






1.detect
2.train

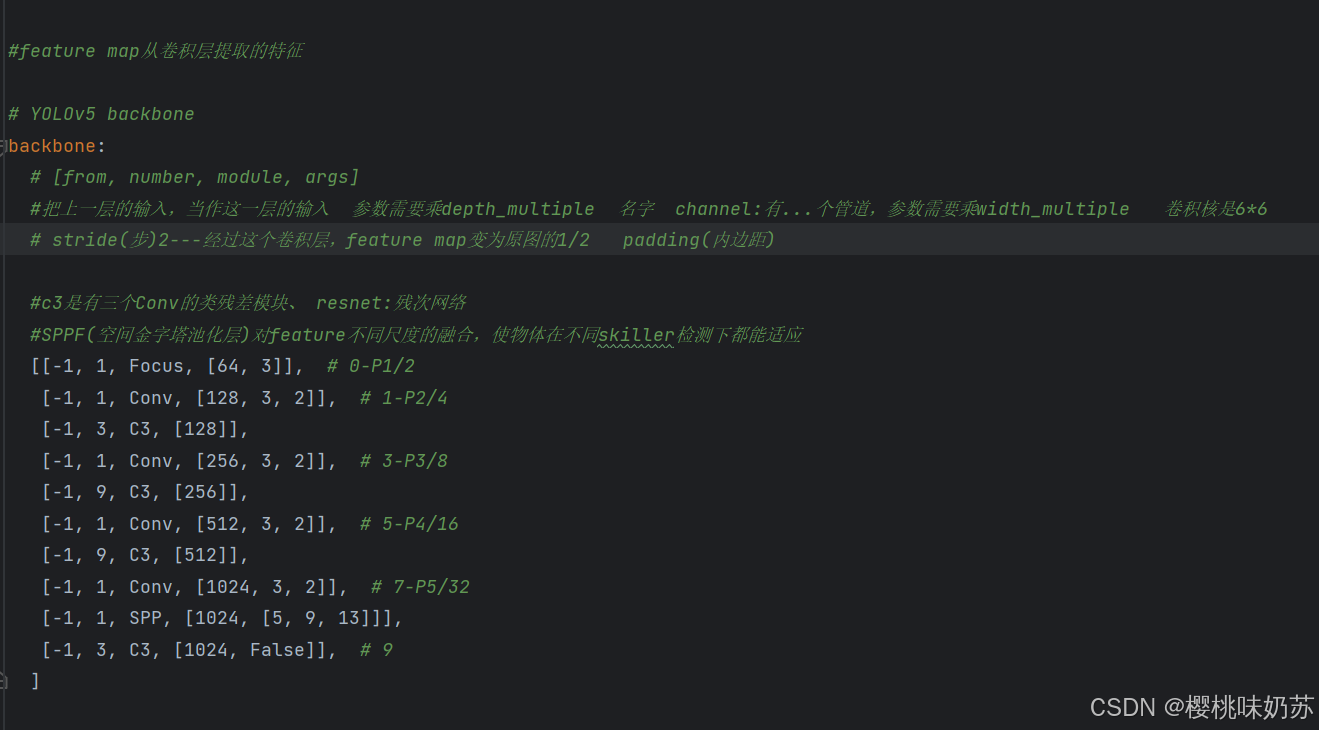
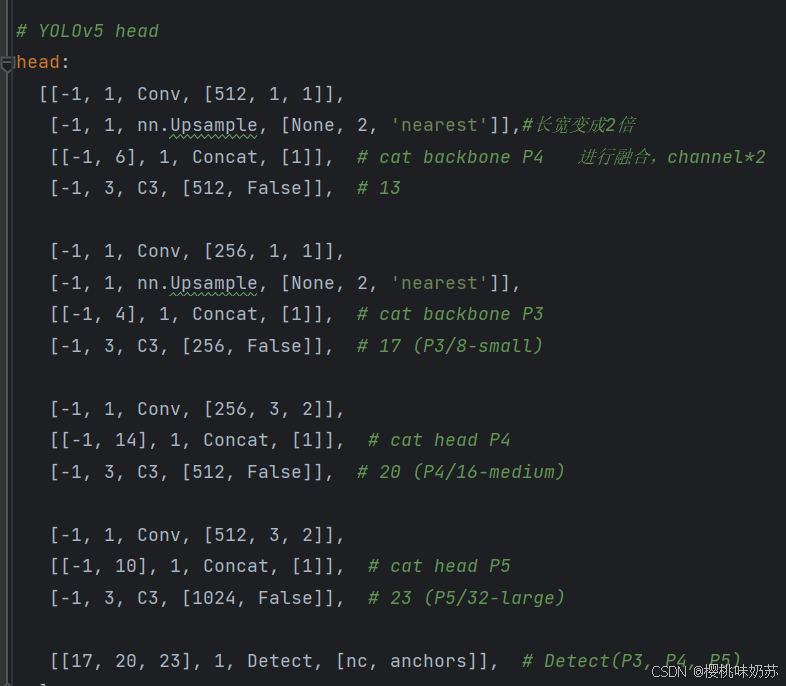
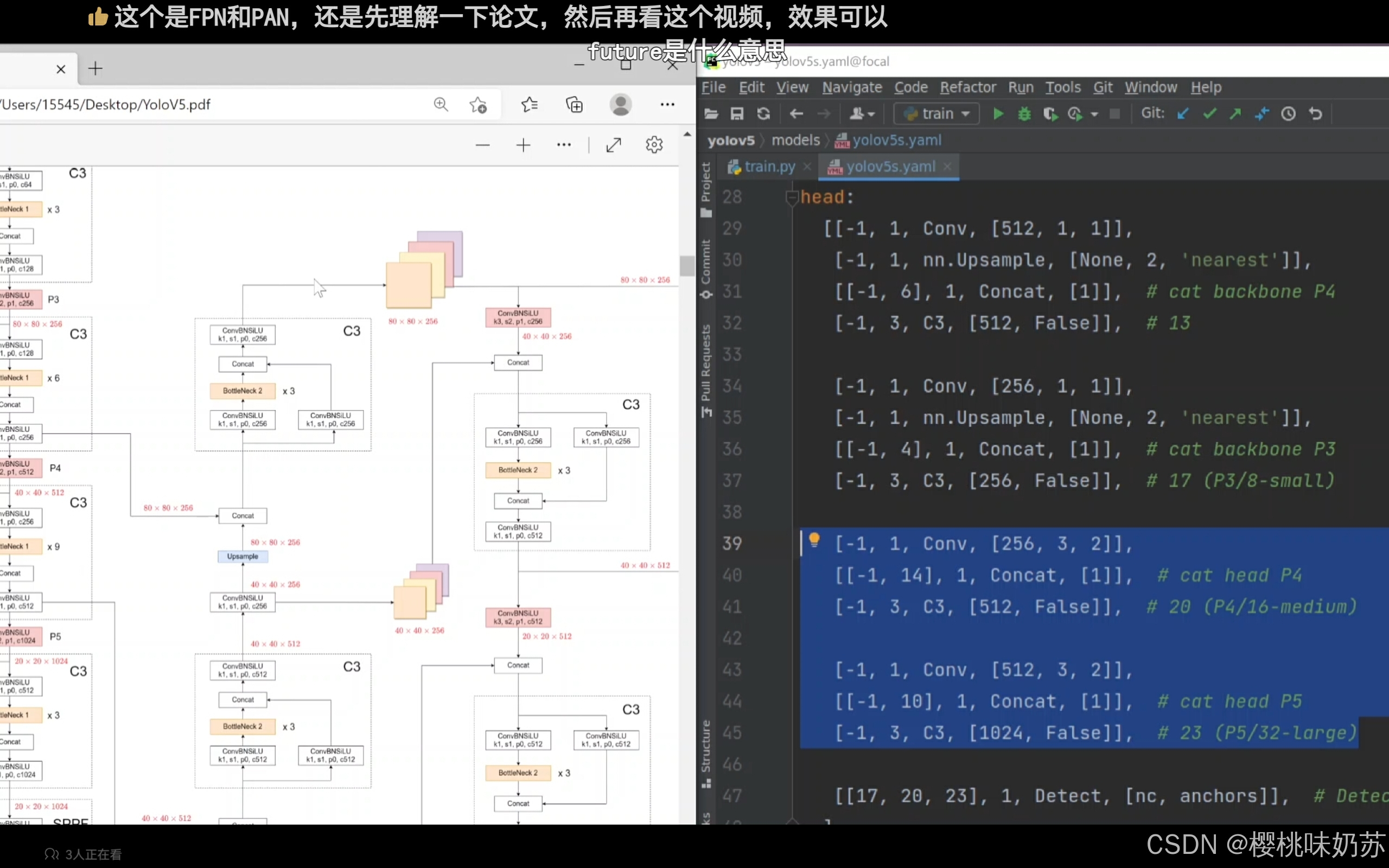
3.yolov5模型架构
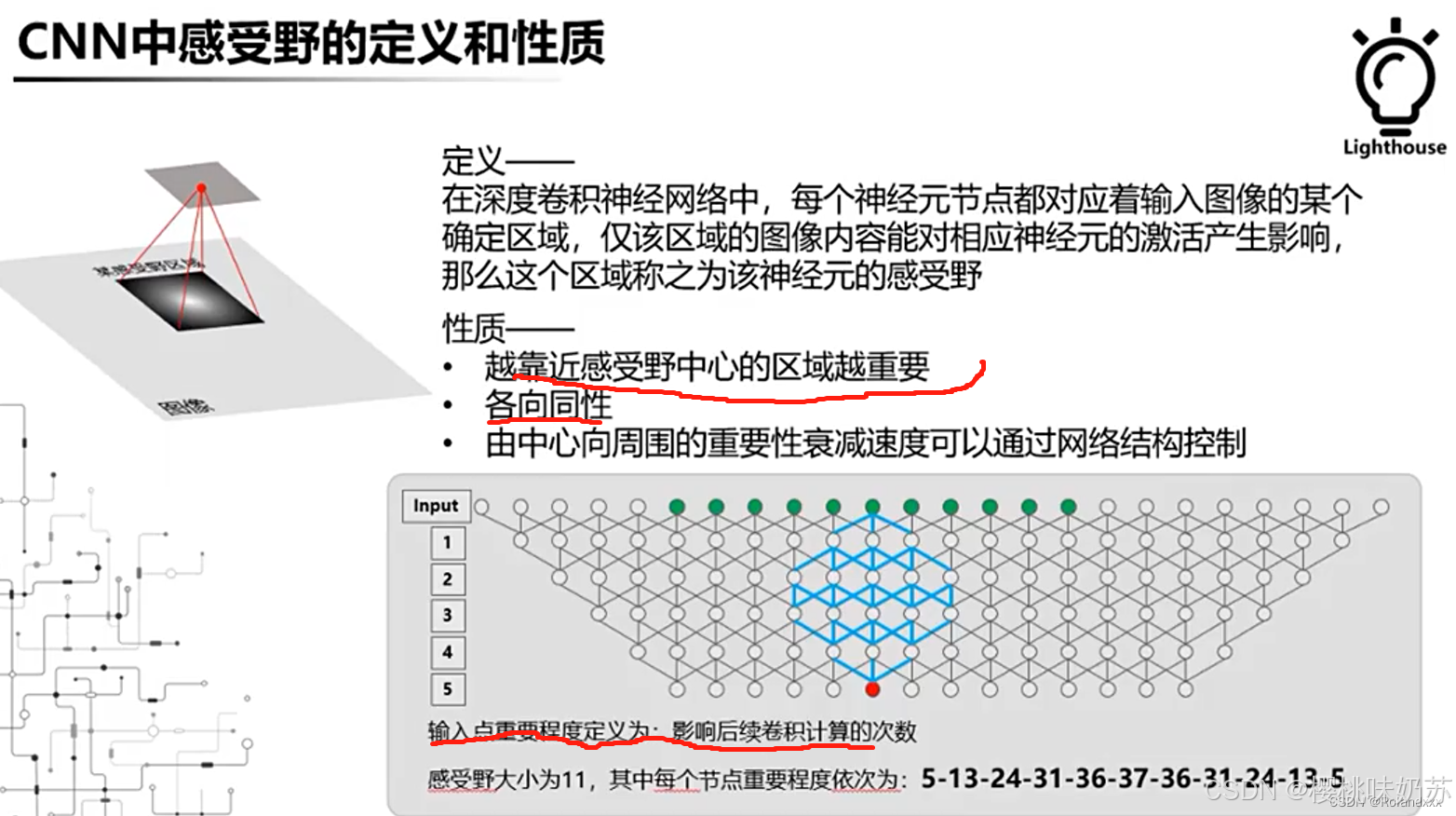
anchor:锚
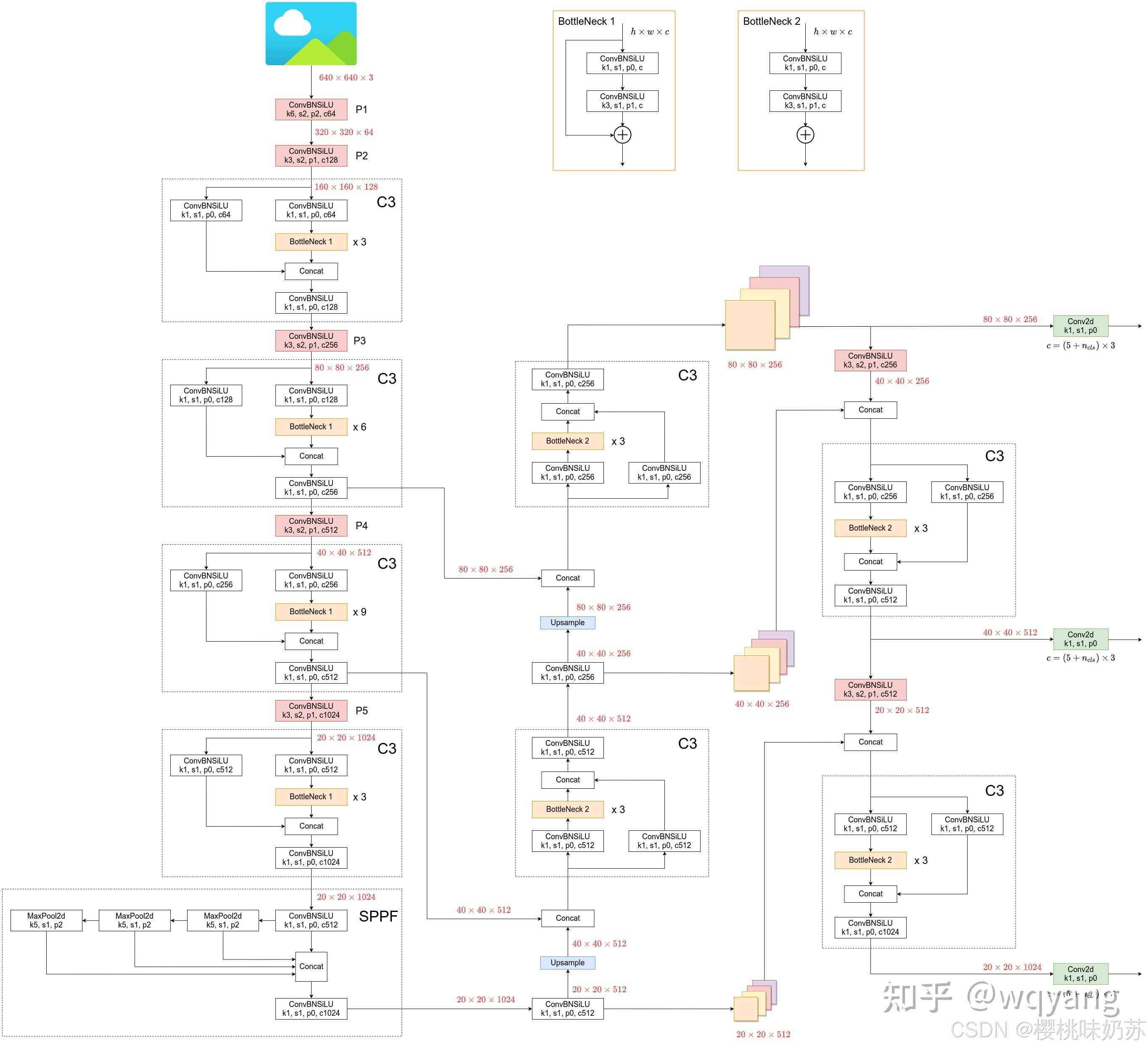
第二个数字表示重复的次数,还需要乘以depth_m...
向上特征融合:FPN
向下特征融合:PAN
4.Aero-yolov8模型架构
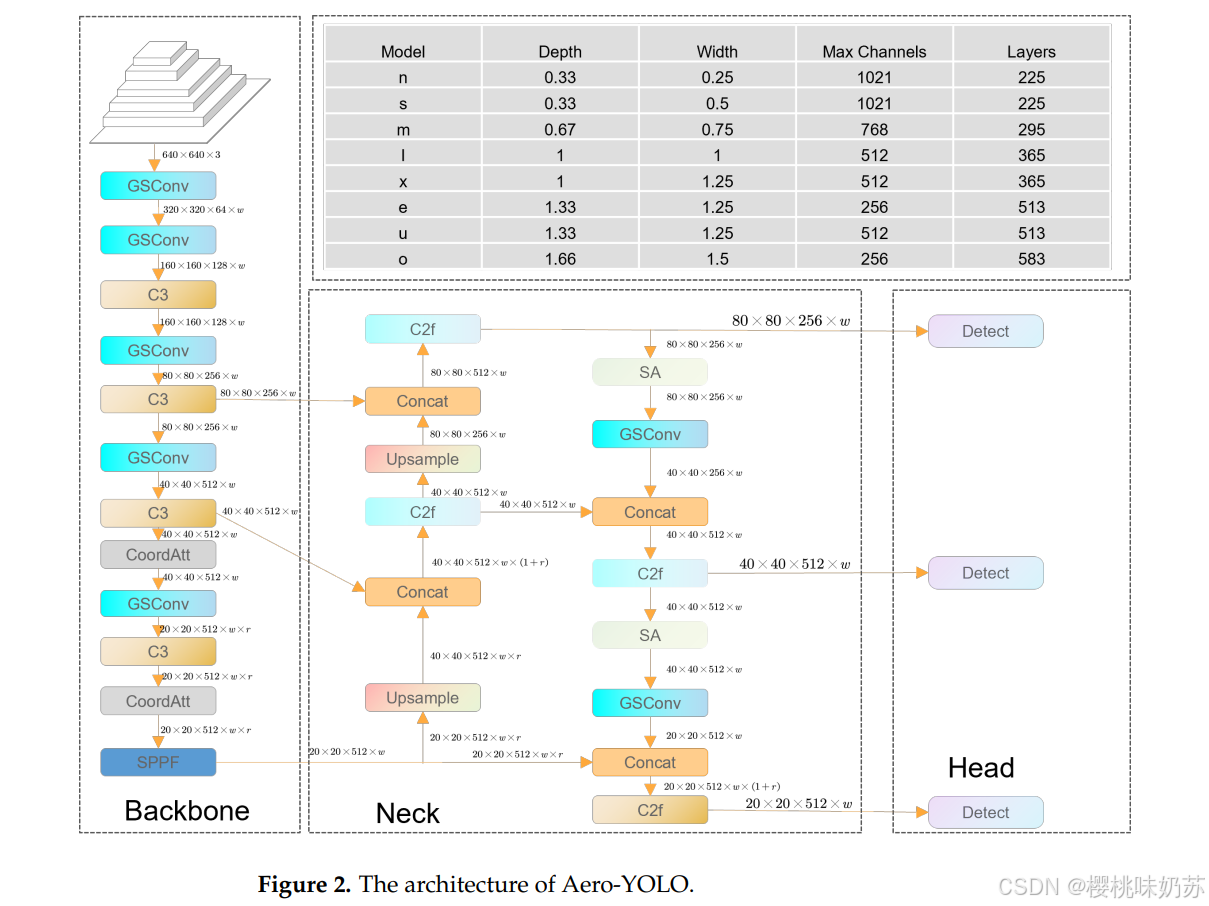
coordatt:注意力转移机制
通过一维特征编码捕获远程依赖和精确位置信息
随机注意力机制
-
CoordAtt和shuffle attention[13]机制的结合增强了特征提取,特别是有利于从无人驾驶飞行器的角度检测小型或受阻的车辆。
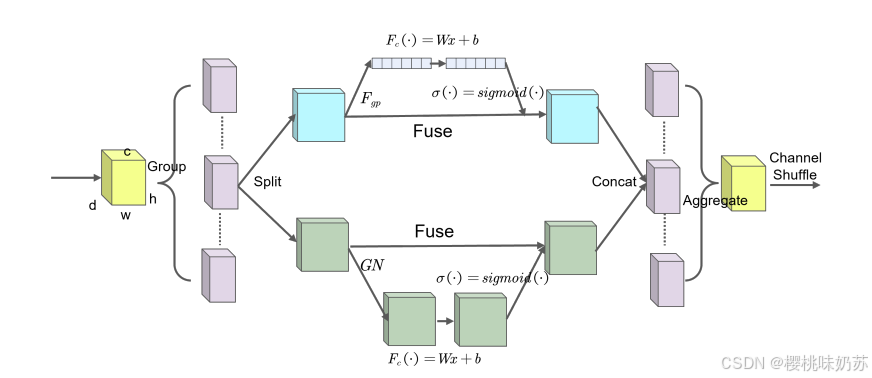
SA机制:采用两种注意力机制:空间和通道注意力机制,对通道特征进行分组得到多个子特征,使用channel shuffle融合各个子特征。
GSConv替换原来的Conv模块,用C3替换C2f模块,以减少模型参数,扩大感受野,提高计算效率
减轻模型复杂度的同时保持检测精度
YOLOv5改进(六)--引入YOLOv8中C2F模块_yolov8 c3和c2f-CSDN博客
GSConv和Conv比起来有什么优点
GSConv(Groupwise Separable Convolution)相比于传统的卷积(Conv)有几个优点:
1. 计算效率:GSConv通过将卷积操作分解为组卷积和逐点卷积,减少了计算量和参数量,提高了效率。
2. 更少的参数:它利用分组卷积降低了模型的参数数量,从而减少了内存消耗和计算负担。
3. 更快的推理速度:由于计算复杂度降低,GSConv通常能在较少的计算资源下提供更快的推理速度,适合移动设备和嵌入式系统。
这些优势使得GSConv在实际应用中更加高效,尤其是在资源有限的情况下。
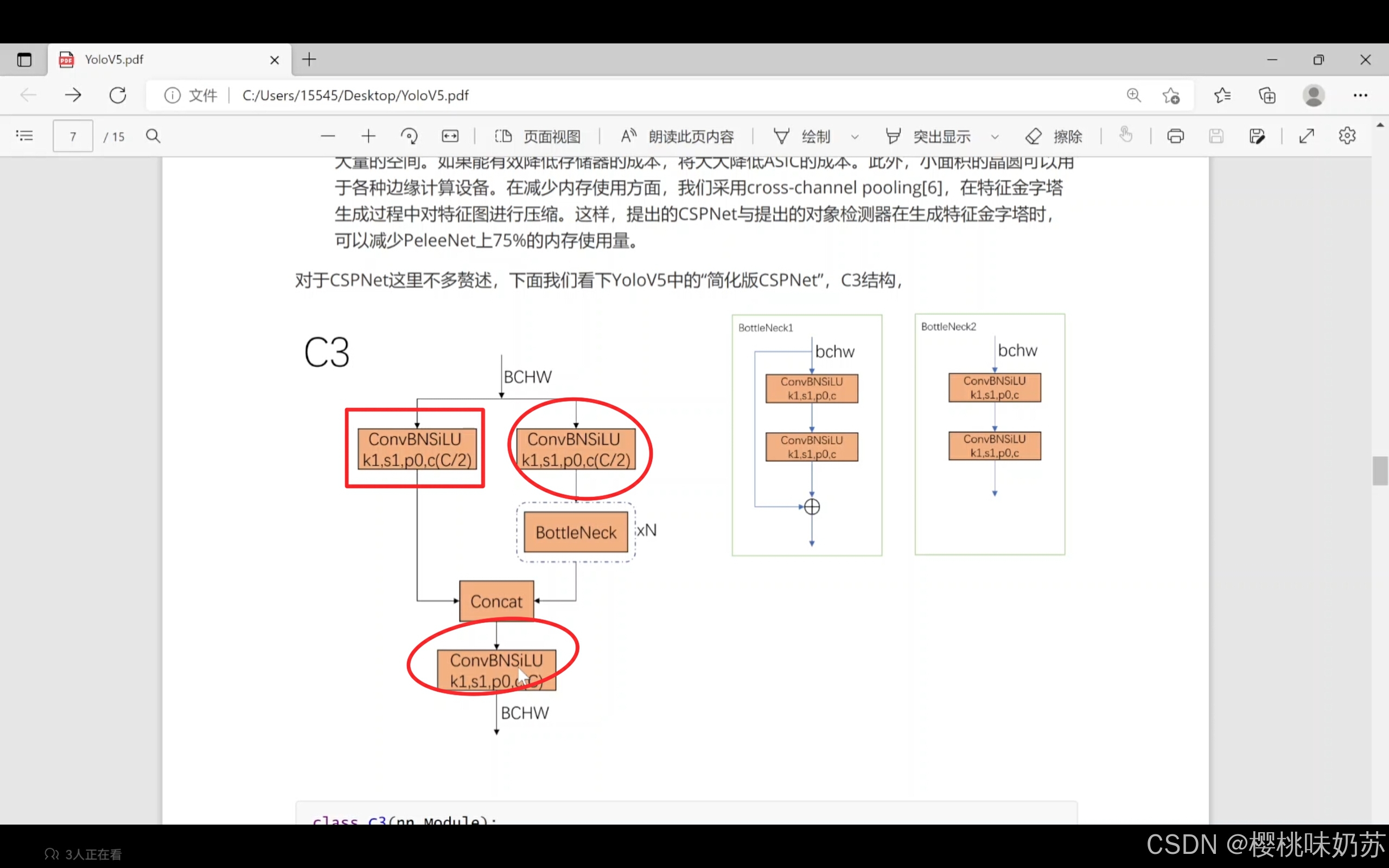
C3:三个conv块
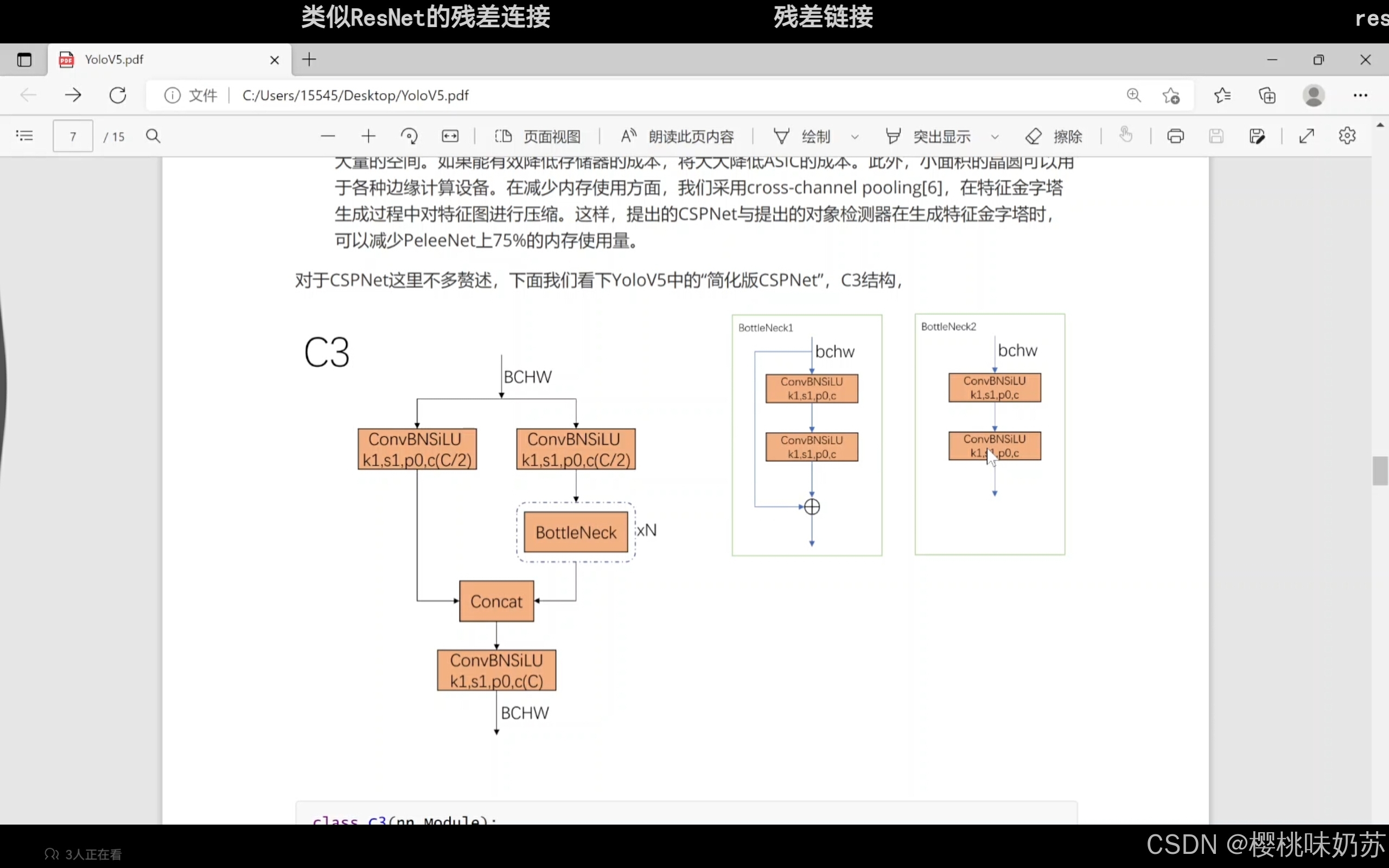
resnet:残差网络
fpn和pan:FPN和PAN的内容及区别(修改版1.2)-CSDN博客

数据集:UAV-ROD和VisDrone2019数据集(无人机拍摄图片)
通过与自适应矩估计(Adam)[14]的对比分析,选择随机梯度下降(SGD)作为优化器,在模型收敛性和整体效率方面具有优异的性能。
- Adam: 由于其易用性和快速收敛的特点,Adam非常适合在需要快速得到结果的场景中使用,特别是在计算资源有限或模型较复杂时。
- SGD: 如果模型训练时出现过拟合,或者当你有足够的时间和资源来精细调整学习率时,SGD可能是更好的选择。对于大规模分布式训练,SGD的泛化能力可能更优。
将原始的 CSPDarknet53 替换为带有 C3 的两级 FPN (C2f) 模块,使模型的结构更加轻巧。
在YOLOv8现有参数的基础上,引入了三个新的参数规范,Aero-YOLO (extreme), Aero-YOLO (ultra), and Aero-YOLO (omega)
从广义上讲,目标检测算法通常分为两阶段和一阶段方法,它们的处理阶段存在根本差异。两阶段算法涉及使用单独的网络进行区域提案和分类/回归任务。两阶段方法的一个典型例子是Faster R-CNN[19],它依赖于基于区域的卷积神经网络。相比之下,YOLO [20]、SSD [21] 和 RetinaNet [22] 等单阶段方法利用单一网络直接对边界框进行分类并使用锚点进行调整。
阅读:在RetinaNet之前,目标检测领域普遍认为one-stage算法,如YOLO系列和SSD,在准确性上不及two-stage算法,如Faster R-CNN。这种差异主要源于以下两个原因:
two-stage算法的流程包括使用RPN(Region Proposal Network)生成一系列的建议框,随后在这些建议框的基础上利用Fast R-CNN进行精细化调整,这一双阶段的设计使得结果更为精确。
样本不平衡问题在one-stage算法中尤为突出。在Faster R-CNN中,正负样本的比例被明确设定为1:3,而one-stage算法中的正负样本比可能极端失衡,有时甚至达到1:1000。这种不平衡导致在训练过程中,梯度主要被简单样本所驱动,而复杂样本因为占比小,在损失函数的计算中被大量简单样本的影响所淹没。
RetinaNet的提出,在一定程度上解决了这一问题,它使得one-stage算法也能达到与two-stage算法相媲美的准确性。


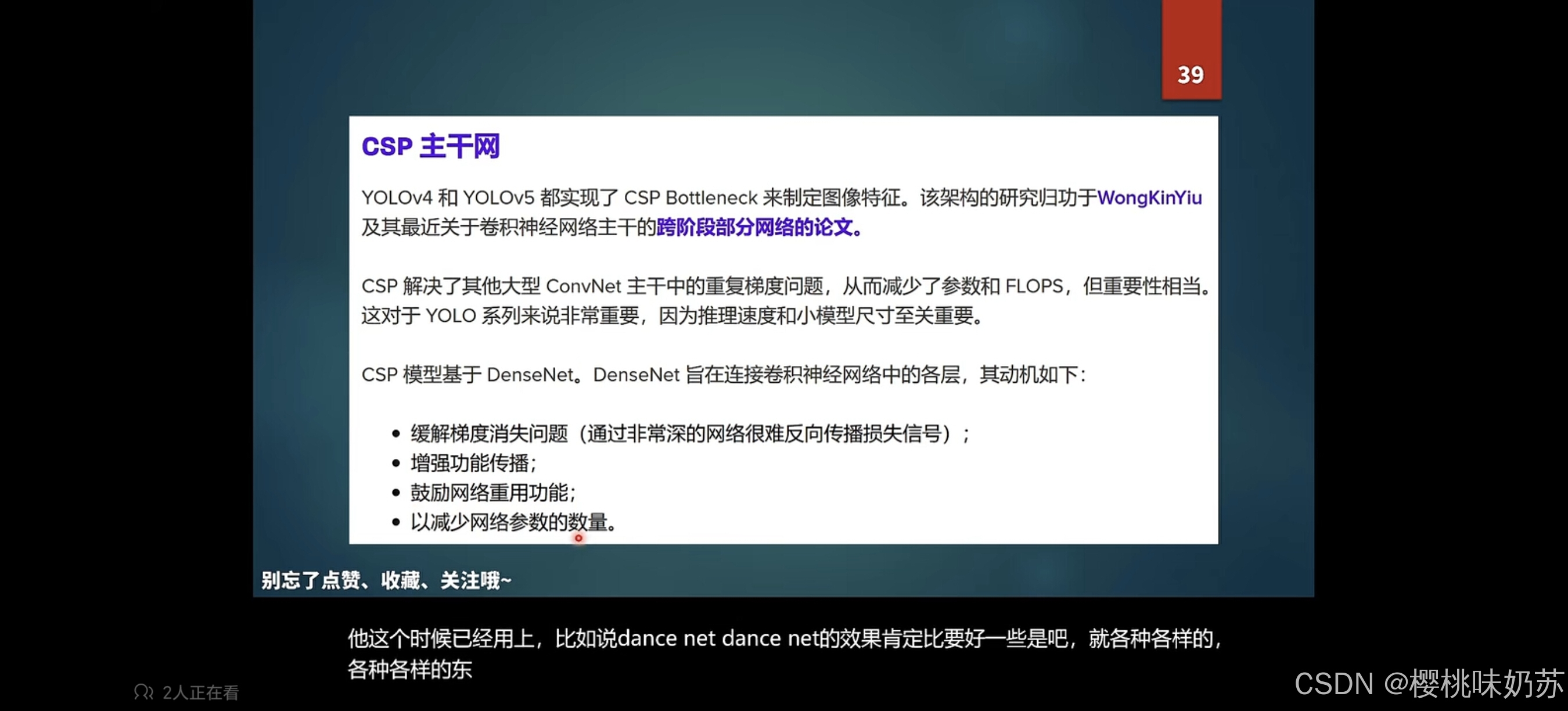
在一级探测器中最具代表性的算法之一是YOLO系列。YOLO采用卷积神经网络提取图像特征,并通过生成锚定框直接预测边界框和类别,从而实现实时目标检测。YOLOv2 [23] 用 Darknet-19 取代了原来的 YOLO 的 Google Inception Net(GoogleNet),而 YOLOv3 [24] 将 Darknet-19 升级为 Darknet-53,并采用了多尺度框架,保留了 ResNet [25] 的剩余连接。YOLOv4 [26] 结合了 CSPNet [27]、Darknet-53 框架、CIoU 损失 [28] 和 Mish 激活函数 [29] 来增强性能。YOLOv5 集成了前面提到的各种架构,在推理速度、精度和计算成本方面提供了多种选择。2023 年 1 月发布的 YOLOv8 [30] 采用了 YOLOv5 [31] 的更新

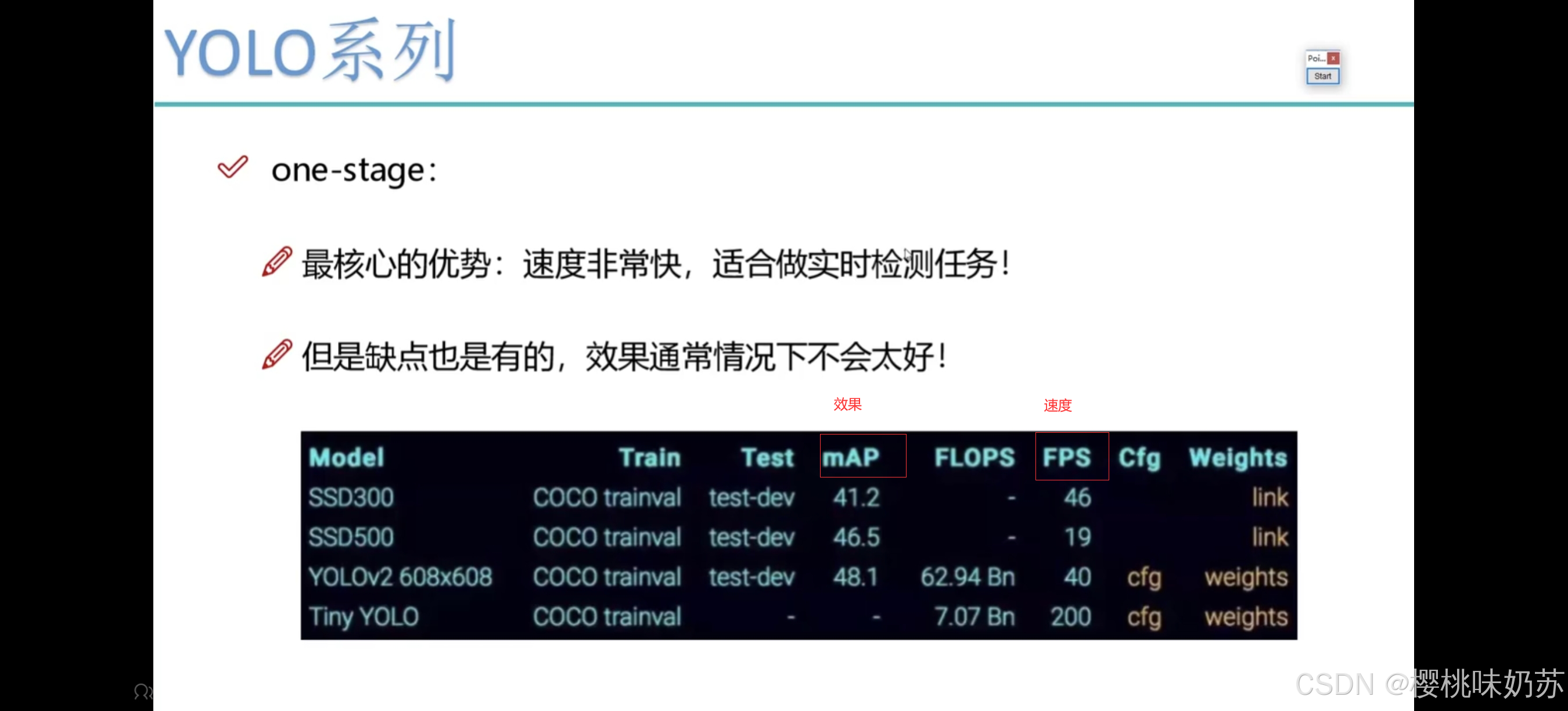

速度和效果成反比关系,速度越快,效果越差
速度越慢,效果越好
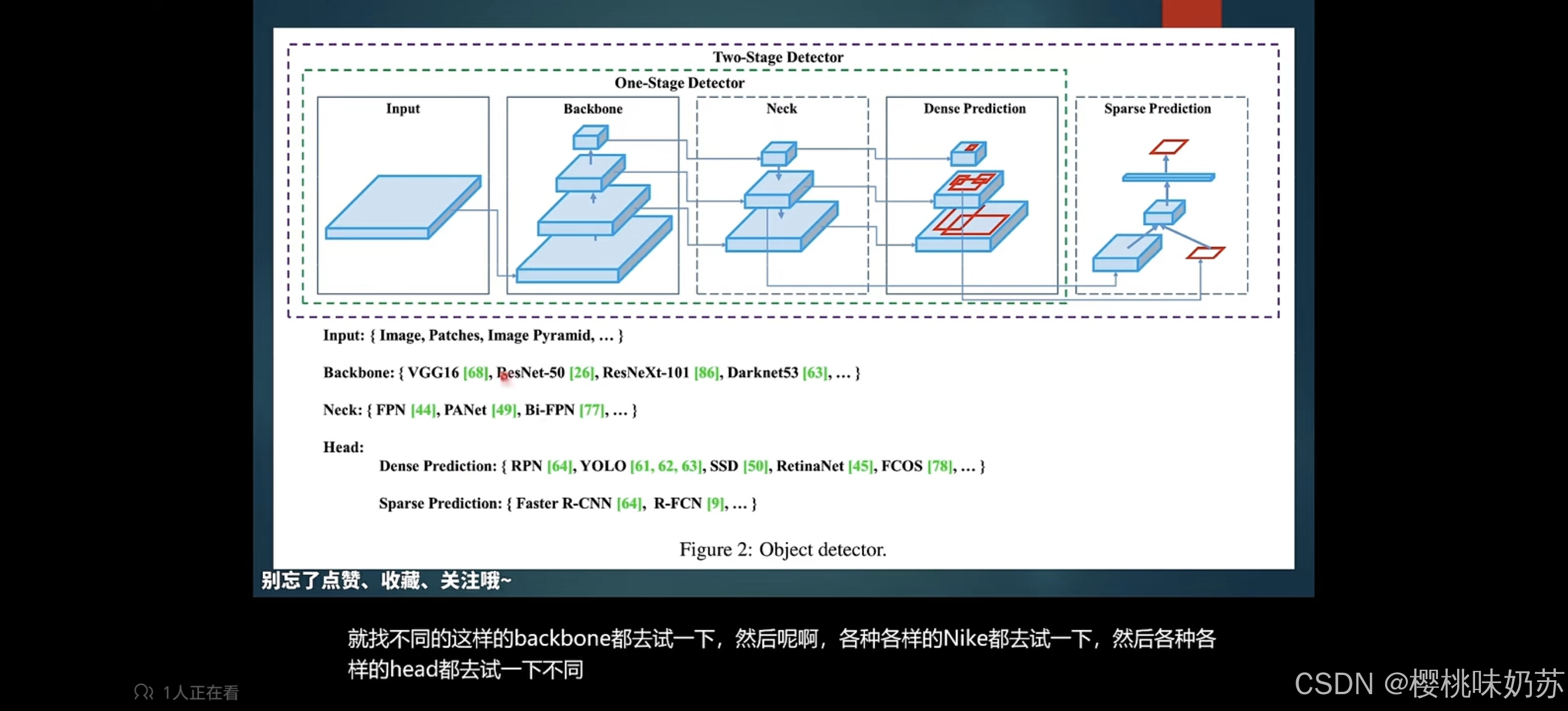
yolo系列将一堆算法像堆乐高一样叠起来,看看哪一个效果更好
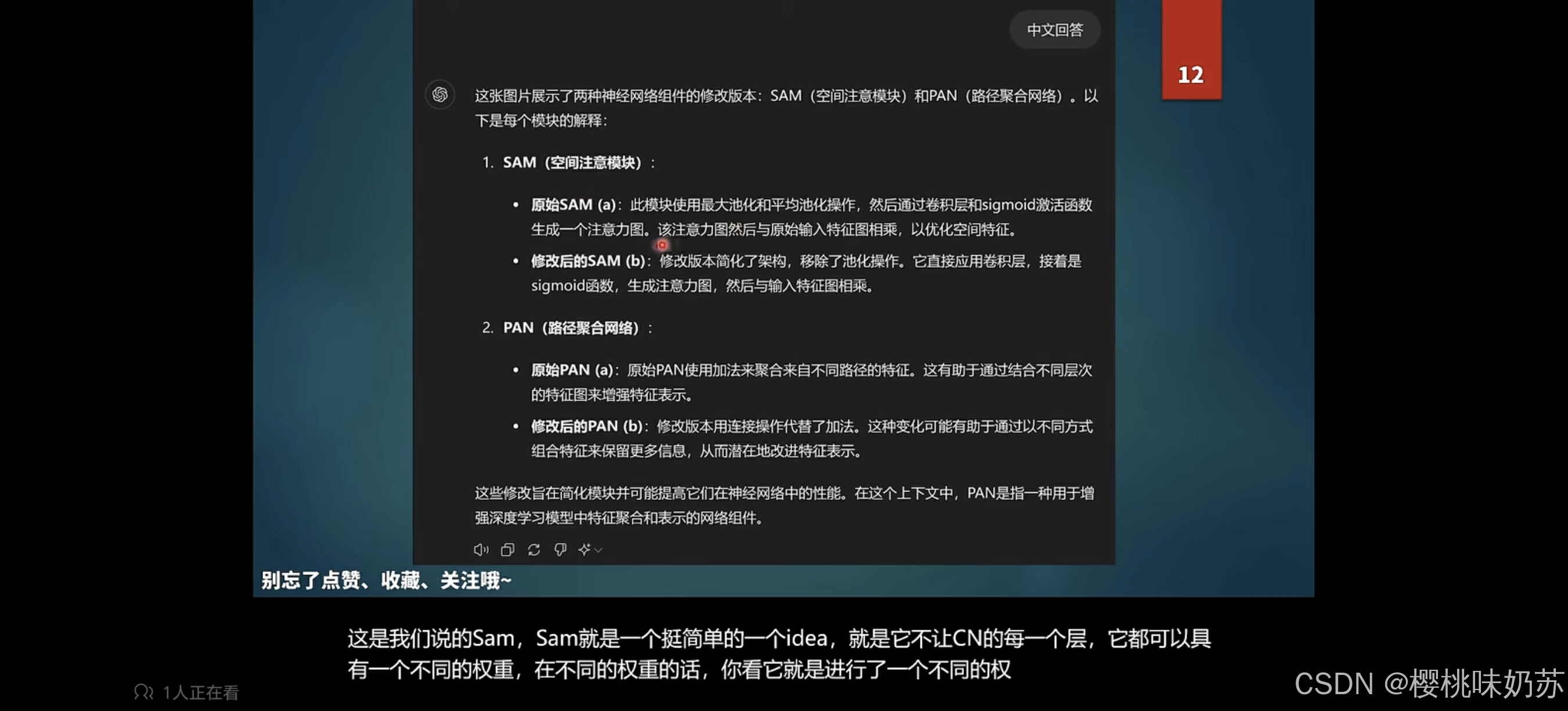
sam让cnn每个层有不同的权重,pan连接,不是加


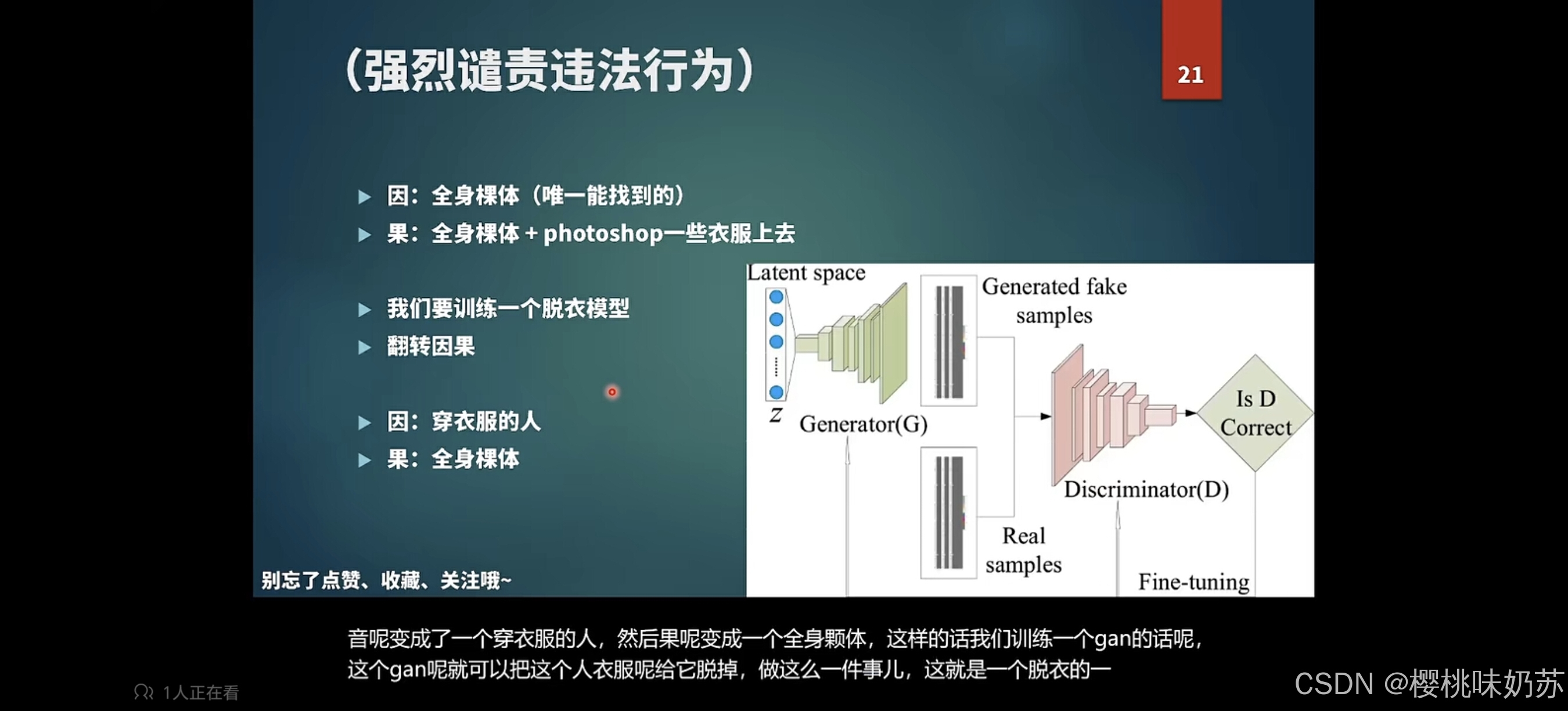
data augmentation加噪去噪 stable diffusion
5.yolov5
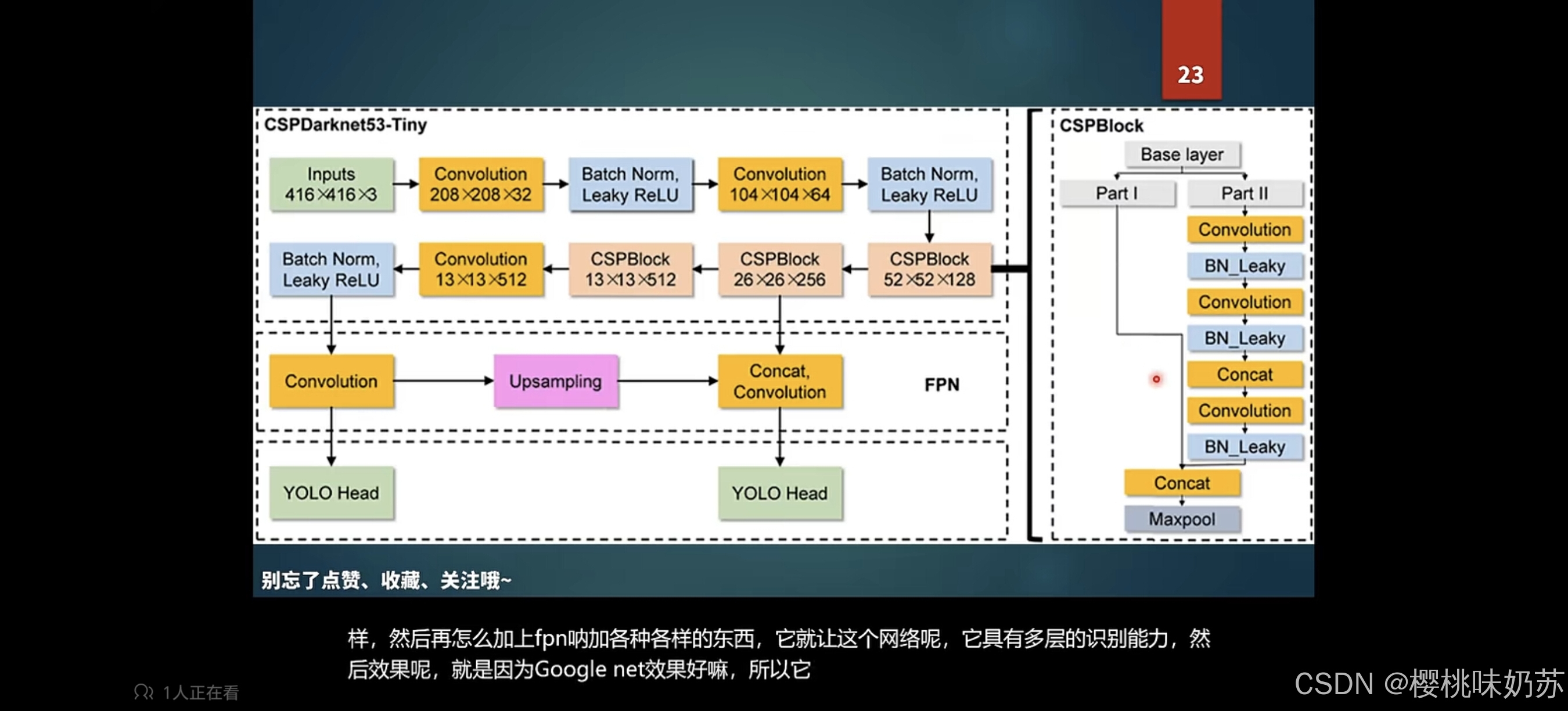
CNN:

FPN:


ReLU、LeakyReLU:激活函数




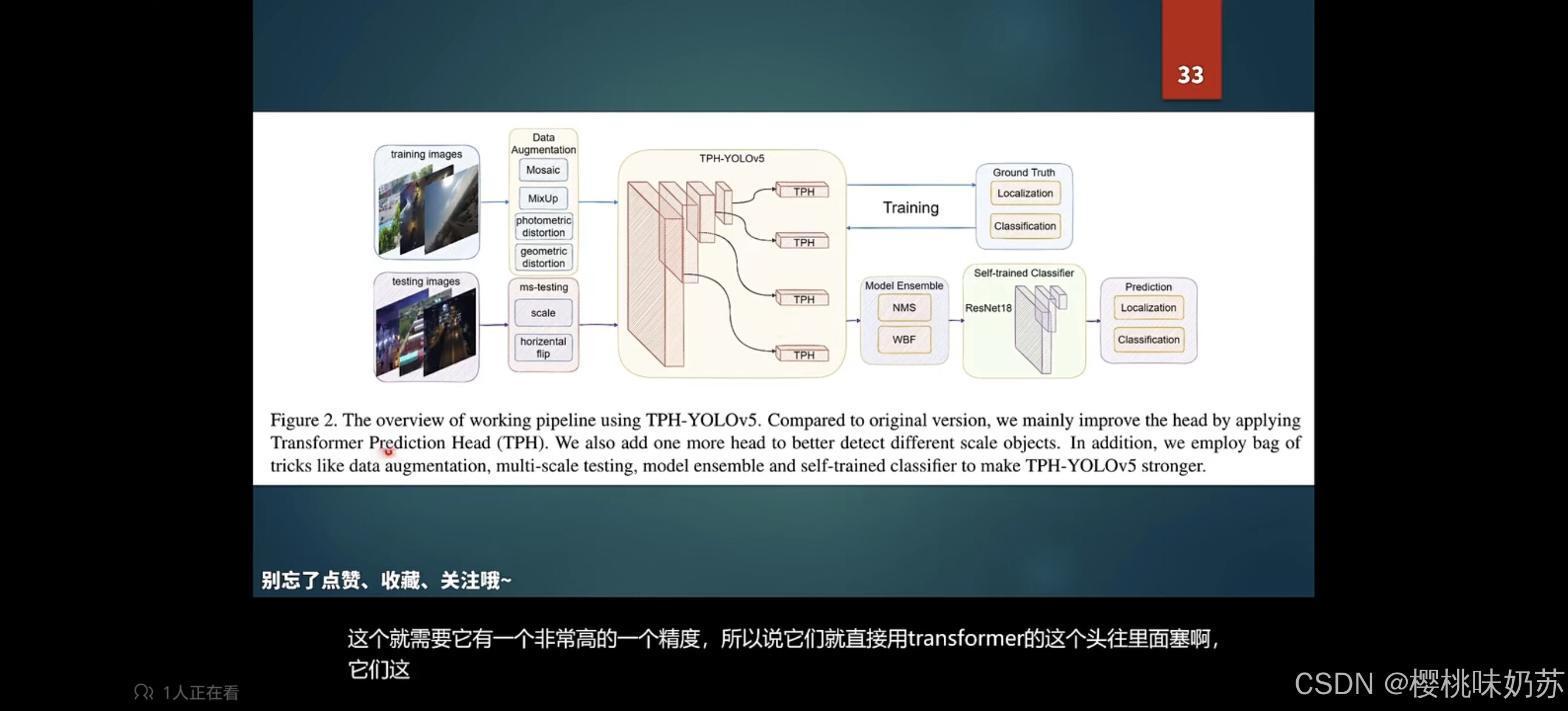
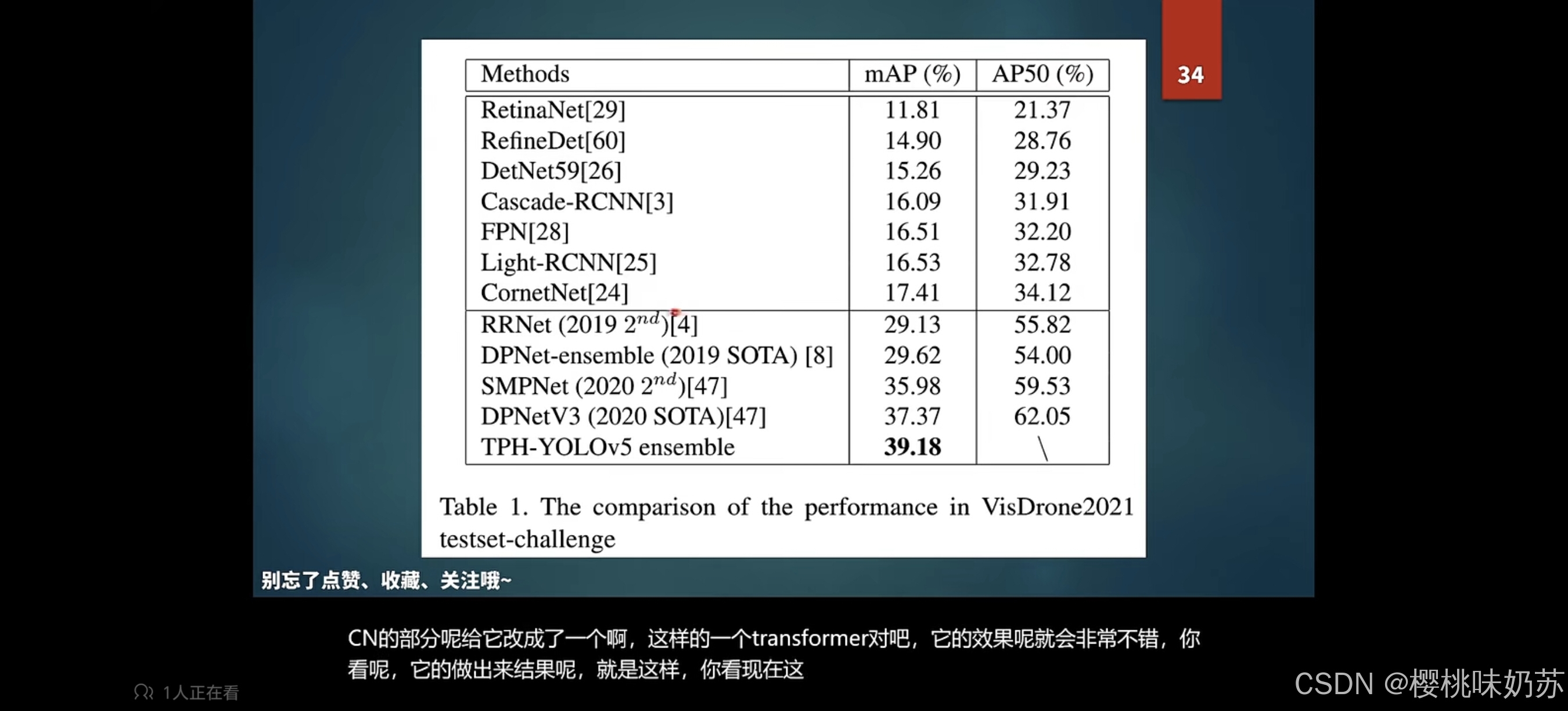
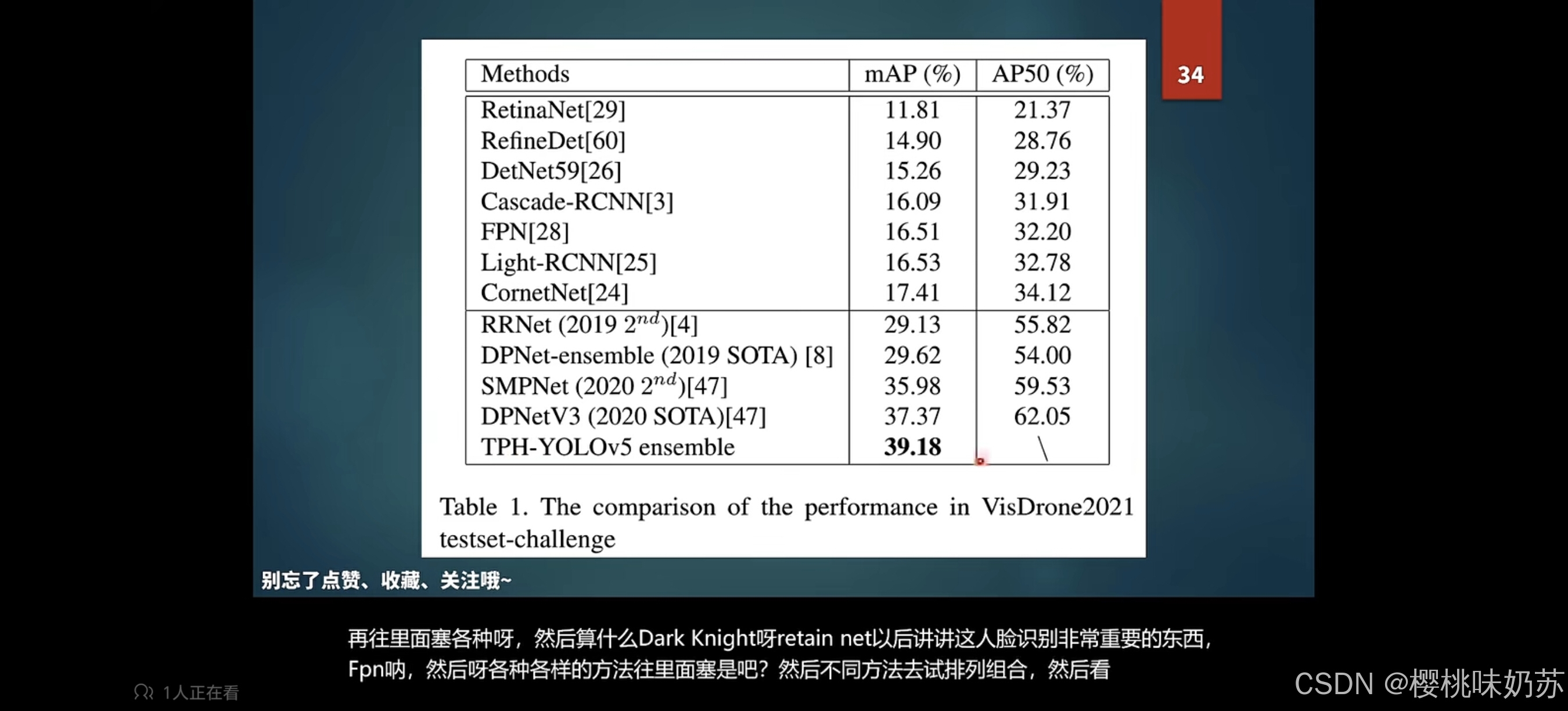
RetinaNet:视网膜网络(人脸识别)
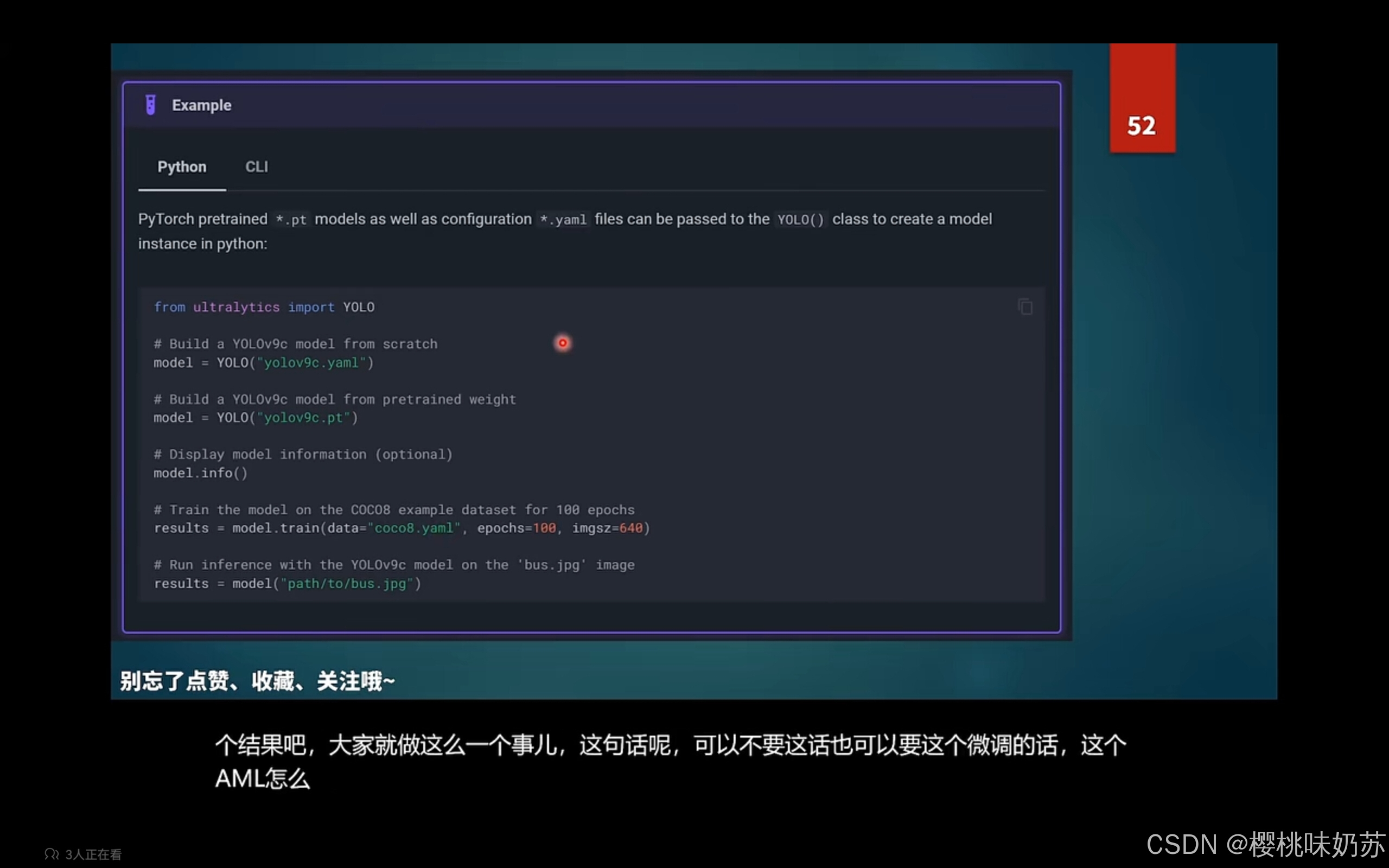
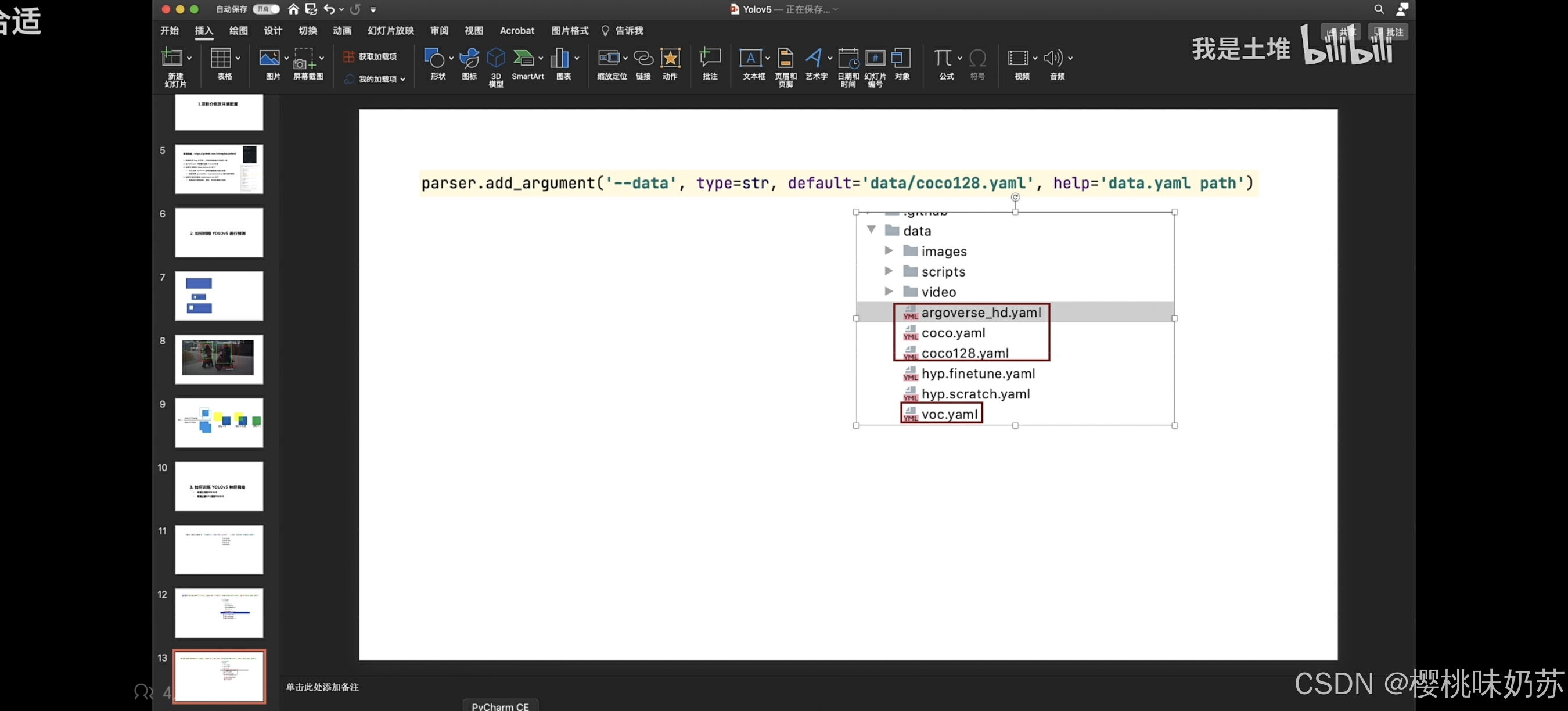
超参数 scratch:对coco数据集,从头到尾
finetune:对voc数据集微调
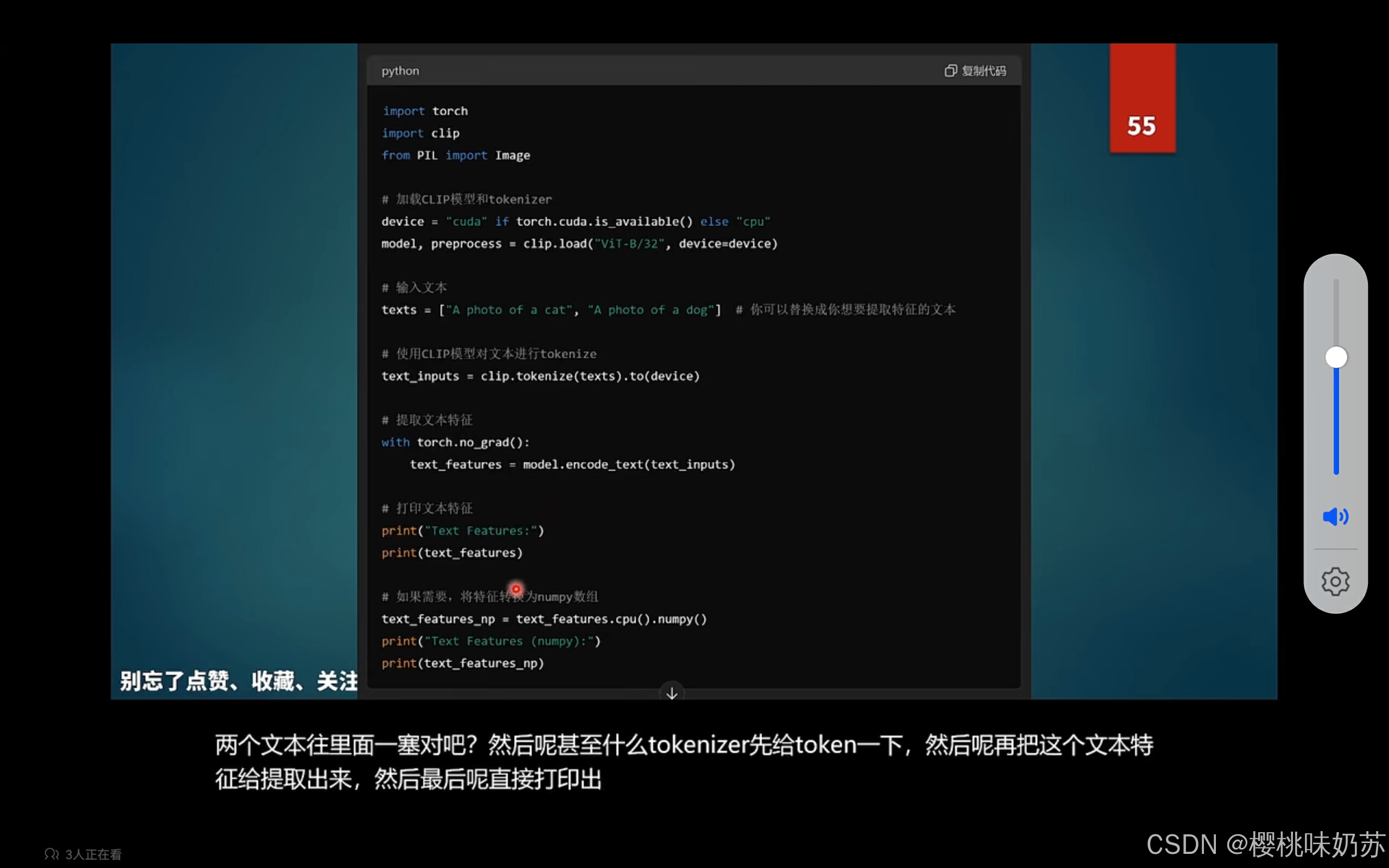
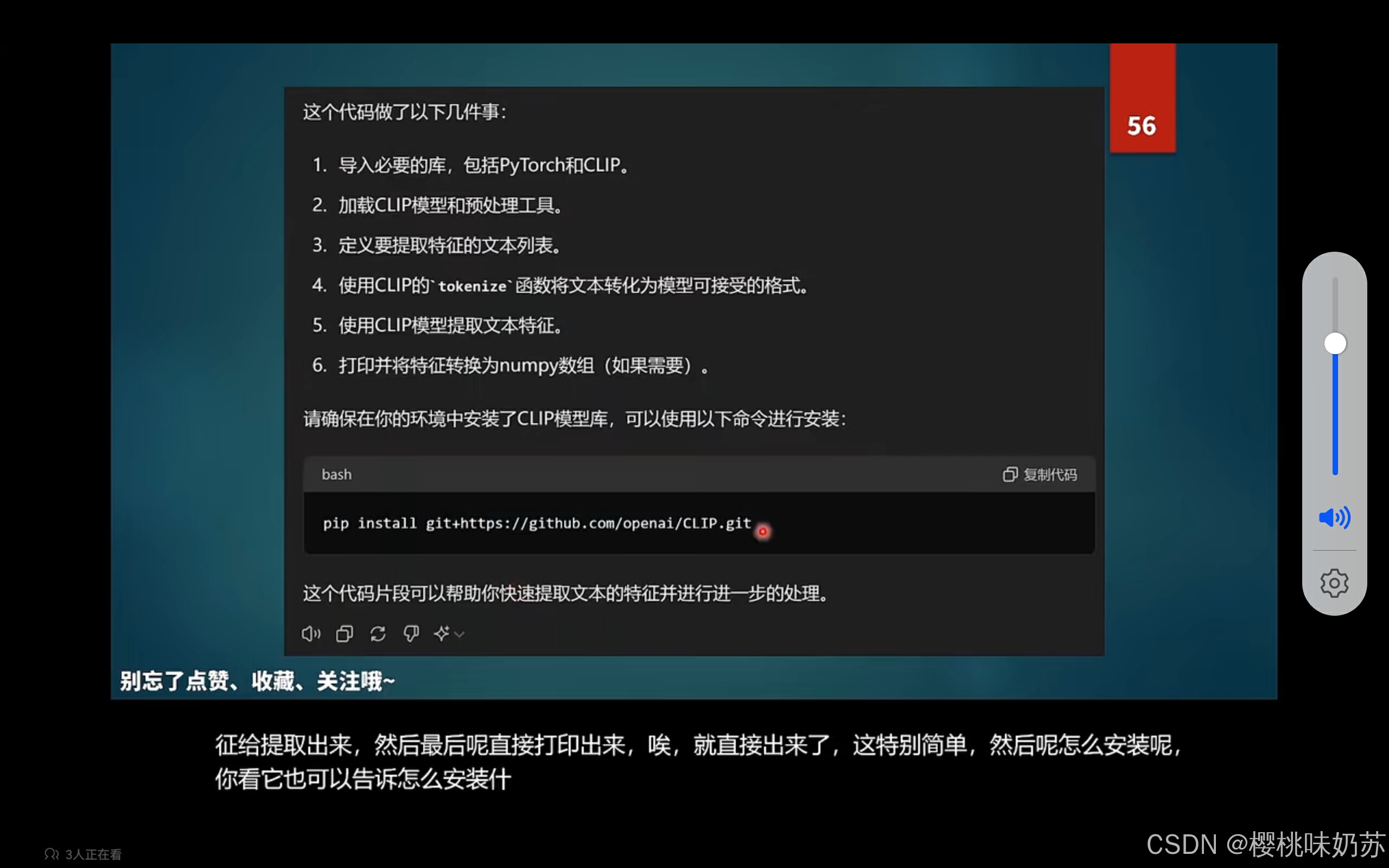





5.运行
examples:这些文件和文件夹共同提供了一系列关于如何在不同编程环境中实现和利用 YOLOv8 的实际示例。这些示例涵盖了从基本的对象检测到更复杂的图像分割和视频处理任务,为开发者提供了丰富的学习资源和应用指导。
tests:包含自动测试脚本,用于确保代码的稳定性和性能。
nn:pytorch底层相关的一些操作

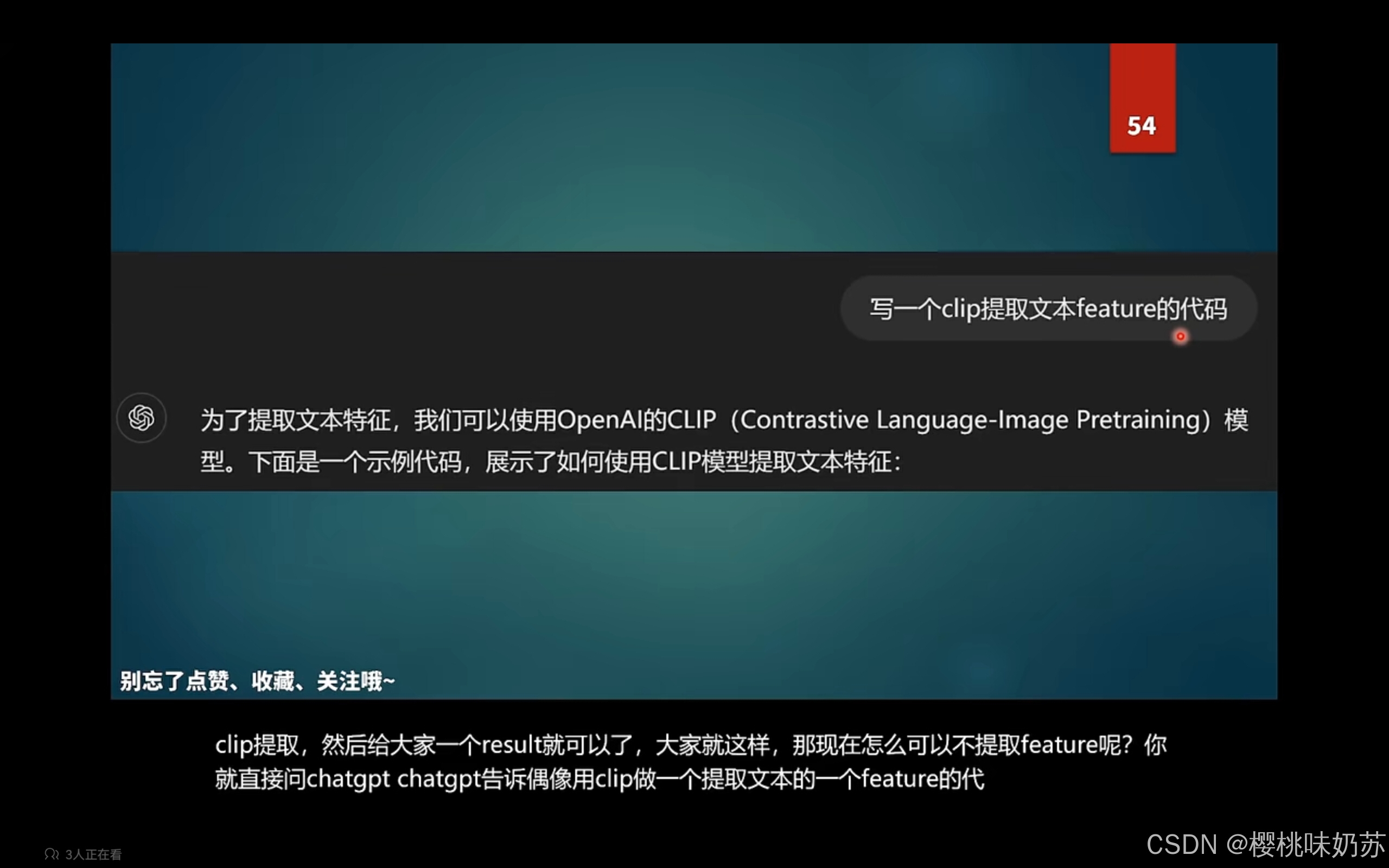
写入模块里面

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









