







环境准备
安装 hadoop,参照:https://www.jianshu.com/p/9c8a0f7b98cf
安装hive,参照:https://www.jianshu.com/p/ed4c2852754c
说明:本文测试环境为单机,而非集群环境。
CLI连接
安装好之后,可通过客户端,通过hive命令直接连接,并进行相关操作:
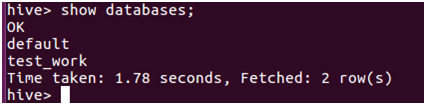
HiveServer2/beeline连接
CLI连接时,输入hive实际上是在启动的时候执行:hive --service cli。
而在beeline连接时,需通过:hive --service hiveserver2来开启服务。
启动之后通过jps命令可以查看到名为RunJar的进程。
但这种启动方式在终端关闭后,服务随之关闭。最好是通过后台服务的方式启动:
nohup hiveserver2 1>[标准日志输出路径] 2>[错误日志输出路径] &
nohup表示在终端关闭时服务不挂起,1表示标准日志输出,2表示错误日志输出,&是启动为后台服务所必须的。
hiveserver2服务启动之后,就可以通过beeline客户端去连接了。
beeline在hive的bin目录下。连接命令为:

-u 参数为元数据库的连接信息,-n 指定用户名和密码。
连接成功后,就可以执行数据库操作了:
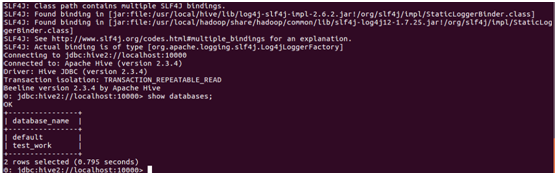
创建数据库的方式跟mysql一样:
create database test_work;
use test_work;
创建user_info表:
create table user_info(id int, name string, age int, occupation string) row format delimited fields terminated by '\t' ;
然后导入数据(需要有文件权限):
load data inpath '/tmp/users/data.txt' overwrite into table user_info;
python+beeline+hql
在代码里该如何通过命令行方式来调用hql执行hive的数据库操作呢?demo如下:
# coding=utf-8
import os
import sys
import logging
import time
import tempfile
import commands
def get_user():
logging.basicConfig(stream=sys.stdout,
level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s')
ts = str(int(time.time()))
work_dir = os.path.join(tempfile.gettempdir(), 'users')
output_dir = os.path.join(work_dir, ts)
if not os.path.exists(work_dir):
os.mkdir(work_dir)
try:
logging.info("start to execute hive")
get_user_from_dp(output_dir) # 从hive中获取数据
tmp_result = load_data(output_dir)
print tmp_result
if os.path.exists(output_dir):
os.system('rm -rf ' + output_dir)
except Exception, e:
logging.info(e)
def get_user_from_dp(output_dir):
if not (os.path.exists(output_dir) and os.path.isdir(output_dir) and os.listdir(output_dir) != []):
'''hql'''
hql = '''insert overwrite local directory '{output_dir}' row format delimited fields terminated by '\\t' stored
as textfile select id, name from test_work.user_info;!q'''.format(output_dir=output_dir)
hive_cmd(output_dir, hql) # 执行hql脚本
return output_dir
def hive_cmd(output_dir, cmd):
file_name = 'balance_%s.hql' % os.path.basename(output_dir)
file_path = os.path.join(os.path.dirname(os.path.abspath(output_dir)), file_name)
with open(file_path, 'w') as f:
f.write(cmd)
'''获取hive2 Server'''
server = '''HADOOP_CLIENT_OPTS="-Djline.terminal=jline.UnsupportedTerminal" /usr/local/hive/bin/beeline -u 'jdbc:hive2://localhost:10000' -n 'hadoop' -f {path} '''.format(path=file_path)
os_cmd(server)
os.remove(file_path)
def os_cmd(cmd):
(s, o) = commands.getstatusoutput(cmd)
if s != 0:
raise Exception('error code %s: %s msg: %s' % (s, cmd, o))
return s, o
def load_data(output_dir):
result = []
separator = '\t'
for file_name in os.listdir(output_dir):
file_path = os.path.join(output_dir, file_name)
with open(file_path, 'r') as f:
for line in f:
line = line.strip('\n')
if line.strip() == 0:
continue
items = line.split(separator)
if len(items) < 2:
continue
id, author = items[0], items[1]
result.append((id, author))
os.remove(file_path)
return result
if __name__ == '__main__':
get_user()
print 'finish'
在本例中,先将hql语句写入脚本文件/tmp/users/balance_xxx.hql(xxx为时间戳)。通过命令行方式建立起hive的数据库连接,并执行hql,将结果输出到/tmp/users/xxx目录下。然后读取查询到的结果,进行处理。
注意tmp/users文件夹的权限,当权限不足时可能会报错: Error: Error while compiling
statement: FAILED: IllegalStateException Cannot create staging
directory 'file:/tmp/users/xxxx















 4532
4532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









