







1、Controller Broker机制
Kfaka集群在工作时,有两个比较重要的领导者,一个是Topic 下面每个Partition 都会有一个Leader,另一个就是所有Broker 中会有一个Controller
其主要负责:
-
分区和副本的状态
-
监听/brokers/ids 下面节点的变化
-
监听/brokers/topics 感知topic以及对应的partition 的变化
-
监听/admin/delete_topic 节点,处理删除topic的动作
-
将元数据推送给其余Broker
在集群中的Kfaka启动时,会向Zookeeper中写一个/controller 临时节点,并将自己的brokerid写入,只要有一个写入成功,那么其余节点就不能写入成功,保证集群中只有一个Controller。
2、Leader Partition 选举机制
LeaderPartition状态如何记录
Kafka中每一个Topic的消息都是记录在多个Partition下面的,在创建Topic时,可指定topic有几个Partition以及有几个副本
-
--replication-factor 指定每个partition有几个副本、备份
-
--partitions 指定有几个partition
<span style="background-color:#dadada"><span style="color:#1f0909">bin/kafka-topics.sh --bootstrap-server 172.26.163.240:9092 --create --replication-factor 2 --partitions 4 --topic disTopic</span></span>在多个partition备份中需要选出一个leader,负责对接所有客户的消息,并将消息优先保存,然后通知其余的follower同步消息
通过下面的指令,查看集群中topic的状态
<span style="background-color:#dadada"><span style="color:#1f0909">bin/kafka-topics.sh --bootstrap-server 172.26.163.240:9092 --describe --topic disTopic</span></span>
可以看出,每个topic有多个partition,每个partiiton有多个备份,每个partition有一个leader
下面解释一下Replicas 以及 Isr
-
Replicas 又称 AR(Assigned Replicas) 表示分区中的所有副本,不管是否在线
-
ISR 表示所有在AR中存活的副本,存活的机器,需要与Leader定时发送消息,如果超时,会被提出ISR集合,超时时间由replica.lag.time.max.ms参数设置,默认为30s
-
OSR,表示从ISR中提出的节点
Leader 如何选举
这里在3台集群中下线第二台机器的Kfaka服务,即BrokerID为1的机器
下线前可以看出partition 1 的leader是节点1
下线指令bin/kafka-server-stop.sh

下线后可以看出,Partiton1的leader变成了0,
选举机制是这样的:
遍历AR,如果当前机器在ISR中就它为Leader
3、Leader Partition 自动平衡机制
Leader 选举机制保证了我们集群中的Partition每时每刻只有一个Leader,保证了我们服务的高可用,但是,并不是这样就能保证我们服务的稳定,通常Leader是业务繁忙的一个机器,如果在所有partition中,1在拥有大部分partiton的备份,如果在选举过程中导致1变成大部分Partition的Leader,那么就会导致1机器的压力,没有分配好集群中机器的资源。
那么Kafka如何解决的呢?
自平衡逻辑:
通常认为Ar中的第一个就是理想的Leader,Controller会定期检测集群中的Partition平衡情况,检查时,会遍历所有Broker,如果发现Broker上不配合Partiton的比例高于leader.imbalance.per.broker.percentage阈值时,就会触发一次Leader Partition的自平衡。
涉及下面几个参数

也可以手动触发:bin/kafka-leader-election.sh --bootstrap-server worker1:9092 --election-type preferred --topic secondTopic --partition 1
4、Kafka的Partition故障恢复机制
在Kafka设计最初,就是为了保证在各种不稳定网络情况下的高可用,那么如何保证在partition的Leader宕机,选举Leader过程中的高可用呢?
在Kafka内部保证数据同步时有两个关键的参数 LEO、HW
-
LEO:每个Partition的最后一个Offset
每个Partition都会记录自己保存消息的偏移量,Leader 在收到消息后会将消息保存并将LEO + 1,同时将消息同步到Follower,follower在收到leader的消息后将自身的LEO + 1,这就完成了消息的接收和备份
这与前面的ack机制不同,ack机制是生产者与Broker保证消息成功投递
-
HW(High Watermark):一组Partition中最小的LEO
follower在向Leader同步消息时,会将自己的LEO给Leader,这样Leader就可以计算HW,并会将最终的HW同步给follower,集群中认为,这个HW之前的消息是安全的,这些安全的消息就可以暴露给消费者,供消费者消费,而HW之后的消息是不安全的。
下面讨论两种情况:
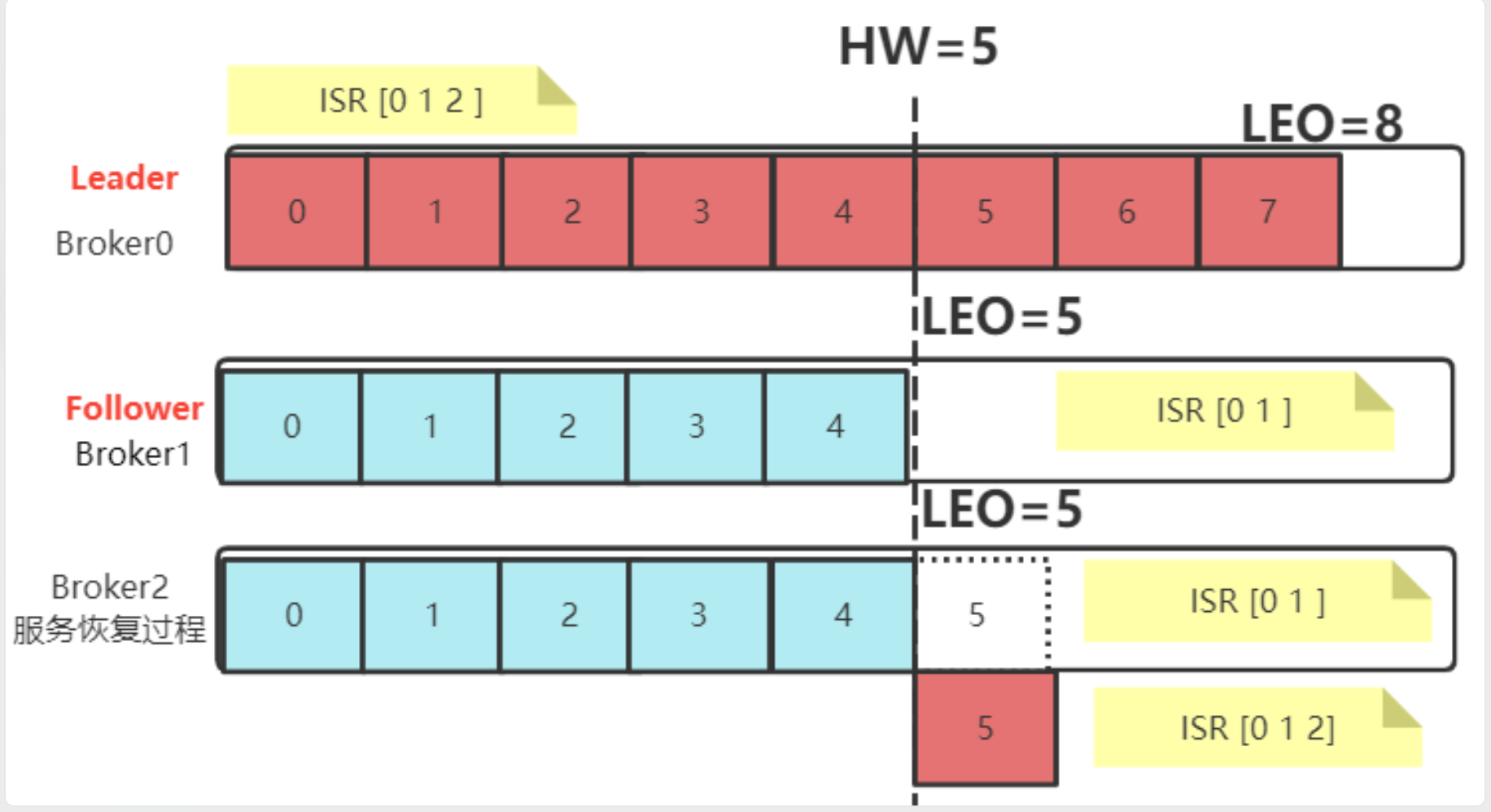
1、follower宕机
follower宕机这比较好处理,无非是partition少了一个备份,将follower提出ISR集合就行,而在follower恢复后不会立即加入集群工作,而是会静自己日志中高于HW的信息全部删掉,然后开始向leader请求HW,进行消息同步,当follower的LEO大于等于集群的HW时,才会重新加入集群。
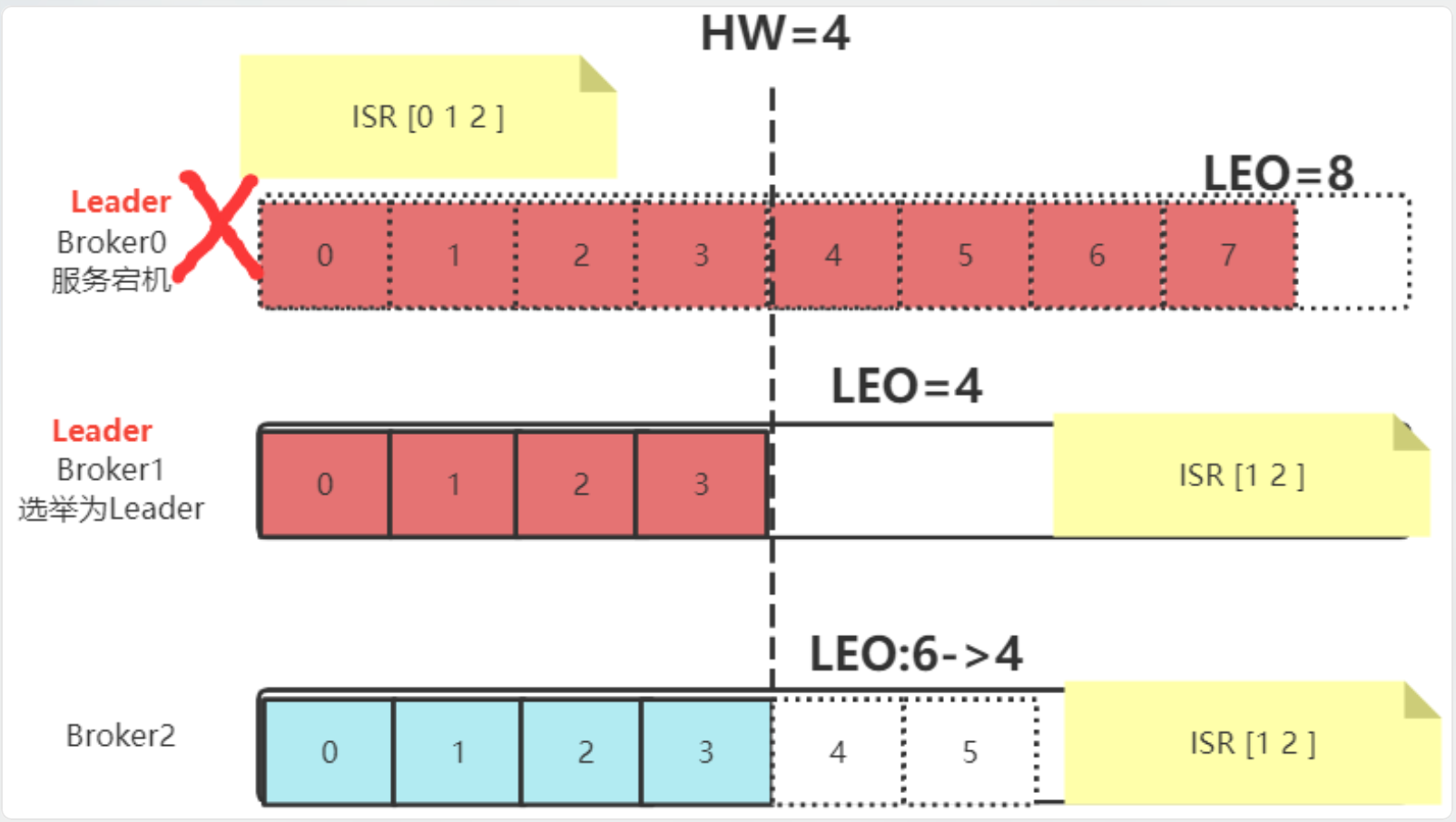
2、leader宕机
leader宕机的话,会导致还存在消息没有同步给follower,这会导致消息的丢失,这里复习一下选举过程,遍历AR,如果当前节点在ISR中,就为Follower,这时候,集群就以新的Leader的HW为准,将各自高于HW的消息删掉,然后从新的Leader同步消息
Kafka在Partition恢复 的过程当中,有可能会有消息丢失。

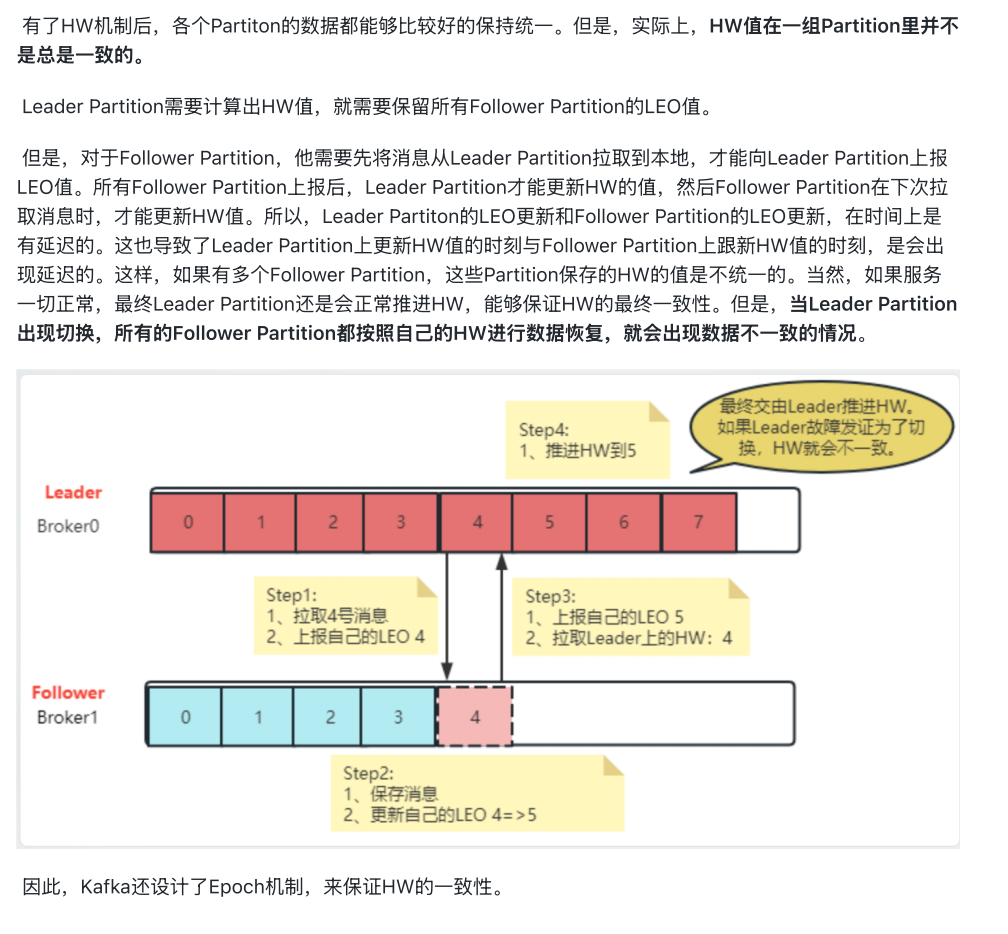
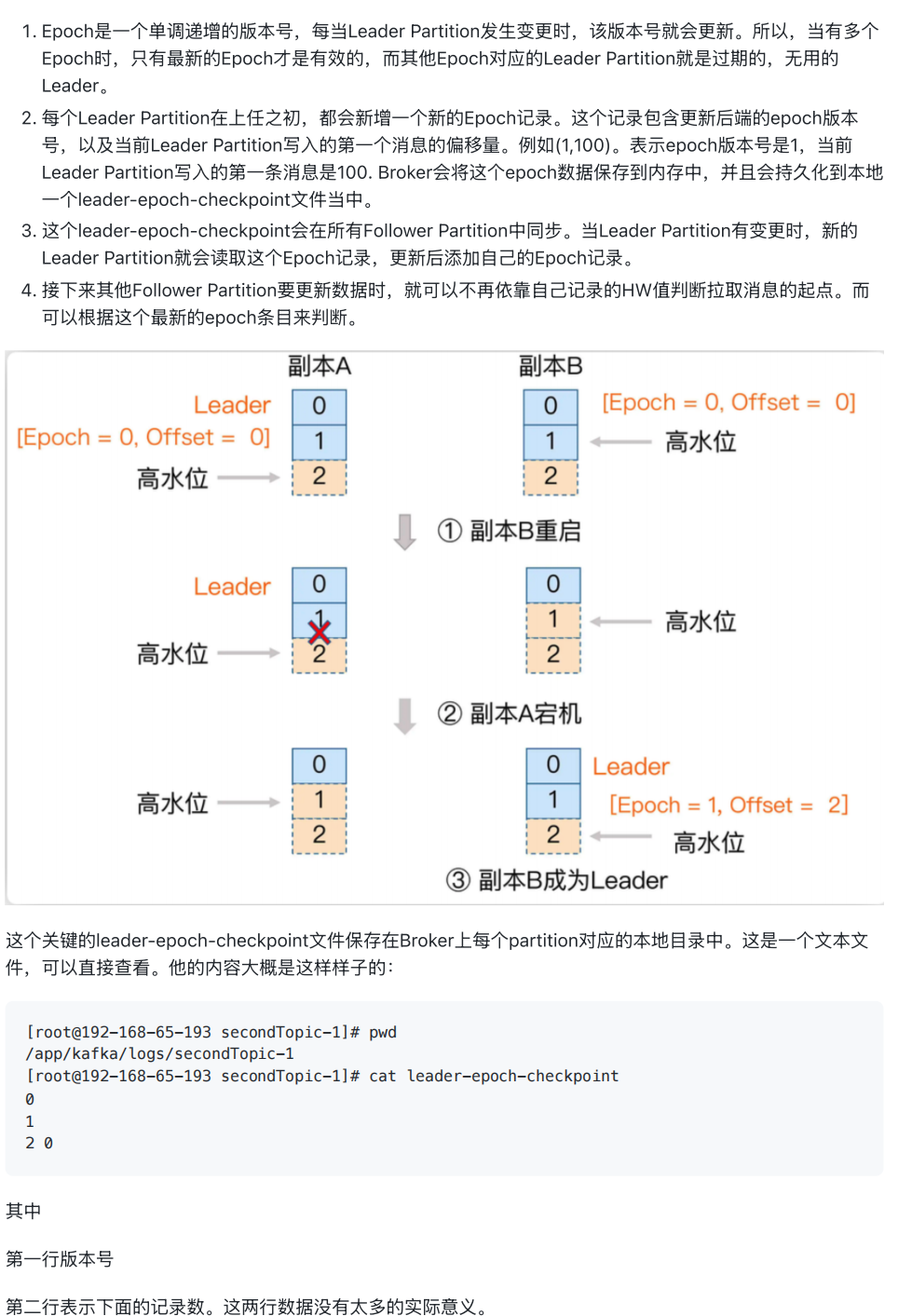
5、HW一致性保障机制 - Epoch更新机制



















 4927
4927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











