






最强OLAP分析引擎-Clickhouse快速上手一
一、Clickhouse简介
1、什么是Clickhouse
Clickhouse是由俄罗斯yandex公司开源的一个用于联机分析OLAP的列式数据库管理系统。他是使用C++语言编写的,支持SQL实时查询的大型数据管理系统。由于Clickhouse在大型数据集查询处理的高效表现,从2016年开源以来,就吸引了全球的目光,甚至一度登上github的关注度头把交易。
这一段介绍中标出了Clickhouse的几个显著特点。
- OLAP
Clickhouse的设计定位就是用于OLAP离线数据处理。相比于OLTP在线事务处理,Clickhouse更关注于对海量数据的计算分析,关注的是数据吞吐、查询速度、计算性能等指标。而对于数据频繁的修改变更,则不太擅长。所以Clickhouse通常用来构建后端的实时数仓或者离线数仓。 - 列式存储
Clickhouse是一个真正意义上的列式存储数据库。传统数据库存储数据都是按照数据行进行存储。
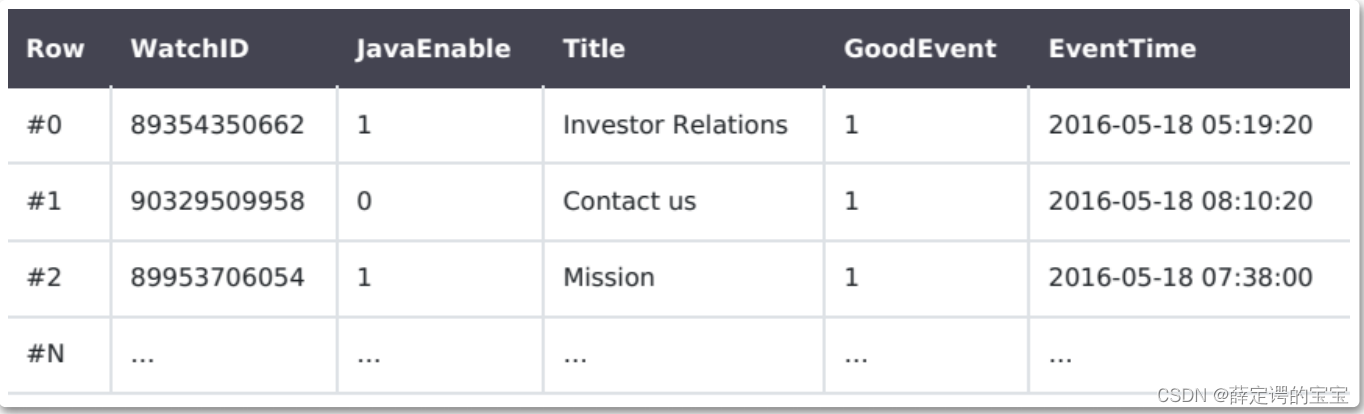
比如常用的MySQL,他的B+树的叶子节点就会整体保留一行数据。这样的好处是,当想要查询某一条数据时,可以通过一次磁盘查找加顺序读取获得这一条完整的数据。而Clickhouse存储数据的方式则是按照列来存储,将来自不同列的数据进行单独存储。实际上后面会介绍到,Clickhouse存储一个表数据时,就是以一列为一个文件进行存储的。
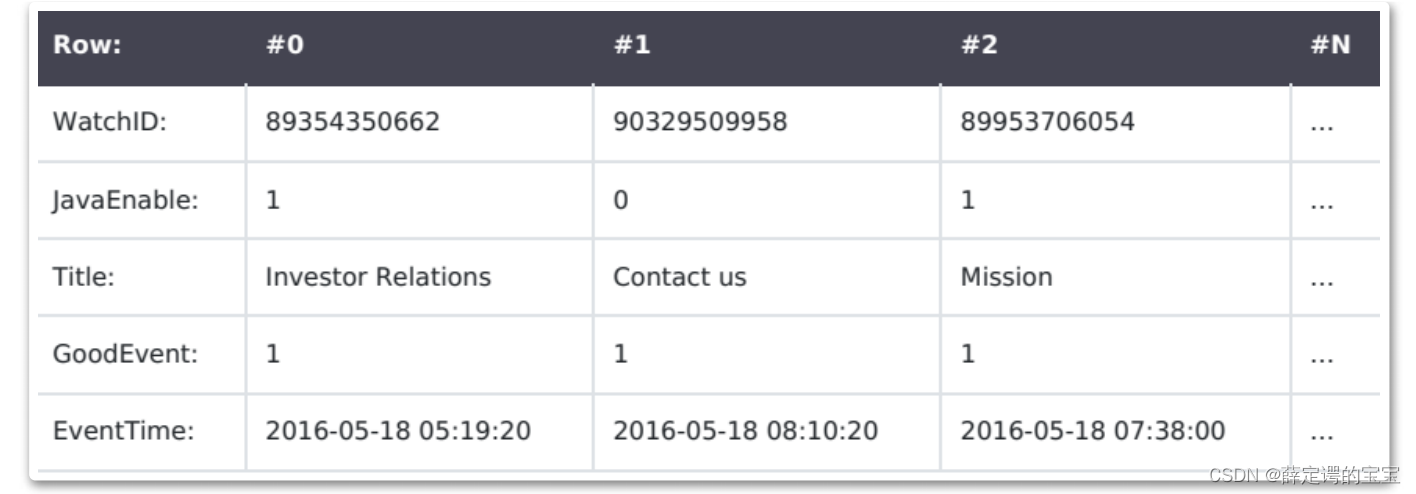
列式存储的数据库产品其实也有很多,像Druid数据库,InfiniDB等等很多。只是在国内其实用的还是比较少的。列式存储相比于行式存储在很多数据计算方面会体现出很多优势。例如通常一个计算过程都只会用到少数几个列的数据,这时行式存储就需要读取到相关行的所有列数据再进行过滤。而列式存储就可以直接读取这几个列的相关数据,而不用查找其他不关心的数据。
2、Clickhouse适用场景。
一个典型的OLAP场景主要是对海量数据进行更新,相比于我们常用的mysql等OLTP数据库,有一些很明显的特征。
绝大多数请求都是读请求。对数据的修改比较少或者几乎没有。
数据量很大。这个量即包括数据的行数,也包括数据的列数。也就是通常说的宽表。大部分情况下,对分布式表结构的要求是必须的。
数据通常以大的批次进行整体更新,而不是单行更新。这需要有很高的数据吞吐量。
对事务的要求不是必须的。对于数据一致性的要求不会太高。通常只要求数据最终一致性。
Clickhouse的数据吞吐量相当大,能够存储海量的数据,并能够以水平扩展的方式进行扩容。对大表的查询计算处理效率也非常高,甚至很多场景下都可以拥有媲美于关系型数据库的查询效率。官网给出的一些测试数据也大都是 上千万行*数百列的数据规模。很多大规模的数据查询也都能轻松达到毫秒级别。
但是需要指出,Clickhouse高效性能的背后,肯定伴随计算机资源的大量消耗。Clickhouse对内存和CPU的占用率都非常高,一个很普通的查询都可能需要消耗非常多的资源。因此,Clickhouse的查询频率也不宜太高。过于频繁的连续或者并发查询甚至很容易导致服务直接崩溃。
综合Clickhouse的特点,他就非常适合用于后端数仓的建设。当然,这本身也是Clickhouse的设计目标。
二、Clickhouse环境安装
1、线上快速体验
Clickhouse的官方网站是https://clickhouse.com/ 。他的LOGO是一个列式存储的示意图。
现在体验线上的应该需要注册账号登录一下,这里就不演示了。
2、本地快速部署
Clickhouse的官方文档非常详细,是学习Clickhouse最重要的资料。其中关于安装部署的章节地址是:https://clickhouse.com/docs/zh/gettingstarted/install/。
演示环境还是用三台CentOS服务器hadoop01,hadoop02,hadoop03三台机器。安装前,建议关闭三台服务器的防火墙以及SELinux安全组件,并打开操作系统的文件限制。
接下来这一章节将演示单机环境下的clickhouse安装。clickhouse的单机环境已经能够体现出非常强的性能。从单机扩展到集群是相当简单
的,在后续clickhouse的备份以及分布式表章节用到集群时再一起分享。
clickhouse不需要依赖其他的组件,自己就能够提供非常强悍的数据处理性能。支持的安装环境非常多,安装方式也有很多种。这里,我们采用最为直观的tgz压缩包的方式进行安装。当然,如果是生产环境,建议的方式还是通过源码打包编译。
首先需要下载Clickhouse。下载地址:https://repo.clickhouse.com/tgz/stable/。在这个仓库中直接包含了Clickhouse的所有发布版本,俄罗斯简单直接的风格一览无余。从这里也能看出,Clickhouse的版本发布非常频繁。这里我们选取当前最新的21.9.4.35版本。这里面总共有四种tgz包是我们需要下载的,clickhouseserver-21.9.4.35.tgz, clickhouse-common-static-dbg-21.9.4.35.tgz,
clickhouse-common-static-21.9.4.35.tgz, clickhouse-client-21.9.4.35.tgz。然后将这四个压缩包解压并依次进行安装。
tar -xzvf clickhouse-common-static-$LATEST_VERSION.tgz
sudo clickhouse-common-static-$LATEST_VERSION/install/doinst.sh
tar -xzvf clickhouse-common-static-dbg-$LATEST_VERSION.tgz
sudo clickhouse-common-static-dbg-$LATEST_VERSION/install/doinst.sh
tar -xzvf clickhouse-server-$LATEST_VERSION.tgz
sudo clickhouse-server-$LATEST_VERSION/install/doinst.sh
tar -xzvf clickhouse-client-$LATEST_VERSION.tgz
sudo clickhouse-client-$LATEST_VERSION/install/doinst.sh
安装过程中,第1、第2、第4三个包的安装都没有输出,因为这三个包的安装过程只是简单的复制文件。安装第3个包clickhouse-server-21.9.4.35时,clickhouse会在数据库中创建一个默认的用户default,安装过程中,会需要给这个default用户输入一个密码。这里进行测试,就直接回车,不设置密码即可。正常情况下,安装完成会得到这样的输出日志。
Enter password for default user:
Password for default user is empty string. See /etc/clickhouseserver/users.xml and /etc/clickhouse-server/users.d to change it.
Setting capabilities for clickhouse binary. This is optional.
ClickHouse has been successfully installed.
Start clickhouse-server with:
sudo clickhouse start
Start clickhouse-client with:
clickhouse-client
安装完成后,就可以使用clickhouse start指令启动clickhouse服务了
服务端还有其他一些指令,可以使用clickhouse --help查看
然后使用clickhouse-client就可以打开客户端。这样就可以使用SQL进行查询了。例如 show databases;查看已有的数据库。show tables from system; 查看系统表。
客户端启动时可以设置非常多的参数,可以使用clickhouse-client --help查看。常用的clickhouse -m表示支持多行SQL查询。
安装完成后,有几个重要的目录要记住:
- 执行脚本 : /usr/bin/ 之前用到的clickhouse和clickhouse-client这些指令就被默认安装在这个目录。
- 配置文件: /etc/clickhouse-server/ 这个目录下的config.xml和users.xml是最为重要的两个配置文件。后续章节会介绍其中的重要配置。
- 运行日志:/var/log/clickhouse-server/ 服务运行的详细日志。
- 数据目录: /var/lib/clickhouse/ 这个目录包含了clickhouse运行时的所有数据文件。例如metadata目录下存放了所有表的元数据,可以看到,clickhouse就是以sql文件的方式保存表结构,启动时加载这些sql文件就完成了数据加载。而data目录下存放了所有的表数据。像之前看到的default和system两个默认的数据库就对应data目录下的两个文件夹。
另外,clickhouse在安装时,会默认创建一个clickhouse用户来部署这些文件。所以,如果不是使用root用户进行操作的话,需要注意下用户权限的问题。
3、远程连接clickhouse
3.1 打开远程连接控制
默认情况下,clickhouse服务只能在本地进行连接,远程机器是无法连接的。这点跟mysql是很类似的。因此,还需要做一些修改,让clickhouse可以远程访问。配置方式直接修改clickhouse的config.xml配置文件。 所在目录/etc/clickhouse-server。将下面这一行注释打开。文件156行。
<listen_host>::</listen_host>
然后重启clickhouse即可。
clickhouse restart
注意,重启时不能有客户端连接上。否则无法正常重启。重启完成后,其他机器上就可以使用clickhouse-client命令行工具远程连接
clickhouse服务了。只不过需要通过-h参数指定服务端机器名即可。关于clickhouse-client命令行工具的其他使用方式,可以使用
clickhouse-client --help方式查看帮助。也可以查看官方文档:https://clickhouse.com/docs/zh/interfaces/cli/
3.2 其他方式访问clickhouse
clickhouse除了命令行客户端外,还提供了非常丰富的接入客户端。例如使用浏览器直接访问地址 http://hadoop01:8123/?query=show databases 就可以访问clickhouse的http客户端。这个8123端口可以在clickhouse的配置文件中进行
定制。
同样在8123端口,clickhouse还提供了JDBC驱动程序来连接。目前官网提供了一个官方的驱动包以及两个第三方的驱动包。其中,官方JDBC驱动包的maven坐标是
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
引入这个驱动包后,就可以像连接其他关系型数据库一样访问clickhouse了
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
Connection connection =
DriverManager.getConnection("jdbc:clickhouse://hadoop01:8123/default");
.....
当然,这个客户端工具也提供了自己封装的客户端,简化数据库访问。具体参见官方github仓库:https://github.com/ClickHouse/clickhouse-jdbc
另外还有两个第三方开发的JDBC驱动包。 分别是 ClickHouse-Native-JDBC(仓库地址:https://github.com/housepower/ClickHouse-Native-JDBC) 和clickhouse4j (仓库地址:https://github.com/blynkkk/clickhouse4j)
如果你觉得自己下载JDBC驱动包比较麻烦,那还有更简单的方式。 clickhouse完全兼容最常用的mysql和postgresql两个数据库,可以用他们对应的JDBC驱动直接连接。只需要注意 mysql服务的默认端口是9004。Postgresql的默认端口是
9005。
接下来,也可以将对应的jar包导入到一些第三方的客户端工具中,例如navicat,DataGrip等工具,像访问MySQL一样访问clickhouse。
从这个安装过程中可以体会到,虽然clickhouse底层的设计非常精妙,但是表现出来的实现方式却是非常简单直接。大部分的功能都是以一种统一有序的方式直接进行堆叠。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









