




 本文总结了九种经典的排序算法,包括插入排序的递归版、冒泡排序、选择排序、归并排序、快速排序、堆排序、计数排序、基数排序以及桶排序,详细阐述了每种算法的原理和实现方法。
本文总结了九种经典的排序算法,包括插入排序的递归版、冒泡排序、选择排序、归并排序、快速排序、堆排序、计数排序、基数排序以及桶排序,详细阐述了每种算法的原理和实现方法。
如果要转载,需要注明出处: http://blog.csdn.net/xiazdong
本文是 http://blog.csdn.net/xiazdong/article/details/7304239 的补充,当年看了《大话数据结构》总结的,但是现在看了《算法导论》,发现以前对排序的理解还不深入,所以打算对各个排序的思想再整理一遍。
本文首先介绍了基于比较模型的排序算法,即最坏复杂度都在Ω(nlgn)的排序算法,接着介绍了一些线性时间排序算法,这些排序算法虽然都在线性时间,但是都是在对输入数组有一定的约束的前提下才行。
这篇文章参看了《算法导论》第2、3、4、6、7、8章而总结。
算法的由来:9世纪波斯数学家提出的:“al-Khowarizmi”

排序的定义:
输入:n个数:a1,a2,a3,...,an
输出:n个数的排列:a1',a2',a3',...,an',使得a1'<=a2'<=a3'<=...<=an'。
In-place sort(不占用额外内存或占用常数的内存):插入排序、选择排序、冒泡排序、堆排序、快速排序。
Out-place sort:归并排序、计数排序、基数排序、桶排序。
当需要对大量数据进行排序时,In-place sort就显示出优点,因为只需要占用常数的内存。
设想一下,如果要对10000个数据排序,如果使用了Out-place sort,则假设需要用200G的额外空间,则一台老式电脑会吃不消,但是如果使用In-place sort,则不需要花费额外内存。
stable sort:插入排序、冒泡排序、归并排序、计数排序、基数排序、桶排序。
unstable sort:选择排序(5 8 5 2 9)、快速排序、堆排序。
为何排序的稳定性很重要?
在初学排序时会觉得稳定性有这么重要吗?两个一样的元素的顺序有这么重要吗?其实很重要。在基数排序中显得尤为突出,如下:
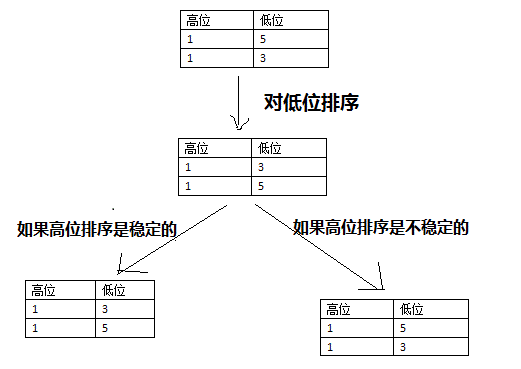
算法导论习题8.3-2说:如果对于不稳定的算法进行改进,使得那些不稳定的算法也稳定?
其实很简单,只需要在每个输入元素加一个index,表示初始时的数组索引,当不稳定的算法排好序后,对于相同的元素对index排序即可。
基于比较的排序都是遵循“决策树模型”,而在决策树模型中,我们能证明给予比较的排序算法最坏情况下的运行时间为Ω(nlgn),证明的思路是因为将n个序列构成的决策树的叶子节点个数至少有n!,因此高度至少为nlgn。
线性时间排序虽然能够理想情况下能在线性时间排序,但是每个排序都需要对输入数组做一些假设,比如计数排序需要输入数组数字范围为[0,k]等。
在排序算法的正确性证明中介绍了”循环不变式“,他类似于数学归纳法,"初始"对应"n=1","保持"对应"假设n=k成立,当n=k+1时"。
一、插入排序
特点:stable sort、In-place sort
最优复杂度:当输入数组就是排好序的时候,复杂度为O(n),而快速排序在这种情况下会产生O(n^2)的复杂度。
最差复杂度:当输入数组为倒序时,复杂度为O(n^2)
插入排序比较适合用于“少量元素的数组”。
其实插入排序的复杂度和逆序对的个数一样,当数组倒序时,逆序对的个数为n(n-1)/2,因此插入排序复杂度为O(n^2)。
在算法导论2-4中有关于逆序对的介绍。
伪代码:

证明算法正确性:
循环不变式:在每次循环开始前,A[1...i-1]包含了原来的A[1...i-1]的元素,并且已排序。
初始:i=2,A[1...1]已排序,成立。
保持:在迭代开始前,A[1...i-1]已排序,而循环体的目的是将A[i]插入A[1...i-1]中,使得A[1...i]排序,因此在下一轮迭代开 始前,i++,因此现在A[1...i-1]排好序了,因此保持循环不变式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4783
4783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









