







集合提供给我们的是许多实用的数据结构。
如果熟悉C++的STL,就会更容易接触java的集合类,C++的STL的缺点是复杂而且比较低效。
对象的引用强度分为四个级别:在java.lang.ref中
1.强引用:当内存不足时,这些对象也绝对不会被回收。
2.软引用:当内存不足时,会回收对象内存,用来实现内存敏感的告诉缓存。
3.弱引用:无论内存是否紧张,只要被垃圾回收器发现,则立即回收。
4.虚引用:与没有引用一样。
错误种类:
1.编译器错误:在javac阶段出现的错误,必须解决。
2.运行时错误:在java时抛出运行时异常。
jdk升级目标:将运行时异常转变成编译时错误。
接口与实现分离的思想:
如果要实现一个集合,则可以预先设定一个接口,规定方法的名称,这样可以使得给予用户所见的只有方法的名称,而实现的方法可以自己变动。
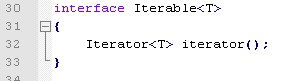
迭代器:用于遍历一个容器的接口。
Iterator主要用于集合的输出,因此只要看到输出,就最好使用iterator接口。
Iterator在遍历集合时,不能用另一个线程去修改集合,不然会抛出java.util.ConcurrentModificationException,因为Iterator运用了快速失败机制,因此一旦检测到集合被修改,立即抛出异常。
Iterator和Enumeration接口的比较
一般Enumeration通常用在vector输出,因为Vector中有element()方法返回Enumeration接口。

共同点是都能够遍历一个容器的每个元素。
遍历方式1:

遍历方式2:for each:
for each遍历形式的适用条件:实现Iterable接口。
移除元素:在调用remove之前,必须要调用next。
Collection<T>接口:
- Iterator<T> iterator(); Iterator<T> iter=c.iterator();
- int size();
- boolean isEmpty();
- boolean contains(Object obj);
- boolean add(Object elem); 插入elem,如果集合发生变化,则返回true
- boolean remove(Object elem); 移除elem,如果成功,返回true
- clear(); 清除
- toString();把集合中的所有元素打印出来。
- toArray(T[] t)将集合变成数组
代码示例:将链表集合变成数组。
package org.LinkedList;
import java.util.LinkedList;
public class toArrayTest {
public static void main(String[] args) {
LinkedList<String> list1 = new LinkedList<String>();
list1.add("a");
list1.add("b");
list1.add("c");
list1.add("d");
String[]arr = list1.toArray(new String[0]);
for(String e:arr)
System.out.println(e);
}
}
特别要注意:remove方法移除依赖于迭代器的状态。所以一般很少使用!因为List接口存在remove(Object obj)方法。
在iterator迭代中使用List的remove方法会出现一个问题:一旦执行了remove方法,就直接跳出循环。
因此在iterator迭代输出时,不能使用List的remove方法。
代码实例:
package org.Collections;
import java.util.*;
public class removeExceptionTest {
public static void main(String[] args) {
List<String> list = new LinkedList<String>();
list.add("a");
list.add("b");
list.add("c");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
if ("b".equals(str)) {
list.remove(str); // 在移除b后就跳出循环
} else {
System.out.println(str);// 只输出了a
}
}
}
}AbstractCollection<T>是一个抽象类,实现了Collection的部分方法。
链表LinkedList:双向链表 有序集合
由于ArrayList是由数组实现的,因此添加和删除的效率很低。因此引入了链表
当数据量大,并且有很多的插入删除操作,则使用链表。
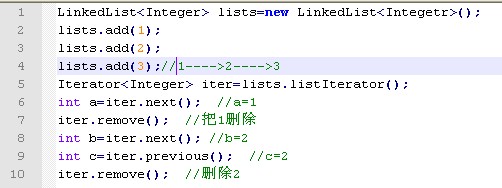
专有迭代器:ListIterator<T>,增加了以下几种方法:
- void add(T elem); 把elem添加到迭代器所指位置的前面
- void set(T elem); 把elem替代最近一次next或previous访问的那个元素。
- E previous(); 返回前一个对象,并把迭代器前移一位。
- boolean hasPrevious(); 是否还有前继。
- int nextIndex(); //获得调用next后的索引
- int previousIndex();//获得调用previous后的索引
迭代器默认是在最前面的。
因此当创建了一个ListIterator后,直接进行由后向前遍历,是不行的!!
示例:
package org.Collections;
import java.util.LinkedList;
import java.util.ListIterator;
public class ListIteratorTest {
public static void main(String[] args) {
LinkedList<Integer> list1 = new LinkedList<Integer>();
list1.add(1);
list1.add(2);
list1.add(3);
ListIterator<Integer> iterator = list1.listIterator();
System.out.println("输出链表:");
while(iterator.hasPrevious()) // 不能输出,因为默认迭代器在最前
{
System.out.println(iterator.previous());
}
}
}
举例:
LinkedList常用方法:
- list.addFirst();
- list.addLast();
- list.removeFirst();
- list.removeLast();
- add(T e);
- remove(index);
- remove(Object obj);
- set(int index,T elem);
LinkedList实际运用:
(1)双端队列Deque:
(2)堆栈Stack:
- T pop();
- void push(T elem);
- T peek();
(3)队列
注:java提供了Stack类专门用于堆栈
- T push(T item);
- T pop();
- T peek();
ArrayList<T>与vector<T>
共同点:有着几乎共同的方法。
相异点:vector<T>所有方法都是同步的,因此效率不是很高,一般我们都用ArrayList。
- T get(int index);
- T set(int index, T elem); 返回以前在这个索引处的旧值。
- boolean add(T elem); 加在尾部
- trimToSize(); 把数组列表的容量调整为尺寸
HashSet和TreeSet
HashSet<T>

特点:
- 前面提到的由于实现了List接口,因此能够控制集合的顺序,但是这个数据结构不能控制集合的顺序。
- 当不确定元素在集合中的位置时,能够快速访问。
- 散列表是一个数组,每个数组索引为一个散列表元,一个散列表元包含不同的散列码元素,一个索引对应一个链表,包含不同散列码值映射到相同散列表元的元素。
- 散列冲突:多个元素的散列码对应相同的散列表元。即equals不想等,但是hash
- 当散列表中的元素太多,则必须要再散列,即重新创建一个更大的散列表,把原来散列表的元素经过散列放入新的散列表中。
- 遍历散列表的元素是没有顺序的。
- 散列必须是随机的,均匀的。
- HashSet判断是否添加元素的依据是hashcode()和equals()方法,当这个函数判断相等时,才不能添加。
- 要保证hashcode()和equals()的一致性
常用函数:
- 构造:HashSet<T> s=new HashSet(int capacity,float loadFactor);
- 添加:s.add(T elem);
- 迭代器遍历:iterator();
术语:
- 散列表元
- 加载因子
- 散列冲突
注意:在元素加入HashSet后最好不要改变其哈希值!
代码示例:
package org.HashSet;
import java.util.*;
public class HashSetTest {
public static void main(String[] args) {
HashSet<Person> set1 = new HashSet();
Person p1 = new Person("张三",15);
Person p2 = new Person("李四",16);
Person p3 = new Person("王五",17);
Person p4 = new Person("赵六",18);
Person p5 = new Person("张三",15);
set1.add(p1);
set1.add(p2);
set1.add(p3);
set1.add(p4);
System.out.println(set1);
set1.add(p5); //添加重复元素
System.out.println(set1);//集合不变
p1.setAge(100); //修改hash值
System.out.println(set1);//集合元素被修改
set1.remove(p1); //试图删除p1,但是没有成功
System.out.println(set1);//集合元素不变,没有删除
}
}
class Person {
String name;
int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}TreeSet<T>
特点:
- 有序集合。插入一个元素,则会放到恰当的位置。
- 迭代器迭代时是按照排列顺序遍历。
- 由于插入时需要比较,因此速度比HashSet慢。
- 红-黑树实现。
- 当修改了TreeSet的元素后,TreeSet并不会重新排序。
插入的元素必须都是可比较的。实现方式有两种:
(1)插入元素的类实现Comparable接口.因此这个实现必须在开发阶段实现。但是如果有的类开发时没有实现这个接口呢?则引入第二种方法。
(2)继承Comparator<T>接口,并实现int Compare(T a,T b);把这个对象传递给TreeSet构造器中。可以采用匿名内部类。

常用函数:
- TreeSet<T> set=new TreeSet<T>();
- TreeSet<T> set=new TreeSet<T>(Comparator<T> c);
- 给定条件获得部分视图。
- add\remove
package org.TreeSet;
import java.util.*;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Student> set1 = new TreeSet<Student>(new Comparator<Student>()
{
public int compare(Student a , Student b)
{
if(a.getScore() < b.getScore())
return -1;
else if(a.getScore() > b.getScore())
return 1;
else return 0;
}
});
Student stu1 = new Student("张三",90);
Student stu2 = new Student("李四",80);
Student stu3 = new Student("王五",100);
Student stu4 = new Student("赵六",90);
set1.add(stu1);
set1.add(stu2);
set1.add(stu3);
System.out.println(set1);
set1.add(stu4); //插入score相同的值时将不成功
System.out.println(set1);//赵六没有插入成功
}
}
class Student { //预先并没有给定比较器
String name;
double score;
public Student(String name, double score) {
super();
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
@Override
public String toString() {
return "Student [name=" + name + ", score=" + score + "]";
}
}当对于排序不要求时则用HashSet,对排序有要求则用TreeSet。
Map一般作为查找使用。
HashMap和TreeMap和Hashtable
HashMap<K,V>
特点:
- 以key-value进行组合。
- 对于key进行散列。
- 其他特点类似于HashSet。
- 键是唯一的。
- 拥有三个视图。键视图、值视图、键-值视图。
函数:
- V put(key,value); 添加key-value对,如果key原本存在,则替换value值,返回旧value值。
- get(key);
- Set<K> keySet();返回键视图。
- Collection<V> values();返回值视图。 能删除,但是不能添加
- Set<Map.Entry<K,V>>entrySet();返回键值视图。 能删除,但是不能添加
- remove(key);移除键-值对。 能删除,但是不能添加
Map.Entry<K,V>保存一个key-value内容,方法有
(1)getKey();
(2)getValue();
示例代码:
package org.Collections;
import java.util.*;
public class HashMapTest {
public static void main(String[] args) {
HashMap<Integer, String> students = new HashMap<Integer, String>();
students.put(1, "张三");
students.put(2, "李四");
students.put(3, "王五");
students.put(4, "赵六");
Set<Integer> ids = students.keySet();
Collection<String> names = students.values();
System.out.println(ids);
students.remove(1); //在原来映射表中删除一个元素
System.out.println(ids);//在视图中反应出来
ids.remove(4); //在视图中删除,则在原来映射表中也会同样删除,因此视图和原来映射表是同步的
//但是视图不能添加元素
printMaps(students);
names.remove("王五");
printMaps(students);
}
public static void printMaps(HashMap<Integer,String>map)
{
Set<Map.Entry<Integer, String>> maps = map.entrySet();
for(Map.Entry<Integer, String> entry:maps)
{
System.out.println(entry.getKey()+" "+entry.getValue());
}
System.out.println("************************");
}
}
TreeMap<K,V>
对键进行排序,其他特点类似TreeSet
添加比较器:
TreeMap<String> map = new TreeMap<String>(new Comparator<String>(){
public int compare(String o1,String o2){
return o2.compareTo(o1);
}
});
可以实现反序;
常用方法:
(1)containsKey(Object o);
(2)containsValue(Object o);
Hashtable
功能和HashMap一样,区别在于Hashtable是线程同步的。
- Enumeration<K> keys(); 返回键的枚举
- Enumeration<V> elements(); 返回值的枚举
PriorityQueue<T>
特点:
- 以堆形式构造。因此不需要排序,而只要保证头是最小元素。
- 自我调整的二叉树。
常用函数:
- 构造:PriorityQueue<T> q=new PriorityQueue<T>();
- 构造:PriorityQueue<T> q=new PriorityQueue<T>(Comparator<T> c);
- 删除头:remove();
- 删除指定元素:remove(T e);
- 添加:add(T e);
WeakHashMap会自动移除没有使用的键值对,由垃圾回收器回收。
package org.Collections;
import java.util.Map;
import java.util.*;
public class WeakHashMapTest {
public static void main(String[] args) {
Map<String,String> map = new WeakHashMap<String,String>();
map.put(new String("A"),new String("a"));//创建三个临时的类型
map.put(new String("B"),new String("b"));
map.put(new String("C"),new String("c"));
System.out.println("垃圾收集之前:");
System.out.println(map);
System.gc();//强制进行垃圾收集
System.out.println("垃圾收集之后:");
System.out.println(map);//元素被垃圾收集,因此为空
}
}
LinkedHashSet<T>和LinkedHashMap<K,V>与LinkedHashSet 和LinkedHashMap的区别是在数据结构中既有散列表又有链表。
- 有两种模式遍历元素:默认是插入顺序,即按照插入的顺序遍历;如果在构造方法中设置,则可以按照访问顺序即按照链表进行遍历,如果某个调用get或put方法,则自动放入链表的末尾。
package org.Collections;
import java.util.*;
import java.util.Map;
import java.util.Set;
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Integer, String> students = new LinkedHashMap<Integer, String>(); //插入顺序
students.put(1, "张三");
students.put(2, "李四");
students.put(3, "王五");
students.put(4, "赵六");
students.get(1);
printMaps(students);
LinkedHashMap<Integer, String> students2 = new LinkedHashMap<Integer, String>(16,0.75f,true);
//访问顺序,按照列表进行访问,当对一个元素调用get或put方法时,则将这个元素放置列表末尾
students2.put(1, "张三");//将1, 张三 放到列表末尾
students2.put(2, "李四");//同上
students2.put(3, "王五");//同上
students2.put(4, "赵六");//同上
students2.get(1); //同上
printMaps(students2);//结果李四在第一个
}
public static void printMaps(HashMap<Integer, String> map) {
Set<Map.Entry<Integer, String>> maps = map.entrySet();
for (Map.Entry<Integer, String> entry : maps) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
System.out.println("************************");
}
}
IdentityHashMap:能够重复key。
package org.Collections;
import java.util.HashMap;
import java.util.*;
public class IdentityHashMapTest {
public static void main(String[] args) {
Map<Person,String> map = new IdentityHashMap<Person,String>();
map.put(new Person("张三",15), "张三");
map.put(new Person("李四",30), "李四");
map.put(new Person("张三",15), "zhangsan"); //只要key的地址不一样,则可以允许键值重复
Set<Map.Entry<Person, String>> entry = map.entrySet();
for(Map.Entry<Person, String>e :entry){
System.out.println(e.getKey()+"--->"+e.getValue());
}
}
}
EnumSet和EnumMap
EnumSet 枚举类型的集合
特点:没有构造方法。用静态工厂方法,类似线程池。
工厂方法:
(1)EnumSet<T> a=EnumSet.allOf(Class);
(2)EnumSet<T> a=EnumSet.noneOf(Class);
(3)EnumSet<T> a=EnumSet.range(T from,T to);
EnumMap是键值为枚举类型的映射表。
构造:EnumMap(Class<K> keyType);
集合框架是实现高级类的基础。可以把高级类的一些共同方法抽象出来,放到集合框架的底层类中。
RandomAccess接口是标记接口,实现了这个接口的类适用于随机访问方法。
视图能够把原来的集合的一部分给用户看,但是又不是单纯的把那部分值复制,而是当改变视图的值会对原来的集合进行修改。
视图会随着原始集合的更改而更新。
一般视图
(1)List<T> l=Arrays.asList(T...elem);
比如:
String[] str=new String[5];
List<String> l= Arrays.asList(str);
(2)对于List类:
List<T> subList(int from.int to);
(3)对于SortedSet
- SortedSet<T> subSet(int from,int to); 返回视图
- SortedSet<T> headSet(to);
- SortedSet<T> tailSet(from);
(4)对于SortedMap
- subMap(from,to);
- headMap(to);
- tailMap(from);
有了前面的视图操作,我们就可以进行批操作,即对于大量数据进行移动。
- a.retainAll(Collection<T>b); a<---a交b
- a.removeAll(Collection<T>b); a<---a-b
- a.addAll(b); a<---a并b
可以利用视图和批操作结合。
Collections集合工具类:
Collections和Collection没有关系。
不可修改视图:只是视图不能修改,但是原始集合仍旧能修改,并在视图中更新。
- Collections.unmodifiableCollection(Collection<T>);
- Collections.unmodifiableList(List<T>);
- Collections.unmodifiableSet(Set<T>);
- Collections.unmodifiableSortedSet(SortedSet<T>);
- Collections.unmodifiableMap(Map<K,V>);
- Collections.unmodifiableSortedMap(SortedMap<K,V>);
同步视图:确保多线程安全
经过同步视图后视图的所有方法都是同步的。
- Collections.synchronizedCollection(Collection<T>);
- Collections.synchronizedList(List<T>);
- Collections.synchronizedSet(Set<T>);
- Collections.synchronizedSortedSet(SortedSet<T>);
- Collections.synchronizedMap(Map<K,V>);
- Collections.synchronizedSortedMap(SortedMap<K,V>);
被检验视图:解决放入错误类型进入泛型集合中。在放入时立即报错。
- Collections.checkedCollection(Collection<T>,T.class);
- Collections.checkedList(List<T>,T.class);
- Collections.checkedSet(Set<T>,T.class);
- Collections.checkedSortedSet(SortedSet<T>,T.class);
- Collections.checkedMap(Map<K,V>,K.class,T.class);
- Collections.checkedSortedMap(SortedMap<K,V>,K,class,V,class);
Collections 集合辅助类库:
排序
- Collections.sort(List<T>l); 排序的集合必须实现List接口,即必须是可比较的。
- Collections.sort(List<T>l,Comparator<T>comp); 如果没有实现可比较,则可以外加比较器。
- Collections.sort(List<T> l,Collections.reverseOrder(comp));根据comp比较器倒序。
- copy(List dest,List,src);
混排
- Collections.shuffle(List<T> l); 混排,即随机排列。
二分查找
int Collections.binarySearch(List<T>l,T key);
- 如果找到,则返回索引。
- 如果没找到,返回负数i,-i-1为这个key插入仍保持有序的位置。
int Collections.binarySearch(List<T>l,T key,Comparator<T>);
二分查找的集合必须是实现RandomAccess的。
package org.Collections;
import java.util.*;
public class BinarySearchTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("c");
list.add("b");
list.add("a");
list.add("e");
Collections.sort(list);
int i = Collections.binarySearch(list, "c");
System.out.println("c的位置是:" + i);
int j = Collections.binarySearch(list, "d");// 没有找到d
System.out.println("d的位置是:" + j);
list.add((-j - 1), "d");// -j-1就是能够维持有序的插入位置
System.out.println(list);
}
}最大值
- Collections.max(Collection<T>max);
- Collections.max(Collection<T>max,Comparator<T>comp);
最小值
- Collections.min(Collection<T>min);
- Collections.min(Collection<T>min,Comparator<T>comp);
复制数组
Collections.copy(List<T>to,List<T>from);
填充数组
Collections.fill(List<T>l,T value);
查看出现次数
int f=Collections.frequency(Collection<T> c,Object o);
是否有公共元素
boolean b=Collections.disjoint(Collection a,Collection b);
内容反转
Collections.reverse(Collection<> col);
集合与数组的互换
数组--->集合:Arrays.asList();
例如:
String[] str;
List<String> list=Arrays.asList(str);
可以把list赋给任何一个集合。
注意:asList返回的是数组的视图,因此如果视图修改了,则数组也会被同步修改!
import java.util.*;
public class AsListDemo{
public static void main(String args[]){
String[]arr = {"4","3","2","5","6","7","1"};
List<String> list = Arrays.asList(arr);
Collections.sort(list);
System.out.println("*****排序*******");
for(String a:arr)
System.out.println(a);
}
}集合--->数组:toArray(T[] s);
例如:
如果要把list换成数组,则可以
String [] str=list.toArray(new String[list.size]);
集合是可扩展的,因为设计者预先给我们一个abstract的抽象类,便于我们扩展,实现自己的功能。
package org.Collections;
import java.util.*;
public class CircularQueueTest {
public static void main(String[] args) {
CircularArrayQueue<Integer> queue = new CircularArrayQueue<Integer>(3);
queue.add(1);
queue.add(2);
queue.add(3);
boolean ok = queue.offer(4);
System.out.println(ok);
System.out.println(queue);
Iterator<Integer> iterator = queue.iterator();
while(iterator.hasNext())
System.out.println(iterator.next());
}
}
class CircularArrayQueue<T> extends AbstractQueue<T> {
private T[] elem;
private int count;
private int head;
private int tail;
public CircularArrayQueue(int capacity) {
super();
elem = (T[])new Object[capacity];
count = 0;
head = 0;
tail = 0;
}
@Override
public boolean offer(T e) {
if (count == elem.length)
return false;
else {
elem[tail] = e;
tail=(tail+1 == elem.length)?0:(tail+1);
count++;
return true;
}
}
@Override
public T poll() {
if (size() == 0)
return null;
T r = elem[head];
head = (head + 1 == elem.length) ? 0 : (head + 1);
count--;
return r;
}
@Override
public T peek() {
if (size() == 0)
return null;
return elem[head];
}
@Override
public Iterator<T> iterator() {
return new QueueIterator();
}
@Override
public int size() {
return count;
}
class QueueIterator implements Iterator<T>
{
int current;
boolean hasnext;
public QueueIterator() {
super();
current = 0;
hasnext =false;
}
@Override
public boolean hasNext() {
return current < count;
}
@Override
public T next() {
if(current+1 <= count){
hasnext = true;
return elem[current++];
}
else return null;
}
@Override
public void remove() {
}
}
}记住:在平常使用这些集合类是不要对具体的类太苛刻,这样就不灵活。比如在函数参数上、函数返回值等。
比如f(ArrayList<T>list)不如使用f(Collection<T>c);
Properties类
一般我们都调用getProperty(String key);和setProperty(String key, String value);获得和设置属性。
特点是:
- key-value都是字符串
- 可以存入普通文件或者XML文件,通过load(InputStream in)和store(OutputStream out,String commentString);
- 通过properties类的配置文件可以实现灵活性。
- Property p = System.getProperty();获得系统属性的property对象。
package org.Collections;
import java.io.*;
import java.util.*;
public class PropertiesTest {
public static void main(String[] args)throws Exception
{
FileInputStream in = new FileInputStream("config.properties");
Properties p = new Properties();
p.load(in);
in.close();
String str1 = p.getProperty("name");//获得name属性的值
p.setProperty("gender","male");//把这个键值对放入属性集
FileOutputStream out = new FileOutputStream("config.properties");
p.store(out, "\0");//把现在的属性集存入文件
out.close();
}
}
BitSet类
- 构造:BitSet s=new BitSet(int n);
- 长度:s.length();
- boolean get(int i);
- void set(int i); 设置一个位
- void clear(int i);清除一个位
- and(BitSet set); a&b
- or(BitSet set); a|b
- xor(BitSet set); a^b
- andNot(BitSet set); a&~b
数组
String[][][]str1 = new String[1][][2]; //错误,因为要从低维到高维,创建每一维数组(1)equals():只有数组元素相同并且对应位置也相同,返回true。
EnumMap
EnumMap也是Map的子类,规定key必须是enum类型;
注意:在EnumMap<>构造函数中必须要传入参数Enum类型的class;比如:
enum Grade{};
EnumMap<Grade,String>(Grade.class);
import java.util.EnumMap;
public class EnumDemo {
enum Grade {A,B,C,D};
public static void main(String args[]){
EnumMap<Grade,String> maps = new EnumMap<Grade,String>(EnumDemo.Grade.class);
maps.put(Grade.A, "A");
maps.put(Grade.B, "B");
maps.put(Grade.C, "C");
maps.put(Grade.D, "D");
System.out.println(maps.get(Grade.A));
}
}
for-each循环的集合必须实现java.lang.Iterable,从而能够支持迭代。
EnumSet
package org.impl;
import java.util.EnumSet;
import java.util.Set;
public class Log4jDemo {
enum Grade {A,B,C};
public static void main(String args[]){
Set<Grade> set = EnumSet.allOf(Grade.class);
//print A,B,C
for(Grade g:set){
System.out.println(g);
}
Set<Grade>noneSet = EnumSet.noneOf(Grade.class);
noneSet.add(Grade.A);
Set<Grade> rangeSet = EnumSet.range(Grade.A, Grade.B);
//print A,B
for(Grade g:rangeSet){
System.out.println(g);
}
}
}














 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









