







基本介绍
Zookeeper可以看成是一个拥有文件系统特点的分布式数据库,为分布式系统提供一致性协调服务。可以用来作为统一命名服务,集群管理,分布式配置管理组件来使用。
通常来说,Zookeeper以集群形式部署,包含多个server节点, 其中一个leader,多个follower。
数据模型
Zookeeper的数据模型结构与unix文件系统类似,整体上可以看作是一棵树,每个节点是一个ZNode。每个ZNode可以通过其路径唯一标识。
与文件系统不同的是,zookeeper的每个节点既可以当成目录,也可以看成文件,因为节点上可以存储少量的内容。节点数据默认最大值为1M,可以通过配置修改,但通常不建议在ZNode上存储大量数据。
Zookeeper的文件结构如下图所示:
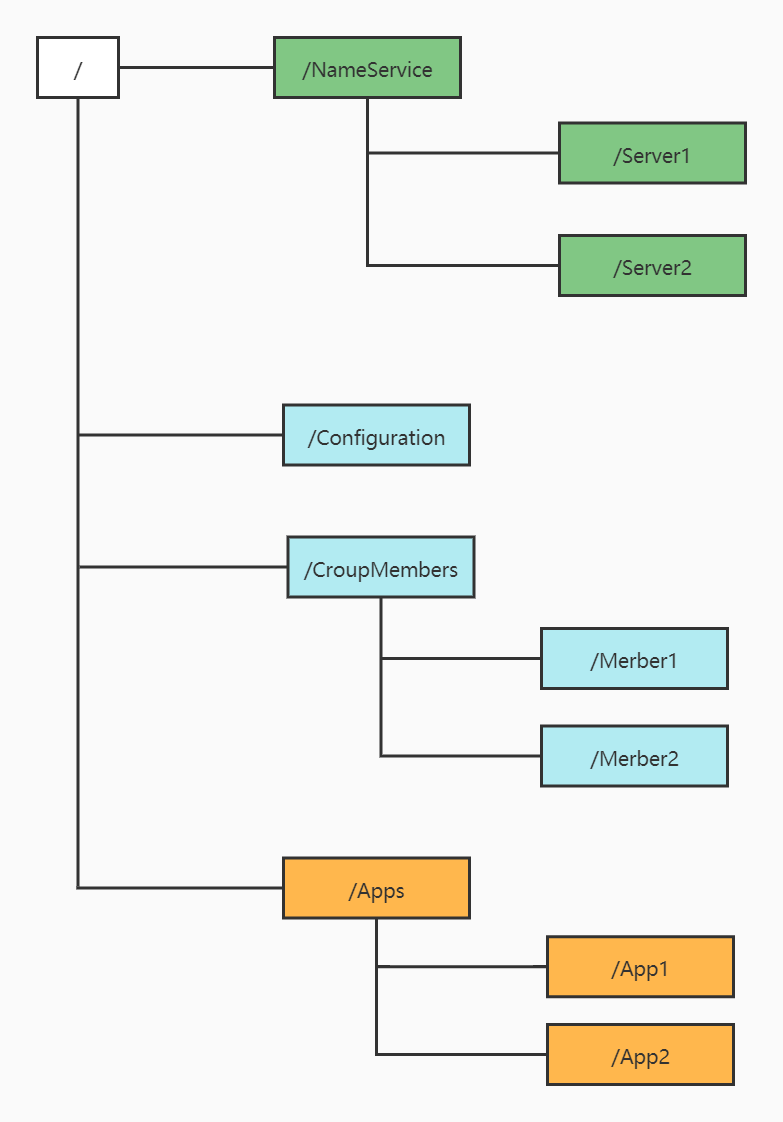
ZNode根据本身的特性可以分为四类:
- 持久化节点
客户端与zookeeper断开连接后,该节点依旧存在。 - 持久化顺序节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号。 - 临时节点
客户端与zookeeper断开连接后,该节点被删除。 - 临时顺序节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
通知机制
客户端注册监听它关心的节点,当节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
zookeeper安装和使用
从清华镜像站下载zookeeper3.6.3版本,地址:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.6.3.

下载到本地并解压缩后(注意下载3.6.3-bin.tar.gz),进入zk目录修改配置文件名:
cp conf/zoo_sample.cfg conf/zoo.cfg
接着进入bin目录启动服务端:
./zkServer.sh start
服务端启动后,继续启动客户端:
./zkCli.sh
就进入客户端命令行了。
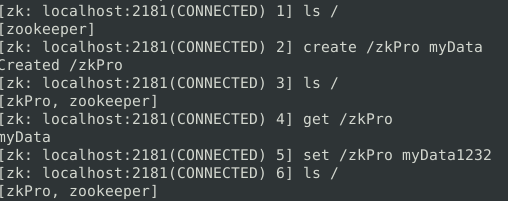
简单的创建节点,查看节点,设置节点数据的操作如下:
Java访问zookeeper
先创建一个节点:

在代码中引入maven依赖包:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
创建一个简单demo来监听zk节点数据的变更:
public class ZookeeperProSync implements Watcher {
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private static ZooKeeper zk = null;
private static Stat stat = new Stat();
public static void main(String[] args) throws Exception {
//zk path
String path = "/username";
// connect to zk and register a listener
zk = new ZooKeeper("127.0.0.1:2181", 5000, new ZookeeperProSync());
// wait for zk connected
connectedSemaphore.await();
System.out.println(new String(zk.getData(path, true, stat)));
Thread.sleep(Integer.MAX_VALUE);
}
@Override
public void process(WatchedEvent watchedEvent) {
if (Event.KeeperState.SyncConnected == watchedEvent.getState()) {
if (Event.EventType.None == watchedEvent.getType() && null == watchedEvent.getPath()) {
connectedSemaphore.countDown();
} else if (watchedEvent.getType() == Event.EventType.NodeDataChanged) {
try {
System.out.println("config has changed, new value is " + new String(zk.getData(watchedEvent.getPath(), true, stat)));
} catch (Exception e) {
}
}
}
}
}
原始的节点配置数据为howe,通过set指令将其修改为howee。输出结果如下:

集群部署
在一台机器上模拟集群环境来安装,复制zoo.cfg文件为zoo1.cfg,zoo2.cfg,zoo3.cfg。
修改zoo1.cfg文件, 主要是数据路径和节点配置:
# vim conf/zoo-1.cfg
dataDir=/tmp/zookeeper-1
clientPort=2181
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
接着修改zoo2和zoo3,但只需要修改dataDir和clientPort,数据路径分别为zookeeper-2,zookeeper-3,端口分别为2082和2083。
其他配置项说明:
- tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔。
- initLimit:Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是zk服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20 秒。
- syncLimit:Leader 与 Follower 之间进行数据同步时,请求和应答的时间长度,单位是tickTime,总的时间长度就是 5*2000=10秒。
- dataDir:Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
- server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是当集群中的 Leader 服务器宕机时,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。本文这里是伪集群的配置方式,B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,要给它们分配不同的端口号。
当启动一个服务器时,我们需要知道启动的是哪个服务器。一个服务器通过读取data目录下一个名为myid的文件来获取服务器ID信息。通过以下命令来创建这些文件创建三个文件夹/tmp/zookeeper-1,/tmp/zookeeper-2,/tmp/zookeeper-2,也就是上面设置的dataDir目录。在每个目录中创建文件myid 文件,写入当前实例的server id:
# cd /tmp/zookeeper-1
# vim myid
1
# cd /tmp/zookeeper-2
# vim myid
2
# cd /tmp/zookeeper-3
# vim myid
3
启动三个实例:
# bin/zkServer.sh start conf/zoo1.cfg
# bin/zkServer.sh start conf/zoo2.cfg
# bin/zkServer.sh start conf/zoo3.cfg
检测集群状态:
第一次启动的时候最开始始终有一个节点是standalone单机模式,后来全部退出重新启动之后就正常了。
原子广播协议
Zookeeper的核心是原子广播,通过原子广播协议(ZAB)保证各个server之间的数据同步。Zab协议有两种模式,分别是恢复模式和广播模式。
当服务启动或者在leader崩溃后,zab进入恢复模式。在恢复模式中,每个节点都发起投票选举leader。当超过半数节点投票同一个节点,那这个节点就选作为了leader。当leader被选举出来,并且大多数节点完成了和leader的状态同步之后,恢复模式就结束了。随后就进入广播模式,接受客户端的请求,并作为事务来处理。
恢复模式
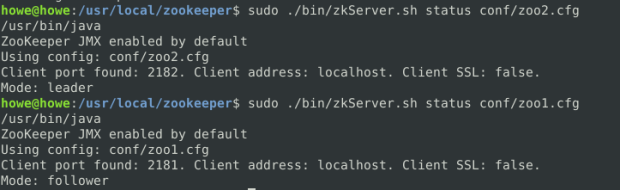
当zookeeper的server节点启动时,先给自己投票,选票里包含server id和zxid(事务id)。当两个以上节点启动后,节点之间还会彼此交换投票信息,并比较当前的投票,先比较事务id,再比较server id,取id较大的投票为leader投票。
举个例子说明,在上文介绍zk集群部署时,三个server节点的启动顺序分别为zoo1,zoo2,zoo3,则zoo1和zoo2分别先投给自己,然后交换彼此的投票,比较投票信息里的server id和zxid,刚启动时zxid相同,zoo2的server id为2,比zoo1的大,因此zoo1会更改投票,将自己的票投给zoo2。这样zoo2就获得了两票,超过总节点数的一半,因此zoo2将成为leader,zoo1成为follower,如下图所示:
再继续启动zoo3,由于集群中已经有了leader节点,此时zoo3就以follower角色加入集群中。
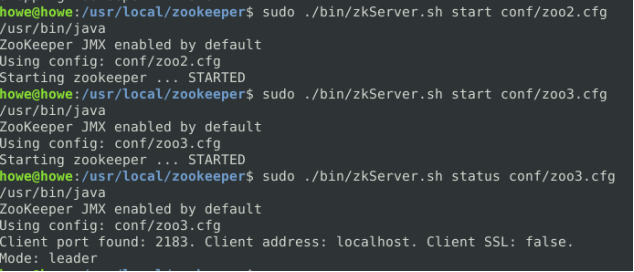
如果以zoo2,zoo3,zoo1的顺序启动,可以推测出zoo3将作为leader节点。实际也是如此:
广播模式
Zookeeper集群进入广播模式后,就可以接受客户端请求,并进行事务处理。
当然并不是所有的请求都是事务性请求,比如读请求,不涉及数据的修改,直接从接受请求的节点返回要读取的数据即可。
真正的事务性请求是写请求。客户端发出一个写请求之后,接受请求的节点会将这个请求转发给leader节点,leader节点再通过两阶段提交的方式来提交事务:首先通知所有的follower进行事务预提交,当超过一半的follower返回确认之后,才真正的提交事务。
参考资料
[1]. https://blog.csdn.net/java_66666/article/details/81015302















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









