








一个多月对Elasticsearch的探索,现将其中的坑列出来,以免后面再忘记。
首先在这里申明数据量:
记录数:1914531
用户量:62749
可以看到数据量还是很小的。数据是一个用户在某个时间确证的疾病的编码,然后我们利用该数据去计算OR。
对于OR的计算介绍如下:
给定疾病A与疾病B,得到表格:
| 疾病B存在 | 疾病B不存在 | |
| 疾病A存在 | N11 | N10 |
| 疾病A不存在 | N01 | N00 |
其中:
- N11:A存在,B存在,
- N10:A存在,B不存在
- N01:A不存在,B存在,
- N00:A不存在,B不存在
Standard error:SE=sqrt(1/N11+1/N10+1/N01+1/N00)
置信区间:[e^M,e^N],M=ln(OR)-1.96SE,N=ln(OR)+1.96SE
HBase中直接计算OR
数据导入HBase当然是我们的第一步,这里不介绍。数据格式如下:
然后我们进行计算OR:
//tow exits!
val sf1 = new SingleColumnValueFilter(Bytes.toBytes(colFamily),Bytes.toBytes(icdname.apply(i).apply(0).toString),CompareFilter.CompareOp.EQUAL,Bytes.toBytes("1"))
val sf2 = new SingleColumnValueFilter(Bytes.toBytes(colFamily),Bytes.toBytes(icdname.apply(j).apply(0).toString),CompareFilter.CompareOp.EQUAL,Bytes.toBytes("1"))
sf1.setFilterIfMissing(true)
sf2.setFilterIfMissing(true)
val filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL)
filterList.addFilter(sf1)
filterList.addFilter(sf2)
scan1.setFilter(filterList)
val scanner1 = table.getScanner(scan1)
val doubleexit = scanner1.iterator().asScala.length
其他的情况跟上面的代码相似。
if(doubleexit*oneexit1*oneexit2*noexit!=0){
val or:Float = (doubleexit*oneexit1)/(oneexit2*noexit).toFloat
val se:Float = math.sqrt((1.toFloat/doubleexit)+(1.toFloat/oneexit1)+(1.toFloat/oneexit2)+(1.toFloat/noexit)).toFloat
val m = math.log(or)/math.log(math.E)-(1.96*se)
val n = math.log(or)/math.log(math.E)+(1.96*se)
val disease1 = icdname.apply(i).apply(0)
val disease2 = icdname.apply(j).apply(0)
out.println(s"$disease1 $disease2 $or $se $m $n")
out.flush()
}
然后使用公式计算出相应的OR已经置信区间。
但是不幸的是:任务跑了34个小时。
//tow exits!
val sf1 = new SingleColumnValueFilter(Bytes.toBytes(colFamily),Bytes.toBytes(icdname.apply(i).apply(0).toString),CompareFilter.CompareOp.EQUAL,Bytes.toBytes("1"))
val sf2 = new SingleColumnValueFilter(Bytes.toBytes(colFamily),Bytes.toBytes(icdname.apply(j).apply(0).toString),CompareFilter.CompareOp.EQUAL,Bytes.toBytes("1"))
sf1.setFilterIfMissing(true)
sf2.setFilterIfMissing(true)
val filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL)
filterList.addFilter(sf1)
filterList.addFilter(sf2)
scan1.setFilter(filterList)
val scanner1 = table.getScanner(scan1)
val doubleexit = scanner1.iterator().asScala.length其他的情况跟上面的代码相似。
if(doubleexit*oneexit1*oneexit2*noexit!=0){
val or:Float = (doubleexit*oneexit1)/(oneexit2*noexit).toFloat
val se:Float = math.sqrt((1.toFloat/doubleexit)+(1.toFloat/oneexit1)+(1.toFloat/oneexit2)+(1.toFloat/noexit)).toFloat
val m = math.log(or)/math.log(math.E)-(1.96*se)
val n = math.log(or)/math.log(math.E)+(1.96*se)
val disease1 = icdname.apply(i).apply(0)
val disease2 = icdname.apply(j).apply(0)
out.println(s"$disease1 $disease2 $or $se $m $n")
out.flush()
}
然后使用公式计算出相应的OR已经置信区间。
Elasticsearch运行OR
HBase不能满足我们的要求,故而去选择Elasticsearch。
首先,我们需要将需要建索引的字段写入到Elasticsearch中,为字段建索引。这个过程经历了比较多的坑,但是归根结底还是Elasticsearch没有熟悉,所以对其中的原理不熟悉,导致整个过程经历了比较久。
数据写入到Elasticsearch中之后,接下来的工作就是检索疾病的数量,从而进行OR的计算。由于考虑到要使用spark作为计算引擎,所以想着先把数据加载到spark中,然后再基于spark进行计算。下面是我的计算逻辑:
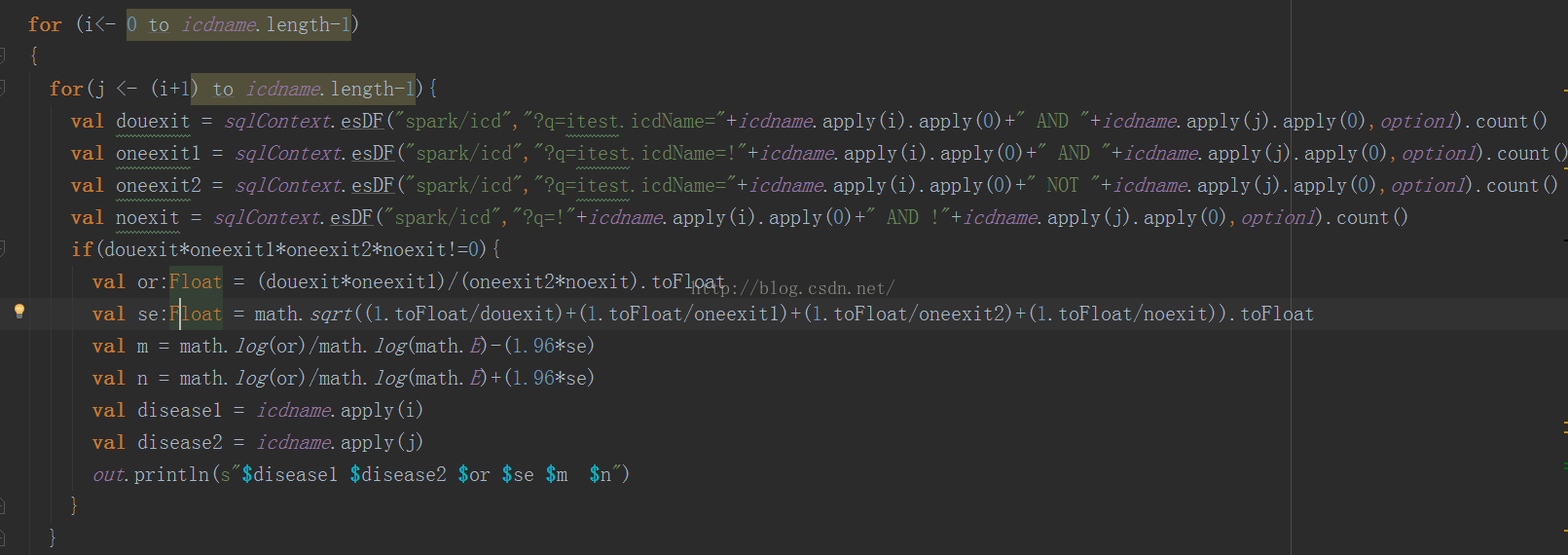
将数据加载进来,但是需要去基于lucene去检索。最后返回一个数量。
在这里,我们需要每两个病,判断四种不同情况下人群的数量,也就是:两种病都存在,一种存在一种不存在,一种不存在一种存在,两种都不存在四种情况下,人群的数量。在这里用了lucene的检索方式,?q=A AND B,?q=A NOT B,?q=NOT A AND B,?q=NOT A AND NOT B。
但是很不幸的,我的任务跑了还是26个小时左右。这里面,我们能够发现的问题是每一次都是进行全文检索,而且是使用query,这种方式在lucene里面是非常慢的。显然,这种方式是不能够满足我们的要求的。
Elasticsearch Client运行OR
人生总是在折腾,有探索才能有发现。
The most common way to get a client is by creating a
TransportClient that connects to a cluster.在这里,
我个人理解为Client是将我们的计算集群作为一个client端连接到Elasticsearch集群中,这样的方式下,对于取数据不需要进行传输,
速度会快很多。
这里申明一下我的集群环境:
Elasticsearch版本:2.3.4
- spark集群:1.4.1
- Scala版本:2.10.4
- lucene版本:5.5.0
在这里我们需要Elasticsearch client的jar包,一定要卸载和自己的Elasticsearch版本一致的jar包,要不然链接不到集群上去。这里贴一下可以下载的网址,我也是找了好久才找到的。建议保存。
下载完成之后,将该包加入到spark的环境变量里,也就是修改一下spark-env.xml中的配置。然后会需要将Elasticsearch中lib文件夹下的jar包加入到spark的环境变量里,这里主要是使用lucene的相关jar包。配置完成之后,需要重启spark。
这些配置完成之后,接下来初始化刻客户端,如下所示:

这些工作完成之后,就可以进行检索了。

这次,任务终于在四分钟跑完了。26个小时到4分钟。
所以,最终的建议就是使用client端去处理数据,不要使用esDF,检索数据太慢了。















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









