







文章目录
ClickHouse
类LSM Tree的结构,也就是类hbase的结构
- 更新数据的时候,老的数据还在,记录历史,但会有版本号记录
- 也会有大合并的过程,这个时候老的数据会被消除
- 写数据的时候顺序追加写,类同kafka,也是顺序写,比随机写效率高很多
- 类同hive有分区的功能
- 单条Query就能利用整机所有CPU,多核并行处理,所以多余高qps(每秒钟查询次数)查询并不是强项
- 不适合初始存储,适合做宽表,大量字段的,单表查询很快,多表join不及presto和impala
quick start
-
基于 21.7.3.14 版本,注意会占用9000端口
-
采用rpm安装
- 默认会在/etc下生成clickhouse-client/ clickhouse-server/
- 数据,默认是在/var/lib/clickhouse
- log,默认是在/var/log/clickhouse
-
终端客户端访问:clickhouse-client -m
-
目录文件介绍,主要是/var/lib/clickhouse/data文件

表引擎
不依赖hadoop生态,其实也就是存储不依赖hdfs,默认的存储方式就是/var/lib/clickhouse路径下
-
TinyLog:列文件存储磁盘,不支持索引,没有并发控制,一般保存数据较小,也就是测试用下
-
Memory:基于内存,重启数据消失,不支持索引,内存读写性能较高,生产不会用
-
MergeTree:ck最强引擎,支持索引分区,由此引擎衍生出多个引擎
create table t_order_mt( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id);-
分区,降低全表扫描,
- 默认一个分区
- mergetree是以列文件+索引文件+表文件组成
- 设置了分区就会保存到不同目录
- 任何数据写入都会产生一个临时分区,写后大概101-5分钟会进行merge,将临时分区合并到已有分区,也可手动处罚 optimize table xxxx final,合并后路径对应文件也会变化,也可手动合并指定的分区 optimize table xxxx partition xxxx final
-
ck的主键
-
可以重复,并不是唯一约束,但也是索引
-
稀疏索引:类似跳表,下图就是稀疏索引,ck默认的mergeTree是8192
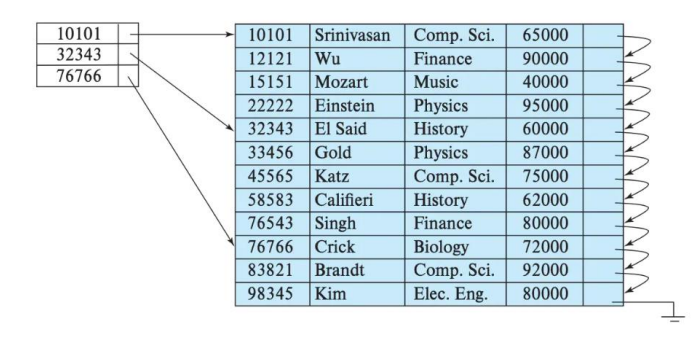
-
-
order by
- ck建表必填项,分区内排序
为适合主键的稀疏索引采用必须排序- 主键必须是 order by 字段的前缀字段,比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
-
二级索引
- 建二级索引测, GRANULARITY N 是设定二级索引对于一级索引粒度的粒度,也就是对一级索引聚合的数量级
例子:比如原来一级索引是[1,3] ,[4,6],[7,9],现在添加二级索引,粒度为3,直接变成[1,9]
create table t_order_mt2( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime, INDEX a total_amount TYPE minmax GRANULARITY 5 ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id); -
TTL
-
字段级别过期时间,下面是设置10s后过期
-
必须是日期类型,且不能是主键字段
create table t_order_mt3( id UInt32, sku_id String, total_amount Decimal(16,2) TTL create_time+interval 10 SECOND, create_time Datetime ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id); -
表级别TTL,修改表内某列的ttl
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
-
-
-
ReplacingMergeTree
-
继承mergeTree,增加去重功能,
只会在合并的过程中出现 -
如果表分区,去重只会在分区内部进行去重,不能执行跨分区的去重
create table t_order_rmt( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =ReplacingMergeTree(create_time) partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id); -
ReplacingMergeTree()内填入的为去重的版本字段,重复数据保留版本字段最大的,不填,默认按照插入顺序保留最后一条
-
如果还未实现合并去重,可以手动执行
OPTIMIZE TABLE t_order_rmt FINAL;
-
-
SummingMergeTree
-
关心于聚合能力,预处理的功能,类似kylin
create table t_order_smt( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =SummingMergeTree(total_amount) partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id ); -
SummingMergeTree()里面填入的就是待聚合的列
- 可以填多列,但必须为数字列
- 分区内聚合
- 在分区内,将order by的字段作为group by保留最早的一行数据
-
CURD
-
insert
- 和mysql基本一致:支持insert into [table_name] values(…),(….) ,支持表到表的插入insert into [table_name] select a,b,c from [table_name_2]
-
update && delete(alter操作)
- delete:例子 alter table t_order_smt delete where sku_id =‘sku_001’;、
- update:例子 alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id =102;
-
select
-
支持子查询,支持with子句,支持join
-
GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计,同hive
-
with rollup例子:select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with rollup;
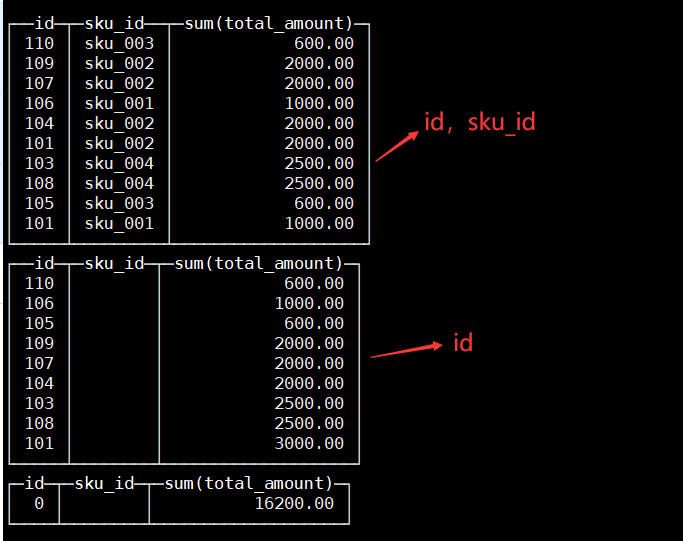
-
with cube例子: select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with cube;
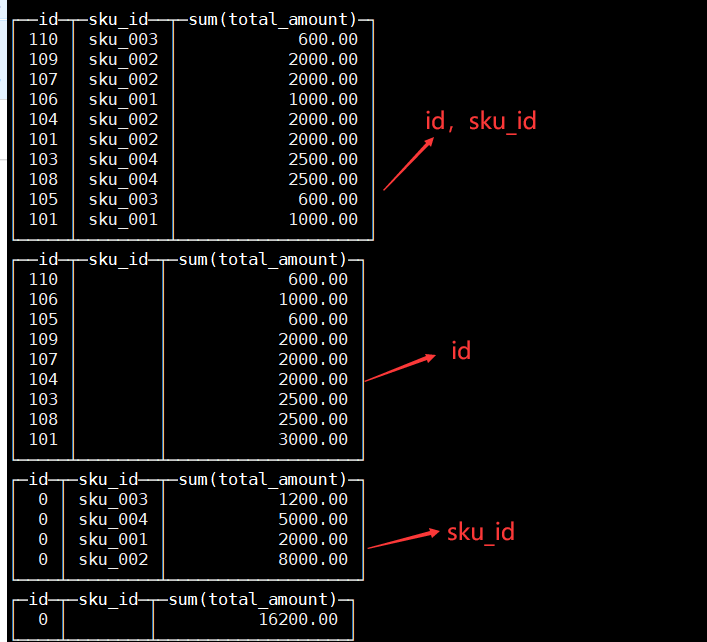
-
-
-
alter表操作
- 新增字段:alter table tableName add column newcolname String after col1;
- 修改字段类型:alter table tableName modify column newcolname String;
- 删除字段:alter table tableName drop column newcolname;
HA+集群
副本
-
保证数据可用性,HA
-
需要zk,默认可以在/etc/clickhouse-server下修改config.xml文件
<zookeeper>
<node>
<host>example1</host>
<port>2181</port>
</node>
<node>
<host>example2</host>
<port>2181</port>
</node>
<node>
<host>example3</host>
<port>2181</port>
</node>
</zookeeper>
- 不修改配置文件内上述配置,可以将配置单独文件,在任意路径创建xml文件,注意修改权限为clickhouse用户,然后在配置文件config.xml中配置路径,下面metrika.xml文件、以及在config.xml下配置
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>master</host>
<port>2181</port>
</node>
<node index="2">
<host>node1</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
-
节点需要同步配置,并且需要各创建表,重启clickhouse,注意建表的时候需要指定不同表引擎的副本结构(ReplicatedMergeTree)
create table t_order_rep2 ( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102') partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id); -
ReplicatedMergeTree
- 第一个参数是zk的路径,最好按照/clickhouse/table/{shard}/{table_name} 的格式
- 第二个参数是副本名称,注意相同分片的副本名称不能相同
分片
-
分布式存储的思想:副本作为HA,分片对不同节点实现分布式存储,类同HDFS、Kafka集群的思想
-
Distributed作为分片集群管理的表引擎
-
先有本地表再后分布式表
-
一台节点创建本地表,其他节点会同步
create table st_order_mt on cluster gmall_cluster ( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine =ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}') partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id); -
一台节点创建分布式表,Distributed(集群名称,库名,本地表名,分片键)分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()
create table st_order_mt_all2 on cluster gmall_cluster ( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime )engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));
-
优化
explain
- 用explain去查看执行任务
- EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, …] SELECT … [FORMAT …]
- 普通用的话直接explain就可以
- 优化sql
- 对于三元运算符可以开启优化:SET optimize_if_chain_to_multiif = 1;
- EXPLAIN SYNTAX + sql语句,可返回优化后的sql语句
建表优化
-
数据类型
-
时间字段:能用数值或者日期时间就不用用string,底层会将Datatime格式转为Long类型,但不要直接写Long类型,需要明文转换,所以直接写Datetime
-
空值类型:最好不好存在空值,可以用逻辑上不同意义区分,比如-1,下文建表为允许空值
CREATE TABLE t_null(x Int8, y Nullable(Int8)) ENGINE TinyLog; INSERT INTO t_null VALUES (1, NULL), (2, 3); SELECT x + y FROM t_null;
-
-
分区和索引
- 分区:业务数据一般按天分区
- 索引:必须指定索引列,就是order by字段,最好遵循查询频率大的在前面的原则
-
表参数
- 索引粒度:Index_granularity,默认为8192,看情况调整
- TTL:如果不保存历史数据,可以指定ttl生存时间
-
写入/删除
- 尽量不要有单条/小批量的insert/delete操作,会产生小分区文件,尽可能大批次
- 不要一次写入太多分区,数据太快也会导致归并跟不上,建议每秒2-3次写入操作,每次2w-5w
- 遇到too many parts 的问题,可以使用WAL预写日志,积攒批次写入
-
资源配置
-
配置项主要在 config.xml 或 users.xml 中, 基本上都在 users.xml 里
-
cpu:
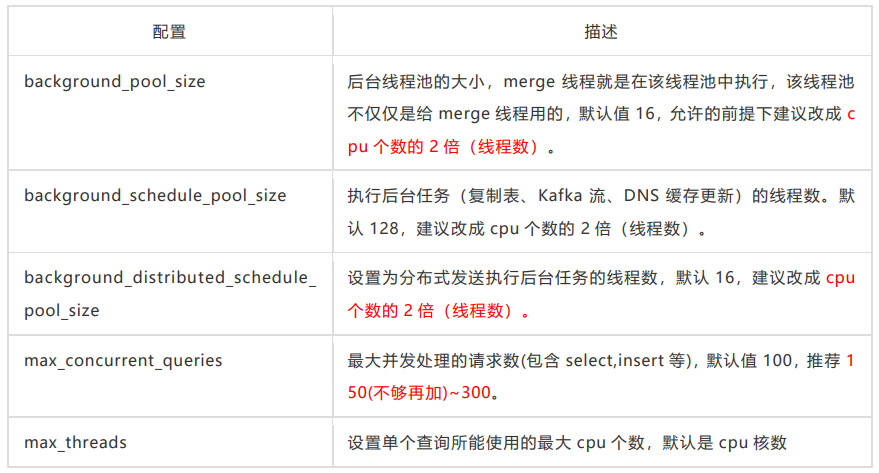
-
内存:

-
存储,ck不支持多数据目录,但可以从逻辑路径上入手,挂载不同的虚拟卷组
-
sql优化
使用官方的数据集测试, visits_v1和 hits_v1
-
count优化
- 使用的是count()或者count(*),且没有where条件,会直接使用system.tables的total_rows,如果指定了字段则不会使用
- 可以通过explain查看有Optimized trivial count
-
having
- 在group by后有having,且没有with cube、with rollup 或者 with totals 修饰的时候,having会转为where
- 父sql的where如果子sql存在,会转变成先在子sql中where
-
聚合函数
- sum(UserID * 2)会转换为sum(UserID) * 2
- 没有意义的sql会被优化
-
标量替换:相当于加一列常量列
-
三元运算:开启了optimize_if_chain_to_multiif参数,三元会被替换成multiIf函数
单表
-
prewhere替换where
- where是先查出select的列再按照条件过滤,prewhere先找到条件过滤列过滤再横向找select的列
- 打开 where 自动转 prewhere:set optimize_move_to_prewhere=1;
- 有些情况会失效,需要手动指定,就是where替换成prewhere:常量表达式、alias类型字段、包含arrayjoin/globaIn/globaNotIn/indexHint查询、select字段和where字段一致、使用了主键字段
-
采样,SAMPLE
SELECT Title,count(*) AS PageViews FROM hits_v1 SAMPLE 0.1 #代表采样 10%的数据,也可以是具体的条数 WHERE CounterID =57 GROUP BY Title ORDER BY PageViews DESC LIMIT 1000 -
别用select * ,选择列,order by 结合where 、limit
-
尽量避免新增列,会非常消耗资源性能
-
uniqCombined替换distinct
- 感觉鸡肋,不保证百分百去重,由于HyperLogLog(HLL)算法所以性能快,几乎是10倍
-
物化视图,视图相当于保存计算查询的逻辑,而物化则是将这种结果保存下来
-
写入数据最好先排序,无序的数据或者涉及的分区太多,会导致ck无法及时对新导入的数据进行合并
-
也需要关注cpu的性能,大于50%会出现波动,ck主要耗费的性能就是cpu
多表 join
-
用in代替join,单个字段关联可用子查询再用in替换
select a.* from hits_v1 a where a. CounterID in (select CounterID from visits_v1); -
大小表join
- 需要满足小表在右的原则,ck会将右表加载到内存
-
分布式表使用 GLOBAL
- 分布式表join和in之前必须要加上GLOBAL关键字,右表只会在接收查询请求的那个节点上查询一次
-
使用字典表,一般会将纬度表创建成为字典表,放在内存,不宜太大
数据一致性
-
ck可以保证最终一致性的原则,对数据进行合并去重
-
写入数据后立即进行合并(不推荐),手动optimize,默认根据order by 字段去重
-
根据group by 去重,这里做的是记录时间,每次查视图获取最新时间的数据,argMax(field1,field2):按照 field2 的最大值取 field1 的值。下面是视图
CREATE VIEW view_test_a AS SELECT user_id , argMax(score, create_time) AS score, argMax(deleted, create_time) AS deleted, max(create_time) AS ctime FROM test_a GROUP BY user_id HAVING deleted = 0; -
final查询,在查询语句后增加 FINAL 修饰符,这样在查询的过程中将会执行 Merge 的特殊逻辑(例 如数据去重,预聚合等)
select * from visits_v1 final WHERE StartDate = '2014-03-17' limit 100 settings max_final_threads = 2;
-
物化视图
普通视图不保存数据,保存的仅仅是语句,物化视图也保存了查询的结果
-
实质上是create语法,创建一个临时表保存了数据,默认是.inner.物化视图名
-
优缺
- 优:速度快,因为已经计算过保存了,查询肯定快
- 缺:流式数据,是累加的技术,历史的数据去重这样的分析不太好用
-
原表数据更新,物化视图也会更新,不支持同步删除,原数据删除该表不会删,
-
历史数据直接导入物化视图,insert into
MaterializeMySQL引擎
专门针对mysql,该 database 能 映 射 到 MySQL 中 的 某 个 database , 并 自 动 在 ClickHouse 中 创 建 对 应 的 ReplacingMergeTree。ClickHouse 服务做为 MySQL 副本,读取 Binlog 并执行 DDL 和 DML 请 求,实现了基于 MySQL Binlog 机制的业务数据库实时同步功能。
-
支持全量和增量同步,创建之初会全量同步,之后会通过binlog进行增量同步
-
每张同步mysql的表会有 _sign 和 _version 字段, _version是版本参数当有增/删/改的时候会全局自增, _sign用来标记是否删除,取值为1/-1
-
mysql配置
-
默认修改/etc/my.cnf,在[mysqld]下添加
server-id=1 log-bin=mysql-bin binlog_format=ROW -
开启 GTID 模式,主次切换保持数据同步
gtid-mode=on enforce-gtid-consistency=1 # 设置为主从强一致性 log-slave-updates=1 # 记录日志
-
-
ck配置
- 开启ck物化引擎:set allow_experimental_database_materialize_mysql=1;
- 创建复制的管道:CREATE DATABASE test_binlog ENGINE = MaterializeMySQL(‘[mysql地址]:[端口号]’,‘[数据库名]’,‘[用户名]’,‘[密码]’);
常见问题
-
分布式DDL语句某节点副本不执行,发现报错为下文,重启该节点
Retrying createReplica(), because some other replicas were created at the same time
















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











