







百度指数是百度公司推出的一项基于海量网民行为数据的数据分享平台,它利用百度搜索引擎的海量数据,通过科学的数据分析模型,计算并分析关键词在百度网页搜索中搜索频次的加权和,以反映不同关键词在过去一段时间里的“用户关注度”和“媒体关注度”。百度指数可以展示关键词的搜索趋势、需求图谱、资讯指数、人群画像等,为企业的市场趋势分析、品牌监测、产品研究等提供有力的数据支持。
最近我们将2011-2023年所有城市的城市间搜索指数爬取完成,并整理为矩阵形式,耗时多日。整个数据集大小2个多G,源数据样本量达数十亿条,并整理为分年矩阵形式。
一、数据名称:
城市级百度指数搜索日月年源数据+城市间矩阵
二、范围:
2011-2023年(包括日度源数据、月度汇总、年度汇总、年度矩阵)
百度指数收录的全国365个城市
三、数据来源:
百度指数
四、详情及部分截图:
1、城市VS城市矩阵
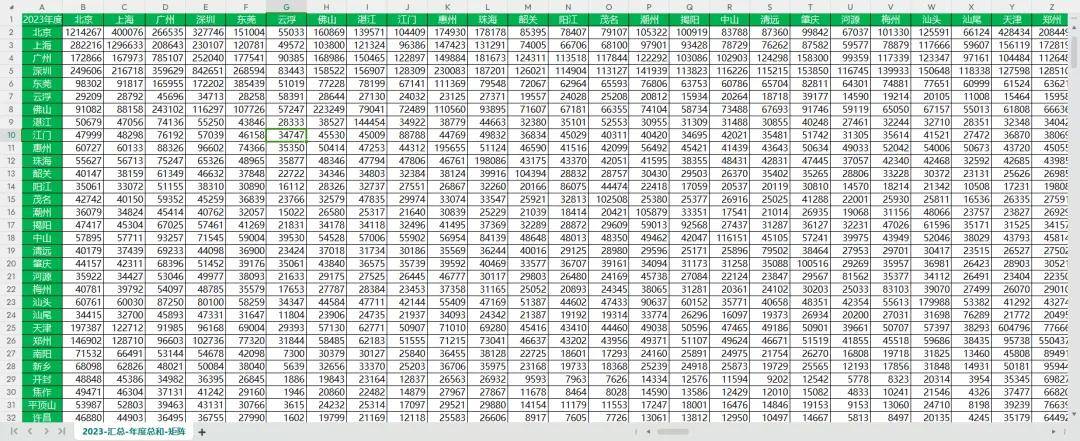
2、日度源数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









