







文章目录
高层协议(如IP)经过路由后,为数据包确定了出口net_device,然后通过邻居子系统为数据包添加L2首部,最后数据包交给 dev_queue_xmit()函数,由设备接口层接力后续的数据发送流程。这篇笔记分析了数据包从进入设备接口层到给到网络设备驱动之间的代码实现。
队列: netdev_queue
每个net_device支持多发送队列,具体支持几个由驱动程序在分配net_device时决定,一般会对应到实际的硬件队列上。当前版本只有发送支持多队列,接收只有一个队列(更高版本接收也支持多队列)。
队列用netdev_queue表示。
struct netdev_queue {
struct net_device *dev;
struct Qdisc *qdisc; // 每个队列可以有不同的排队规则
unsigned long state; // 队列状态,见下方
spinlock_t _xmit_lock;
int xmit_lock_owner;
struct Qdisc *qdisc_sleeping;
} ____cacheline_aligned_in_smp;
struct net_device {
...
// 发送队列,当有多个发送队列时指向的是一个数组
struct netdev_queue *_tx ____cacheline_aligned_in_smp;
/* Number of TX queues allocated at alloc_netdev_mq() time */
unsigned int num_tx_queues;
/* Number of TX queues currently active in device */
unsigned int real_num_tx_queues;
unsigned long tx_queue_len; /* Max frames per queue allowed */
spinlock_t tx_global_lock;
// 接收队列
struct netdev_queue rx_queue;
}
netdev_queue中核心字段如下:
- qdisc和qdisc_sleeping表示该队列的排队规则。后者如何实现目前暂不清楚。
- state表示队列的状态,具体见数据收发过程中的网络设备状态。驱动程序可以通过控制队列的状态来影响协议栈是否可以继续使用该队列发送数据包,比如硬件通路很拥塞,可以设置XOFF,此时设备接口层会停止入队列数据包,等状态缓建后取消XOFF,进而可以继续发送。
net_device中核心字段如下:
- _tx表示所有的发送队列,发送队列个数由num_tx_queues表示。虽然real_num_tx_queues表示当前实际可以工作的队列个数,但是目前版本没有看到该字段和num_tx_queues不相等的情况。
- tx_queue_len表示队列中所能缓存的skb上限,超过该值的skb在入队列时会被丢弃。
队列初始化
关于队列的初始化可以分为三个阶段:
- 在alloc_netdev_mq()中执行netdev_init_queues()进行基本初始化;
- 在register_netdev()中执行dev_init_scheduler()初始化排队规则;
- 在dev_open()中执行dev_activate()激活排队规则;
基本初始化
可以看到基本的初始化建立了队列和net_device对象之间的关联。
static void netdev_init_one_queue(struct net_device *dev,
struct netdev_queue *queue,
void *_unused)
{
queue->dev = dev;
}
static void netdev_init_queues(struct net_device *dev)
{
netdev_init_one_queue(dev, &dev->rx_queue, NULL); // 初始化接收队列
netdev_for_each_tx_queue(dev, netdev_init_one_queue, NULL); // 初始化所有发送队列
spin_lock_init(&dev->tx_global_lock);
}
安装默认排队规则
net_device对象注册时,为收发队列安装了默认的排队规则noop_disc。参考默认网络设备流量控制,我们知道该排队规则什么都不做,仅仅是丢弃数据包,这也就是为什么没有UP的网络设备根本无法进行数据收发的原因。
static void dev_init_scheduler_queue(struct net_device *dev,
struct netdev_queue *dev_queue,
void *_qdisc)
{
struct Qdisc *qdisc = _qdisc;
dev_queue->qdisc = qdisc;
dev_queue->qdisc_sleeping = qdisc;
}
void dev_init_scheduler(struct net_device *dev)
{
netdev_for_each_tx_queue(dev, dev_init_scheduler_queue, &noop_qdisc);
dev_init_scheduler_queue(dev, &dev->rx_queue, &noop_qdisc);
// 看门狗定时器见下文单独介绍
setup_timer(&dev->watchdog_timer, dev_watchdog, (unsigned long)dev);
}
激活排队规则
当设备打开时,会重新安装可以正常工作的排队规则,此时安装的排队规则是pfifo_fast,该排队规则使得net_device可以正常的收发数据包。关于dev_activate()的详细分析见默认网络设备流量控制。
dev_queue_xmit()
仔细阅读该函数的注释很有必要。该函数的核心逻辑如下:
- 根据网络设备的能力(往往对应硬件的能力)来决定是否对数据包进行合并、计算校验和以及线性化处理。这里的一个原则是尽可能的利用硬件的能力,例如,若硬件有校验和计算能力,那么就让硬件去计算校验和,这样可以节省CPU性能,提供吞吐量;
- 后面的发送过程分为两种情况:基于流控的发送过程和无流控的发送过程;
- 有流控机制时,将数据包入队列,然后触发一次流控调度,后续数据包的处理交给流控机制;
- 无流控机制时,这种方式非常简单,将数据包直接递交给网络设备驱动程序;
/**
* dev_queue_xmit - transmit a buffer
* @skb: buffer to transmit
*
* Queue a buffer for transmission to a network device. The caller must
* have set the device and priority and built the buffer before calling
* this function. The function can be called from an interrupt.
*
* A negative errno code is returned on a failure. A success does not
* guarantee the frame will be transmitted as it may be dropped due
* to congestion or traffic shaping.
*
* -----------------------------------------------------------------------------------
* I notice this method can also return errors from the queue disciplines,
* including NET_XMIT_DROP, which is a positive value. So, errors can also
* be positive.
*
* Regardless of the return value, the skb is consumed, so it is currently
* difficult to retry a send to this method. (You can bump the ref count
* before sending to hold a reference for retry if you are careful.)
*
* When calling this method, interrupts MUST be enabled. This is because
* the BH enable code must have IRQs enabled so that it will not deadlock.
* --BLG
*/
int dev_queue_xmit(struct sk_buff *skb)
{
// 经过层三路由,已经确定了该数据包应该从哪个网络设备对象发送出去
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
/* GSO will handle the following emulations directly. */
// 如果网卡硬件可以处理GSO数据包,那么后面可能的线性化、校验和计算都可以由硬件处理
if (netif_needs_gso(dev, skb))
goto gso;
// 数据包有分片但是硬件不支持自动处理分片,需要软件将数据包线性化(即将所有数据放
// 到一个地址连续的缓存区中)
if (skb_shinfo(skb)->frag_list &&
!(dev->features & NETIF_F_FRAGLIST) &&
__skb_linearize(skb))
goto out_kfree_skb;
/* Fragmented skb is linearized if device does not support SG,
* or if at least one of fragments is in highmem and device
* does not support DMA from it.
*/
// 硬件不支持SG,或者不支持非连续的DMA(不懂),同样要软件进行线性化处理
if (skb_shinfo(skb)->nr_frags &&
(!(dev->features & NETIF_F_SG) || illegal_highdma(dev, skb)) &&
__skb_linearize(skb))
goto out_kfree_skb;
/* If packet is not checksummed and device does not support
* checksumming for this protocol, complete checksumming here.
*/
// 高层协议没有进行完整的校验和计算,如果硬件也不支持校验和计算,
// 调用skb_checksum_help()进行软件校验和计算
if (skb->ip_summed == CHECKSUM_PARTIAL) {
skb_set_transport_header(skb, skb->csum_start - skb_headroom(skb));
if (!dev_can_checksum(dev, skb) && skb_checksum_help(skb))
goto out_kfree_skb;
}
gso:
// 至此,数据包准备就绪,下面利用发送机制将数据包传送给网络设备驱动
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
// 选择一个发送队列
txq = dev_pick_tx(dev, skb);
// 获取到Qdisc
q = rcu_dereference(txq->qdisc);
#ifdef CONFIG_NET_CLS_ACT
skb->tc_verd = SET_TC_AT(skb->tc_verd,AT_EGRESS);
#endif
// 如果发送队列指定了qdisc,说明需要使用流控机制进行数据包发送。
// 从目前的代码实现上看,默认情况下qdisc会设置为pfifo_fast,除非用户态进行了特殊的配置
if (q->enqueue) {
spinlock_t *root_lock = qdisc_lock(q);
spin_lock(root_lock);
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) {
// 队列没有打开,直接丢包
kfree_skb(skb);
rc = NET_XMIT_DROP;
} else {
// 把数据包入队列然后触发一次qdisc调度,具体数据包被何时传送网络设备驱动由流控机制决定
rc = qdisc_enqueue_root(skb, q);
qdisc_run(q);
}
spin_unlock(root_lock);
goto out;
}
/* The device has no queue. Common case for software devices:
loopback, all the sorts of tunnels...
Really, it is unlikely that netif_tx_lock protection is necessary
here. (f.e. loopback and IP tunnels are clean ignoring statistics
counters.)
However, it is possible, that they rely on protection
made by us here.
Check this and shot the lock. It is not prone from deadlocks.
Either shot noqueue qdisc, it is even simpler 8)
*/
// 下面处理网络设备没有开启流量控制的情形。这时只能尝试直接发送,如果发送时机不对
// 或者是别的其它导致没有发送成功,那么只能丢弃数据包,因为设备没有队列保存数据
// 设备必须已经被打开,即执行过dev_open()
if (dev->flags & IFF_UP) {
// 防止dev_queue_xmit()在同一CPU上被递归调用
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
HARD_TX_LOCK(dev, txq, cpu);
// 队列被关闭也会导致丢包。队列正常时将数据包交给设备驱动程序
if (!netif_tx_queue_stopped(txq)) {
rc = 0;
if (!dev_hard_start_xmit(skb, dev, txq)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
if (net_ratelimit())
printk(KERN_CRIT "Virtual device %s asks to queue packet!\n", dev->name);
} else {
/* Recursion is detected! It is possible, unfortunately */
if (net_ratelimit())
printk(KERN_CRIT "Dead loop on virtual device "
"%s, fix it urgently!\n", dev->name);
}
}
rc = -ENETDOWN;
rcu_read_unlock_bh();
out_kfree_skb:
kfree_skb(skb);
return rc;
out:
rcu_read_unlock_bh();
return rc;
}
选择发送队列: dev_pick_tx()
前面有提到,net_device支持多发送队列。自然的,在发送过程中需要为数据包选择一个队列。如上,dev_queue_xmit()函数通过调用dev_pick_tx()来选择发送队列。
static struct netdev_queue *dev_pick_tx(struct net_device *dev, struct sk_buff *skb)
{
const struct net_device_ops *ops = dev->netdev_ops;
u16 queue_index = 0; // 默认第一个队列
// 优先让驱动程序自己选择一个,如果驱动未实现则按照默认策略选择一个
if (ops->ndo_select_queue)
queue_index = ops->ndo_select_queue(dev, skb);
else if (dev->real_num_tx_queues > 1)
// 该函数不再展开,基本就是根据随机数、网络层报头、传输层报头的一些信息哈希一个索引
queue_index = simple_tx_hash(dev, skb);
// 将选择好的队列索引记录到skb->queue_mapping中,后续设备驱动就知道从哪个队列发送了
skb_set_queue_mapping(skb, queue_index);
// 返回选择的发送队列对象
return netdev_get_tx_queue(dev, queue_index);
}
当前实现的队列的选择策略也非常简单,分两种情况:
- 优先让驱动程序按照自己的策略选择;
- 如果驱动程序未定制选择策略,那么根据发送数据包的一些信息选择一个发送队列;
基于流控的发送过程
如dev_queue_xmit()所示,如果发送队列的qdisc指定了入队函数enqueue()则按照基于流控的发送过程发送数据包。
基于流控的发送过程,首先调用qdisc_enqueue_root()将数据包入队列,然后调用qdisc_run()触发qdisc调度。
入队列: qdisc_enqueue_root()
入队列并不会真正发送数据包,并且具体如何如队列是由qdisc决定的,不同的qdisc有不同的策略,可能很简单,也可能非常复杂,这部分内容在流量控制部分再详细展开。
static inline int qdisc_enqueue_root(struct sk_buff *skb, struct Qdisc *sch)
{
qdisc_skb_cb(skb)->pkt_len = skb->len; // 数据包长度保存在控制信息中
return qdisc_enqueue(skb, sch) & NET_XMIT_MASK; // 执行qdisc的入队列
}
static inline int qdisc_enqueue(struct sk_buff *skb, struct Qdisc *sch)
{
#ifdef CONFIG_NET_SCHED
if (sch->stab)
qdisc_calculate_pkt_len(skb, sch->stab);
#endif
return sch->enqueue(skb, sch); // 不同qdisc有不同的入队列策略
}
qdisc调度: qdisc_run()
qdisc调度才会真正的将数据包发送给设备驱动。调度过程有如下要点:
- 一个qdisc同一时刻只有一个CPU在调度执行,这是通过__QDISC_STATE_RUNNING状态标记实现的;
- 调度是有策略的,每次调度执行最多执行一个时钟滴答,如果在一个时钟滴答内没有发送完所有的数据包,那么在发送软中断中重新进行下一次调度,以此往复知道所有数据发送完毕。这种策略显然是为了防止CPU被长期占用进而影响系统整体的性能;
static inline void qdisc_run(struct Qdisc *q)
{
// 如果qdisc没有被调度,则设置正在调度状态标记并进行调度
if (!test_and_set_bit(__QDISC_STATE_RUNNING, &q->state))
__qdisc_run(q);
}
void __qdisc_run(struct Qdisc *q)
{
unsigned long start_time = jiffies;
// 循环将数据包发送给网络设备驱动程序。
// 返回0表示不能继续发送了;此时要么数据已经发送完了,要么设备不允许继续发送了(如硬件队列已满);
// 返回非0表示还有数据包需要发送,一般会返回队列长度,即剩余还有多少数据包需要发送
while (qdisc_restart(q)) {
/*
* Postpone processing if
* 1. another process needs the CPU;
* 2. we've been doing it for too long.
*/
// 如注释所述,这里是为了避免发送过程持续太长。这种场景下,
// 设备还有数据要发,所以调用netif_schedule()激活发送软中断继续处理
if (need_resched() || jiffies != start_time) {
__netif_schedule(q);
break;
}
}
// 退出时清除正在调度状态标记,让其它CPU可以继续调度该队列
clear_bit(__QDISC_STATE_RUNNING, &q->state);
}
出队列: qdisc_restart()
该函数从队列中取一个数据包,然后将数据包发送给网络设备驱动,如上所分析,其返回值会影响是否继续执行调度。
和入队列类似,具体以何种策略出队列也是qdisc相关的,不同的qdisc有不同的策略,这里不再详细展开。
/*
* NOTE: Called under dev->queue_lock with locally disabled BH.
*
* __LINK_STATE_QDISC_RUNNING guarantees only one CPU can process this
* device at a time. dev->queue_lock serializes queue accesses for
* this device AND dev->qdisc pointer itself.
*
* netif_tx_lock serializes accesses to device driver.
*
* dev->queue_lock and netif_tx_lock are mutually exclusive,
* if one is grabbed, another must be free.
*
* Note, that this procedure can be called by a watchdog timer
*
* Returns to the caller:
* 0 - queue is empty or throttled.
* >0 - queue is not empty.
*
*/
static inline int qdisc_restart(struct Qdisc *q)
{
struct netdev_queue *txq;
int ret = NETDEV_TX_BUSY;
struct net_device *dev;
spinlock_t *root_lock;
struct sk_buff *skb;
// 从qdisc出队列一个数据包,如果返回为NULL,则说明qdisc不允许
// 发送或者已经全部发送完毕,返回0结束qdisc调度
if (unlikely((skb = dequeue_skb(q)) == NULL))
return 0;
root_lock = qdisc_lock(q);
/* And release qdisc */
spin_unlock(root_lock);
// 前面已经为skb选择好了发送队列
dev = qdisc_dev(q);
txq = netdev_get_tx_queue(dev, skb_get_queue_mapping(skb));
// 将数据包发送给设备驱动
HARD_TX_LOCK(dev, txq, smp_processor_id());
if (!netif_tx_queue_stopped(txq) && !netif_tx_queue_frozen(txq))
ret = dev_hard_start_xmit(skb, dev, txq);
HARD_TX_UNLOCK(dev, txq);
// 根据发送结果分情况处理
spin_lock(root_lock);
switch (ret) {
case NETDEV_TX_OK:
// 发送成功,返回剩余数据包数目
ret = qdisc_qlen(q);
break;
case NETDEV_TX_LOCKED:
// 设备持锁失败,那么进行CPU冲突相关处理。主要是进行统计,并将
// 数据包重新入队列,然后返回队列中剩余数据包数目
ret = handle_dev_cpu_collision(skb, txq, q);
break;
default:
// 本次发送失败,将数据包重新入队列,然后返回队列中剩余数据包数目
if (unlikely (ret != NETDEV_TX_BUSY && net_ratelimit()))
printk(KERN_WARNING "BUG %s code %d qlen %d\n",
dev->name, ret, q->q.qlen);
ret = dev_requeue_skb(skb, q);
break;
}
// 这种情况是驱动程序暂停了发送队列,比如硬件队列满了。返回0结束qdisc调度
if (ret && (netif_tx_queue_stopped(txq) || netif_tx_queue_frozen(txq)))
ret = 0;
return ret;
}
激活发送软中断: __netif_schedule()
如果一次qdisc调度无法将所有数据包都发送完毕,那么就会通过__netif_schedule()触发发送软中断,在软中断中进行下一次调度来继续发送数据包。
void __netif_schedule(struct Qdisc *q)
{
// 如果qdisc还没有被调度,则设置调度标记并进行调度,__QDISC_STATE_SCHED状态标记
// 确保了一个qdisc同时只会被一个CPU调度
if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state))
__netif_reschedule(q);
}
static inline void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
// 获取当前CPU的发送队列,将qdisc接入队列并激活发送软中断
sd = &__get_cpu_var(softnet_data);
q->next_sched = sd->output_queue;
sd->output_queue = q;
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
}
在设备接口层初始化中有看到在系统初始化时,分配了一个cpu相关的全局收发队列,其类型为struct softnet_data,其中有两个字段和发送过程相关。
/*
* Incoming packets are placed on per-cpu queues so that
* no locking is needed.
*/
struct softnet_data
{
// 当前CPU调度的待发送Qdisc链表
struct Qdisc *output_queue;
// 发送完成队列,用于释放发送完毕的skb,见net_tx_action()
struct sk_buff *completion_queue;
};
发送数据包到设备驱动
如上面分析,无论是哪种发送方式,最终设备接口层都是通过dev_hard_start_xmit()函数将数据包发送给设备驱动程序的。
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
const struct net_device_ops *ops = dev->netdev_ops;
prefetch(&dev->netdev_ops->ndo_start_xmit);
// 数据包由一个skb组成
if (likely(!skb->next)) {
// 这里提供了一种勾取发送报文的方式,向注册在ptype_all中的所有勾子函数都发送一份数据包
if (!list_empty(&ptype_all))
dev_queue_xmit_nit(skb, dev);
// GSO处理
if (netif_needs_gso(dev, skb)) {
if (unlikely(dev_gso_segment(skb)))
goto out_kfree_skb;
if (skb->next)
goto gso;
}
// 将数据包发送给驱动程序
return ops->ndo_start_xmit(skb, dev);
}
gso:
// 发送的是一个skb列表,按照顺序将一片片的数据包分别递交给驱动程序
do {
struct sk_buff *nskb = skb->next;
int rc;
skb->next = nskb->next;
nskb->next = NULL;
rc = ops->ndo_start_xmit(nskb, dev);
if (unlikely(rc)) {
nskb->next = skb->next;
skb->next = nskb;
return rc;
}
if (unlikely(netif_tx_queue_stopped(txq) && skb->next))
return NETDEV_TX_BUSY;
} while (skb->next);
skb->destructor = DEV_GSO_CB(skb)->destructor;
out_kfree_skb:
kfree_skb(skb);
return 0;
}
HARD_TX_LOCK锁
如果驱动程序在dev->feature字段中设置了NETIF_F_LLTX标记,表示驱动内部能够保证并发调用hard_start_xmit()函数不出问题。
如果驱动没有设置NETIF_F_LLTX标记,那么框架就使用net_device中的自旋锁__xmit_lock来确保同时只有一个CPU能执行发送过程。持有该锁时,将dev->xmit_lock_owner被设置为当前持锁的CPU ID。
#define HARD_TX_LOCK(dev, cpu) { \
if ((dev->features & NETIF_F_LLTX) == 0) { \
__netif_tx_lock(dev, cpu); \
} \
}
#define HARD_TX_UNLOCK(dev) { \
if ((dev->features & NETIF_F_LLTX) == 0) { \
netif_tx_unlock(dev); \
} \
}
/**
* netif_tx_lock - grab network device transmit lock
* @dev: network device
* @cpu: cpu number of lock owner
*
* Get network device transmit lock
*/
static inline void __netif_tx_lock(struct net_device *dev, int cpu)
{
spin_lock(&dev->_xmit_lock);
dev->xmit_lock_owner = cpu;
}
static inline void netif_tx_unlock(struct net_device *dev)
{
dev->xmit_lock_owner = -1;
spin_unlock(&dev->_xmit_lock);
}
勾取发送报文
发送过程中,如果ptype_all链表非空,就会调用dev_queue_xmit_nit()函数将要发送的数据包复制一份给监听者,以此可以实现对发送报文的勾取。类似的,skb_receive_skb()中有类似的逻辑可以勾取接收报文。
/*
* Support routine. Sends outgoing frames to any network
* taps currently in use.
*/
static void dev_queue_xmit_nit(struct sk_buff *skb, struct net_device *dev)
{
struct packet_type *ptype;
// 设置时间戳
net_timestamp(skb);
rcu_read_lock();
// 遍历ptype_all链表
list_for_each_entry_rcu(ptype, &ptype_all, list) {
/* Never send packets back to the socket
* they originated from - MvS (miquels@drinkel.ow.org)
*/
// 匹配dev参数,检查af_packet_priv是为了防止出现”发送-接收“死循环
if ((ptype->dev == dev || !ptype->dev) &&
(ptype->af_packet_priv == NULL ||
(struct sock *)ptype->af_packet_priv != skb->sk)) {
// 克隆一份skb
struct sk_buff *skb2= skb_clone(skb, GFP_ATOMIC);
if (!skb2)
break;
/* skb->nh should be correctly
set by sender, so that the second statement is
just protection against buggy protocols.
*/
skb_reset_mac_header(skb2);
if (skb_network_header(skb2) < skb2->data ||
skb2->network_header > skb2->tail) {
if (net_ratelimit())
printk(KERN_CRIT "protocol %04x is "
"buggy, dev %s\n",
skb2->protocol, dev->name);
skb_reset_network_header(skb2);
}
skb2->transport_header = skb2->network_header;
// 设置数据包的类型为PACKET_OUTGOING
skb2->pkt_type = PACKET_OUTGOING;
// 调用上层协议提供的回调
ptype->func(skb2, skb->dev, ptype, skb->dev);
}
}
rcu_read_unlock();
}
发送软中断: net_tx_action()
从上面的代码中看到,发送软中断非常重要,正是它才能不断的调度qdisc,最终才能够将所有的数据包都发送给网络设备驱动。
发送软中断有如下要点:
- 依次处理当前CPU的softnet_data中所有等待调度的qdisc;
- 释放当前CPU的softnet_data中所有发送完毕的skb;
static void net_tx_action(struct softirq_action *h)
{
// 获取当前CPU上面的softnet_data
struct softnet_data *sd = &__get_cpu_var(softnet_data);
// completion_queue队列的目的是让驱动程序将数据发送完毕后,如果想要快速退出,
// 可以延后执行数据包的回收。可以将待释放的数据包放入该队列,释放动作会在软中断中完成
if (sd->completion_queue) {
struct sk_buff *clist;
// 注意这种优化写法:先关中断,把数据从队列中摘下来,再开中断,由于free动作比较耗时,
// 而该队列是所有设备共享的,这种设计可以保证关中断的时间尽可能的短
local_irq_disable();
clist = sd->completion_queue;
sd->completion_queue = NULL;
local_irq_enable();
// 释放这些SKB
while (clist) {
struct sk_buff *skb = clist;
clist = clist->next;
WARN_ON(atomic_read(&skb->users));
__kfree_skb(skb);
}
}
// 尝试发送output_queue中的数据包
if (sd->output_queue) {
struct Qdisc *head;
// 类似completion_queue的优化处理
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
local_irq_enable();
// 遍历所有等待调度的qdisc
while (head) {
struct Qdisc *q = head;
spinlock_t *root_lock;
head = head->next_sched;
root_lock = qdisc_lock(q);
if (spin_trylock(root_lock)) {
smp_mb__before_clear_bit();
// 尝试通过流量控制机制发送,这里之所以能肯定使用了流量控制机制,是因为如果不使用,
// 那么在dev_queue_xmit()中就直接调用驱动的发送接口发送了,根本不会激活发送软中断
// 另外,注意这里为了尽可能的块,使用的是trylock()版本的持锁方式,也表达了这里只是
// 尽最大努力发送的意思,如果本次不能发送,那么就再次调度,等待下次软中断机会
clear_bit(__QDISC_STATE_SCHED, &q->state);
qdisc_run(q);
spin_unlock(root_lock);
} else {
// 持锁失败重新调度
if (!test_bit(__QDISC_STATE_DEACTIVATED, &q->state)) {
__netif_reschedule(q);
} else {
smp_mb__before_clear_bit();
clear_bit(__QDISC_STATE_SCHED, &q->state);
}
}
}
}
}
驱动程序可以通过dev_kfree_skb_in_irq()或dev_kfree_skb_any()将发送完毕的数据包放到当前CPU的softnet_data.complete_queue中。
看门狗定时器
当网络设备被打开后,驱动程序有可能会临时性的关闭发送队列(如硬件队列已满),如果在一定时间内驱动程序没有再次将队列打开,那么设备接口层就会认为驱动异常了。为了实现这样的检测机制,在dev_activate()中会为net_device启动一个看门狗定时器,默认的超时时长为5s,驱动也可以根据自身情况进行修改,定时器超时处理函数为dev_watchdog()。
static void dev_watchdog(unsigned long arg)
{
struct net_device *dev = (struct net_device *)arg;
netif_tx_lock(dev);
if (!qdisc_tx_is_noop(dev)) { // 排队规则有效
if (netif_device_present(dev) && // 设备已打开
netif_running(dev) &&
netif_carrier_ok(dev)) { // 链路状态ok
int some_queue_stopped = 0;
unsigned int i;
// 统计是否有发送队列被关闭
for (i = 0; i < dev->num_tx_queues; i++) {
struct netdev_queue *txq;
txq = netdev_get_tx_queue(dev, i);
if (netif_tx_queue_stopped(txq)) {
some_queue_stopped = 1;
break;
}
}
// 如果最近一次发送报文的时间已经超过了watchdog的时长,打印告警信息
// 并且回调驱动程序的ndo_tx_timeout()
if (some_queue_stopped &&
time_after(jiffies, (dev->trans_start + dev->watchdog_timeo))) {
char drivername[64];
WARN_ONCE(1, KERN_INFO "NETDEV WATCHDOG: %s (%s): transmit timed out\n",
dev->name, netdev_drivername(dev, drivername, 64));
dev->netdev_ops->ndo_tx_timeout(dev);
}
// 重启WatchDog定时器
if (!mod_timer(&dev->watchdog_timer, round_jiffies(jiffies + dev->watchdog_timeo)))
dev_hold(dev);
}
}
netif_tx_unlock(dev);
dev_put(dev);
}
从实现可以看出,驱动程序可以通过实现ndo_tx_timeout()回调来处理这种超时异常,比如在回调中可以复位网卡。
小结
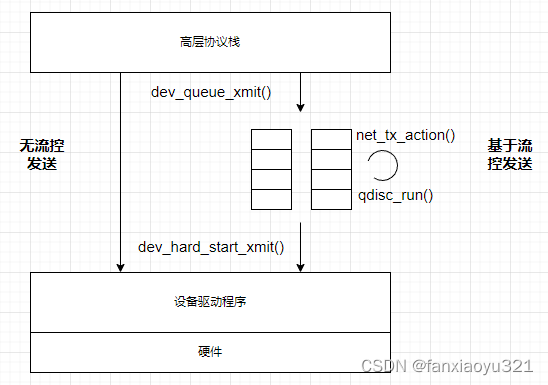
最后来回顾下设备接口层的数据包发送过程:
- 高层协议将数据包准备好后,调用dev_queue_xmit()将数据包发送给设备接口层,这里面有个非常重要的前提是高层协议已经确定数据包要从哪一个网络设备发出(设置了skb->dev字段);
- 在dev_queue_xmit()中进行线性化、校验和等处理后,根据是否启用了流量控制,分为两种发送处理流程:基于流控的发送和无流量控制发送,下面我们在只看基于流控的发送;
- 对于基于流控的发送过程,先将数据包入队列,然后调用qdisc_run()启动qdisc调度,如果一次调度无法将数据包发送完毕,则会在发送软中断中继续调度qdisc,直到所有数据包都发送给设备驱动为止;
- 发送软中断依次处理发送softnet_data.ouput_queue中等待调度的qdisc,处理时同样是使用qdisc_run()函数。如果一次软中断中无法调度完毕,那么就继续激活下一次软中断,如此反复,直到所有的qdisc都调度完毕为止;
- 无流控的发送过程就非常简单,在dev_queue_xmit()中直接将数据包发送给设备驱动。
上述过程可以用下图表示:














 2978
2978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









