









K Nearest Neighbor算法又叫KNN算法,是机器学习里面一个经典的算法。其中的K表示最接近自己的K个数据样本就,一般K取奇数,这是为了使投票的时候不会出现平票的情况。
算法直观理解:有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。
简单理解:由那离自己最近的K个点来投票决定待分类数据归为哪一类。
先引用Wikipedia上的KNN词条中有一个比较经典的图来说明下KNN算法:
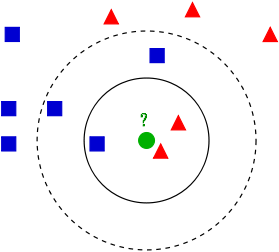
从上图中可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。


距离函数的定义:D( , )是距离函数,满足如下四个性质:
(1)非负性:D(X,X)>=0
(2) z自反性: D(X,Z)=0 当且仅当 X=Z
(3)对称性:D(X,Z)=D(Z,X)
(4)三角不等式:D(X,Z)<=D(X,V)+D(V,Z)
通常d维空间里的欧几里得距离能满足上述性质,而且我们常用此来计算,但务必注意:这样得到的距离值未必总是有意义的。例如,对每一个坐标轴乘以一个任意常数,虽然只是改变了每一个属性的单位,但是变换后的距离关系和原来的可能完全不同。

上图中,将x轴变为原来的1/3,这时原来(a)中黑点是最近的,在(b)中变成了灰色点。
KNN算法步骤:
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K-最近邻样本中每个类标号出现的次数
step.7---选择出现频率最大的类标号作为未知样本的类标号
时间复杂度计算:
假设属性空间的维数为l,训练样本数目为n。
KNN算法要做的就是寻找距离测试点 X 最近的 k 个训练样本,在最简单的 1-NN 方法中,需要搜索每一个训练样本点,找出距离X最近的那一个。假设采用的是欧几里得距离,计算测试点与一个训练样本的距离其复杂度为 O(l),因此这样的搜索方法总的计算复杂度为 O(l * n^2)。当训练数据集的规模很大,维数较多时,利用最邻近进行分类的时间比较长。
为了降低KNN的搜索复杂度,有3种通用的方法:1、降维法;2、预建结构法;3、训练集裁剪法。
K值的选取:
如果k足够大,能够覆盖所有训练样本,则变成了朴素贝叶斯模型,即哪一类的训练样本多(也就是出现的频率高),就判断为哪一类。结果会非常不准确。
如果k数值过小,决策边界将会变得很不稳定。训练样本的小变化将会导致分类结果的大变化。(例如去掉了距离 x 最近的一个样本的话,分类可能会完全变成另一个分类)。
实际当中k数值没有很好地选择方法,只能从另一方面来确定,即错误率的大小。将训练集分成两部分,训练集和验证集。对不同的k,使用验证集来检测错误率。选择错误率最小的k。
实际中的一些问题:
1、某个点刚好处于分界线上,距离两个类的距离是一样的
二类分类时:选择奇数k,可以避免这个问题。
多类分类时:a. 随机选择一类 (既然在边界线上了,选择某一类的成本会是一样的)
b. 选择先验概率最大的一类(训练样本中出现次数最多)
c. 使用1-NN,选择距离最近的一类。
2、 如何加快KNN算法的速度
a.减少矩阵的维度
b.不要和所有的训练样本进行比较,通过某种算法找到距离最近的一些,对这些进行运算。
K-Means 和 KNN的相似与区别:
之前有篇文章说过 K-Means 算法,点这里
相似点:都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。
区别:
| KNN | K-Means |
| 1.KNN是分类算法 2.监督学习 3.喂给它的数据集是带label的数据,已经是完全正确的数据 | 1.K-Means是聚类算法 2.非监督学习 3.喂给它的数据集是无label的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序 |
| 没有明显的前期训练过程,属于memory-based learning | 有明显的前期训练过程 |
| K的含义:来了一个样本x,要给它分类,即求出它的y,就从数据集中,在x附近找离它最近的K个数据点,这K个数据点,类别c占的个数最多,就把x的label设为c | K的含义:K是人工固定好的数字,假设数据集合可以分为K个簇,由于是依靠人工定好,需要一点先验知识 |
| | |
| | |
关于一些预测、判断和平滑的例子,可以参考一下这篇文章里面的例子,是直接翻译外文的,比较容易懂。















 1460
1460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









