







程序设计实验1 词法分析
一、实验目的:
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
二、实验内容
编制一个单词获取程序,从文件输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、整数、小数、字符串、字符、分隔符、运算符等八大类。
三、实验要求
1、词法规则
关键字: void、var、int、float、string、begin、end 、if、then、else、while、do、call、read、write、and、or
单词类别:1 注意:关键字大小敏感(区分大小写)。
标识符: 字母或 “ $ ” 打头、由字母、数字串或“$”组成的任意长度的符号串。
单词类别:2 注意:标识符大小敏感(区分大小写)。
整数: 数字串。
单词类别:3
小数: 数字串1. 数字串2
单词类别:4 注意:数字串1不能为空,数字串2可以为空,例如:23.
字符串: 由一对“”括起来的任意长度的符号串。注意:可以多行。
单词类别:5
字符: 由一对单引号括起来的单个字母。如:‘a’、‘5’、‘+’
单词类别:6
分隔符: {、}、(、)、;、空格
单词类别:7
运算符: ==、=、<、<=、>、>=、<>、+、-、*、/
单词类别:8
注释: 支持单行注释和多行注释(注释语法同C语言)。
为了实现的编译程序实用,这里规定源程序可采用自由书写格式,即一行内可以书写多个语句,一个语句也可以占领多行书写。
2、设计要求
(1)设计一个主程序,通过人机交互的方式或命令行参数获得需要分析的源代码文件,打开待分析的源程序,通过反复调用词法分析程序逐个获得源代码中的所有单词并输出。
整个程序的总体流程见图1-1。
(2)设计一个词法分析器,其输入为要分析的源文件,每次调用顺序识别出源文件中的下一个单词。每个单词需要输出:单词本身、单词类别、单词所在的行列号。遇到错误时可显示“Error”,然后跳过错误部分继续显示。
注意:在主程序中输出单词的信息,词法分析中不能输出单词信息,只能通过返回值或全局变量返回所提取的单词信息。
(3)实验结束后提交源代码、测试数据、实验报告至:
ftp://编译原理/程序设计1
本次实验提交的截止日期:2023-04-15 晚22:00 前.
(4)实验报告内容:(具体参见“编译原理程序设计实验报告模版.docx”)
(a) 有关词法分析器设计的说明。详细说明词法分析器的实现原理,包括软件结构设计说明、功能模块说明、关键数据结构说明、关键算法实现等。
(b) 给出词法分析器源程序清单,并标记出每个模块的功能;
© 说明词法分析器中可能存在的问题;
(d) 经验总结,如果重做一遍,你会有哪些新的改进?
四、实验过程和指导
(一)准备:
1、阅读课本有关章节,明确语言的语法,写出基本保留字、标识符、常数、运算符、分隔符和程序例。
2、初步编制好程序。
3、准备好多组测试数据,包括正确的输入和错误的输入。
(二)程序要求:
程序输入/输出示例:
如源程序为C语言。输入如下一段:
void main()
{
int a,b;
a = 10;
b = a + 20;
}
要求输出如下所示,每个单词输出:单词类型、单词本身、行号、列号。
(1,void,1, 1)
(2,main, 1, 6)
(7, ( ,1,10)
(7, ),1,11)
(7, { ,2, 1)
(1, int,3, 4)
(2, a ,3, 8)
(…
(三)设计指导:
词法分析程序的主要工作为:
(1)从源程序文件中逐个读入字符。
(2)统计行数和列数用于错误单词的定位。
(3)删除空格类字符,包括回车、制表符空格。
(4)根据每个单词的首字符确定该单词的类型,按构词规则从源文件中逐个读入字符检查该字符是否该单词的允许输入。
在编写词法分析程序时,用重复调用词法分析子程序取一单词的方法得到整个源程序的单词序列。
整个程序的总体流程见图1-1。
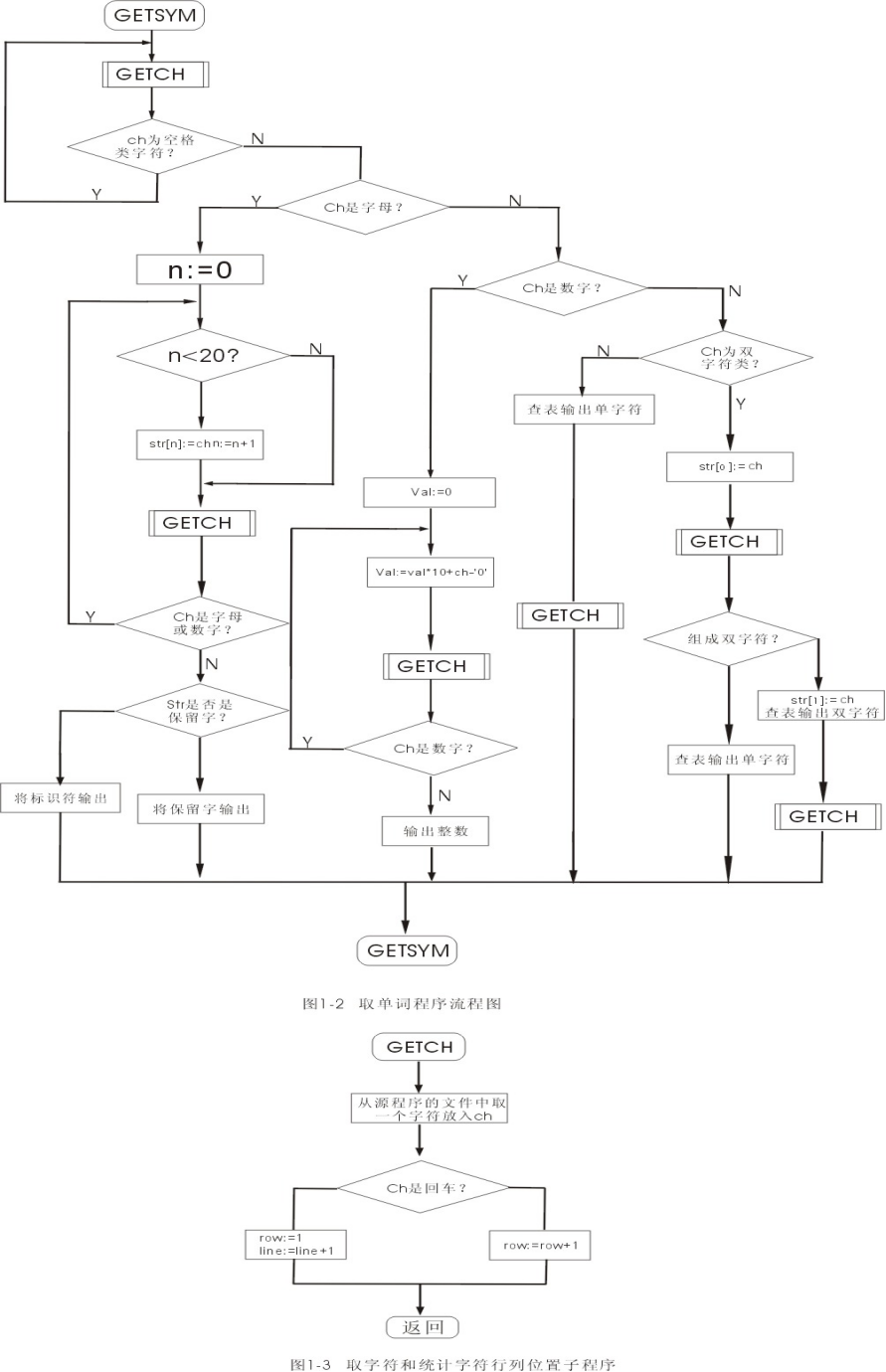
词法分析程序的流程图见图1-2。
取字符和统计字符行列位置子程序见图1-3。
注意:图1-2、图1-3仅供参考,并不完全符合本次实验的要求,仅仅说明整个词法分析程序的总体框架。因此,实验报告中不能直接贴图1-1、图1-2、图1-3,否则实验报告以无效处理。
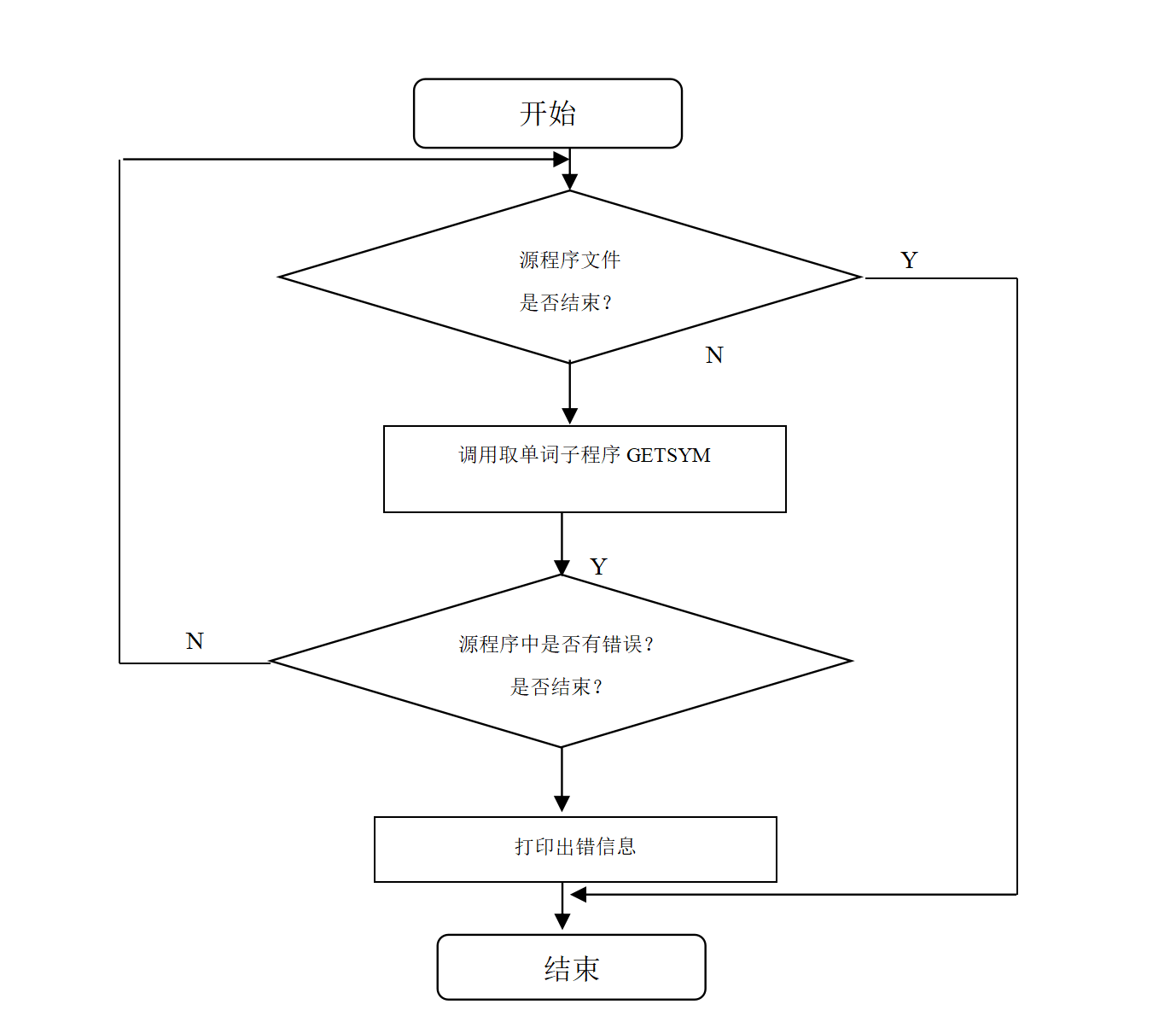
图1-1
源代码:
import java.util.Arrays;
import java.util.Scanner;
import java.util.*;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.regex.Pattern;
class Results{//保存要输出的结果
boolean rig;//是否是错误
int type;//记录类型
String res;//输出内容
int li=0,co=0;//所在行和列
}
public class Main {
static final int N=101;//定义一个常量,当输入增多时便于后续修改
static int a[]=new int [N];//该数组用来存放文本每行的列数(假设输入数据不超过100行)
static boolean ok=false;//记录每行第一个单词前是否有空格,如果有为true
static boolean mark=false;//如果判断出是注释的内容,是则为true,否则为false
static boolean biu=false;//当存在多行注释时为true
static int blank=0;//保存前面的空格数
static int k=0,lines,cols;//lines用来记录是第几行,cols记录第几列,不赋初值时自动为0
static int num=0;//记录每一行字符的个数
static boolean words=false;//当由""引起来的字符串占多行时为true
static String strs="";//保存多行字符串前面的内容
static Results RE[]=new Results[N];//保存一行中遇到的字符
static String keyWord[]={"void","var","int","float","string","begin","end","if",
"then","else","while","do","call","read","write","and","or"};//1 关键字
static String symbol[]={"{","}","(",")",";"," "};//7 分隔符
static String operation[]={"==","=","<","<=",">",">=","<>","+","-","*","/"};//8 运算符
static ArrayList<String> keyWords=null;//1 关键字
static ArrayList<String> symbols=null;//7 分隔符
static ArrayList<String> operations=null;//8 运算符
//关键字,字母或$的识别 1 2
public static void letterCheck(String str){
cols=k+1;
String token= String.valueOf(str.charAt(k++));
char ch;
for( ;k<str.length();k++){
ch=str.charAt(k);
if (!Character.isLetterOrDigit(ch)&&ch!='$')
break;
else
token+=ch;
}
if(ok)
cols+=blank;
if (keyWords.contains(token)){
RE[num].rig=true;RE[num].type=1;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
else{
RE[num].rig=true;RE[num].type=2;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
if (k!=str.length()-1||(k==str.length()-1&&(!Character.isLetterOrDigit(str.charAt(k))&&str.charAt(k)!='$')))
k--;
}
//数字的识别 3 4
//1、识别退出:遇到空格符,遇到运算符或者界符 2、错误情况:两个及以上小数点,掺杂字母
public static void digitCheck(String str){
cols=k+1;
String token= String.valueOf(str.charAt(k++));
int flag=0;//记录小数点的个数
boolean err=false;
char ch;
for( ;k<str.length();k++){
ch=str.charAt(k);
if(ch==' '||(!Character.isLetterOrDigit(ch)&&ch!='.')||
symbols.contains(ch)||operations.contains(ch))//遇到空格,运算符或者标识符则退出,属于正常退出
break;
else if (err)
token+=ch;
else{
token+=ch;
if (ch == '.') {//这个if判断是否存在多个小数点的情况
if(flag>=1)//如果之前已经记录有一个小数点了,那么此时就是错误
err=true;
flag++;//只要遇到小数点就加一
}
else if (Character.isLetter(ch))//遇到字母时是不对的
err=true;
}
}
if(token.charAt(token.length()-1)=='.'&&flag>=2)//如果最后的出的字符串最后一位是小数点,并且出现多个小数点则错误
err=true; //小数点前面不能为空,后面2可以为空
if(err){
RE[num].rig=false;RE[num].type=-1;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
else{
if(ok)
cols+=blank;
if(flag==0) {//flag为0时说明没有小数点,数字串和小数要分开输出
RE[num].rig=true;RE[num].type=3;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
else{
RE[num].rig=true;RE[num].type=4;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
}
if(k!=str.length()-1||(k==str.length()-1&&!Character.isDigit(str.charAt(k))))
k--;
}
//字符串检查 5
public static void stringCheck(String str){
cols=k+1;
String token=String.valueOf(str.charAt(k++));
char ch;
int n=str.length();
if(!words){//直接寻找第一次分号的位置并记录下来,如果不加这个条件可能会被识别为第2次的
for(int i=0;i<n;++i){
if(str.charAt(i)=='"'){
RE[num].li=lines;
RE[num].co=i+1+(ok==true?blank:0);
break;
}
}
}
for( ;k<n;++k){
ch=str.charAt(k);
token+=ch;
if(words==true&&ch=='"'){//多行结束情况判断,遇到引号结束,就把strs的值赋给token
strs+=token;
token=strs;//最后保存到RE中的是token,所以将strs的值赋给token
words=false;//这里一定要置为false,否则后面对1,2的判断都不会出现
break;
}
if(ch=='"')//单独一行就直接break就行了
break;
}
if(token.charAt(token.length()-1)!='"') {//最后一个字符不是双引号说明是多行字符串,标记为true,直接返回继续判断
words=true;
strs+=token;
return;
}
else{
RE[num].type=5;
RE[num].res=token;
++num;
}
}
//单引号引起来字符的识别 6
public static void charCheck(String str){
cols=k+1;
String token=String.valueOf(str.charAt(k++));
char ch;
int n=str.length();
for( ;k<n;++k){
ch=str.charAt(k);
token+=ch;
if(ch=='\'')//单个打印号要用转义字符表示
break;
}
if(token.charAt(token.length()-1)!='\'') {//最后一个字符不是单引号
RE[num].rig=false;RE[num].type=-1;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
else {//没有就可以输出是第几个类型的词,本身,行号和列号
if(ok)
cols+=blank;
RE[num].rig=true;RE[num].type=6;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
}
//分隔符,运算符的识别 7 8
public static void symbolCheck(String str){
cols=k+1;
String token= String.valueOf(str.charAt(k++));
char ch;
if (symbols.contains(token)){//如果该符号包含在分隔符中,因为分隔符中都是单个符号,所以直接输出token
if(ok)
cols+=blank;
RE[num].rig=true;RE[num].type=7;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
k--;
}
else {
if (operations.contains(token)){
if (k<str.length()){
ch=str.charAt(k);
if(str.charAt(k)=='/'&&str.charAt(k-1)=='/'){//只要遇到单行注释,直接return就行,不用做标记
mark=true;
return;
}
if(str.charAt(k-1)=='/'&&str.charAt(k)=='*'){//当存在多行注释时,使biu为true
biu=true;
//return; 当在一行中找到/*符号时,可能这一行也会有*/符号,所以这个需要判断,不能直接返回
}
if(biu){//判断是不是会在当前这行注释结束
for(int i=k;i<str.length();++i){
if(str.charAt(i)=='*'&&str.charAt(i+1)=='/'){
biu=false;
k=i+1;//从多行注释结束的下一个字符开始分析
return;
}
}
return;//如果没在同一行结束,直接返回判断下一行就好了
}
if (operations.contains(token+ch)){//如果包含,说明该运算符由2个字符组成
token+=ch;
if(ok)
cols+=blank;
RE[num].rig=true;RE[num].type=8;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
else {//此情况说明只是单个字符的运算符
k--;
if(ok)
cols+=blank;
if(mark==false&&biu==false){
RE[num].rig=true;RE[num].type=8;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
}
}
}
else {//错误
k--;
if(ok)
cols+=blank;
RE[num].rig=false;RE[num].type=-1;
RE[num].res=token;RE[num].li=lines;RE[num].co=cols;
++num;
}
}
}
public static void init(){//初始化把数组转换为ArrayList,容易查找
keyWords=new ArrayList<>();
operations=new ArrayList<>();
symbols=new ArrayList<>();
Collections.addAll(keyWords,keyWord);
Collections.addAll(symbols,symbol);
Collections.addAll(operations,operation);
}
public static void analyze(String str){
k=0;
char ch;
str=str.trim();//去掉每一行前后的空格
int n=str.length();
if(biu){//判断是不是会在下一行注释结束
for(int i=0;i<n-1;++i){
if(str.charAt(i)=='*'&&str.charAt(i+1)=='/'){
biu=false;
k=i+2;//从多行注释结束的下一个字符开始分析
break;
}
}
}
if(biu)
return;//如果当前没有多行注释结束标志,说明这一行还是注释,直接跳过
for ( ;k<str.length();k++){
ch=str.charAt(k);
if (Character.isDigit(ch))
digitCheck(str);//3 4
else if((words==false)&&(Character.isLetter(ch)||ch=='$'))//多行字符串时不能被1,2判断
letterCheck(str);//1 2
else if (words==true||ch=='"')//多行字符串的情况或者双引号开头都要归为第5类判断
stringCheck(str);//5
else if(ch=='\'')
charCheck(str);//6
else if (ch==' ')
continue;
else {
symbolCheck(str);//7 8
if(mark||biu)
return;
}
}
}
public static void main(String[] args) {
init();
File file=new File("D:\\Java_code\\Beijing\\src\\score3.txt");
try(Scanner in=new Scanner(file)) {
while (in.hasNextLine()){
String str=in.nextLine();//每次读取一行
cols=0;//每一次换行的列数 都要从头计数
ok=false;
mark=false;//每一行新判断的时候都应该把注释记录清空
//biu=false; 多行注释的消除只能通过再一次遇到*/才行,不是每次循环设为false
//只要出现2个斜杠它后面就得是注释,不管后面还有啥,2个斜杠是肯定把后面的东西都注释掉了
if(!words){//当有多行字符串时,要保存之前的行和列,所以就不对其清零了。并且数组也不从0开始保存
num=0;//表示一行中分析到词的个数
for(int i=0;i<N;++i){
RE[i]=new Results();//必须要先对每一个对象先实例化之后再对其赋值,否则会报空指针的错误
RE[i].rig=true;RE[i].type=0;
RE[i].res="";RE[i].li=0;RE[i].co=0;
}
}
int len=str.length();
a[++lines]=len;//用数组存放每一行有多少列
if(str.trim().length()!=a[lines]) {//如果前面有空格,就先把相差的空格数记上
blank=(a[lines] - str.trim().length());
ok=true;//只有开头有空格时ok才为true,在句子中时或者句子前没空格时ok为false
}
analyze(str);
for(int i=0;i<num;++i){//在主函数中输出信息
if(RE[i].rig)
System.out.println("("+RE[i].type+","+RE[i].res+","+RE[i].li+","+RE[i].co+")");
else
System.out.println(RE[i].li+"line"+": "+RE[i].res+" Error");
}
}
}
catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
}
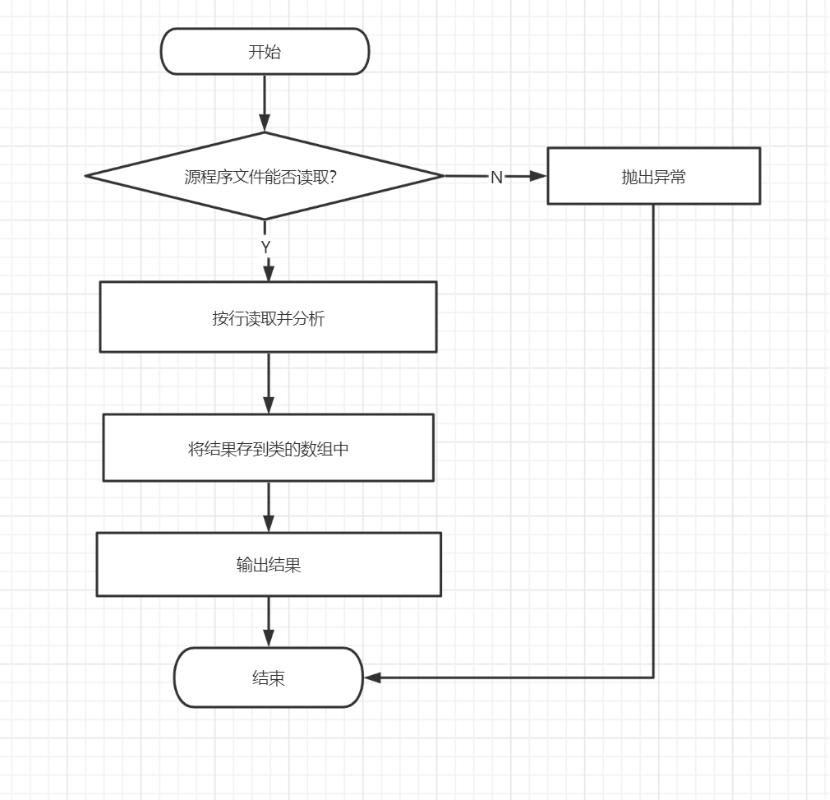
图1-1 总体架构设计
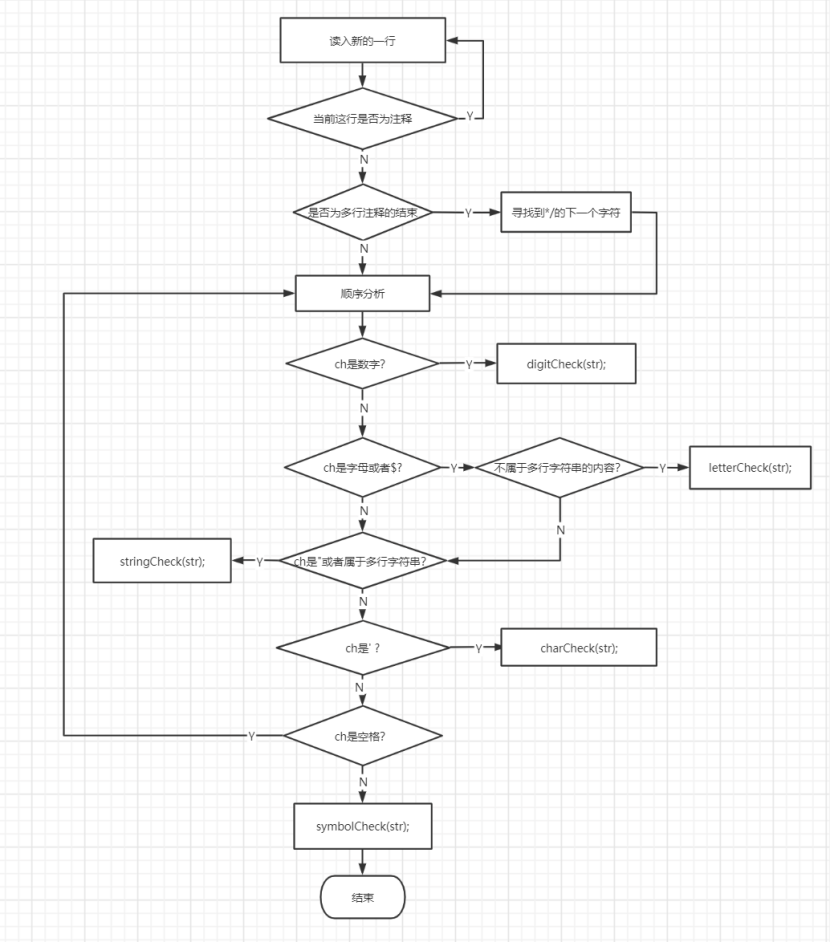
图1-2 词法分析程序
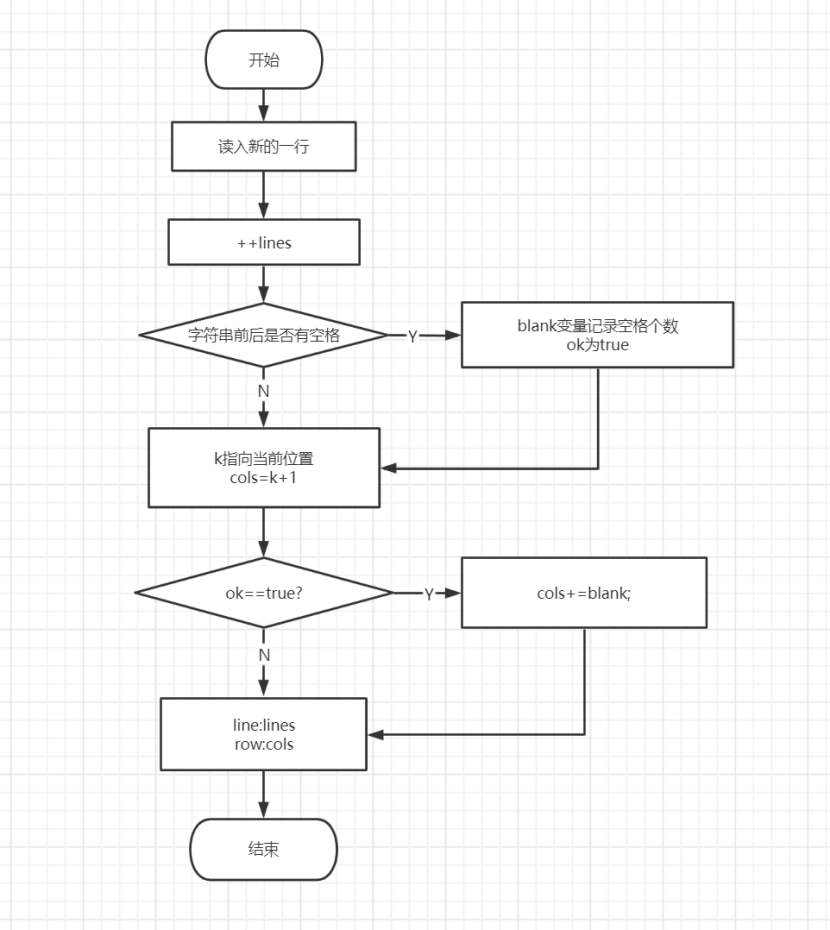
图1-3 取字符和统计字符行列位置
时间:2023年5月12日17:12:42
















 4765
4765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











