






资源介绍

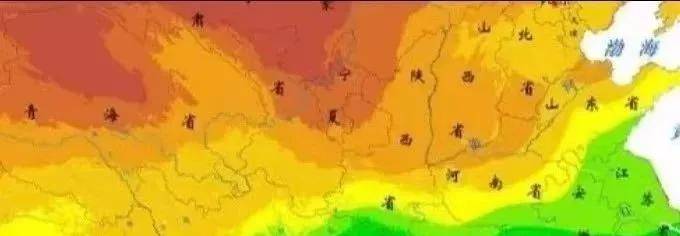
1950-2022全国各省、市、县逐年水文数据(降水量)
数据年份:1950-2022年,年度数据
数据范围:
省级数据:全国33省份(含直辖市,香港/台湾);
城市数据:全国371城市地级市、直辖市、地区州盟 ;
区县数据:全国2876区县、市辖区、自治县、县域县级市;
数据来源:欧盟及欧洲中期天气预报中心等组织发布的ERA5-Land数据集!
单位:m
单位换算到mm:需要换算*1000*365
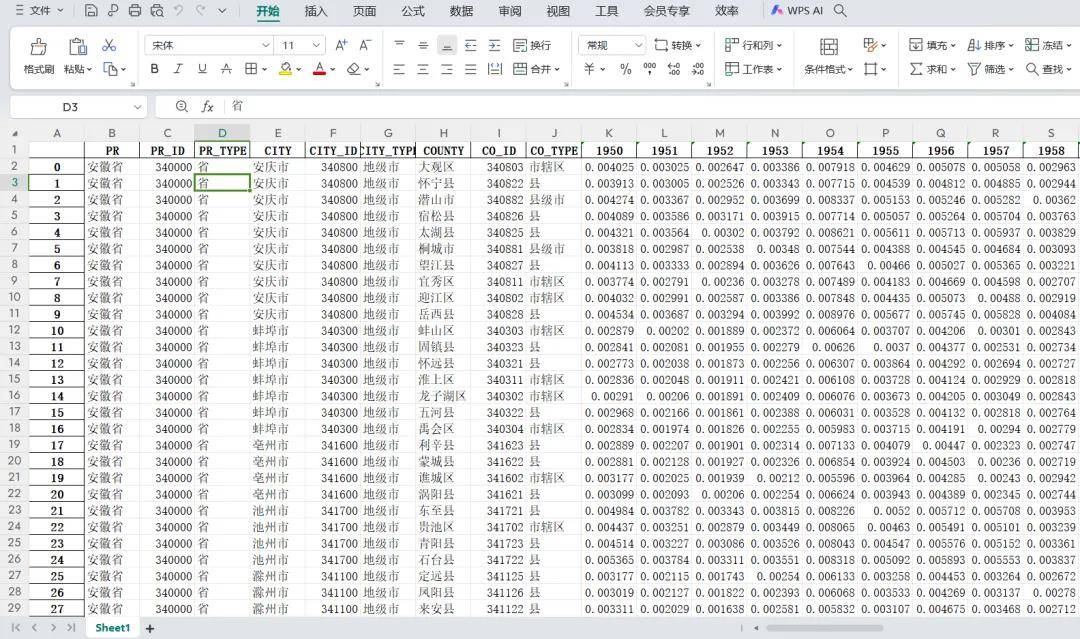
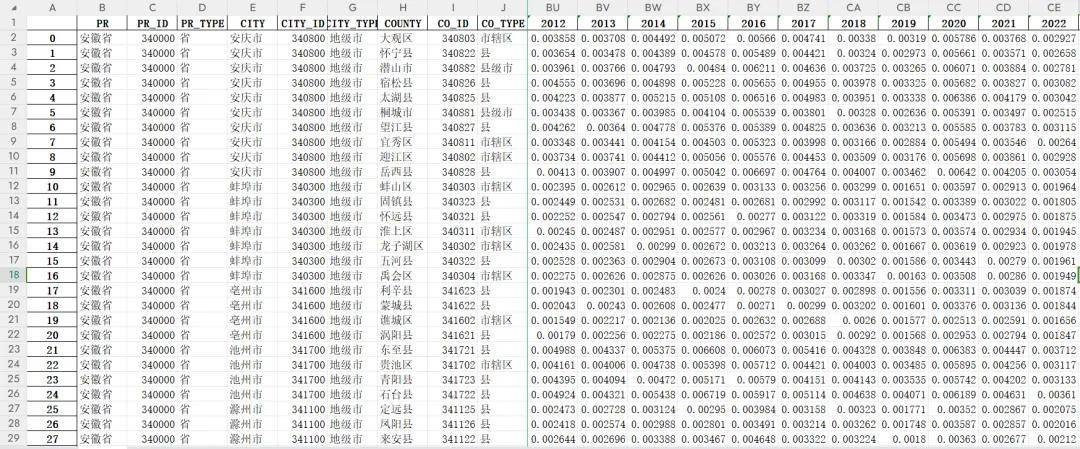
【下载→
方式一(推荐):主页 个人 简介
方式二:数据下载方式汇总-CSDN博客
资源介绍
1950-2022全国各省、市、县逐年水文数据(降水量)
数据年份:1950-2022年,年度数据
数据范围:
省级数据:全国33省份(含直辖市,香港/台湾);
城市数据:全国371城市地级市、直辖市、地区州盟 ;
区县数据:全国2876区县、市辖区、自治县、县域县级市;
数据来源:欧盟及欧洲中期天气预报中心等组织发布的ERA5-Land数据集!
单位:m
单位换算到mm:需要换算*1000*365
【下载→
方式一(推荐):主页 个人 简介
方式二:数据下载方式汇总-CSDN博客
 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























