









ES的基本组成和es的优势以及搜索写入原理
前言
本文依照倒叙的方式介绍什么是elasticsearch,包含es的基本组成和es的优势以及写入搜索的流程
首先引入一个问题,如何从三段文本中快速找到包含关键词’caixukun’的记录?
id:1 I like caixukun
id:2 I like forward caixukun video
id:3 I follow caixukun footsteps
最直接的思路就是遍历所有的文本记录,然后判断是否包含关键词,最后返回文本的id
如果记录的条数有上亿条呢?或者十亿?百亿?
继续采用最初的思路全部遍历,先不说速度与乌龟相比如何,有没考虑过计算机的感受?cpu呢?内存呢?磁盘io?
所以当面对大量文本数据需要快速检索特定关键词(如"caixukun")时,逐一遍历每段文本显然效率低下。这种情况下,一种高效的解决方案是利用搜索引擎技术,例如 Elasticsearch,Elasticsearch 是一个基于 Lucene 的搜索引擎,专门设计用于处理和查询大规模数据
ElasticSearch的基本组成
倒排索引(Inverted Index)
倒排索引(Inverted Index)是一种用于文本搜索的数据结构,它将文档中的内容(例如单词或词组)映射到文档列表,该列表包含包含该单词或词组的所有文档。这样说比较笼统,以前言中的例子来说:
如何从三段文本中快速找到包含关键词’caixukun’的记录?
id:1 I like caixukun
id:2 I like forward caixukun video
id:3 I follow caixukun footsteps
首先我们对于文本记录进行切分,例如 “I like caixukun” 被切分为"I"、“like”、"caixukun"这三个部分,切分的这个动作就是分词,切分后每部分就是一个词项(term)
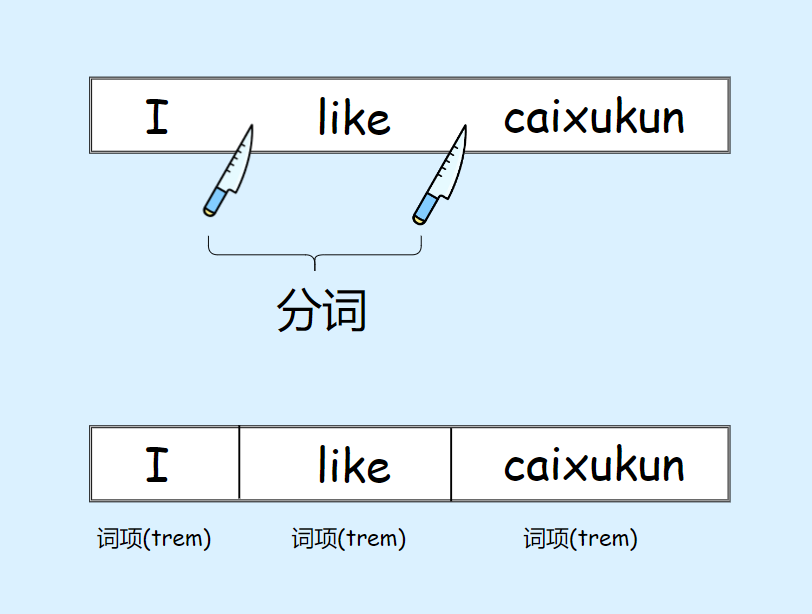
三条记录全部切分后,词项(term)与文档id的对应列表如下
| 词项 Term | 文本 id |
|---|---|
| I | 1, 2 |
| like | 1, 2 |
| caixukun | 1, 2, 3 |
| forward | 2 |
| video | 2 |
| follow | 3 |
| footsteps | 3 |
当我们需要搜索特定词项(如 “caixukun”)时,倒排索引可以显著提高搜索效率。但是考虑到文本的数量和词项的增多,直接线性遍历词项确实效率低下,时间复杂度为 O(N),其中 N 是词项的总数
为了优化这一过程,可以采用将词项按字典序从小到大排序的方法,并结合二分查找。这种优化可以将搜索特定词项的时间复杂度降低到 O(log N),这样可以快速定位到特定词项在倒排索引中的位置,进而快速获取该词项对应的文档列表
| 词项 Term | 文本 id |
|---|---|
| caixukun | 1, 2, 3 |
| follow | 3 |
| footsteps | 3 |
| forward | 2 |
| I | 1, 2 |
| like | 1, 2 |
| video | 2 |
Term Dictionary 是词项按字典序排列的集合,每个词项都唯一地标识了文档中出现的单词或短语。每个词项在 Term Dictionary 中的位置通常通过二分查找等方法进行快速定位,从而提高搜索效率
Posting List 则包含了每个词项在哪些文档中出现过的详细信息。除了文档 id 列表,Posting List 还记录了词项在每个文档中的词频(即出现次数)和词项在文本中的偏移量等信息。这些信息有助于搜索引擎确定文档的相关性,例如可以根据词频和词项在文本中的位置计算出文档的排名。
Term Dictionary(词项字典)和 Posting List(词项对应的文档 id 列表)这两部分就组成了倒排索引(Inverted Index)
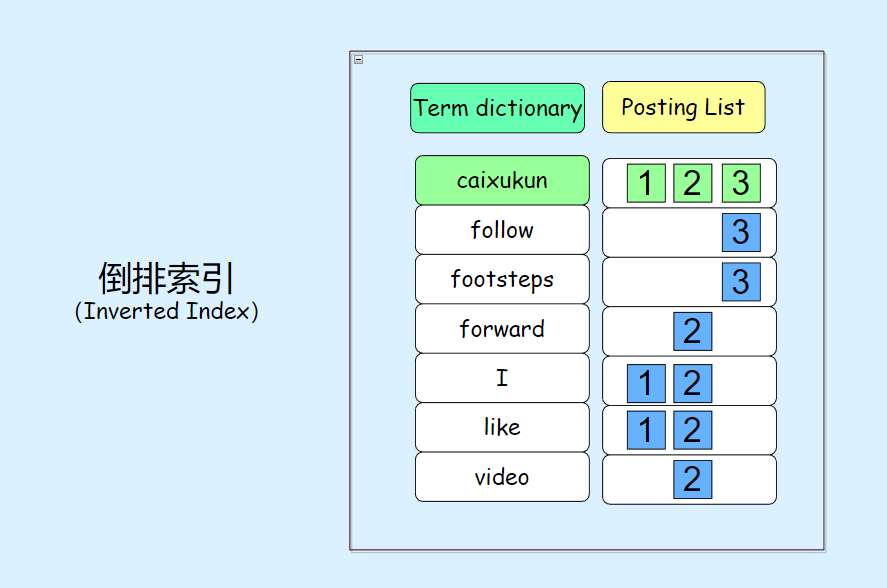
倒排索引面临的问题之一是 Term Dictionary 数据量庞大,因此无法完全存储在内存中而必须存储在磁盘上。然而,从磁盘检索数据通常较慢。为了优化这一过程,可以考虑使用 Term Index
词项索引(Term Index)
Term Index(词项索引)通常是指倒排索引中 Term Dictionary 的一部分。它是对 Term Dictionary 的一个索引结构,用于加速查找和访问倒排索引中词项信息
在倒排索引中,Term Dictionary 是按字典顺序存储的词项集合,通常存储在磁盘上并且其数据量较大,无法完全放入内存。为了有效地定位特定词项,通过使用 Term Index可以帮助快速定位到 Term Dictionary 中某个词项的位置,而不需要顺序扫描整个 Term Dictionary
通过 Term Index,搜索引擎可以在查询过程中快速确定 Term Dictionary 中某个词项的位置,然后进一步访问该词项的 Posting List,以获取相关的文档 id 列表和其他信息。这样可以显著提高搜索效率,减少了直接从磁盘读取 Term Dictionary 的开销和时间。
我们可以利用词项之间的共同前缀来节省空间,并提高搜索效率。通过提取部分词项的共同前缀,比如在 follow 和 forward 中的 fo,我们可以构建一个精简的目录树,其中存储了这些词项在磁盘上的位置信息(偏移量)。这个目录树结构体积小,适合放在内存中,被称为 Term Index。Term Index 可以显著提升搜索引擎的性能,因为它允许快速定位到磁盘上存储的 Term Dictionary 中特定词项的位置,避免了耗时的顺序扫描操作。
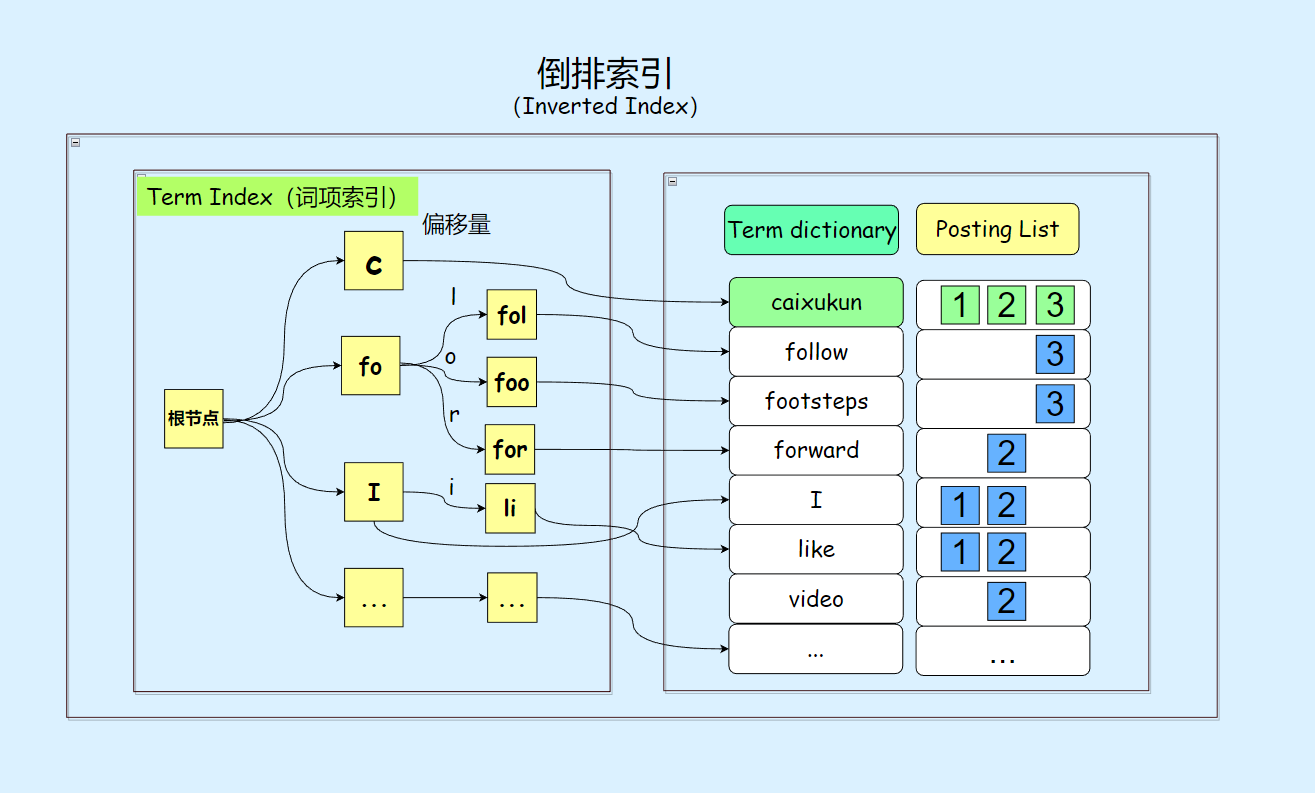
当我们需要查找某个词项的时候,只需要搜索 Term Index,就能快速获得词项在 Term Dictionary 中的大概位置。再跳转到 Term Dictionary,通过少量的检索,定位到词项内容
存储字段(Stored Fields)
定位到词项后,可以获取到对应的文档id,那么要如何根据id获取到原始的文档内容?
Stored Fields是搜索引擎中用于存储文档原始内容或其部分内容的机制。除了构建倒排索引用于搜索外,文档在索引期间会被以原样存储在这些字段中。这些字段包含文档的元数据如标题、作者、发布日期、URL,也可以包含文档的完整内容或部分内容。在搜索过程中,Stored Fields允许搜索引擎直接检索并返回文档的具体内容,无需重新解析和分析文档,从而提高检索效率。
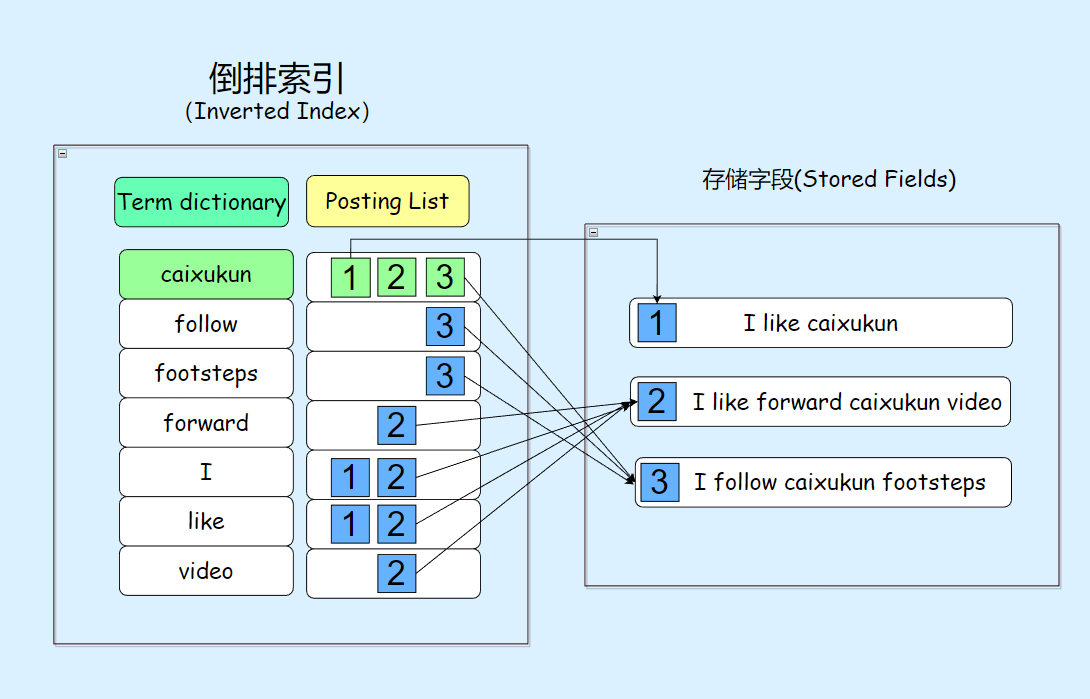
Doc Values
在一些场景中,用户经常需要按照特定字段对文档进行排序,比如按书目价格或书目题名排序。但是这些字段通常是分散存储在文档中的,这意味着在进行排序之前,我们需要先获取文档的存储字段,然后再提取所需的内部字段进行操作。尽管这种方法可行,但存在效率上的提升空间。为了优化这一过程,可以采用“空间换时间”的策略,构建一种列式存储的结构。这种结构将文档中分散存储的字段数据集中存放起来。当需要对某个字段进行排序时,只需一次性读取这些集中存放的字段数据,即可高效地执行排序操作。这种列式存储结构被称为 Doc Values
在 Elasticsearch 中,Doc Values 是默认用于排序、聚合和脚本字段的存储方式。当你需要对字段进行排序或聚合时,Elasticsearch 会自动使用 Doc Values,它用于存储和快速访问文档字段的数据
在搜索引擎中,每个文档(document)包含多个字段(field),例如标题、内容、作者等。为了进行有效的搜索和排序,需要能够快速访问和处理这些字段的数据。传统上这些数据存储在倒排索引(Inverted Index)中用于搜索。然而,倒排索引虽然适合搜索操作,但对于需要排序、聚合等操作可能不太高效
为了解决这个问题,Lucene 引入了 Doc Values 的概念。Doc Values 是一种以列式存储的方式,将文档字段的数据预先排序并优化存储,以便更快速地进行排序、聚合和检索操作。它们被存储在单独的数据结构中,并可以在内存或磁盘上进行有效的访问
示例: 假设我们有一个包含书籍信息的数据库表格,我们可以使用列存储来优化数据的存储和访问效率,展示书籍的基本信息:
| book_id | title | author | genre | price |
|---|---|---|---|---|
| 1 | The Great Gatsby | F. Scott Fitzgerald | Fiction | 12.99 |
| 2 | To Kill a Mockingbird | Harper Lee | Fiction | 10.99 |
| 3 | 1984 | George Orwell | Fiction | 9.99 |
| 4 | Pride and Prejudice | Jane Austen | Fiction | 11.99 |
在传统的行存储结构中,数据按行存储,每行表示一个完整的记录(例如一本书的所有信息)。然而,在列存储中数据按列存储,每列包含相同类型的数据
下面是这个表格在列存储结构下的简化示意:
- book_id 列: [1, 2, 3, 4]
- title 列: [“The Great Gatsby”, “To Kill a Mockingbird”, “1984”, “Pride and Prejudice”]
- author 列: [“F. Scott Fitzgerald”, “Harper Lee”, “George Orwell”, “Jane Austen”]
- genre 列: [“Fiction”, “Fiction”, “Fiction”, “Fiction”]
- price 列: [12.99, 10.99, 9.99, 11.99]
在这个列存储结构中,每个列都存储了表中某个字段的所有值。这种方式带来了以下优势:
- 查询效率:对于分析性查询(如聚合、过滤、排序),列存储能够更快速地访问和处理大量数据,因为查询通常只需访问少量列而不是整行
- 压缩和存储效率:每列仅存储相同数据类型的值,因此可以更有效地进行数据压缩和存储管理
- 扩展性:列存储通常更适合于处理大数据集和高并发查询,特别是在数据仓库和分析工作负载中
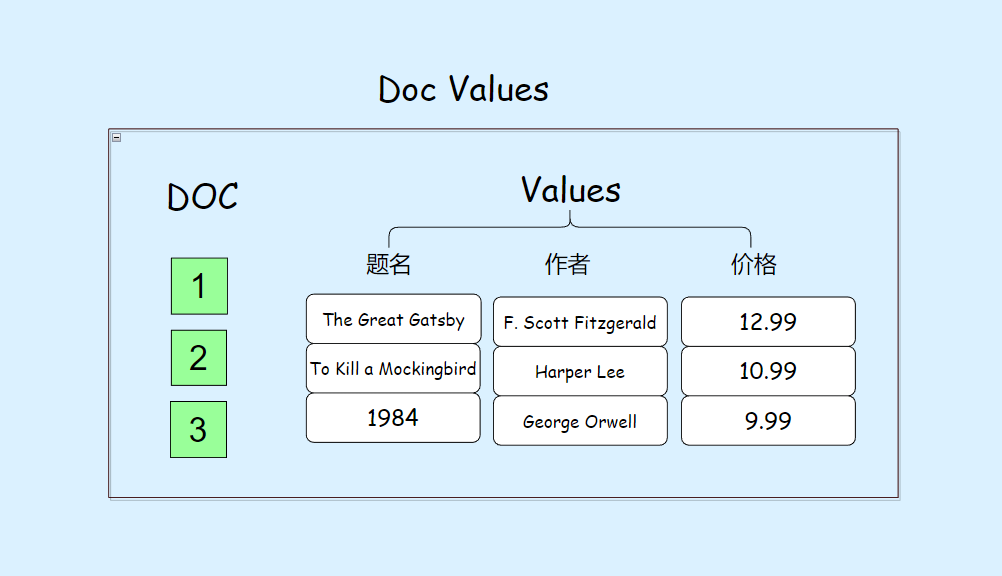
段(segment)
在上文中,我们讨论了四种关键的数据结构,它们在搜索引擎中起着重要作用:
- 倒排索引:用于高效地执行搜索操作
- Term Index:加速搜索过程的辅助索引
- Stored Fields:存储文档的原始内容信息
- Doc Values:用于排序和聚合结果
这些结构合作形成了一个称为“段(segment)”的复合文件,它代表搜索引擎的最小功能单元,能够提供完整的搜索功能
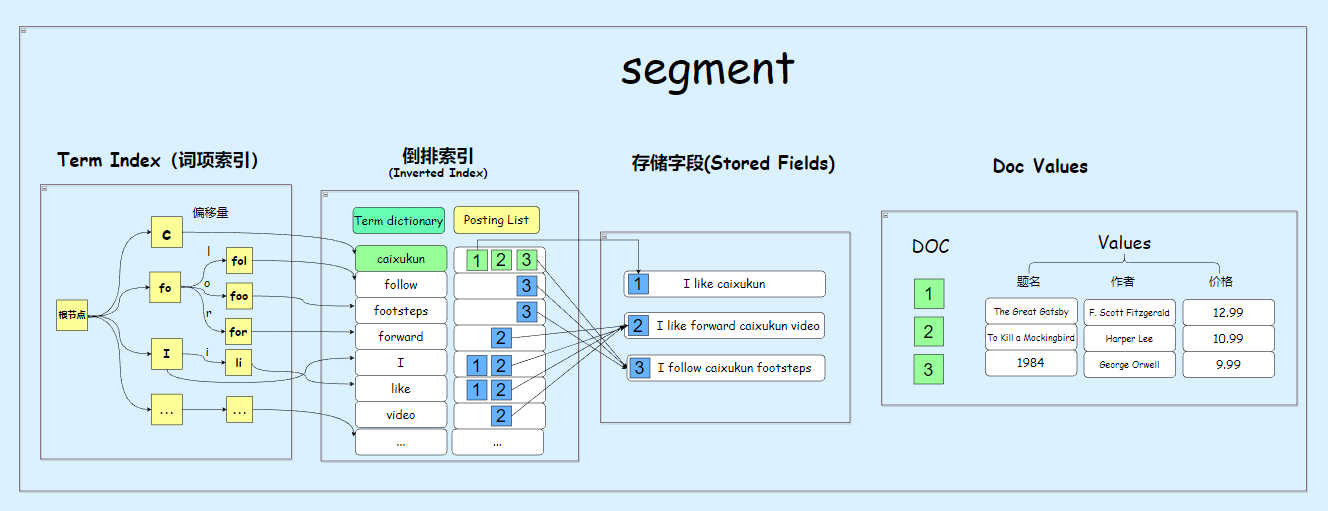
lucene
当处理多个文档生成一个 segment 时,如果我们允许在该 segment 上继续写入新文档,就必须频繁更新 segment 内的多个数据结构,这会降低并发读写的性能。为了解决这个问题,我们可以采用一种策略:一旦生成了一个 segment,就不再对其进行修改。而是在需要写入新文档时,生成一个全新的 segment。
优点:
- 读写分离:老的 segment 被保留用于读取,不需要担心并发写入时的数据一致性问题,从而提高了读操作的性能
- 写操作安全:每次生成新的 segment 时,可以在其中进行新文档的写入操作,而不会影响到老的 segment
- 并发性能:由于不再涉及对已生成 segment 的修改,避免了多个写入操作之间的竞争,从而提升了并发写入的性能和稳定性
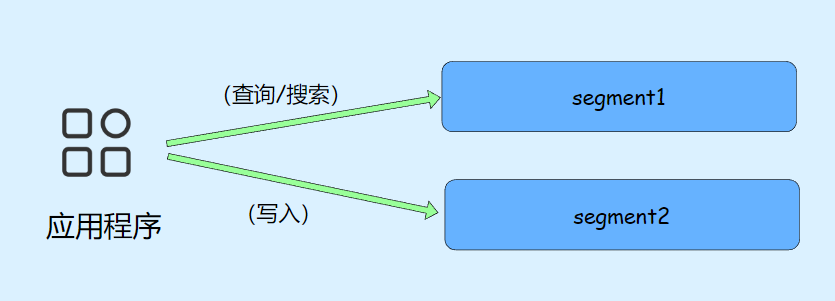
当有多个 segment 存在时,我们需要确保搜索操作可以同时读取多个 segment。这可以通过搜索系统的索引结构和查询处理逻辑来实现。一种常见的方法是将所有 segment 的元数据(比如索引信息)组织到一个整体索引中,这样搜索时可以并行地查询多个 segment,然后合并结果。
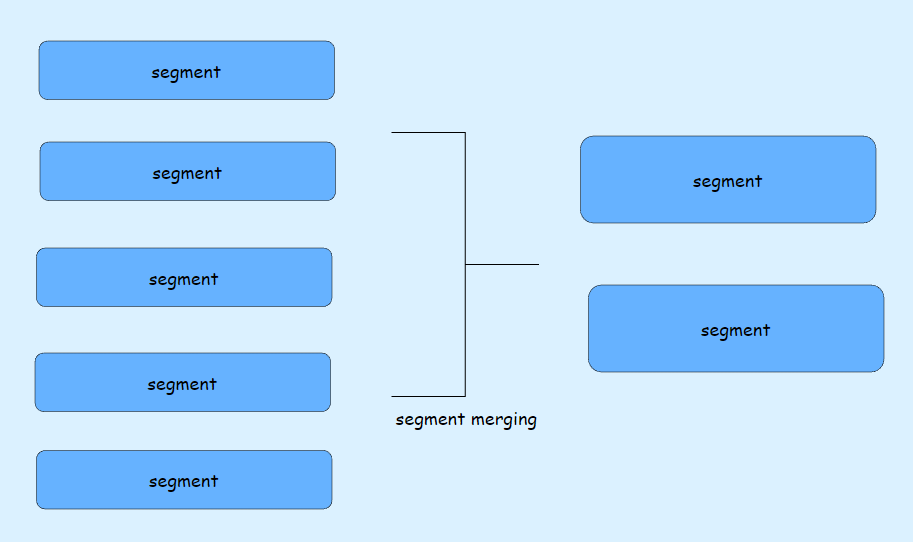
然而,随着时间推移和数据量增加,会导致 segment 文件数量增多,可能导致文件句柄(file handle)被耗尽的问题。这时候,我们可以采取段合并(segment merging)的方法来解决这个问题。段合并是指定期将多个小的 segment 合并成一个较大的 segment。这样做有几个好处:
- 文件管理:减少了打开的文件数量,降低了系统负担,延长了文件句柄的使用寿命。
- 性能优化:减少了并发读取时涉及的 segment 数量,提高了搜索操作的效率。
- 空间利用:有效利用存储空间,避免了大量小文件的存在。
段合并通常在后台异步进行,可以根据系统负载和存储使用情况来决定合并的频率和策略。这样可以确保系统在长期运行中保持高性能和可靠性,同时有效地管理存储资源。
在这里,前面提到的几个部分共同构成了一个单机文本检索库,即开源的基础搜索库Lucene。许多知名搜索引擎都基于Lucene构建,比如Elasticsearch。然而,Lucene本身在一些方面显得有些简陋,比如在高性能、高扩展性和高可用性方面并不突出。现在让我们来探讨如何对Lucene进行优化
ES的高性能、高扩展与高可用
Elasticsearch 是一个开源的搜索引擎和分布式文档存储数据库。它被设计用来快速而且准确地存储、搜索和分析大量数据。Elasticsearch主要有以下几个主要优势:
- 强大的全文搜索: 它不仅支持基本的关键词搜索,还可以处理复杂的查询,如短语搜索、模糊搜索和聚合查询。这使得读者可以更轻松地找到他们需要的信息
- 分布式架构: Elasticsearch 能够分布式存储数据,这意味着它可以在多台服务器上运行,处理大量数据而不影响性能。这对于处理大型博客、大量访问和数据增长非常重要
- 实时数据分析: Elasticsearch 提供强大的实时分析能力,可以帮助你了解博客的读者行为、流量趋势和文章受欢迎程度。你可以通过聚合分析功能来生成报告和可视化数据。
- 易于扩展和集成: Elasticsearch 是基于 RESTful API 构建的,易于与其他应用程序集成,如博客平台、内容管理系统(CMS)和用户界面。它支持多种编程语言和开发工具
高性能
Lucene作为一个搜索库,能够处理大量数据的写入,并提供搜索功能给多个调用方同时使用。然而,如果多个调用方同时读写同一个Lucene索引,就会导致资源竞争,造成等待时间的浪费。为了解决这个问题,我们可以采用以下策略:
首先,我们可以根据数据的类型对写入的数据进行分类,例如将社会新闻和财经新闻数据分为两类,并为每一类分别创建一个Index Name。接着,针对每个Index Name增加多个Lucene索引实例,每个实例专门用于处理对应类别的数据。这样一来,不同类别的数据会被写入到不同的Lucene索引中。
在读取数据时,根据需要指定相应的Index Name进行搜索。通过这种方式,可以有效降低单个Lucene索引的压力,提高系统的并发处理能力,从而减少资源竞争和等待时间的问题。
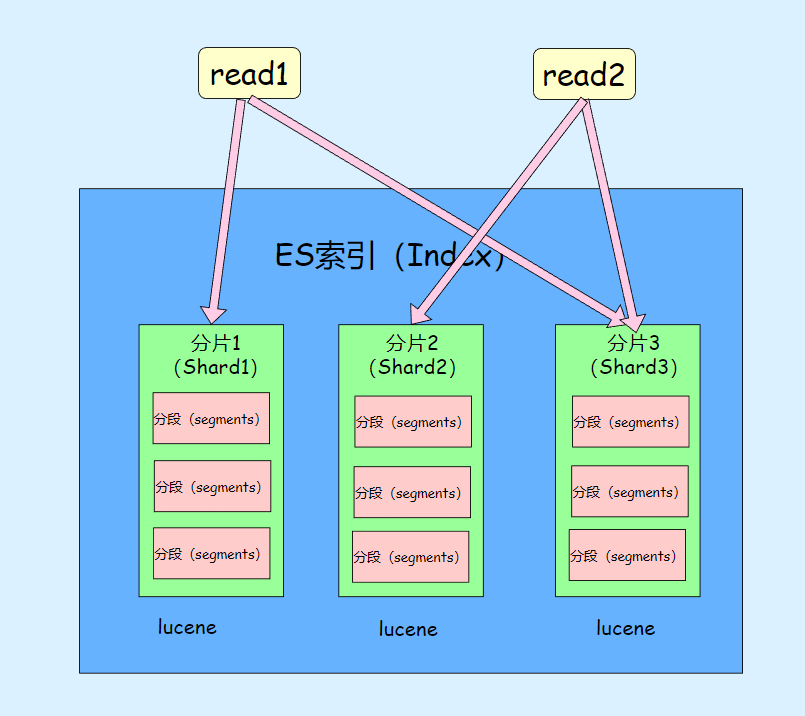
但单个 Index Name 内数据依然可能过多,于是可以将单个 Index Name 的同类数据,拆成好几份,每份是一个 shard 分片,每个 shard 分片本质上就是一个独立的 lucene 库。这样我们就可以将读写操作分摊到多个 分片 中去,大大降低了争抢,提升了系统性能。
高扩展性与高可用
分布式架构
Elasticsearch 是一个基于分布式系统设计的搜索引擎和分析引擎。它的分布式架构使得系统能够水平扩展,即通过增加节点来增强性能和容量。每个节点在集群中独立运行,并且通过协调节点之间的工作来实现高效的数据处理和查询操作。举例来说:
- 增加节点: 当需要处理更多的数据或者提高搜索性能时,可以简单地增加新的节点到现有的Elasticsearch集群中。新节点的加入会自动帮助分担负载,从而提升整体的吞吐量和响应能力。
- 数据分布: Elasticsearch 将索引分割成多个分片(shards),每个分片可以分布在不同的节点上。这种分片和副本的设计使得数据能够水平扩展存储,而且即使某个节点或分片发生故障,系统依然能够保持可用性和数据完整性。
分片和副本
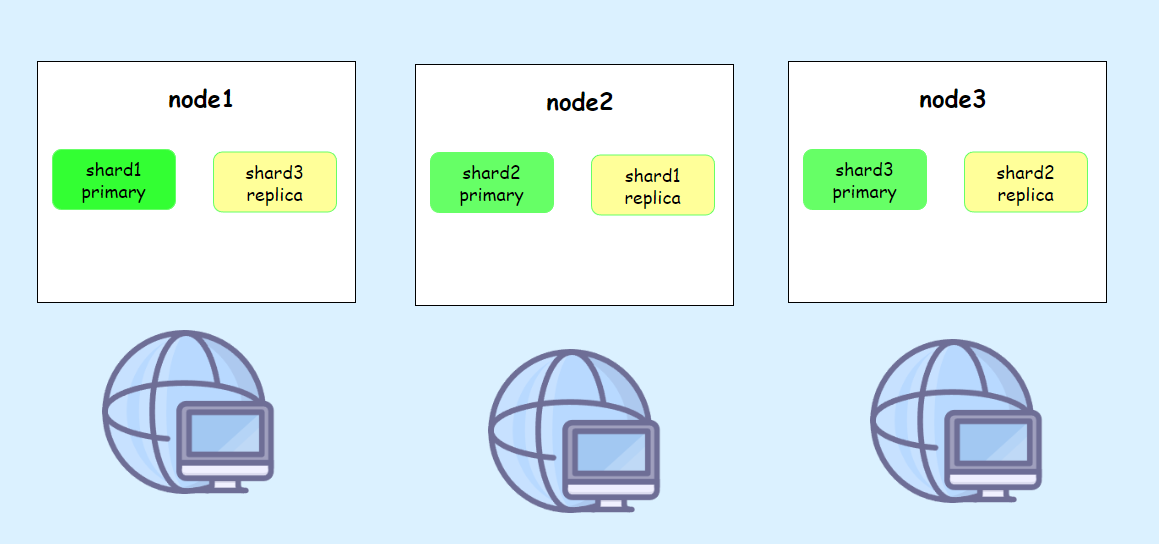
分片和副本是 Elasticsearch 的核心概念,它们为高可用性和容错性提供了基础:
- 数据分片: 每个索引可以被分成多个主分片(primary shard)。主分片可以分布在不同的节点上,这样每个节点就只需管理一部分数据。例如,一个有5个主分片的索引,每个节点可能只需负责其中的一个或多个主分片。
- 副本: 每个主分片可以有零个或多个副本(replica)。副本不仅用于提供数据冗余和故障恢复能力,还能够增加读取操作的并发性能。Elasticsearch 会自动将副本分布在不同的节点上,以确保即使某些节点宕机,数据依然可用。
ES 的写入与搜索流程
ES 的写入流程
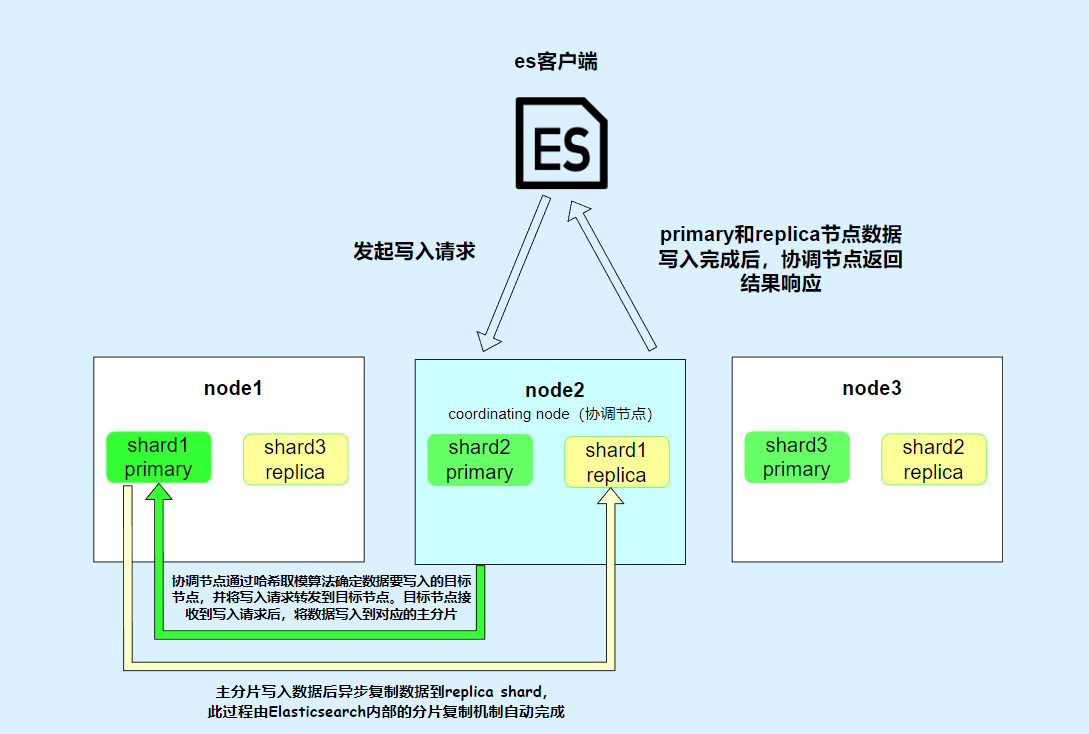
- • 当客户端应用发起数据写入请求,请求会先发到集群中协调节点。
- • 协调节点根据 hash 路由,判断数据该写入到哪个数据节点里的哪个分片(Shard),找到主分片并写入。分片底层是 lucene,所以最终是将数据写入到 lucene 库里的 segment 内,将数据固化为倒排索引和 Stored Fields 以及 Doc Values 等多种结构。
- • 主分片 写入成功后会将数据同步给 副本分片。
- • 副本分片 写入完成后,主分片会响应协调节点一个 ACK,意思是写入完成。
- • 最后,协调节点响应客户端应用写入完成。
ES 的搜索流程
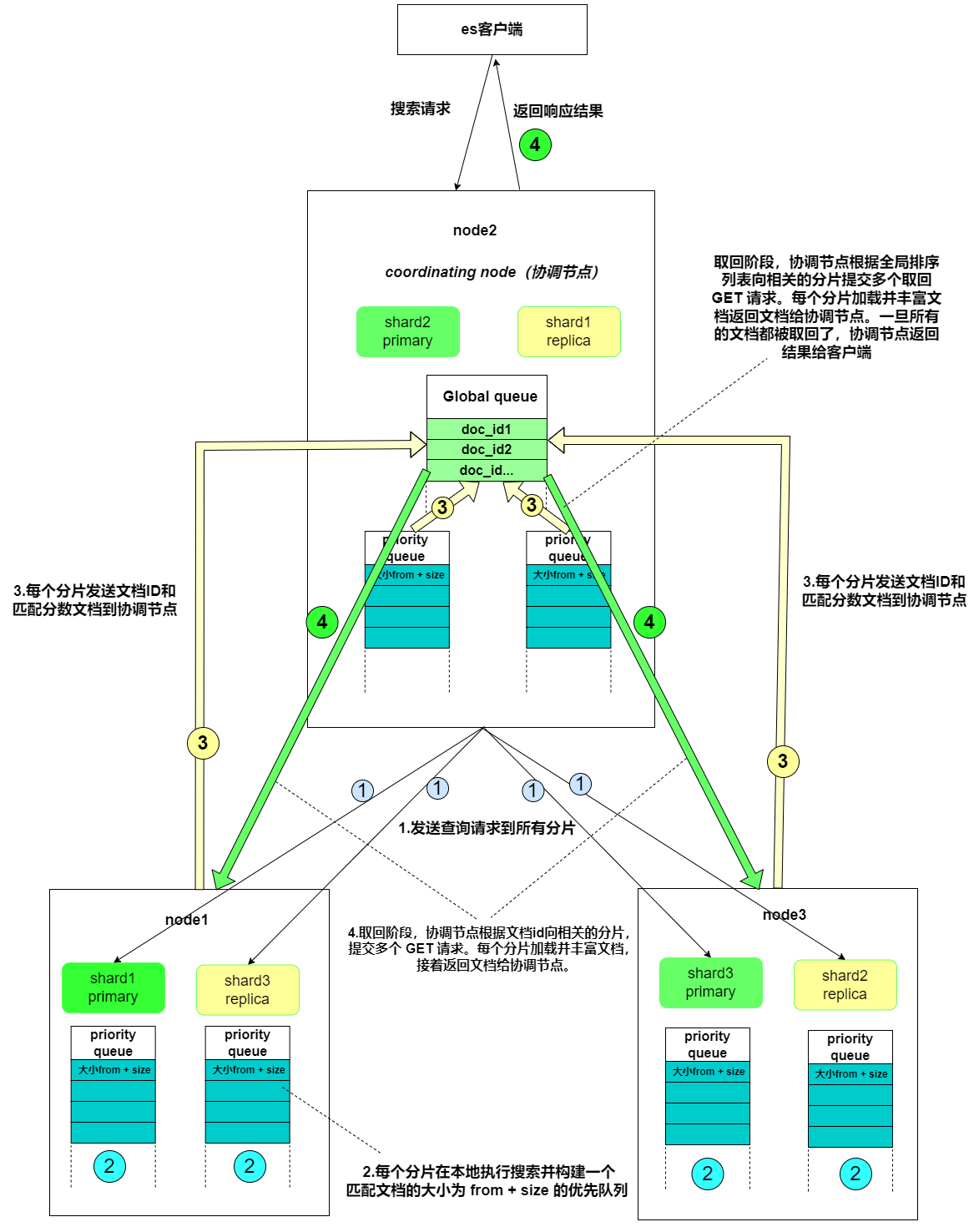
ES 的搜索流程分为两个阶段:分别是查询阶段(Query Phase)和获取阶段(Fetch Phase)
- 搜索系统通常采用两阶段查询(query_then_fetch):首先在第一阶段查询到匹配的文档标识符(DocID),然后在第二阶段查询这些标识符对应的完整文档。
- 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
- 每个分片返回各自优先队列中 所有文档的 ID 和排序值(例如 _score) 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 接下来就是获取阶段(Fetch Phase),协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
总结
- Lucene: Lucene 是 Elasticsearch 的底层技术,用于单机文本检索。它将索引数据划分为多个段(segments),每个段包含倒排索引、Term Index、Stored Fields 和 Doc Values 等组件,这些组件共同构成了实现全面搜索功能的基本单元。
- 索引: Elasticsearch 将数据组织存储在不同的索引名称下。每个索引名称代表一组相关的数据,通过索引名称的分类和管理,使得数据的检索和访问更加高效。
- 分片(Sharding): 为了提高系统的性能和可伸缩性,Elasticsearch 引入了分片机制。分片将每个索引内的数据划分为多个较小的分片,每个分片可以独立地存储在集群的不同节点上。这种分布式存储和并行处理能力,有效地减少了每个节点上的负载,从而提升了整体系统的吞吐量和响应速度。
- 高性能和高可用性:Elasticsearch利用分片和副本管理数据,实现高性能和高可用性,同时支持动态节点扩展和自动负载平衡,确保系统在大规模环境下稳健运行
- 扩展性: Elasticsearch 的节点可以根据需要进行动态扩展和缩减。通过增加节点数量,可以水平扩展集群的处理能力,以应对数据量增长或访问压力增加的情况,从而确保系统能够稳定运行并提供良好的性能表现。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











