







人工智能的由来
人工智能的发展得益于信息化技术,人工智能也就是信息化发展的新阶段,是新一轮科技革命和产业变革的前沿领域,是培育新动能的重要方向。
谈到信息化,我们应该谈到两个人及其理论,首先想到了“现代计算机之父”—冯.诺依曼,他在二十世纪四十年代,设计了经典的冯.诺依曼结构,就是将软件命令和数据都存在一起,把程序本身当做数据来对待,整个设备由中央处理器,内存,硬盘,输入接口,输出设备组合而成。今天,我们仍然采用这样的结构开发人工智能软件。
其次就是“信息论之父”—香农(Claude Shannon),信息是个很抽象的概念,很难量化描述,直到1948年,美国的数学家香农提出了“信息熵”的概念,才解决了对信息的量化、度量问题。信息熵可理解成某种特定信息的出现概率,在机器学习、深度学习、强化学习中得到大量的应用。
人工智能(Artificial Intelligence)概念,是在1956年达特茅斯(Dartmouth)学会上提出的。达特茅斯会议主要发起人有当时在达特茅斯学院数学系任教的麦卡锡(John McCarthy)及在哈佛大学任教的明斯基(Marvin Minsky)。后来,麦卡锡被称为“人工智能之父”,也是Lisp语言的发明者,马文.明斯基(Marvin Minsky)是人工神经网络(ANNs)领域的早期贡献者,以及重要的参会者还有信息论之父香农等等。英国科学家图灵(Alan Turing)做给出了最早的智慧定义。在图灵逝世14年后,他的论文原稿《智能机器》才被大家所发现,在《科学美国人》杂志上发表,图灵也被称为“人工智能之父”。
现代人工智能标志性的事件是1997年5月,在超级电脑“深蓝”在国际象棋上打败国际象棋冠军卡斯特洛夫,以及这二十年之后,2016年3月人工智能Alpha GO才在围棋上击败了李世石。“深蓝”以暴力穷举为基础的特定用途人工智能,而AlphaGo是几乎没有特定领域知识的、基于深度学习、泛化的人工智能。“深蓝”是以超级计算机为代表的一个象征性的人工智能里程碑,而AlphaGo则更具实用意义,接近实用的人工智能。
中间这二十年,是计算机硬件、软件飞速发展的二十年,虽然是人工智能沉寂了,但是,人们对人工智能的研究没有止步。人工智能随计算机技术和信息化技术的发展,大数据、机器学习、深度学习等人工智能技术也得到快速发展。可以说,没有计算机软硬件的飞速发展,也很难有今天的人工智能风口浪尖。
自从2016年3月,Alpha Go在围棋上击败李世石,人工智能迎来发展新的高峰,政府、企业、科研机构纷纷布局人工智能,例如大学开设人工智能课程,这将会使人工智能产业不断向前发展,并与传统产业结合,同时我们将会迎接更多的人工智能产品走进我们的生活。
什么是人工智能?
1891年,德国解剖学家瓦尔德尔(Wilhelm Waldeyer)提出了“神经元学说”,人们认为人脑中约有上千亿个神经元,以及这些神经元被上百万亿的突触链接,从而形成庞大、复杂的神经网络(neural network)。思维学认为,人的大脑的思维有三种基本方式:逻辑思维、形象思维和灵感思维。其中逻辑思维是根据逻辑规则进行推理的过程,这一过程已经可以由计算机代替完成。而形象思维是将分布式存储的信息综合起来想出解决问题的方法。这种思维方式有以下两个特点:一是信息在神经元上的分布存储,二是神经元之间的同时相互作用并做出决策的过程。人工智能(简称AI, Artificial Intelligence)就是模拟这一种形象思维方式。
通俗的按计算机技术来说,人工智能就是使用计算机及相关硬件、软件系统、程序及数学算法集成为统一整体,来模拟人类感知、思维和行为的方式,来实现目前必须借助人类智慧才能实现的工作。从应用范围层面来说,人工智能有狭义和广义之分:狭义的人工智能是指其主要是通过软件和算法的设计及优化,模拟人类的智能行为和思维方式,在特定领域完成单一任务,比如现阶段的照片识别、语音处理,自动驾驶,“Alpha Go”就属于这一个范畴。而广义的人工智能则是指是包括硬件发展在内进一步模拟人脑,可以跨领域解决不同的问题,具有像人一样的推理和思考能力。
人工智能发展历史
最早的神经网络的思想起源于美国心理学家麦卡洛克(Warren McCullock)和数学家皮特斯(Walter Pitts)在1943年首次提出的MCP人工神经元模型,一个简化版大脑细胞的概念,当时是希望能够用计算机来模拟人的神经元反应的过程。在同时代,冯.诺依曼设计出了经典计算机结构。1950年,图灵发表了题为《机器能思考吗》的论文,在论文里提出了著名的“图灵测试”。图灵测试由计算机、被测试的人和主持试验的人组成。人们这些研究,终于在1956年达特茅斯(Dartmouth)学会上,由麦卡锡等人提出了”人工智能“。
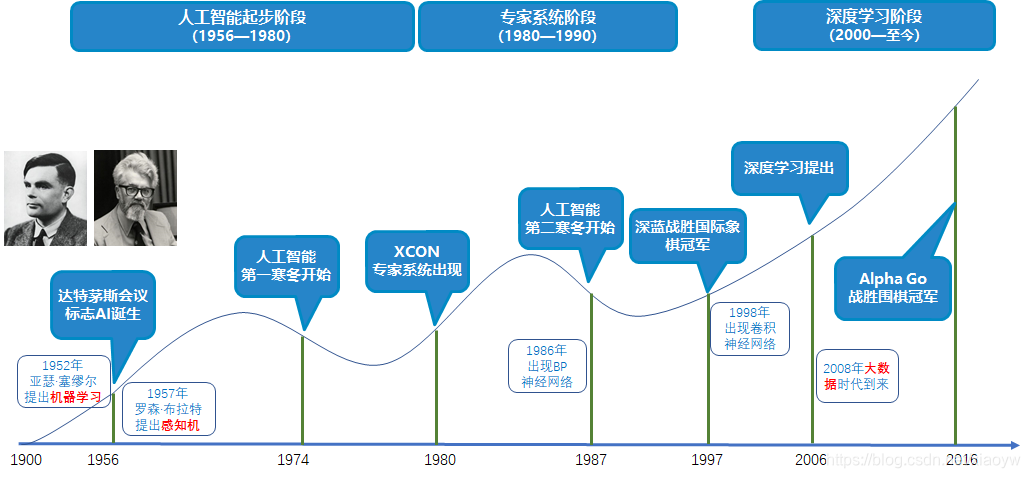
上图人物分别是图灵(左)和麦卡锡(右)。
1、人工智能起步阶段(1956—1980)
最早的神经网络的思想起源于1943年的MCP人工神经元模型,当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。
1958年罗森.布拉特(Rosenblatt)发明的感知器(perceptron)算法。该算法使用MCP模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。1969年,美国数学家及人工智能先驱Minsky在其著作中证明了感知器本质上是一种线性模型,只能处理线性分类问题,就连最简单的XOR(亦或)问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了近20年的停滞。
2、 专家系统阶段(1980—1990)
1965年在美国国家航空航天局要求下,斯坦福大学成功研制了DENRAL专家系统,到20世纪70年代中期,专家系统已逐步成熟起来,专家系统时代最成功的案例是 DEC 的专家配置系统 XCON。DEC 是 PC 时代来临之前的宠儿,他们用小型机冲击 IBM。当客户订购 DEC 的 VAX 系列计算机时,XCON 可以按照需求自动配置零部件。从 1980 年投入使用到 1986 年,XCON 一共处理了八万个订单。
第一次打破非线性诅咒的是深度学习之父——弗里.辛顿(Geoffreg Hinton),在1986年发明了适用于多层感知器(MLP)的BP算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。该方法引起了神经网络的第二次热潮。
1989年,Robert Hecht-Nielsen证明了MLP的万能逼近定理,即对于任何闭区间内的一个连续函数f,都可以用含有一个隐含层的BP网络来逼近该定理的发现极大的鼓舞了神经网络的研究人员。同年,LeCun发明了卷积神经网络-LeNet,并将其用于数字识别,且取得了较好的成绩,不过当时并没有引起足够的注意。
虽然,1997年,LSTM模型被发明,尽管该模型在序列建模上的特性非常突出,但由于正处于NN的下坡期,也没有引起足够的重视。
3、深度学习阶段(2000—至今)
1986年,弗里·辛顿提出了一种适用于多层感知器的反向传播算法——BP算法,让人工神经网络再次的引起了人们广泛的关注。同时期,计算机的计算能力得到快速发展,特别是进入二十一世纪,计算机软件、硬件的快速发展,为神经网络,特别是深度神经网络的研究提供了算力资源,陆续出现了CNN、RNN。
在2006年深度学习理论被正式提出后 ,卷积神经网络的表征学习能力得到了关注,并随着数值计算设备的更新开始快速发展 。自2012年的AlexNet 开始,卷积神经网络多次成为ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)的优胜算法,包括2013年的ZFNet 、2014年的VGGNet、GoogLeNet 和2015年的ResNet 。
其中,随着2008年大数据时代的到来,由于数据量增大,神经网络深度加深等情况越来越普遍,计算机GPU的重要性被突显出来,拥有CPU的计算机,其算力,特别是图像处理能力特到大幅的提升。大数据、机器学习的发展,人工智能爆发式的发展起来。
2017年7月20日,国务院印发《新一代人工智能发展规划》(以下简称规划),该规划提出了面向2030年我国新一代人工智能发展的指导思想、战略目标、重点任务和保障措施,部署构筑我国人工智能发展的先发优势,加快建设创新型国家和世界科技强国。
随着人工智能落地、推广,各行各业急需大量人工智能研发技术人员,扩大人工智能在我们生活中的应用,以及人工智能与工业生产广泛的融合。
人工智能知识体系
从机器学习和IT的视角来看,人工智能很大一部分是数据治理与挖掘,机器学习属于数据治理与挖掘的子集,机器学习又包括深度学习、强化学习子集。如下图所示。
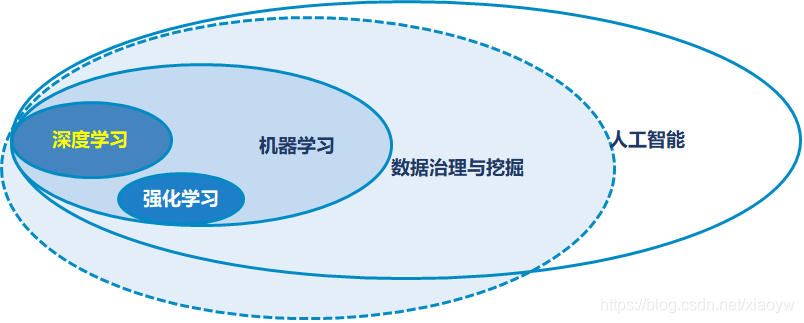
机器学习
“机器学习”的概念提出者是亚瑟.塞缪尔于1952年提出来的,“使计算机在没有明确编程的情况下进行学习”。今天,机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,机器学习是对能通过经验自动改进的计算机算法的研究,
什么是机器学习?
机器学习(简称ML, Machine Learning)是对于某给定的任务T,在合理的性能度量方案P的前提下,某计算机程序可以自主学习任务T的经验E;随着提供合适、优质、大量的经验E,该程序对于任务T的性能逐步提高。
这里最重要的是机器学习的对象:
*任务Task,T,一个或者多个
*经验Experience,E
*性能Performance,P
基于人工智能来描述,机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
机器学习是实现人工智能的一种途径,它和数据挖掘有一定的相似性,也是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。对比于数据挖掘从大数据之间找相互特性而言,机器学习更加注重算法的设计,让计算机能够白动地从数据中“学习”规律,并利用规律对未知数据进行预测。因为学习算法涉及了大量的统计学理论,与统计推断联系尤为紧密,所以也被称为统计学习方法。
机器学习为数据挖掘提供了理论方法,而数据挖掘技术是机器学习技术的一个应用场景。数据挖掘一般是指从大量的数据中通过算法搜索、分析隐藏于其中信息的过程。数据挖掘与机器学习关系上像是机器学习和人工智能的基础,它的主要目的是从各种各样的数据源中,按需求提取出信息,然后将这些信息整合,发现新的的模式和内在关系。
机器学习可以分为以下六个大类:
(1)监督学习:从给定的训练数据集中学习出-一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是输人和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归与分类。
(2)无监督学习:无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类等。
(3)半监督学习:这是一"种介于监督学习与无监督学习之间的方法。
(4)迁移学习:将已经训练好的模型参数迁移到新的模型来帮助新模型训练数据集。
(5)深度学习:的学名又称“深层神经网络”(deep neural network),是从人工神经网络模型演变而来,其对应的是“浅层(单层或双层)神经网络”。
(6)强化学习:通过观察周围环境来学习。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
传统的机器学习算法有以下几种:线性回归模型、logistic回归模型、k-临近算法、决策树、随机森林、支持向量机、人工神经网络、EM算法、概率图模型等。
深度学习
什么是深度学习?
深度学习(简称DL, Deep Learning)是机器学习领域中一个分支,研究人工神经网络方向,它被引入机器学习使其更接近于最初的目标——人工智能。
深度学习是基于人工神经网络学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像、行为和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别并处理文字、图像和声音等数据。
深度学习在搜索技术、数据挖掘、机器学习、机器翻译、自然语言处理、多媒体学习、语音、知识图谱、推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
从结构上来说,“深度学习”的学名又称“深层神经网络”(deep neural network),是从人工神经网络模型演变而来,其对应的是“浅层(单层或双层)神经网络”。由于这一类模型一般采用计算机科学中的网络图模型来直观表达,“深度”即是指网络图模型的层数以及每一层的节点数量。
深度学习的特征
深度学习的方式
以识别狗和猫为例,如果是传统机器学习的方法,我们会首先定义一些特征,比如胡须,耳朵、鼻子、嘴巴的特征等等。这样,我们首先要确定相应的“面部特征”作为我们的机器学习的特征,以此来对我们的对象进行分类识别。
而现在,深度学习的方法则更进一步。深度学习自动地找出这个分类问题所需要的重要特征!由于这些特征不被人们所了解,也就是很难解释。而传统机器学习则需要我们人工地给出特征!
深度学习的优点
在大数据的前提下,深度学习提出了一种让计算机自动学习模式特征的方法,并将特征学习融入到了建立模型的过程中,从而减少了人为设计特征造成的不完备性。而目前以深度学习为核心的某些机器学习应用,在满足特定条件的应用场景下,已经达到了超越现有算法的识别或分类性能。
深度学习的缺点
深度学习虽然能够自动的学习模式的特征,并可以达到很好的识别精度,但这也恰恰是深度学习存在的一个缺点:也就是说在只能提供有限数据量的应用场景下,深度学习算法便不能够对数据的规律进行准确的归类和总结,因此在识别效果上可能不如一些已有的简单算法。另外,由于深度学习中,图模型的复杂化导致了这个算法的时间复杂度急剧提升,为了保证算法的实时性,需要更高的并行编程技巧以及更好更多的硬件支持(比如GPU阵列)。所以,目前也只有一些经济实力比较强大的科研机构或企业,才能够用深度学习算法,来做一些比较前沿而又实用的应用。
深度学习的局限
从功能上来说,目前深度学习的应用集中于人工智能中的模式识别,如图像/语音识别等。但是在人脑中,识别功能仅仅是其中一小部分,甚至不是核心部分。人脑的核心功能在于学习和运用。目前而言,深度学习仅仅能对特定条件下的信息进行处理,从而达到特定的目的。导致深度学习在功能上趋近与大脑的原因,很大程度上是由于目前深度学习中的神经元模型和突触模型还没有突破传统模型的限制。
强化学习
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
————周志华《机器学习》
人工智能的未来
新一代人工智能AI2.0,AI 2.0时代大数据人工智能具体表现为:从浅层计算到深度神经推理;从单纯依赖于数据驱动的模型到数据驱动与知识引导相结合学习;从领域任务驱动智能到更为通用条件下的强人工智能(从经验中学习)。下一代人工智能(AI 2.0)将改变计算本身,将大数据转变为知识,以支持人类社会更好决策。


















 4268
4268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











