







刚才讨论了评价推荐系统的指标,算法工程师的工作是对模型特征策略系统做改进,提升各种指标。
对推荐系统的改动能不能最终上线,要拿实验结果来说话。
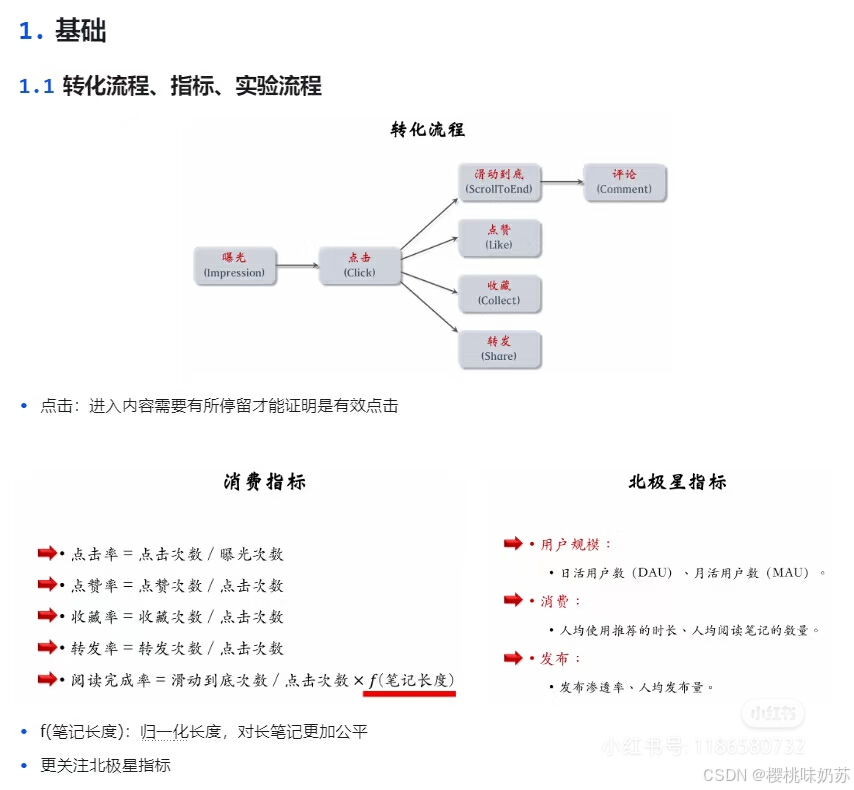
实验流程:
离线实验并没有线上实验可靠,想最终判断算法的好坏,还是需要做线上实验。
前面提到的北极星指标都是线上指标,只能通过线上实验获得,做离线实验无法得到这些指标。
具体做法是开小流量ab测试,把用户随机分为实验组和对照组,实验组用新策略,对照组用旧策略对比两者的业务指标,判断新策略是否会显著优于旧策略。
如果新策略显著优于旧策略,可以加大流量,最终推全。
high level的概述O.o
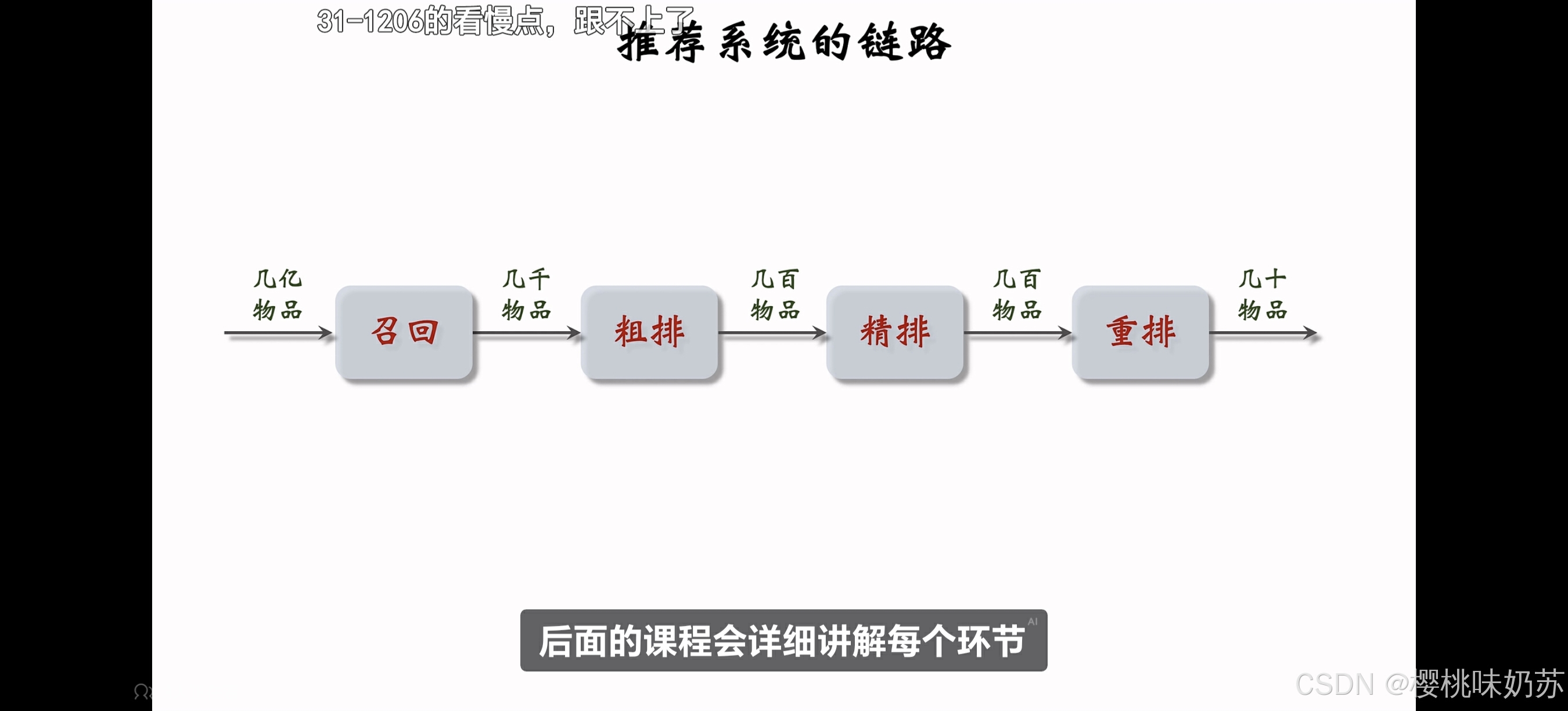
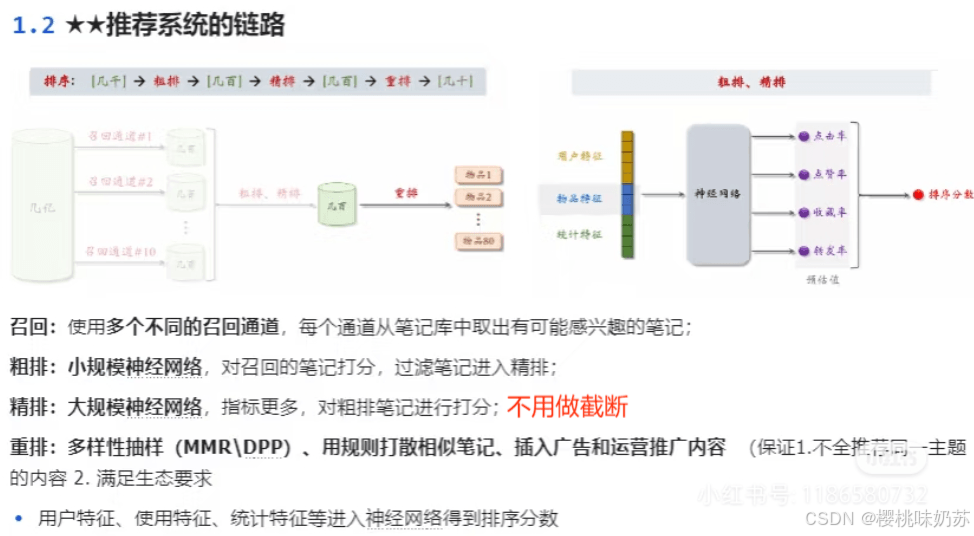
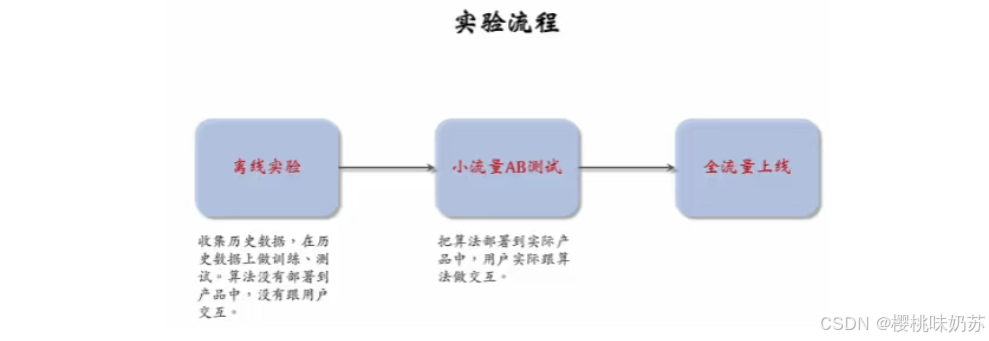
召回:从物品的数据库中快速取回一些物品
比如小红书有上亿篇笔记,当用户刷新小红书的时候,系统会同时调用几十条召回通道,每条召回通道取回几十到几百篇笔记,一个取回几千篇笔记,做完召回之后。
接下来要从几千篇笔记中选出用户最感兴趣的。
下一步是粗排:用规模比较小的机器学习模型给几千篇笔记逐一打分,按照分数做排序和截断,保留分数最高的几百票笔记。
再下一步是精排,这里要用大规模的深度神经网络给几百篇笔记逐一打分,精排的分数反映出用户对笔记的兴趣。
在精排之后,可以做截断也可以不做截断。
我们xhs的精排不做截断,所有的这几百篇笔记都带着精排分数进入重排。
重排是最后一步,这里会根据精排分数和多样性分数做随机抽样,得到几十篇笔记。
然后把相似内容打散,并且插入广告和运营内容。
这就是推荐系统的大致情况。
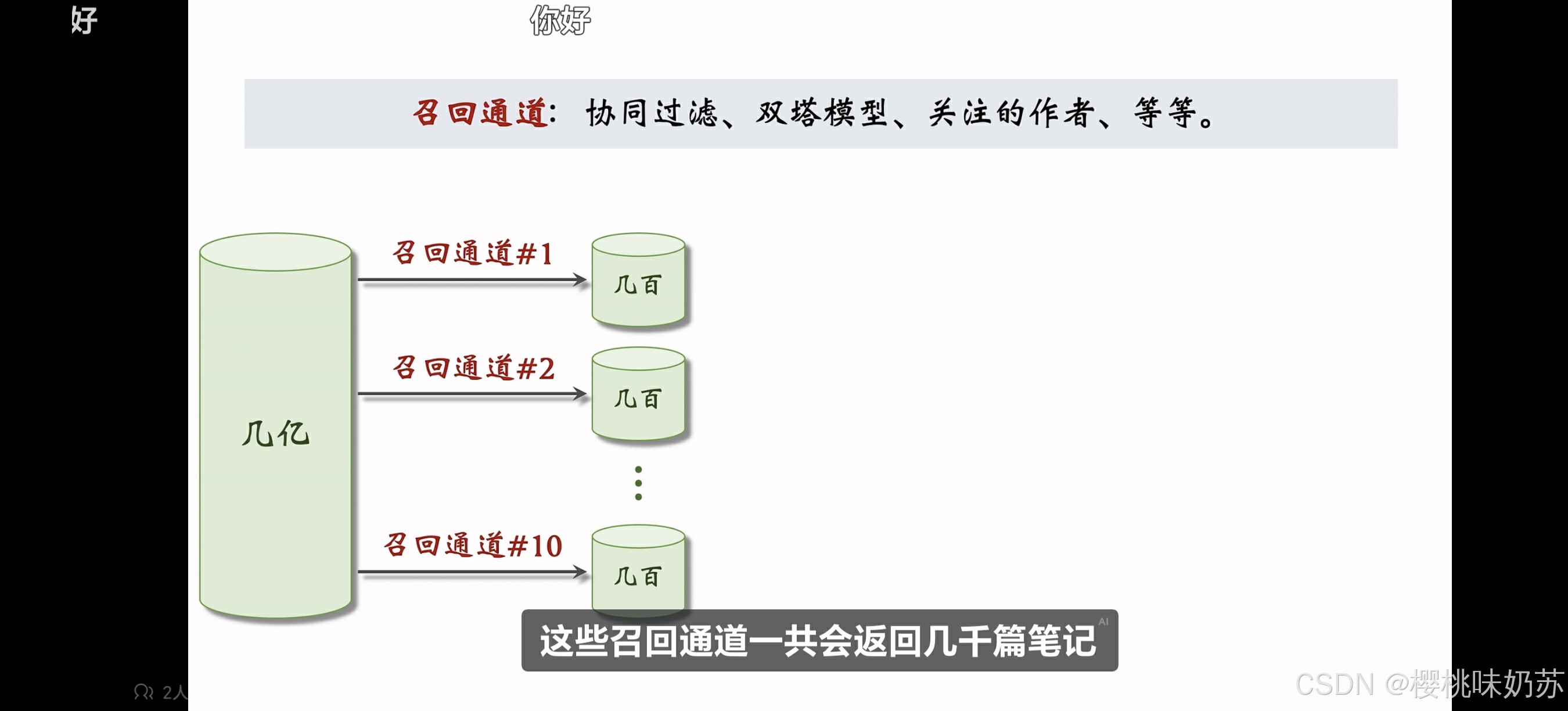
这些召回通道一共会返回几千条笔记,然后推荐系统会融合这些笔记,并且做去重和过滤。
过滤的意思是排除掉用户不喜欢的作者、不喜欢的笔记、不喜欢的话题。
召回几千条笔记后,下一步是做排序,排序是用机器学习模型预估用户对笔记的兴趣,保留分数最高的笔记。
如果直接用大规模的神经网络逐一对几千篇笔记打分,花费代价会很大。为了解决计算量的问题,通常把排序分为粗排和精排这两步。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









