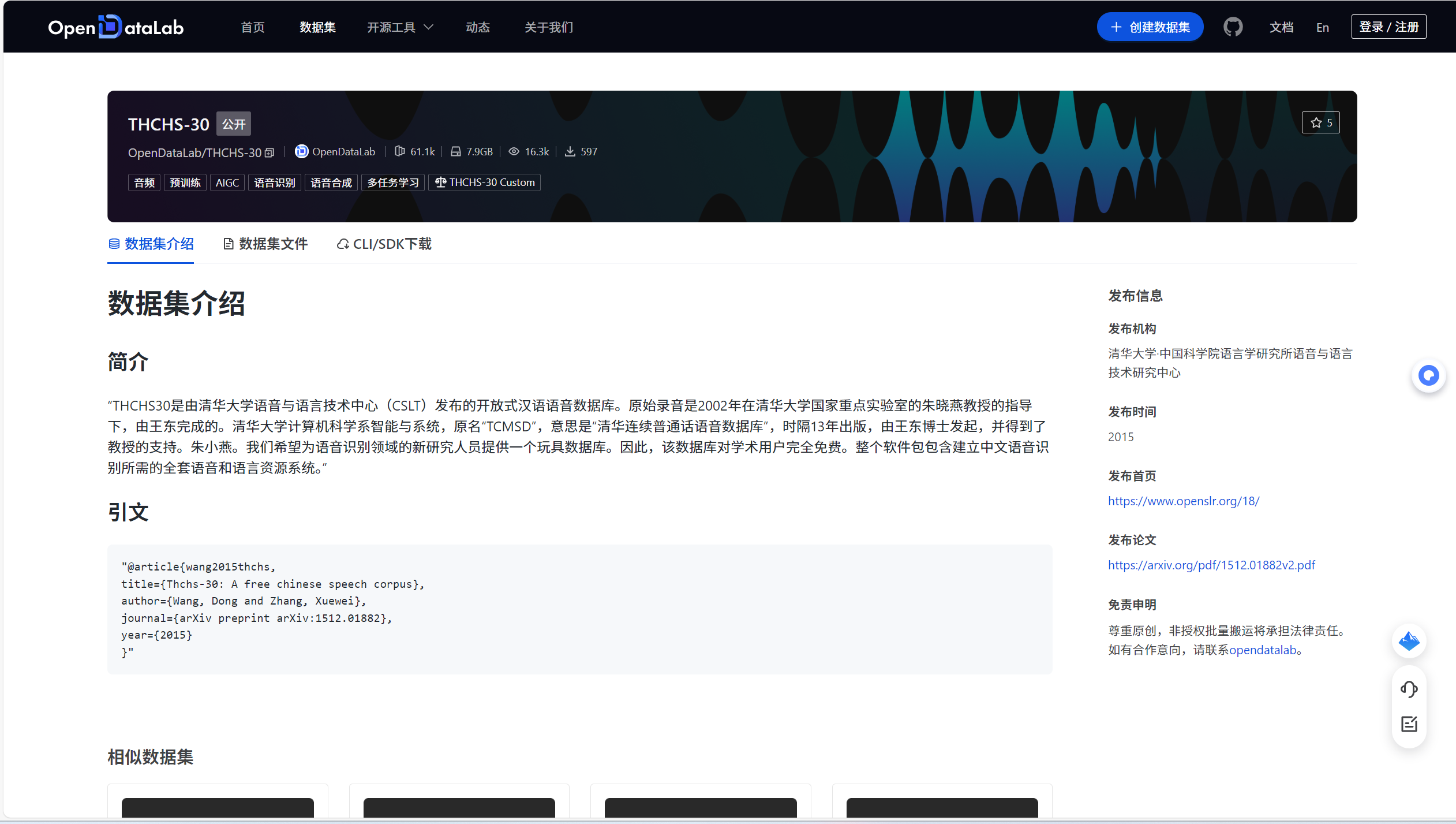
THCHS-30
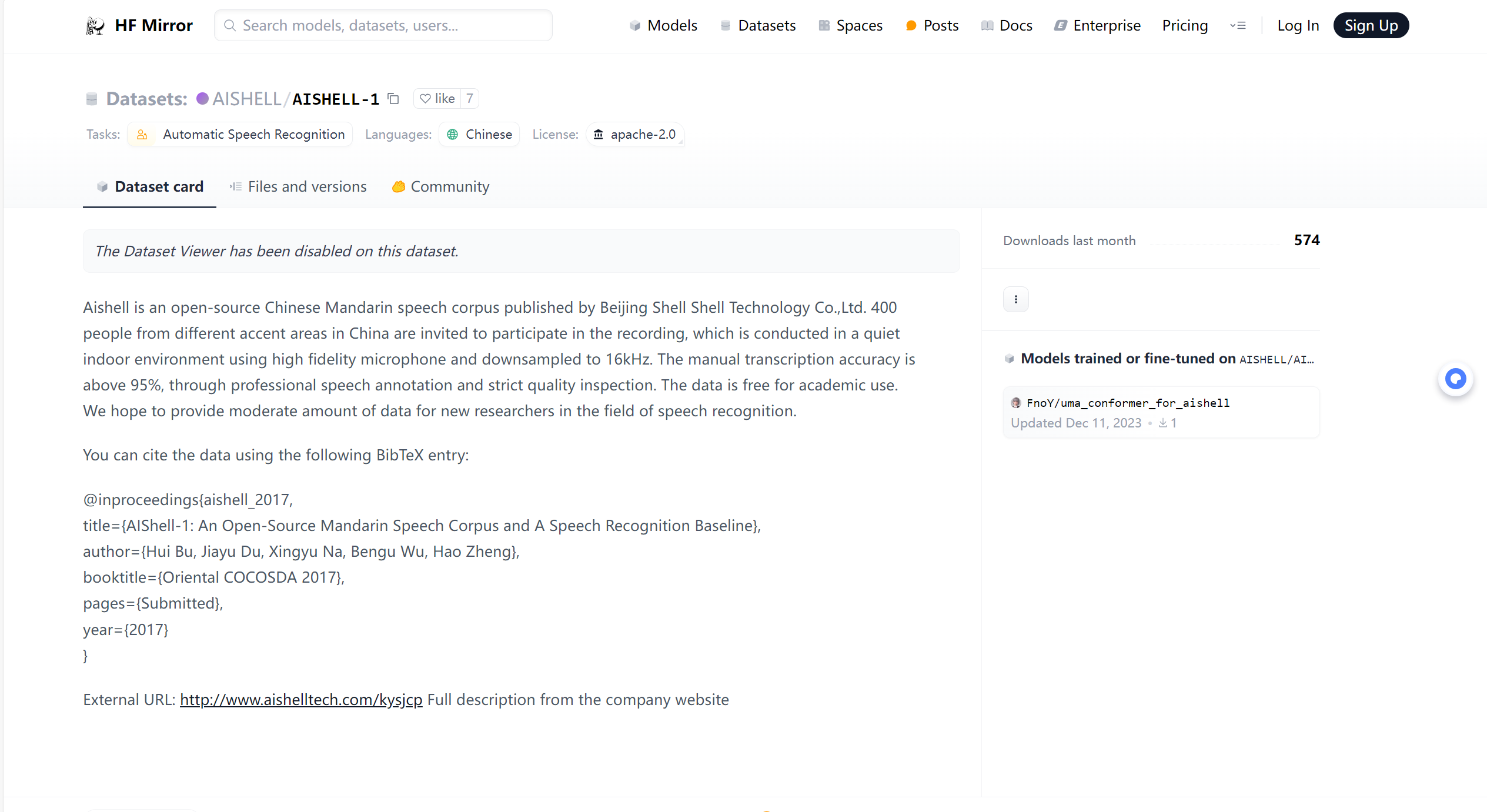
AISHELL
链接
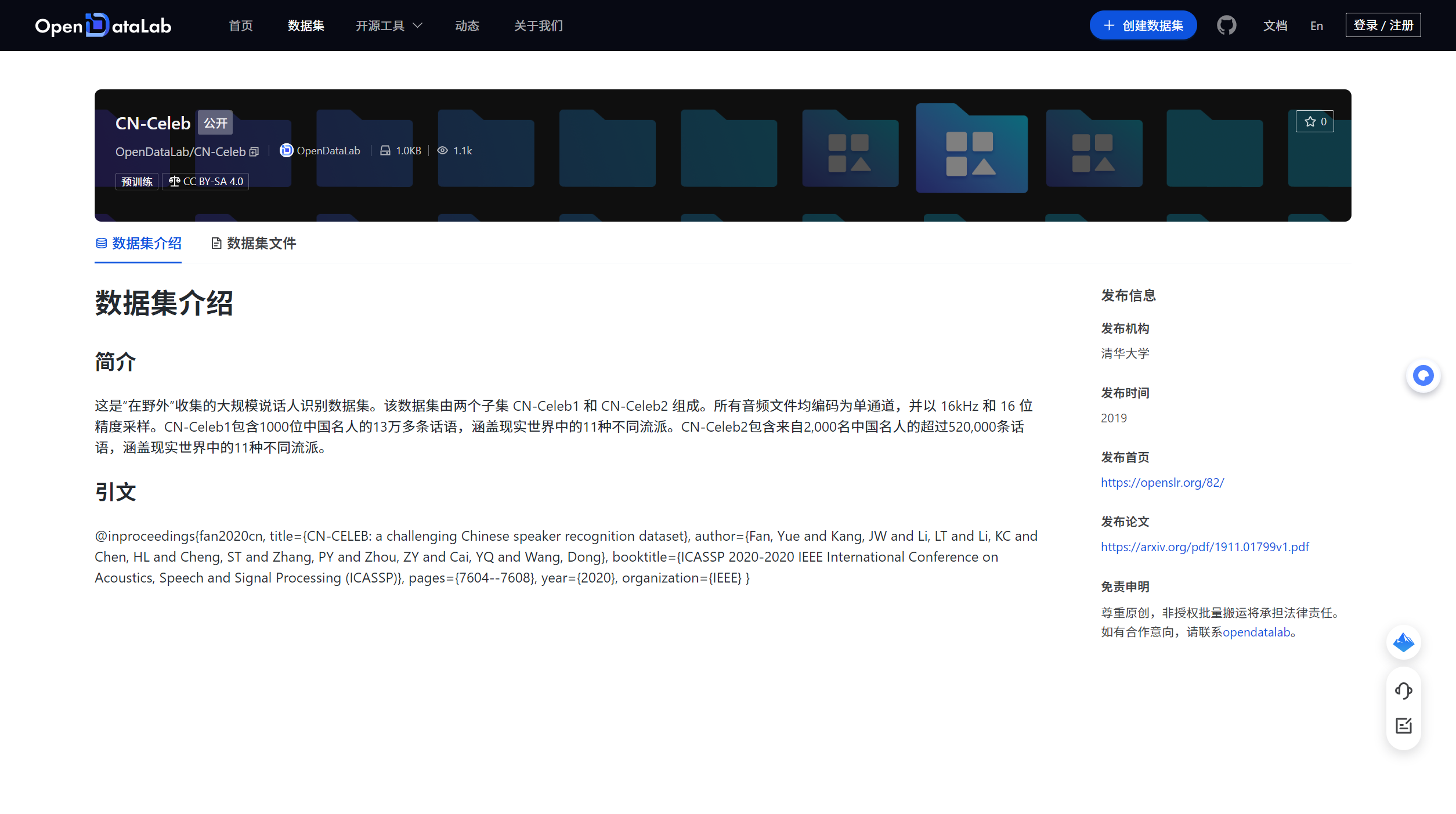
CN-Celeb
至此数据集搜索过程结束,以上就是全部过程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









