






数组
数组是go中基本的数据结构,底层分配的连续内存
func TestTravelArray(t *testing.T) {
a := [...]int{1, 2, 3, 4, 5} //初始化,不指定元素个数
for idx/*索引*/, elem/*元素*/ := range a {
fmt.Println(idx, elem)
}
}
slice
slice是一种轻量级的数据结构,可以看作是对数组的封装。它是一个有序元素序列,长度可以动态增长或缩小
slice声明
s1 := []int{1, 2, 3}
使用make初始化
// 创建一个初始长度为3,容量为6的整型slice
s := make([]int, 3, 6)
slice内部结构
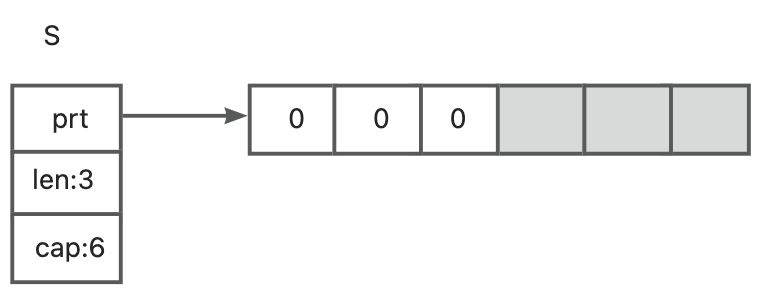
该切片创建了一个能够容纳6个元素(容量)的数组。同时,因为长度length被设置成了3,所以,Go仅仅初始化前3个元素。因为slice的元素是[]int类型,所以前3个元素用int的零值0来初始化。剩余的元素空间只被分配,但没有使用。
如果打印这个切片,将会得到如下结果:[0 0 0]。
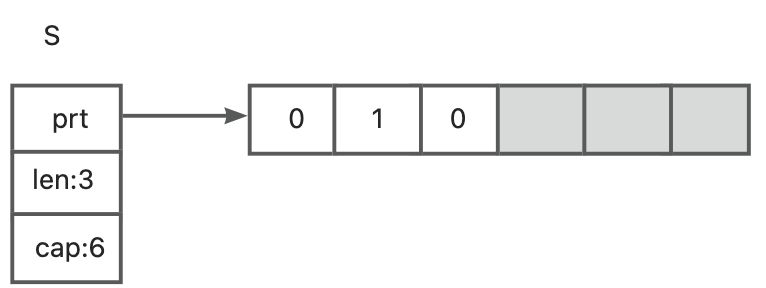
如果我们设置s[1] = 1,那么,该切片的第2个元素将会被更新,但对该slice的长度和容量不会有任何影响。如下图所示:
slice访问panic
slice不允许访问切片长度(length)以外的元素,即使长度以外的内存空间也已经被分配了。例如,s[4] = 0 会引发panic:
panic:runtime error: index out of range [4] with length 3
在直接对slice进行赋值时,应该先对slice的length进行判断
func TestSlice(t *testing.T) {
s1 := make([]int, 5, 6)
if len(s1) >= 5 {
fmt.Printf("%d", s1[4])
}
}
slice 新增元素
那么,我们该如何使用slice中剩余的空间呢?通过内建的append函数:
s = append(s, 2)
该操作将会网s切片中添加一个新的元素。该元素使用第一个图中灰色的元素块(即分配了空间但又没被使用的位置)来存储元素2。如下图所以
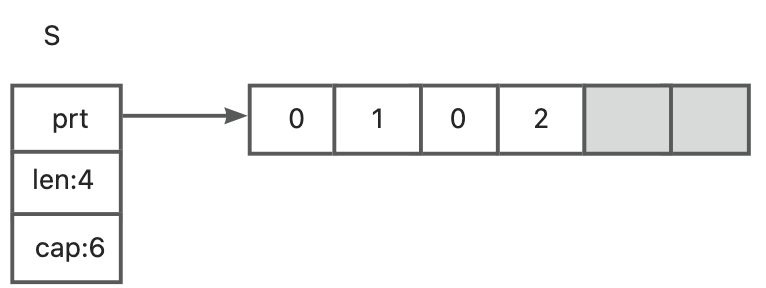
这时,slice的长度length从3变成了4,即该slice现在有4个元素。
那如果我们再多加入3个元素slice会发生什么?后端的数组空间会不会不足够大了?
s = append(s, 3)
s = append(s, 4)
s = append(s, 5)
fmt.Println(s)
如果我们执行这部分代码,我们会注意到该slice依然能满足我们的需求:
[0 1 0 2 3 4 5]
因为数组是一个固定长度的结构,只能将元素4给存储进去。当我们想插入元素5时,该数组就已经满了,Go会创建另一个数组,并且空间大小是原来容量的2倍,然后将原数组中的所有元素都拷贝到新数组中去,再在新数组中插入元素5,如下图所示:
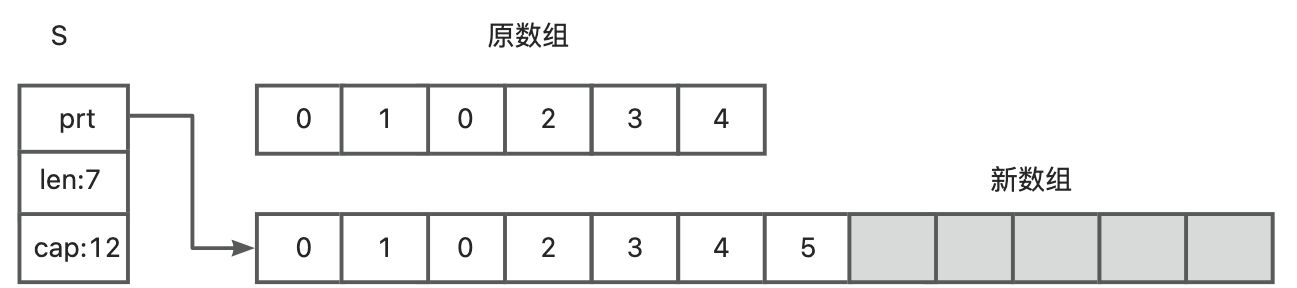
原数组将被GC回收
slice删除元素
slice没有提供delete方法,需要通过append的方式删除元素。即将slice在需要删除的位置切分成两个,再连接起来
s := []int{1, 2, 3, 4, 5}
// 找到需要删除元素的下标index
index := 1
// 使用append()函数将这两个Slice连接起来
s = append(s[:index], s[index+1:]...)
fmt.Println(s) // [1 3 4 5]
github slice库
github上没有star数很高的slice库,可以考虑我们自己封装一个。
可以参考https://github.com/bobg/go-generics,awesome-go中推荐的slice、map、set和goroutine utilities包等
slice浅拷贝
s1 := make([]int, 3, 6) // 一个长度为3,容量为6的切片
s2 := s1[1:3] // 从索引1到3进行切分

首先,s1被初始化成一个长度为3,容量为6的切片。当通过切分s1创建s2切片时,s1和s2的指针字段都指向同一个后端数组。但是,s2的第一个元素的索引是从数组的索引1开始的。因此,切片s2的长度和容量是和s1不同的:长度为2,容量为5.
如果我们更新s1[1]或s2[0],那么对于后端数组来说,变更是一样的。因此,该变更对两个切片都是可见的,如图所示
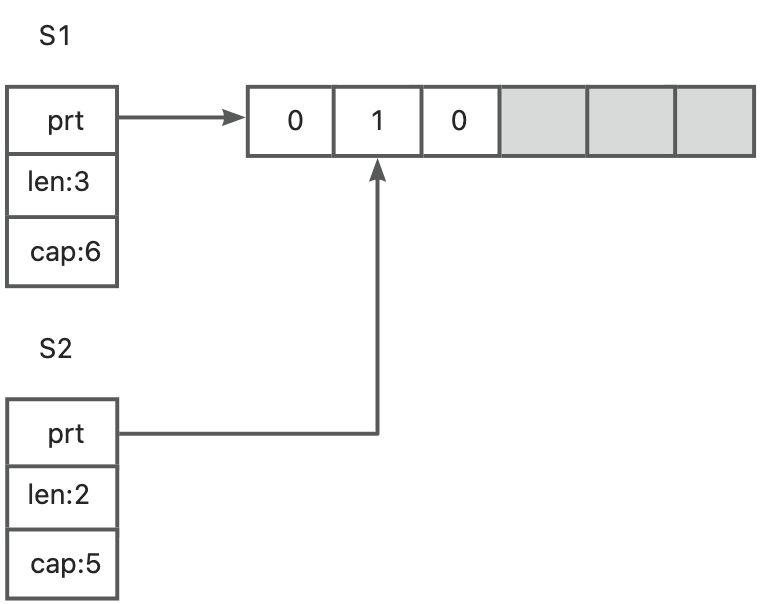
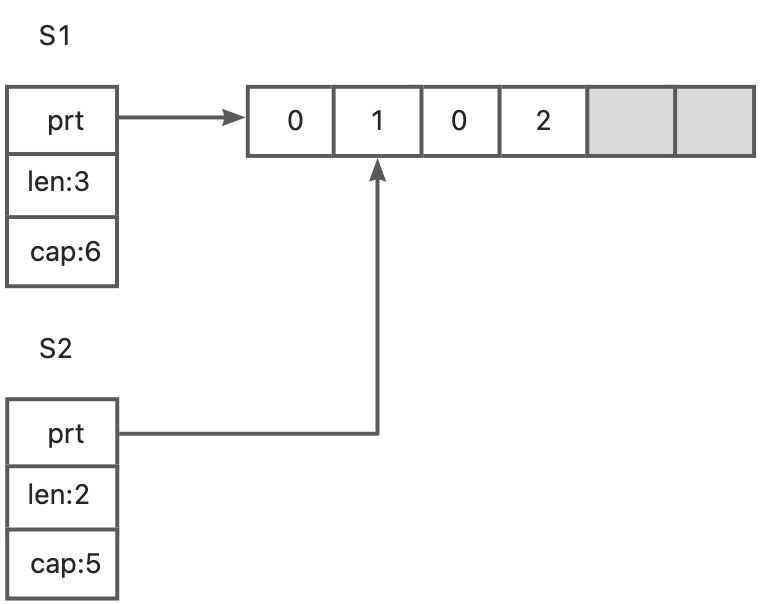
如果现在往s2中append一个元素会发生什么呢?会对s1有影响吗?
s2 = append(s2, 2)
这样,会将共享的数组进行修改,但只有s2的长度会发生改变,如图所示:
浅拷贝新数组扩容
最后一个需要注意的是,如果我们持续往s2中append元素,直到数组满了位置,会发生什么呢? 我们再往s2中增加3个元素,直到将后端的数组填满,没有任何可用的空间:
s2 = append(s2, 3)
s2 = append(s2, 4)
s2 = append(s2, 5) ①
① 在该阶段,后端的数组就已经满了。
这段代码会导致创建另一个新的数组,如图所示:
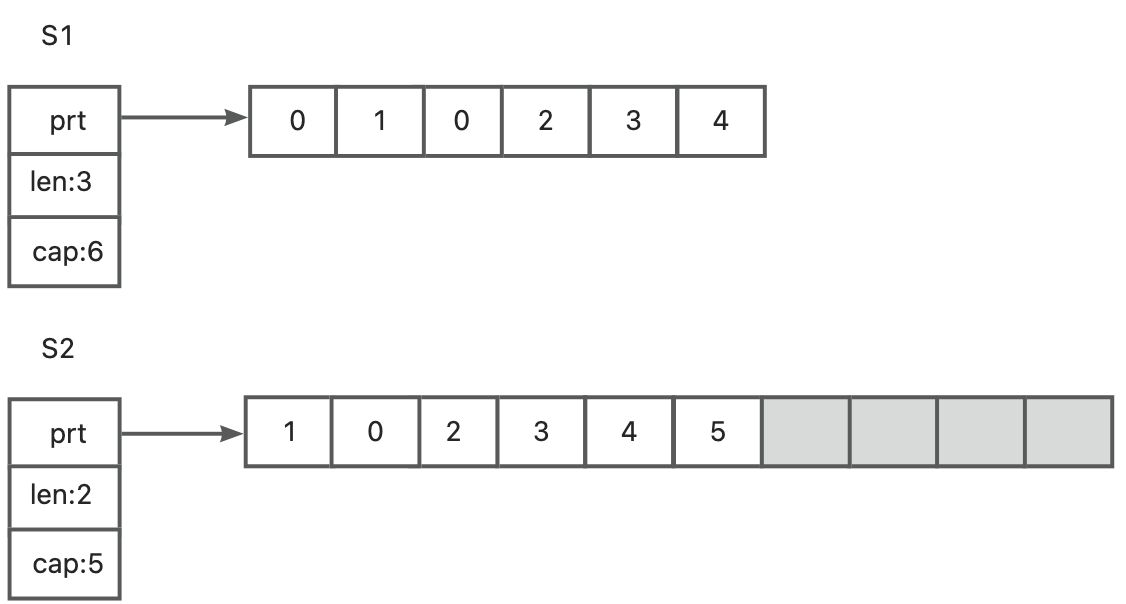
这时s1和s2分别指向了两个不同的数组。实际上,s1依然是一个长度为3,容量为6的切片,同时也有一些可用的buffer空间,因此,它依然是引用了最初的那个数组。同时,新创建的数组,会从s2的起始位置将数据拷贝到自己的空间上来。这也就是为什么新数组的第一个元素是1,而不是0的原因。
因此很可能出现这么一种情况,原切片由大量的元素构成,但是我们在原切片的基础上切片,虽然只使用了很小一段,但底层数组在内存中仍然占据了大量空间,得不到释放
slice深拷贝
如果需要对slice进行深拷贝,我们可以使用copy()函数对其底层数组进行复制。对于一个slice s1,我们可以创建一个空的slice s2,然后使用copy()函数将s1中的所有元素复制到s2中。这样就可以得到一个和s1完全独立的新slice s2。例如
src := []int {1,2,3,4,5,6}
var s2 = make([]int, len(s1))
copy(s2[:], s1)
当slice的元素是一个struct时,直接使用copy()函数进行深拷贝时,需要注意struct中是否存在指针类型。如果存在指针类型,可能存在指针指向同一地址的情况,这样就会影响到原有的slice数据。因此,需要自行实现对于struct的深拷贝操作。
例如,假设存在一个名为Person的struct,定义如下:
type Person struct {
Name string
Age int
Info *Info
}
type Info struct {
Address string
Phone string
}
此时在进行slice的深拷贝时,需要先对Info结构体进行深拷贝,可以通过在Person结构体中实现一个Clone()函数来完成深拷贝操作。该函数的实现如下:
func (p *Person) Clone() *Person {
info := &Info{
Address: p.Info.Address,
Phone: p.Info.Phone,
}
return &Person{
Name: p.Name,
Age: p.Age,
Info: info,
}
}
然后,在进行slice的深拷贝时,可以遍历源slice中的所有Person元素,通过调用Clone()函数来实现对于Person结构体的深拷贝。例如:
var s1 = []Person{
Person{
Name: "Tom",
Age: 28,
Info: &Info{
Address: "Beijing",
Phone: "123456789",
},
},
Person{
Name: "Jack",
Age: 30,
Info: &Info{
Address: "Shanghai",
Phone: "987654321",
},
},
}
var s2 = make([]Person, len(s1))
for i, v := range s1 {
s2[i] = *v.Clone()
}
上述代码中,在遍历s1中的所有元素时,通过Clone()函数来实现对于元素的深拷贝操作,然后将拷贝得到的新元素存储到新的slice中
slice线程安全问题
slice线程不安全原因
在多线程环境下,slice 的线程不安全主要是因为它的元素可以被多个线程同时读写。如append时,多个协程对数组进行添加,会出现被覆盖的情况
解决方法
1. 使用互斥锁(mutex)来保证读写操作的同步
可以在 slice 对象中添加一个互斥锁,然后在每次读写时对该锁进行加锁和解锁操作,以避免多个线程同时读写 slice 导致的数据竞争问题
func main() {
slc := make([]int, 0, 1000)
var wg sync.WaitGroup
var lock sync.Mutex
for i := 0; i < 1000; i++ {
wg.Add(1)
go func(a int) {
defer wg.Done()
// 加锁
lock.Lock()
defer lock.Unlock()
slc = append(slc, a)
}(i)
}
wg.Wait()
fmt.Println(len(slc))
}
优点
比较简单
缺点
性能不高
2. 使用读写互斥锁封装
比直接使用sync.Mutex性能更好
package main
import (
"fmt"
"sync"
)
type SafeSlice struct {
slice []interface{}
lock sync.RWMutex
}
func (s *SafeSlice) Append(value interface{}) {
s.lock.Lock()
defer s.lock.Unlock()
s.slice = append(s.slice, value)
}
func (s *SafeSlice) Get(index int) interface{} {
s.lock.RLock()
defer s.lock.RUnlock()
if len(s.slice) > index {
return s.slice[index]
} else {
return nil
}
}
func (s *SafeSlice) Len() int {
s.lock.RLock()
defer s.lock.RUnlock()
return len(s.slice)
}
func (s *SafeSlice) Print() {
s.lock.RLock()
defer s.lock.RUnlock()
fmt.Println(s.slice)
}
func main() {
safeSlice := &SafeSlice{slice: make([]interface{}, 0)}
safeSlice.Append("hello")
safeSlice.Append("world")
safeSlice.Print() // output: [hello world]
item := safeSlice.Get(0)
fmt.Println(item) // output: hello
fmt.Println(safeSlice.Len()) // output: 2
}
3.使用通道(channel)来实现并发安全
type ServiceData struct {
ch chan int // 用来 同步的channel
data []int // 存储数据的slice
}
func (s *ServiceData) Schedule() {
// 从 channel 接收数据
for i := range s.ch {
s.data = append(s.data, i)
}
}
func (s *ServiceData) Close() {
// 最后关闭 channel
close(s.ch)
}
func (s *ServiceData) AddData(v int) {
s.ch <- v // 发送数据到 channel
}
func NewScheduleJob(size int, done func()) *ServiceData {
s := &ServiceData{
ch: make(chan int, size),
data: make([]int, 0),
}
go func() {
// 并发地 append 数据到 slice
s.Schedule()
done()
}()
return s
}
func main() {
var (
wg sync.WaitGroup
n = 1000
)
c := make(chan struct{})
// new 了这个 job 后,该 job 就开始准备从 channel 接收数据了
s := NewScheduleJob(n, func() { c <- struct{}{} })
wg.Add(n)
for i := 0; i < n; i++ {
go func(v int) {
defer wg.Done()
s.AddData(v)
}(i)
}
wg.Wait()
s.Close()
<-c
fmt.Println(len(s.data))
}
这段代码创建了一个 ServiceData 结构体,并定义了几个方法:
Schedule()方法:该方法是一个死循环,因为 ch 通道是一个不关闭的通道,只有当调用 Close() 方法时才会关闭通道,这样才能让 Schedule() 方法停止循环。Schedule每次从 channel 接收一个int类型的数据,并将其追加到data切片中。Close()方法:关闭ch通道。AddData(v int)方法:将v数据发送到ch通道中。
另外,上面代码还定义了一个 NewScheduleJob 函数,用于创建 ServiceData 实例并启动协程。具体来说,该函数创建了一个缓冲大小为 size 的 ch 通道,并且创建了一个初始为空的 data 切片。接着,在一个协程中通过调用 Schedule() 方法,不断地从 ch 通道中接收数据,并将其追加到 data 切片中。同时,该函数还接受一个回调函数 done,当 Schedule() 协程结束时,会回调该函数告知任务已完成。
在 main() 函数中,定义了一个 wg 变量,即 sync.WaitGroup,用于等待协程执行结束。同时,创建了一个缓冲大小为 0 的 c 通道。接着,通过调用 NewScheduleJob(n, func() { c <- struct{}{} }) 方法,创建 ServiceData 实例并启动协程。然后,在一个 for 循环中,创建了 n 个协程,每个协程通过调用 s.AddData(v) 方法来向 ch 通道发送数据。在 main() 函数的最后,调用 s.Close() 方法关闭 ch 通道,等待 Schedule() 协程执行完毕,并通过 <-c 接收到所有任务已完成后的通知。最后,输出 s.data切片的长度。
简而言之,该段代码的作用是:在一个协程中并发收集数据,并且可以随时添加数据,在主协程中等待任务完成后输出收集到的数据长度
slice使用注意事项
在使用 golang 的 slice(切片)时,需要注意以下几点:
- 切片底层数组的容量:切片的底层数组容量一般是扩充 2 倍,所以当切片的长度接近于底层数组的容量时,需要注意数组的重新分配和复制带来的性能影响。
- 切片与数组的区别:切片是一个引用类型,底层数组的修改会影响到所有的切片,因此需要注意在函数传参时,将切片传递给其他函数的情况,建议函数获取参数时,深拷贝复制新的slice,防止对老的slice产生影响
- 切片的长度和容量:在使用切片时,需要注意长度和容量的区别。长度代表切片中实际包含的元素个数,容量代表底层数组中可用的元素个数。可以通过内置函数 len() 和 cap() 来获取切片的长度和容量。
- 切片的拷贝:在复制切片时建议使用copy() 函数,否则两个切片将共享同一个底层数组。
- 切片的追加:使用内置函数 append() 可以向切片中追加元素,但需要注意切片追加时可能会引起底层数组重新分配和复制,对性能有一定的影响。
总结
length
切片中的length是该切片中当前已存储的元素个数
capacity
切片的容量是该切片指向的数组的元素个数。往一个满了的切片(切片长度=切片容量)中添加新元素会触发创建一个新的数组,并且新数组的容量是原来的2倍,该新数组会将原数组中的元素都拷贝过来,同时将slice中的指针更新到指向新数组
浅拷贝
slice的切分(如:s2 := s1[1:3])是浅拷贝,需要注意s2的修改可能会影响s1,也可能不会影响,需要根据s2是否扩容来确认。为了避免切片的传递修改对原切片影响,建议使用深拷贝
深拷贝
使用copy(dest, source)对切片做深拷贝,如copy(s2[:], s1),可以避免s2的修改对s1的影响。当slice的元素是一个struct时,如果struct中存在指针类型,需要特殊处理一下
list
Golang 中内置了一个双向链表类型 package list ,可以用它来存储一系列的元素。下面是一个例子:
package main
import (
"fmt"
"container/list"
)
func main() {
mylist := list.New()
mylist.PushBack(1)
mylist.PushBack(2)
mylist.PushBack(3)
for x := mylist.Front(); x != nil; x = x.Next() {
fmt.Println(x.Value.(int))
}
}
这个例子中,我们创建了一个包含 1、2 和 3 的双向链表,然后用 for 循环遍历这个链表,打印每一个元素的值。
PushBack 的方法可以向链表的尾部添加元素。如果你需要在链表的头部添加元素,可以使用 PushFront 方法。如果你需要从链表中删除元素,可以使用 Remove 方法,例如
mylist.Remove(someElement)
slice vs list
在Golang中,建议使用Slice而不是List。Slice在性能方面要优于List。
Slice是基于数组实现的,它提供了一个动态数组的抽象。Slice比数组更加灵活,可以按需增加或减少元素。另外,Slice还提供了一些有用的方法,如append()和copy(),可以很方便地进行元素的增加、删除和复制。
List则是基于链表实现的,每个元素都包含了指向前一个和后一个元素的指针。虽然List和Slice一样能够动态添加和删除元素,但是由于List的每个元素都需要保存指针信息,所以List的内存占用比Slice更大,在性能方面也会受到影响
map
map结构
type hmap struct {
count int // 元素的个数
B uint8 // buckets 数组的长度就是 2^B 个
overflow uint16 // 溢出桶的数量
buckets unsafe.Pointer // 2^B个桶对应的数组指针
oldbuckets unsafe.Pointer // 发生扩容时,记录扩容前的buckets数组指针
extra *mapextra //用于保存溢出桶的地址
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
type bmap struct {
tophash [bucketCnt]uint8
}
//在编译期间会产生新的结构体
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}
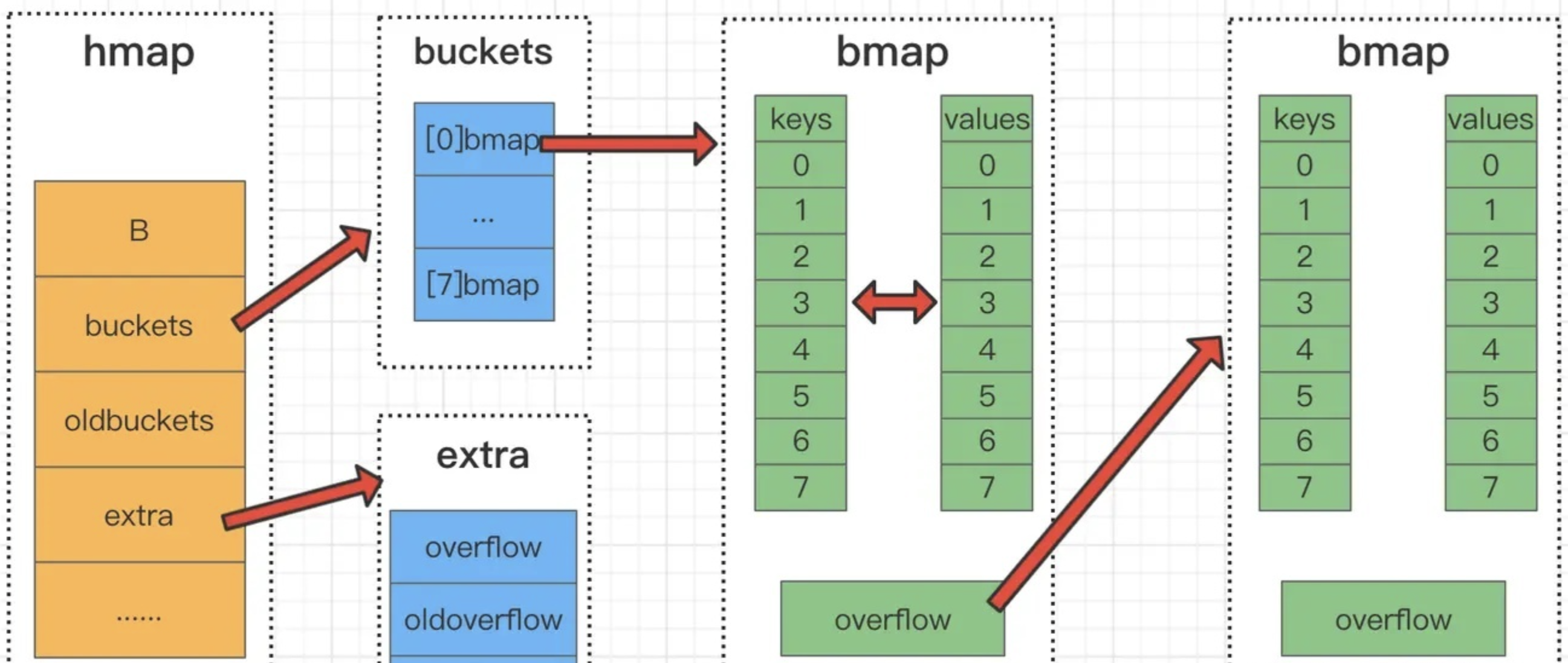
在go的map实现中,它的底层结构体是hmap,hmap里维护着若干个bucket数组 (即桶数组)。
Bucket数组中每个元素都是bmap结构,也即每个bucket(桶)都是bmap结构,每个桶中保存了8个kv对,如果8个满了,又来了一个key落在了这个桶里,会使用overflow连接下一个桶(溢出桶)。
map数据读取
Go 语言中 map 采用的是哈希查找表,由一个 key 通过哈希函数得到哈希值,64位系统中就生成一个 64bit 的哈希值,由这个哈希值将 key 对应到不同的桶 (bucket)中,当有多个哈希映射到相同的的桶中时,使用链表法解决哈希冲突
- key 经过 hash 后共 64 位,根据 hmap 中 B 的值,计算它到底要落在哪个桶 时,桶的数量为 2^B,如 B=5,那么用 64 位最后 5 位表示第几号桶
- 然后依次遍历tophash和计算hash值的高8位是否相等,如果相等则说明元素大概率是找到了,这个时候再详细比较key是否完全一致即可
- 当前 bmap 中的 bucket 未找到,则查询对应的 overflow bucket,对应位置有数据则对比完整的哈希值,确定是否是要查找的数据
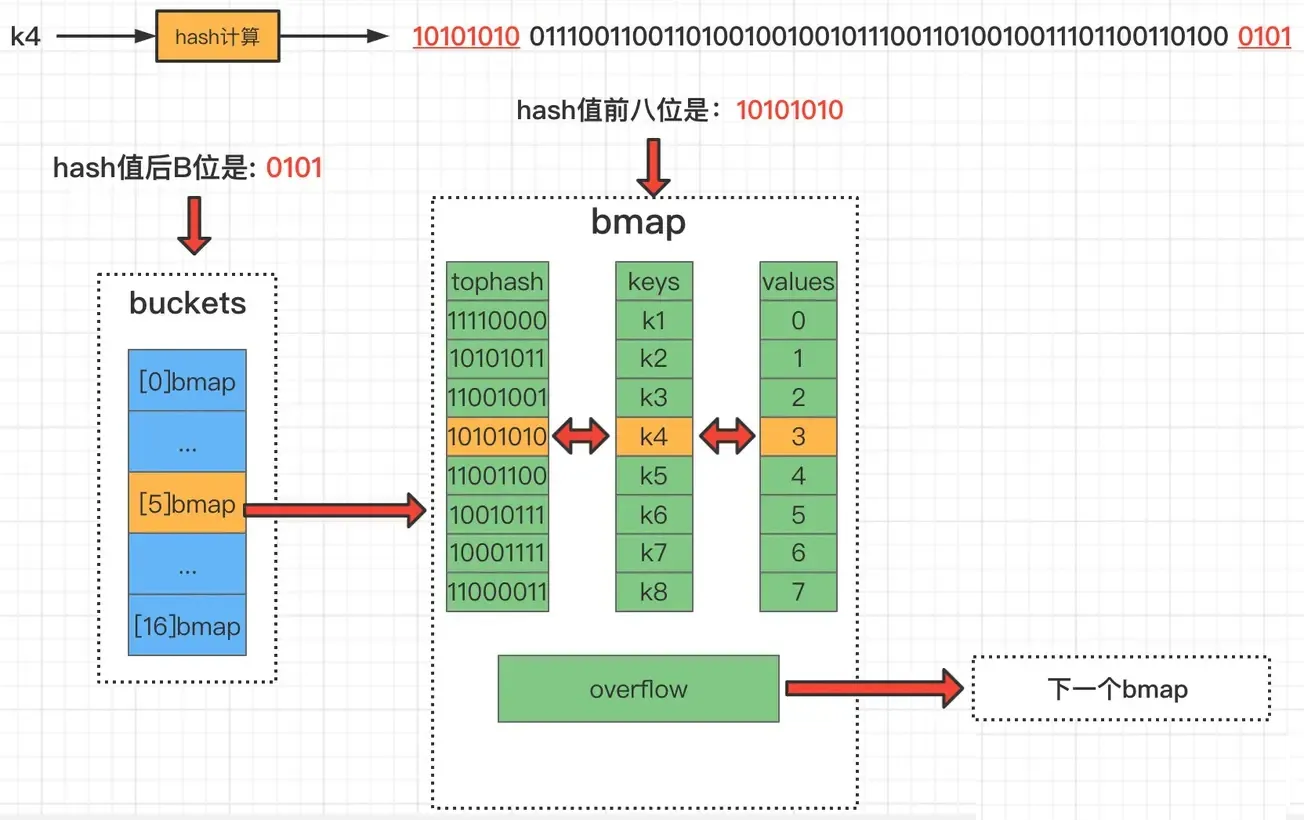
map数据写入
和读取的逻辑一样,先通过hash低n位确定桶,然后根据高8位确定在桶内的位置

可以看到bmap里面有个tophash属性,是一个uint8的数组,其中bucketCnt的值在源代码最上面有定义,大小为8,也就是每个桶中可以放8个元素,这里uint8仅仅存放hash值的高8位,可以参考下面这个图:
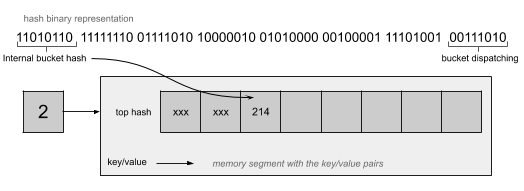
如果两个不同的key被定位到同一个桶中,其实就可以认为出现了哈希冲突
那么这种情况下就依次按照顺序从前往后将hash值的高8位写入到数组空闲的元素中,这里思路和链表法是一致的,之所以这么设计是为了提高哈希冲突时比较的速度,因为比较1个字节要比比较一个很长的key快
如果当前桶存储满了,则会继续挂上新的存储桶,也叫溢出桶,通过这种方式来进行扩展
map扩容过程
map默认的负载因子阈值为0.75。当map中的元素个数达到了内部存储区域容量的0.75倍时,Go就会重新分配更大的内部存储区域。默认情况下,每次扩容会将内部存储区域容量加倍
扩容的流程如下:
- 检查当前存储的元素个数是否超过了当前内部存储区域容量的负载因子阈值
- 申请一个新的哈希表,并将其大小设置为当前哈希表大小的两倍
- 遍历原来的哈希表中的所有桶,将每个桶中的元素重新计算哈希值,然后插入到新哈希表中对应的位置。
- 更新指向旧哈希表的指针为指向新哈希表
- 释放旧哈希表的内存
map中元素是无序的
在 golang 中 map 是无序的,准确的说是无法严格保证顺序的。 golang中map的扩容和slice类似,当元素个数达到临界值时(即当前元素个数等于桶的数量),就需要对 map 进行扩容。扩容操作首先要计算出新的桶的数量,新的桶数量是当前原有桶数量的两倍。扩容后,可能会将部分 key 移至新内存,由于在扩容搬移数据过程中,并未记录原数据位置, 并且在 golang 的数据结构中也并未保存数据的顺序,所以那么这一部分在扩容后实际上就已经是无序的了。
如果我就一个 map,我保证不会对 map 进行修改删除等操作,那么按理说没有扩容就不会发生改变。为了防止用户这么使用出现异常,golang 官方在设计时故意加上随机的元素,将遍历 map 的顺序随机化,用来防止使用者用来顺序遍历,就算不对 map 进行插入删除等操作致使其扩容,其在遍历过程中仍是无序的
map并发使用
Map不是线程安全的,因此在并发读写时可能会导致不确定的结果。目前一般有以下几种方案:分别是读写锁、分片锁和 sync.map。较常使用的是前两种,而在特定的场景下,sync.map 的性能会有更优的表现
使用读写锁
type RWMap struct { // 一个读写锁保护的线程安全的map
sync.RWMutex // 读写锁保护下面的map字段
m map[int]int
}
// 新建一个RWMap
func NewRWMap(n int) *RWMap {
return &RWMap{
m: make(map[int]int, n),
}
}
func (m *RWMap) Get(k int) (int, bool) { //从map中读取一个值
m.RLock()
defer m.RUnlock()
v, existed := m.m[k] // 在锁的保护下从map中读取
return v, existed
}
func (m *RWMap) Set(k int, v int) { // 设置一个键值对
m.Lock() // 锁保护
defer m.Unlock()
m.m[k] = v
}
func (m *RWMap) Delete(k int) { //删除一个键
m.Lock() // 锁保护
defer m.Unlock()
delete(m.m, k)
}
func (m *RWMap) Len() int { // map的长度
m.RLock() // 锁保护
defer m.RUnlock()
return len(m.m)
}
func (m *RWMap) Each(f func(k, v int) bool) { // 遍历map
m.RLock() //遍历期间一直持有读锁
defer m.RUnlock()
for k, v := range m.m {
if !f(k, v) {
return
}
}
}
使用concurent-map
https://github.com/orcaman/concurrent-map
star数3.6K
极客时间:**Go 语言从入门到实战:**https://github.com/easierway/concurrent_map
star数只有300
concurrent-map使用示例
func (m ConcurrentMap) Set(key string, value interface{}) {
// 根据key计算出对应的分片
shard := m.GetShard(key)
shard.Lock() //对这个分片加锁,执行业务操作
shard.items[key] = value
shard.Unlock()
}
func (m ConcurrentMap) Get(key string) (interface{}, bool) {
// 根据key计算出对应的分片
shard := m.GetShard(key)
shard.RLock()
// 从这个分片读取key的值
val, ok := shard.items[key]
shard.RUnlock()
return val, ok
}
使用sync.map
实际在生产环境中,sync.map 用的很少,官方文档推荐的两种使用场景是:
a) when the entry for a given key is only ever written once but read many times, as in caches that only grow.
b) when multiple goroutines read, write, and overwrite entries for disjoint sets of keys.
两种场景都比较苛刻,要么是一写多读,要么是各个协程操作的 key 集合没有交集(或者交集很少)。所以官方建议先对自己的场景做性能测评,如果确实能显著提高性能,再使用 sync.map。
sync.map 的整体思路就是用两个数据结构(只读的 read 和可写的 dirty)尽量将读写操作分开,来减少锁对性能的影响
sync.map实现原理
- 读写分离。读(更新)相关的操作尽量通过不加锁的 read 实现,写(新增)相关的操作通过 dirty 加锁实现。
- 动态调整。新写入的 key 都只存在 dirty 中,如果 dirty 中的 key 被多次读取,dirty 就会上升成不需要加锁的 read。
- 延迟删除。Delete 只是把被删除的 key 标记成 nil,新增 key-value 的时候,标记成 enpunged;dirty 上升成 read 的时候,标记删除的 key 被批量移出 map。这样的好处是 dirty 变成 read 之前,这些 key 都会命中 read,而 read 不需要加锁,无论是读还是更新,性能都很高
其他容易踩坑的地方
- 对空map进行写操作:对空map进行写操作会导致panic。因此,在对map进行写操作之前,应该首先确保map已经被初始化。map作为结构体成员的时候,很容易忘记对它的初始化。
- 判断map中是否存在某个key:直接使用myMap[key]进行判断可能会导致误判,因为即使key不存在,也会返回map的零值。可以使用以下方式来判断map中是否存在某个key:
if value, ok := myMap[key]; ok {
// key exists
} else {
// key does not exist
}
set
Go 语言标准库没有提供 Set 的实现,通常使用 map 来代替。事实上,对于集合来说,只需要 map 的键,而不需要值。即使是将值设置为 bool 类型,也会多占据 1 个字节,那假设 map 中有一百万条数据,就会浪费 1MB 的空间。
因此呢,将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可
这些类型封装后,可以放入shopline通用工具包里使用,不必大家都封装一个
type Set map[string]struct{}
func (s Set) Has(key string) bool {
_, ok := s[key]
return ok
}
func (s Set) Add(key string) {
s[key] = struct{}{}
}
func (s Set) Delete(key string) {
delete(s, key)
}
func main() {
s := make(Set)
s.Add("Tom")
s.Add("Sam")
fmt.Println(s.Has("Tom"))
fmt.Println(s.Has("Jack"))
}
















 2114
2114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









