







目录:
大型分布式网站架构设计与实践(1)
大型分布式网站架构设计与实践(2)
大型分布式网站架构设计与实践(3)
大型分布式网站架构设计与实践(4)
大型分布式网站架构设计与实践(5)
4 系统稳定性
系统上线后,可能会发生各种各样的运行问题。如依赖的应用宕机、程序bug、线程死锁、黑客攻击、负载过高等。发生了问题如何快速定位,如何最大程度地保证线上系统的稳定性,都是本章将要探讨的问题。
4.1 在线日志分析
在线日志分析是出现问题时最常用的问题分析方式。日志中包含了程序在遇到异常情况所打印的堆栈信息。通过异常堆栈可以定位到产生问题的代码行;通过访问IP和请求url参数,排查是否遭到攻击;通过应用的响应时间、垃圾回收,以及系统load来判断系统负载,是否需要增加机器;通过线程dump,判断是否死锁及线程阻塞的原因;通过GC日志,对系统代码和JVM内存参数进行优化,减少GC次数与stw时间,优化应用响应时间。
日志分析命令和脚本网上资料很多,不展开详述。
4.2 集群监控
成熟稳健的系统往往需要对集群运行时的各个指标进行收集,如系统的load,CPU利用率,I/O繁忙程度,网络traffic,内存利用率,应用心跳等,对这些信息就行实时监控,如发现异常情况能够第一时间通知到相应的开发和运维人员进行处理。
4.2.1 监控指标
Load
系统的load是指特定时间间隔内运行队列中的平均线程数。每个cpu的核都维护了一个运行队列,系统的load主要由运行队列来决定。假设一个CPU有8核,运行的应用程序启动了16个线程且都处于运行状态。在平均分配的情况下,每个CPU的运行队列中就有2个线程在运行。假设这种情况维护了1分钟,则这一分钟内系统的load就是2。Load值越大,意味着系统的CPU越繁忙,每个线程获取CPU时间的间隔也越大。一般来说CPU的活动线程数不大于3是正常的,大于5表示系统负载高。
使用uptime可以查看系统的load:
uptime命令可以查看服务器已经运行了多久,当前登录用户有多少,服务器在过去的1、5、15分钟的系统平均负载值。

CPU
在linux系统下, CPU的时间消耗主要在这几个方面,即用户进程、内核进程、中断处理、I/O等待、Nice时间、丢失时间、空闲等几个部分,而CPU的利用率则为这些时间所占总时间的百分比。通过top | grep Cpu命令可以查看CPU的消耗情况:

- 用户时间(us)表示CPU执行用户进程所占用的时间,通常情况下希望us的占比越高越好。
- 系统时间(sy)表示CPU在内核态所花费的时间,sy的占比较高通常意味着系统在某些方面设计的不合理,比如频繁的系统调用导致的用户态和内核态的频繁切换。
- Nice时间(ni)表示系统在调整进程优先级的时候所花费的时间。
- 空闲时间(id)表示系统处于空闲期,等待进程运行所占用的时间。
- 等待时间(wa)表示CPU在等待I/O操作所花费的时间,系统不应该花费大量的时间来进行等待。
- 硬件中断处理时间(hi)表示系统处理硬件中断所占用的时间。
- 软件中断处理时间(si)表示系统处理软件中断所占用的时间。
- 丢失时间(st)表示被强制等待虚拟CPU的时间。如果st占用较高,则表示当前虚拟机与该宿主上的其他虚拟机间的CPU征用较为频繁。
按1可以显示全部CPU的利用率。
其他监控指标有磁盘剩余空间,网络traffic,磁盘I/O,内存使用,qps,rt,GC等等,这里不详细讲述。这些指标都从不同角度反映了系统当前的运行情况。当然,在实际中不可能通过人工的方式一个个去分析,而是通过一些监控系统来统一监控和观察系统当前的运行情况,如APM(Application Performance Manager)工具PinPoint:
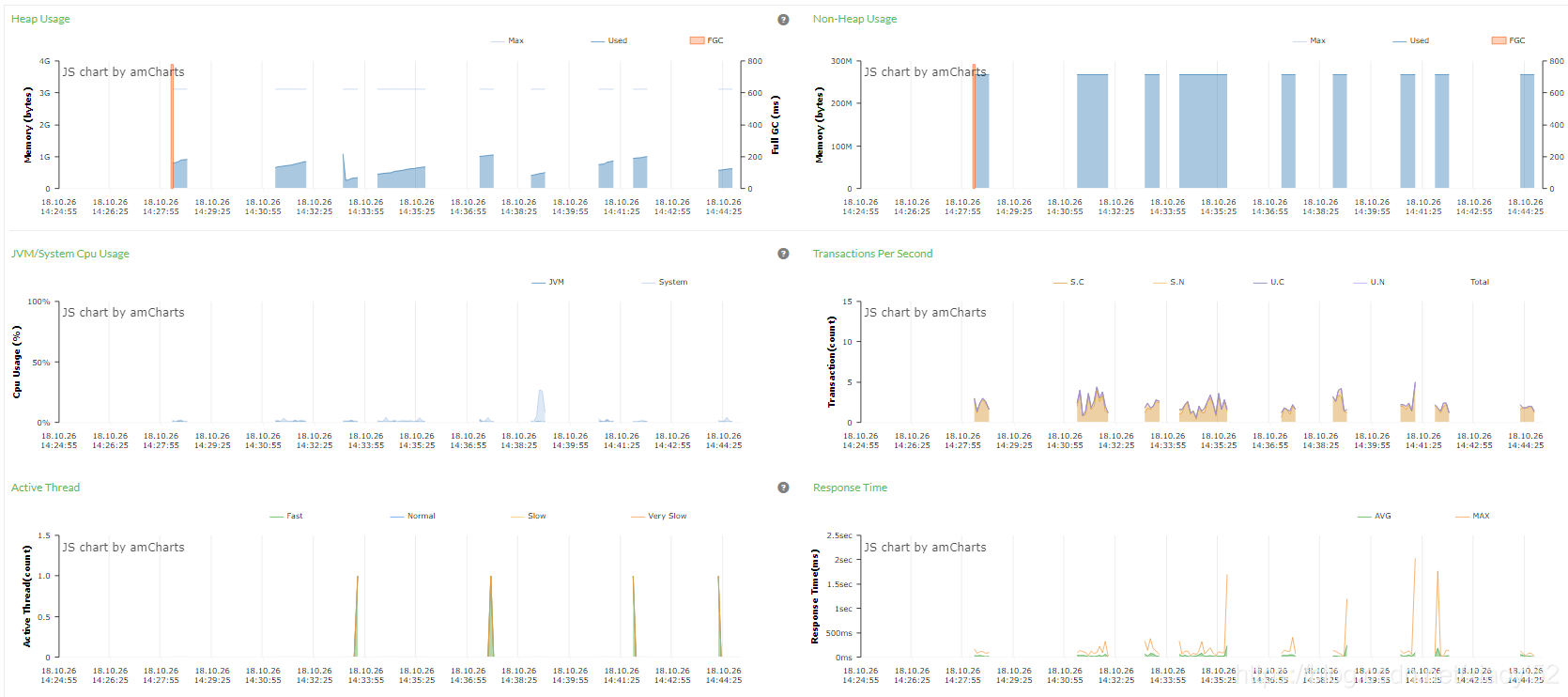
4.2.2 心跳检测
分布式系统一般都是以集群形式存在的,集群中任何一个节点出问题,都需要能够快速检测并且移除。因此对集群服务器和部署于其上的应用的心跳检测是必不可少的。
心跳检测有多重实现方案,作用除了用于检测节点故障之外,还可用于服务故障的检测。服务故障检测主要是针对业务层面的,可定期的发送一些无损的业务请求,以判断服务器是否正常提供服务。比如在博主的工作中,专门做了一个简单的心跳检测系统,通过定期调用其他业务系统的一些查询接口,来验证服务的可用性,以此达到心跳检测的目的。
4.3 流量控制
4.3.1 流量控制方式
任何系统都有承载上限,因此在分布式系统中,对超过上限的流量进行控制是必须的。流量控制可以从多个维度来进行,如对系统的总并发请求数进行限制,或者限制单位时间内的请求次数(如限制qps),或者通过白名单机制来限制接入系统调用的频率。不同的机制适应不同的场景。
对于超载的流量最简单的处理方式是直接丢弃,不进行任何处理直接返回,但会给用户带来糟糕的用户体验。
信号量/线程池
基于Java信号量实现流控的思路如下:
Semaphore semaphore = new Semaphore(INIT_SIZE);
...
// 请求处理
if (semaphore.getQueueLength() > 0) {
return;
}
try {
semaphore.acquire();
// 处理具体的业务逻辑
...
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
通过不断测试和调整,得到系统的承载上限,以此设置资源阈值INIT_SIZE。当流量在可控范围内,就获取信号量,并执行业务逻辑。否则就直接返回。
当然也可以设置等待队列大小,让一部分请求进行有限的等待。
也可以使用线程池,其思路跟使用信号量是一样的。
消息队列
流量控制的另一种方式是通过分布式消息队列来将用户的请求异步化,将请求的接收与业务逻辑处理解耦,当系统请求较多时,请求进入请求处理队列排队,前端用户不用等待系统处理完毕便能够得到相应。而后端系统能够以固定的频率来进行请求的处理,削峰填谷,不用担心瞬间流量过大被压垮。
当然在具体的场景中,对于流量控制实现方案有不同的选择。这里可参考博主的另一篇文章,讲了在实际工作场景中的一种流控实现方案-线程池处理高并发请求。
4.3.2 服务稳定性
分布式系统的依赖错综复杂,一个应用既可能是服务提供者又同时是服务消费者。作为服务提供者时,外部的调用频次、时间是不完全可控的;而作为服务消费者,所依赖的第三方服务稳定性是不可控的。降低不可控因素对线上运行系统的影响,最大限度地提高系统的稳定性,是一个值得考虑的问题。总的来说,主要从几个方面来进行保障。
依赖管理
从服务提供者的角度讲,必须清楚,调用自己的系统有哪些,这样才能评估系统的压力和流量处于一个什么样的层次,是否需要进行扩容等;从服务消费者的角度讲,必须对所依赖的服务了然于胸,清楚哪些是核心依赖,哪些是非核心依赖,非核心依赖在必要的时候可以进行服务降级。
可以借助一些工具来对依赖关系进行管理,对应用的调用日志进行收集和整理,将其中的调用关系和被调用关系以及调用频次提取出来进行展示。
优雅降级
当依赖的某个服务出现故障,系统应该能够及时感知并进行相应处理。否则大量超时的调用,有可能会将系统线程和可用连接数用完,导致新的请求无法进入,进而拖垮整个系统。因此当出现故障时对服务进行降级是必要的,特别是对于一些非核心链路。关于如何进行服务降级,可参考博主的另一篇文章——Hystrix-介绍与使用。
服务分级
对于服务提供者来说,需要判断当前服务被多少人调用,最好建立应用白名单机制,服务调用需要事先申请,以便对服务进行管理和容量规划。如果没有实现的容量规划,当未知的调用者流量突增时,很可能将系统拖垮。
另外,也要对服务消费者的优先级进行区分,哪些调用是核心链路,哪些是非核心链路。区分的好处是,当系统的压力过大无法承载时,为保证核心链路的畅通,非核心链路可以应急关闭。
4.4 性能优化
4.4.1 性能瓶颈优化
Web的性能优化涉及前端优化、服务端优化、操作系统优化、数据库查询优化、JVM调优等。
前端优化工具
YSlow是Yahoo!提供的用于网页性能分析的浏览器插件,可用来对前端页面进行性能检测。
页面响应时间
服务端单个请求的响应速度跟整个页面的响应时间及页面的加载速度密切相关。借助浏览器自带的调试工具,可以清楚看到当前页面的每一个请求耗费的时间,以此快速找到响应慢的请求,分析原因并进行优化。
当然,由于请求和响应经过了一系列网络节点,如反向代理、网络交换设备等,因此请求耗费的时间并不能准确反应服务端响应时间。通过服务端访问日志的配置可以看到每一个请求的响应时间,通过对数据进行收集和分析能够通过数据报表看到响应时间的趋势变化及波动情况。
方法响应时间
定位到响应慢的请求之后,接下来就是定位到具体的代码进行分析。但通常来说比较浪费时间而且容易遗漏。通过动态跟踪工具-btrace,能快速定位和发现耗时的方法。
Btrace对于Java应用在线故障排除方面,是一把不可或缺的利器。
下载地址:https://github.com/btraceio/btrace/releases。
下载之后解压缩,然后配置好环境变量即可。该工具在字节码层面上对代码进行trace ,通过在运行中的java类中注入trace代码, 并对运行中的目标程序进行热交换(hotswap)来达到对代码的跟踪。举个简单栗子来说明使用方法。
假设有个方法如下:
@RequestMapping("/")
@ResponseBody
public String sayHello(){
return "hello";
}
脚本文件HelloWorld.java如下:
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
@BTrace
public class HelloWorld {
@OnMethod(clazz="cn.tonghao.remex.controller.TestController", method="sayHello", location = @Location(Kind.RETURN))
public static void onThreadStart(@Return String result) {
println("thread start!");
println(result);
}
}
启动工程,通过 netstat –ano | findstr “8088” (linux下通过ps 命令查看)找到运行的进程号pid为14124,然后进入脚本文件路径,执行命令:btrace 14124 HelloWorld.java
然后在本地地址栏访问,输出如下:
D:\Program Files>btrace 14124 HelloWorld.java
thread start!
hello
当然,如果能在本地连接远程服务器,也可以通过visualVM可视化界面来编辑btrace脚本和运行。
在btrace脚本中,OnMethod注解标识当前执行的时间,clazz指定要跟踪的类名称(可以使用通配符),method用来指定执行的方法,location表示执行的时机。
Btrace项目目录下的samples目录有很多例子,几乎涵盖了工具使用的所有方面。计算方法响应时间的btrace脚本这里就不展示了。
GC日志分析
GC日志能够反映出Java应用执行内存回收的详细情况,如Minor GC的频繁程度、Full GC的频繁程度、GC导致的STW时间、引起GC的原因等。
上文介绍过PinPoint工具,从监控界面可以很清晰的看到GC的STW时间。当STW时间较大时,结合GC日志可做进一步分析。
通过ps –ef | grep java 命令查看JVM参数,找到日志路径后查看日志。关于JVM调优的问题,可以参考博主的“JVM内存模型与性能调优”一文。
数据库查询
很多请求响应速度慢的原因最终都是由于糟糕的查询SQL导致的。MySQL提供慢SQL日志的功能,能够记录下响应时间超过一定阈值的SQL查询,也就是所谓的慢查。
4.4.2 性能优化措施
找到性能瓶颈之后,就要根据对应的问题来进行优化了。如果是慢查,就要判断是否是查询语句写得有问题,数据库索引设计是否正确;如果是GC带来的长时间STW,那么就要判断GC参数是否可以优化,代码是否合理。另外还有网络、硬件等方面的问题,根据实际情况来判断是否需要提高硬件配置。
代码层面的优化则是一个大的命题,这里不详述。
其他一些优化思路:在数据传输时先进行压缩,提升数据传输速度。结果缓存,提高响应速度等等。















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









